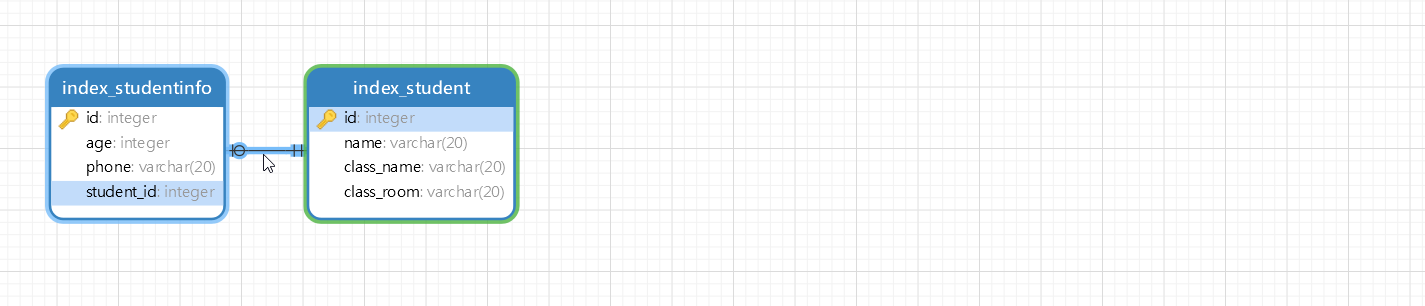Django对各种数据库提供了很好的支持 , 包括PostgreSQL , MySQL , SQLite和Oracle ,
而且为这些数据库提供了统一的API方法 , 这些API统称为ORM框架 .
通过使用Django内置的ORM框架可以实现数据库连接和读写操作 .
本章以SQLite数据库为例 , 分别讲述Django的模型定义与数据迁移 , 数据表关系 , 数据表操作和多数据库的连接与使用 .
本节讲述Django的模型定义 , 开发个人的ORM框架 , 数据迁移和数据导入与导出 , 说明如下 :
● 模型定义讲述了模型字段和模型属性的设置 , 不同类型的模型字段对应不同的数据表字段 .
模型属性可用于Django其他功能模块 , 如设置模型所属的App .
● 开发个人的ORM框架是从源码深入剖析Django的ORM框架底层原理 , 并参考此原理实现个人的ORM框架的开发 .
● 数据迁移是根据模型在数据库里创建相应的数据表 ,
这一过程由Django内置操作指令makemigrations和migrate实现 , 此外还讲述数据迁移常见的错误以及其他数据迁移指令 .
● 数据导入与导出是对数据表的数据执行导入与导出操作 , 确保开发阶段 , 测试阶段和项目上线的数据互不影响 .
ORM框架是一种程序技术 , 用于实现面向对象编程语言中不同类型系统的数据之间的转换 .
从效果上说 , 它创建了一个可在编程语言中使用的 '虚拟对象数据库' ,
通过对虚拟对象数据库的操作从而实现对目标数据库的操作 , 虚拟对象数据库与目标数据库是相互对应的 .
在Django中 , 虚拟对象数据库也称为模型 , 通过模型实现对目标数据库的读写操作 , 实现方法如下 :
( 1 ) 配置目标数据库 , 在settings . py中设置配置属性 , 配置步骤可参考 2.4 节 .
( 2 ) 构建虚拟对象数据库 , 在App的models . py文件中以类的形式定义模型 .
( 3 ) 通过模型在目标数据库中创建相应的数据表 .
( 4 ) 在其他模块 ( 如视图函数 ) 里使用模型来实现目标数据库的读写操作 .
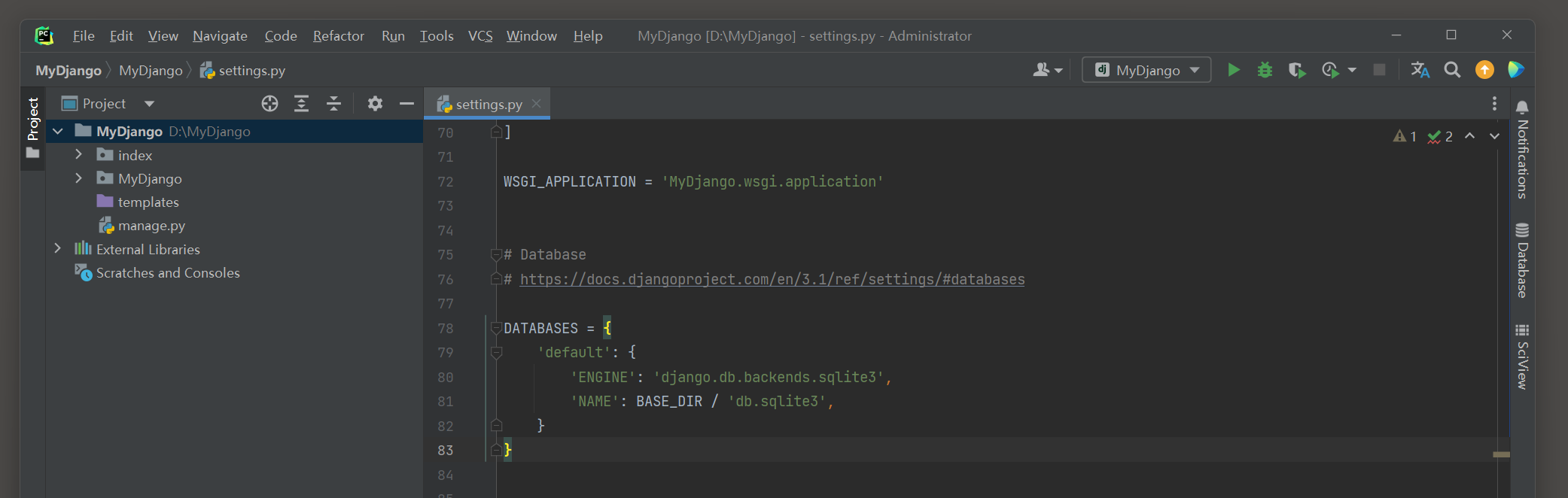
在项目的配置文件settings . py里设置数据库配置信息 . 以MyDjango项目为例 , 其配置信息如下 :
DATABASES = {
'default' : {
'ENGINE' : 'django.db.backends.sqlite3' ,
'NAME' : BASE_DIR / 'db.sqlite3' ,
}
}
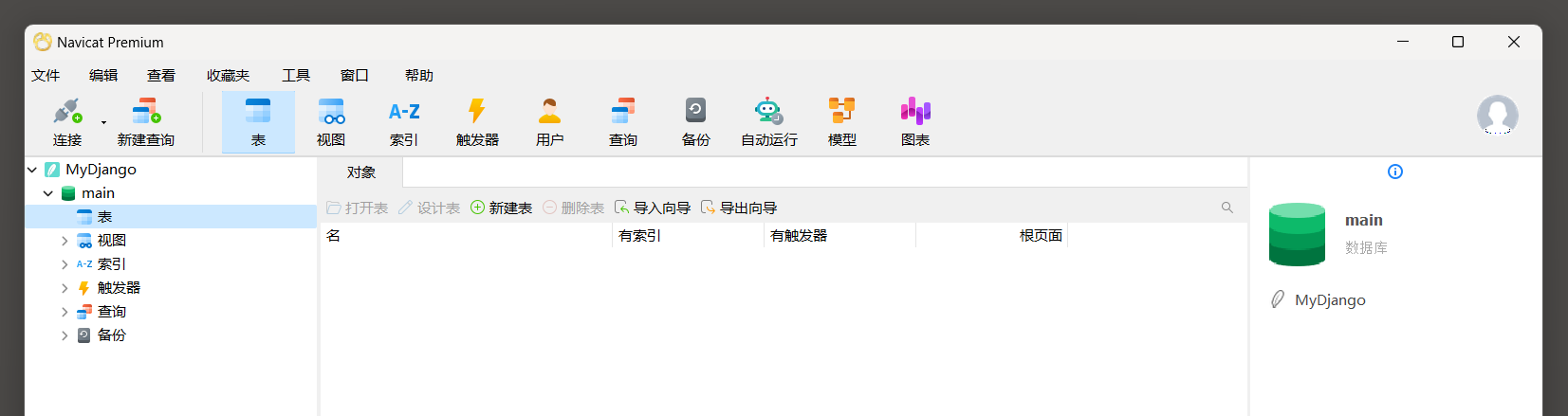
我们使用Navicat Premium数据库管理工具 ( 这是一个可视化数据库管理工具 , 读者可自行在网上搜索并安装该工具 )
查看当前SQLite3数据库 , 数据库文件是MyDjango根目录下的db . sqlite3文件 , 如图 7 - 1 所示 .
( 注意 : 新创建的项目需要运行一次后才会生成db . sqlite3文件 . )
图 7 - 1 数据库信息
从图 7 - 1 中可以看到 , SQLite3数据库当前没有数据表 ,
而数据表可以通过模型创建 , 因为Django对模型和目标数据库之间有自身的映射规则 ,
如果自己在数据库中创建数据表 , 就可能不符合Django的建表规则从而导致模型和目标数据库无法建立有效的通信联系 .
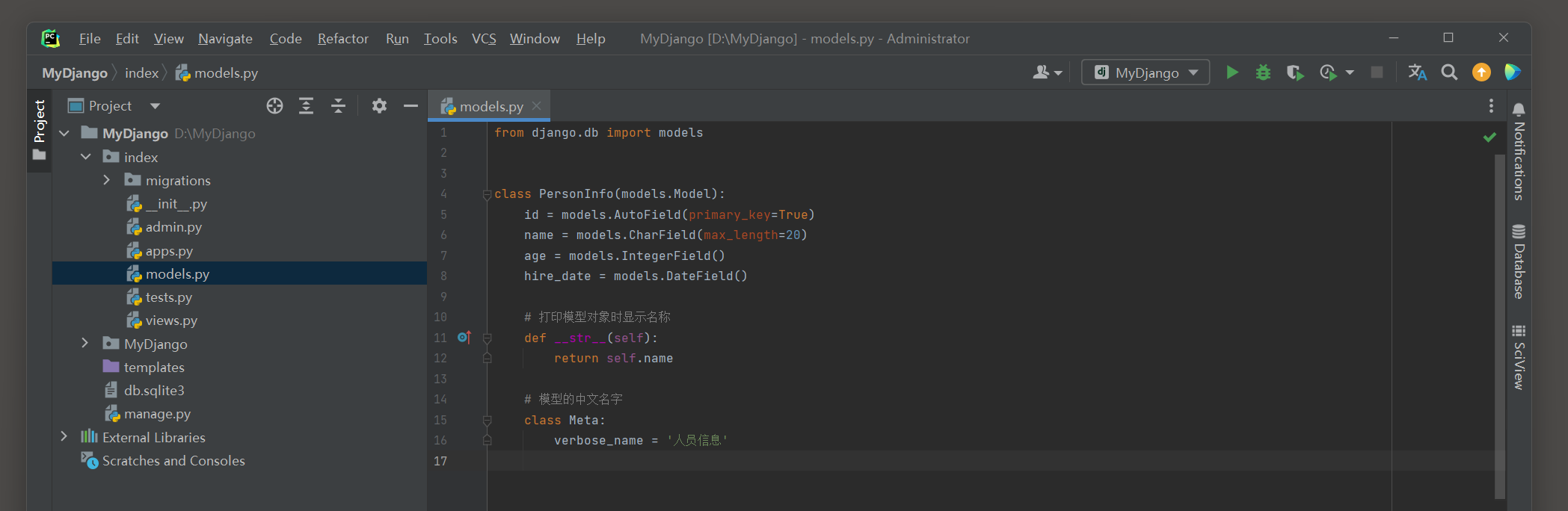
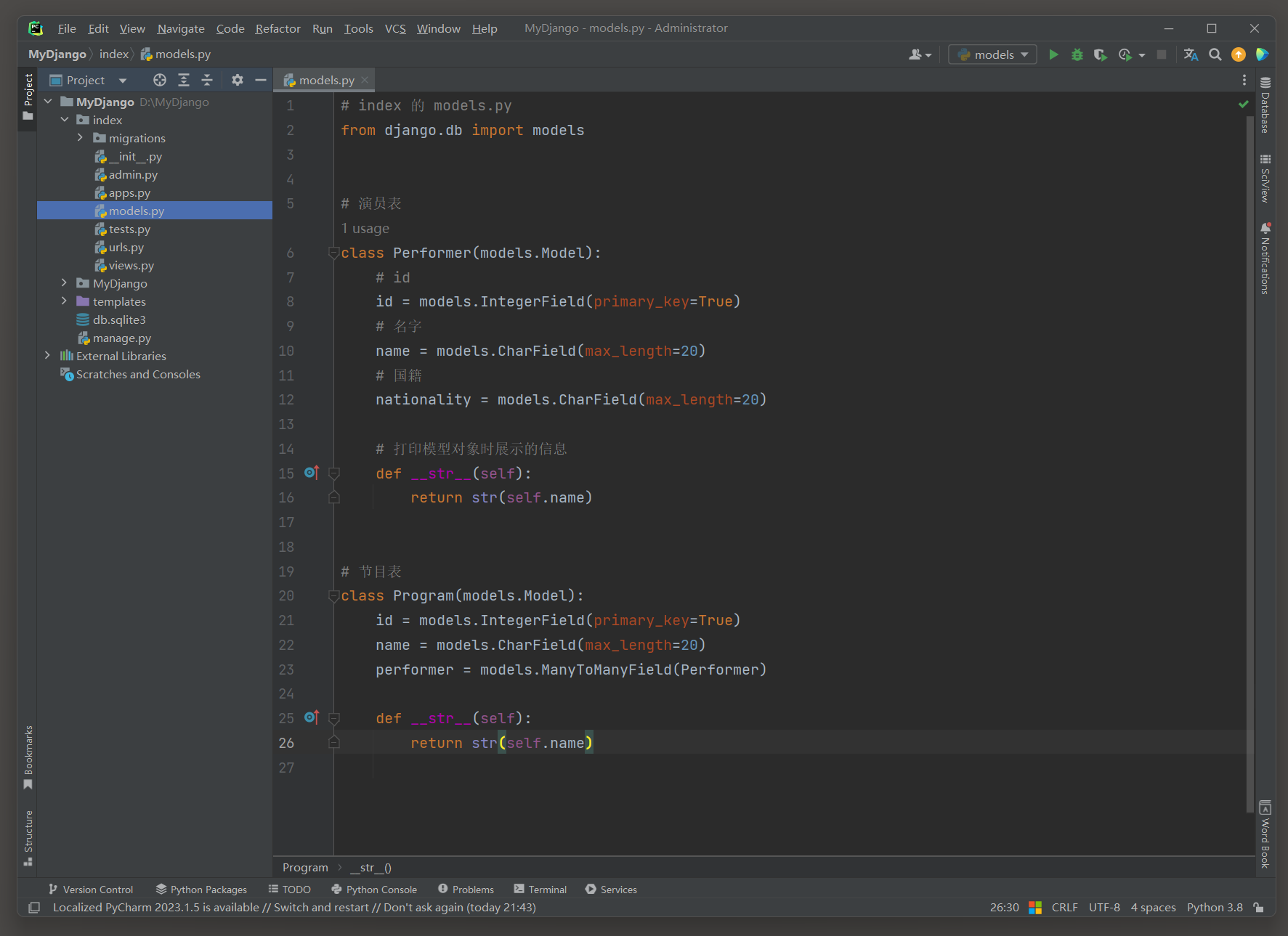
大概了解项目的环境后 , 在项目index的models . py文件中定义模型 , 代码如下 :
from django. db import models
class PersonInfo ( models. Model) :
id = models. AutoField( primary_key= True )
name = models. CharField( max_length= 20 )
age = models. IntegerField( )
hire_date = models. DateField( )
def __str__ ( self) :
return self. name
class Meta :
verbose_name = '人员信息'
模型PersonInfo定义了 4 个不同类型的字段 , 分别代表自增主键 , 字符类型 , 整型和日期类型 .
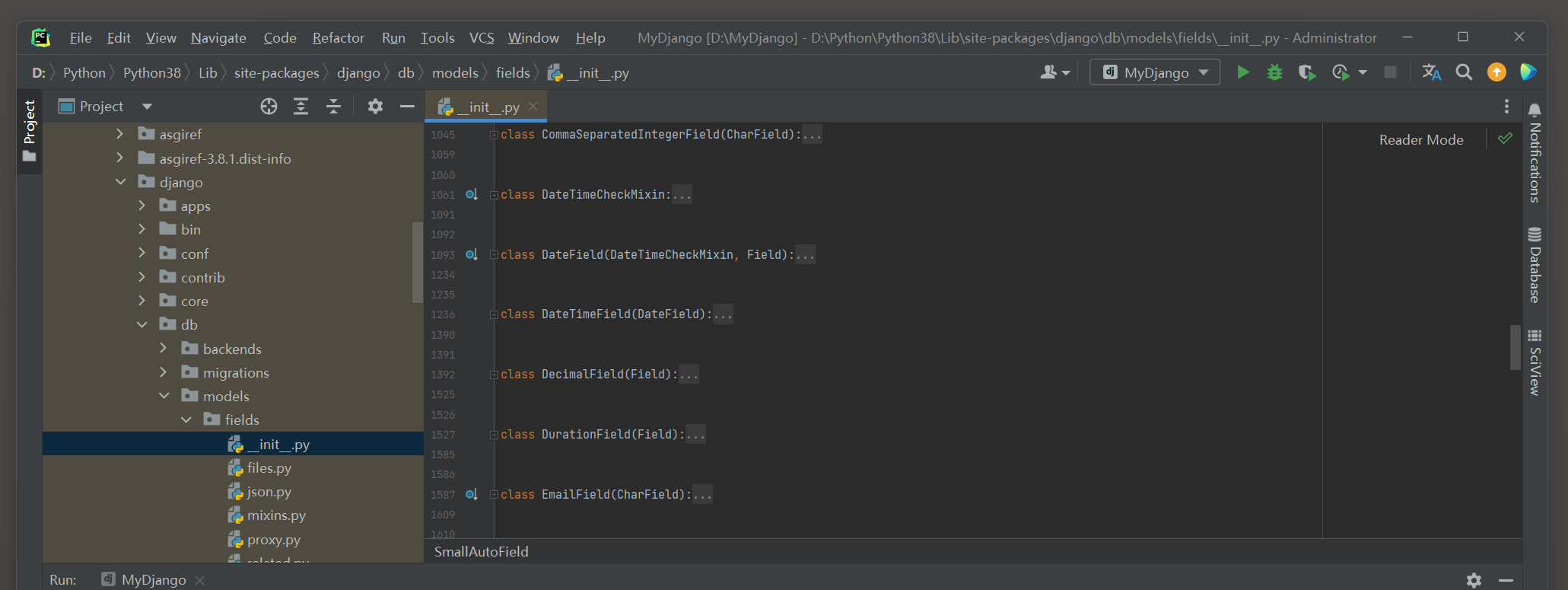
但在实际开发中 , 我们需要定义不同的字段类型来满足各种开发需求 , 因此Django划分了多种字段类型 ,
在源码目录django \ db \ models \ fields的__init__ . py和files . py文件里找到各种模型字段 .
说明如下 :
● AutoField : 自增长类型 , 数据表的字段类型为整数 , 长度为 11 位 .
● BigAutoField : 自增长类型 , 数据表的字段类型为bigint , 长度为 20 位 .
● CharField : 字符类型 .
● BooleanField : 布尔类型 .
● CommaSeparatedIntegerField : 用逗号分隔的整数类型 .
● DateField : 日期 ( Date ) 类型 .
● DateTimeField : 日期时间 ( Datetime ) 类型 .
● Decimal : 十进制小数类型 .
● EmailField : 字符类型 , 存储邮箱格式的字符串 .
● FloatField : 浮点数类型 , 数据表的字段类型变成Double类型 .
● IntegerField : 整数类型 , 数据表的字段类型为 11 位的整数 .
● BigIntegerField : 长整数类型 .
● IPAddressField : 字符类型 , 存储Ipv4地址的字符串 .
● GenericIPAddressField : 字符类型 , 存储Ipv4和Ipv6地址的字符串 .
● NullBooleanField : 允许为空的布尔类型 .
● PositiveIntegerFiel : 正整数的整数类型 .
● PositiveSmallIntegerField : 小正整数类型 , 取值范围为 0 ~ 32767.
● SlugField : 字符类型 , 包含字母 , 数字 , 下画线和连字符的字符串 .
● SmallIntegerField : 小整数类型 , 取值范围为- 32 , 768 ~ + 32 , 767.
● TextField : 长文本类型 .
● TimeField : 时间类型 , 显示时分秒HH : MM [ :ss [ .uuuuuu ] ] .
● URLField : 字符类型 , 存储路由格式的字符串 .
● BinaryField : 二进制数据类型 .
● FileField : 字符类型 , 存储文件路径的字符串 .
● ImageField : 字符类型 , 存储图片路径的字符串 .
● FilePathField : 字符类型 , 从特定的文件目录选择某个文件 .
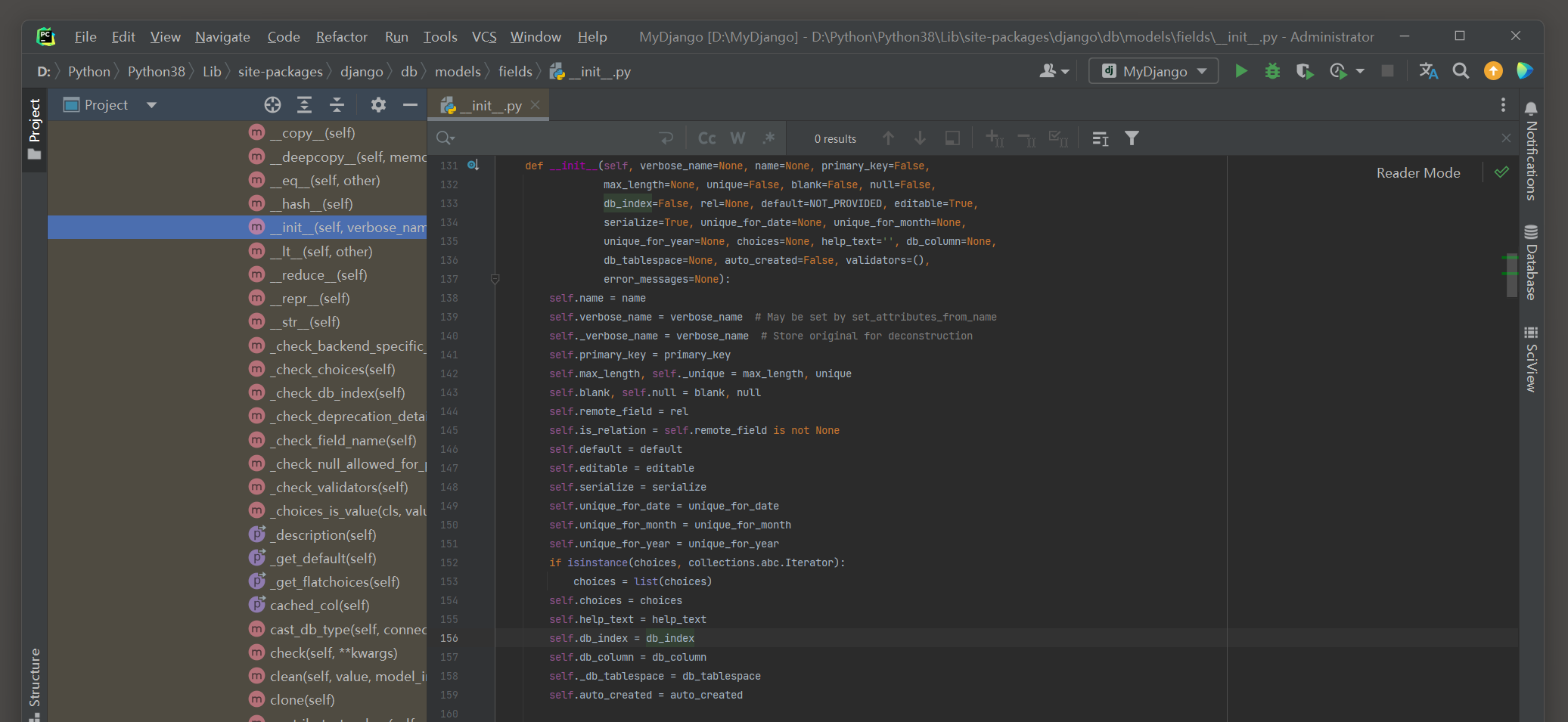
每个模型字段都允许设置参数 , 这些参数来自父类Field ,
我们在源码里查看Field的定义过程 ( django \ db \ models \ fields \ __init__ . py ) 并且对模型字段的参数进行分析 .
● verbose_name : 默认为None , 在Admin站点管理设置字段的显示名称 .
● primary_key : 默认为False . 若为True , 则将字段设置成主键 .
● max_length : 默认为None , 设置字段的最大长度 .
● unique : 默认为False若为True , 则设置字段的唯一属性 .
● blank : 默认为False , 若为True , 则字段允许为空值 , 数据库将存储空字符串 .
● null : 默认为False , 若为True , 则字段允许为空值 , 数据库表现为NULL .
● db_index : 默认为False , 若为True , 则以此字段来创建数据库索引 .
● default : 默认为NOT_PROVIDED对象 , 设置字段的默认值 .
● editable : 默认为True , 允许字段可编辑 , 用于设置Admin的新增数据的字段 .
● serialize : 默认为True , 允许字段序列化 , 可将数据转化为JSON格式 .
● unique_for_date : 默认为None , 设置日期字段的唯一性 .
● unique_for_month : 默认为None , 设置日期字段月份的唯一性 .
● unique_for_year : 默认为None , 设置日期字段年份的唯一性 .
● choices : 默认为空列表 , 设置字段的可选值 .
● help_text : 默认为空字符串 , 用于设置表单的提示信息 .
● db_column : 默认为None , 设置数据表的列名称 , 若不设置 , 则将字段名作为数据表的列名 .
● db_tablespace : 默认为None , 如果字段已创建索引 , 那么数据库的表空间名称将作为该字段的索引名 .
注意 : 部分数据库不支持表空间 .
● auto_created : 默认为False , 若为True , 则自动创建字段 , 用于一对一的关系模型 .
● validators : 默认为空列表 , 设置字段内容的验证函数 .
● error_messages : 默认为None , 设置错误提示 .
上述参数适用于所有模型字段 , 但不同类型的字段会有些特殊参数 , 每个字段的特殊参数可以在字段的初始化方法__init__里找到 ,
比如字段DateField和TimeField的特殊参数auto_now_add和auto_now , 字段FileField和ImageField的特殊参数upload_to .
在定义模型时 , 一般情况下都会重写函数__str__ , 这是设置模型的返回值 , 默认情况下 , 返回值为模型名 + 主键 .
函数__str__可用于外键查询 , 比如模型A设有外键字段F , 外键字段F关联模型B ,
当查询模型A时 , 外键字段F会将模型B的函数__str__返回值作为字段内容 .
需要注意的是 , 函数__str__只允许返回字符类型的字段 , 如果字段是整型或日期类型的 ,
就必须使用Python的str ( ) 函数将其转化成字符类型 .
模型除了定义模型字段和重写函数__str__之外 , 还有Meta选项 , 这三者是定义模型的基本要素 .
Meta选项里设有 19 个属性 , 每个属性的说明如下 :
● abstract : 若设为True , 则该模型为抽象模型 , 不会在数据库里创建数据表 .
● app_label : 属性值为字符串 , 将模型设置为指定的项目应用 , 比如将index的models . py定义的模型A指定到其他App里 .
● db_table : 属性值为字符串 , 设置模型所对应的数据表名称 .
● db_teblespace : 属性值为字符串 , 设置模型所使用数据库的表空间 .
● get_latest_by : 属性值为字符串或列表 , 设置模型数据的排序方式 .
● managed : 默认值为True , 支持Django命令执行数据迁移 ; 若为False , 则不支持数据迁移功能 .
● order_with_respect_to : 属性值为字符串 , 用于多对多的模型关系 , 指向某个关联模型的名称 , 并且模型名称必须为英文小写 .
比如模型A和模型B , 模型A的一条数据对应模型B的多条数据 , 两个模型关联后 , 当查询模型A的某条数据时 ,
可使用get_b_order ( ) 和set_b_order ( ) 来获取模型B的关联数据 , 这两个方法名称的b为模型名称小写 .
此外get_next_in_order ( ) 和get_previous_in_order ( ) 可以获取当前数据的下一条和上一条的数据对象 .
● ordering : 属性值为列表 , 将模型数据以某个字段进行排序 .
● permissions : 属性值为元组 , 设置模型的访问权限 , 默认设置添加 , 删除和修改的权限 .
● proxy : 若设为True , 则为模型创建代理模型 , 即克隆一个与模型A相同的模型B .
● required_db_features : 属性值为列表 , 声明模型依赖的数据库功能 . 比如 [ 'gis_enabled' ] , 表示模型依赖GIS功能 .
● required_db_vendor : 属性值为列表 , 声明模型支持的数据库 , 默认支持SQLite , PostgreSQL , MySQL和Oracle .
● select_on_save : 数据新增修改算法 , 通常无须设置此属性 , 默认值为False .
● indexes : 属性值为列表 , 定义数据表的索引列表 .
● unique_together : 属性值为元组 , 多个字段的联合唯一 , 等于数据库的联合约束 .
● verbose_name : 属性值为字符串 , 设置模型直观可读的名称并以复数形式表示 .
● verbose_name_plural : 与verbose_name相同 , 以单数形式表示 .
● label : 只读属性 , 属性值为app_label . object_name , 如index的模型PersonInfo , 值为index . PersonInfo .
● label_lower : 与label相同 , 但其值为字母小写 , 如index . personinfo .
综上所述 , 模型字段 , 函数__str__和Meta选项是模型定义的基本要素 ,
模型字段的类型 , 函数__str__和Meta选项的属性设置需由开发需求而定 .
在定义模型时 , 还可以在模型里定义相关函数 , 如get_absolute_url ( ) , 当视图类没有设置属性success_url时 ,
视图类的重定向路由地址将由模型定义的get_absolute_url ( ) 提供 .
除此之外 , Django支持开发者自定义模型字段 , 从源码文件得知 , 所有模型字段继承Field类 ,
只要将自定义模型字段继承Field类并重写父类某些属性或方法即可完成自定义过程 ,
具体的自定义过程不再详细讲述 , 读者可以参考内置模型字段的定义过程 .
我们知道模型是以类的形式定义的 , 并且继承父类Model , 但在使用模型操作数据库时 , 开发者直接使用即可 , 无须将模型实例化 .
为了深入探究Django的模型机制 , 在PyCharm里打开父类Model的源码文件 ,
发现Model类在定义过程中设置了metaclass = ModelBase , 如图 7 - 2 所示 .
图 7 - 2 Model的定义过程
在Model类的源码文件里找到ModelBase的定义过程 , 发现ModelBase类继承Python的type类 , 如图 7 - 3 所示 .
图 7 - 3 ModelBase的定义过程
分析Model类和ModelBase类的源码发现 , 两者的定义过程与我们定义类的方式有所不同 .
ModelBase类继承父类type , 这是自定义Python的元类 , 元类是创建类的类 , type是Python用来创建所有类的内置元类 ,
而ModelBase类继承type类 , 它通过自定义属性和方法来创建模型对象的元类 .
Model类设置metaclass = ModelBase是将Model类的创建过程交由元类ModelBase执行 ,
而项目里定义模型继承Model类 , 这说明我们定义的模型也是由元类ModelBase完成创建的 .
也许读者难以理解Python元类 , 因此将通过一个简单的例子来加以说明 , 代码如下 :
class CreateClass ( type ) :
def __new__ ( cls, name, bases, attr) :
attrs = [ ]
print ( attr)
for k, v in attr. items( ) :
if not v. startswith( "__" ) :
attrs. append( ( k, v) )
new_attrs = dict ( ( k, v) for k, v in attrs)
return super ( ) . __new__( cls, name, bases, new_attrs)
class PersonInfo ( metaclass= CreateClass) :
name = 'Django'
name2 = '__qz'
print ( PersonInfo. name)
print ( PersonInfo. name2)
运行上述代码 , 程序执行过程如下 :
( 1 ) 执行类PersonInfo , 目的是生成类对象并加载到计算机的内存里 ( 类对象与实例化对象是两个不同的概念 ) .
( 2 ) 默认情况下 , 类对象的创建是由Python内置的type完成的 , 由于类PersonInfo设置元类CreateClass ,
因此创建过程由元类CreateClass完成 , 它重写type的方法__new__ ,
这是将类PersonInfo的属性进行清洗处理 , 去除属性值带有双下画线的属性 .
( 3 ) 程序执行print函数 , 将类PersonInfo的属性name输出 .
综上所述 , Django的ORM框架是通过继承并重写元类type来实现的 .
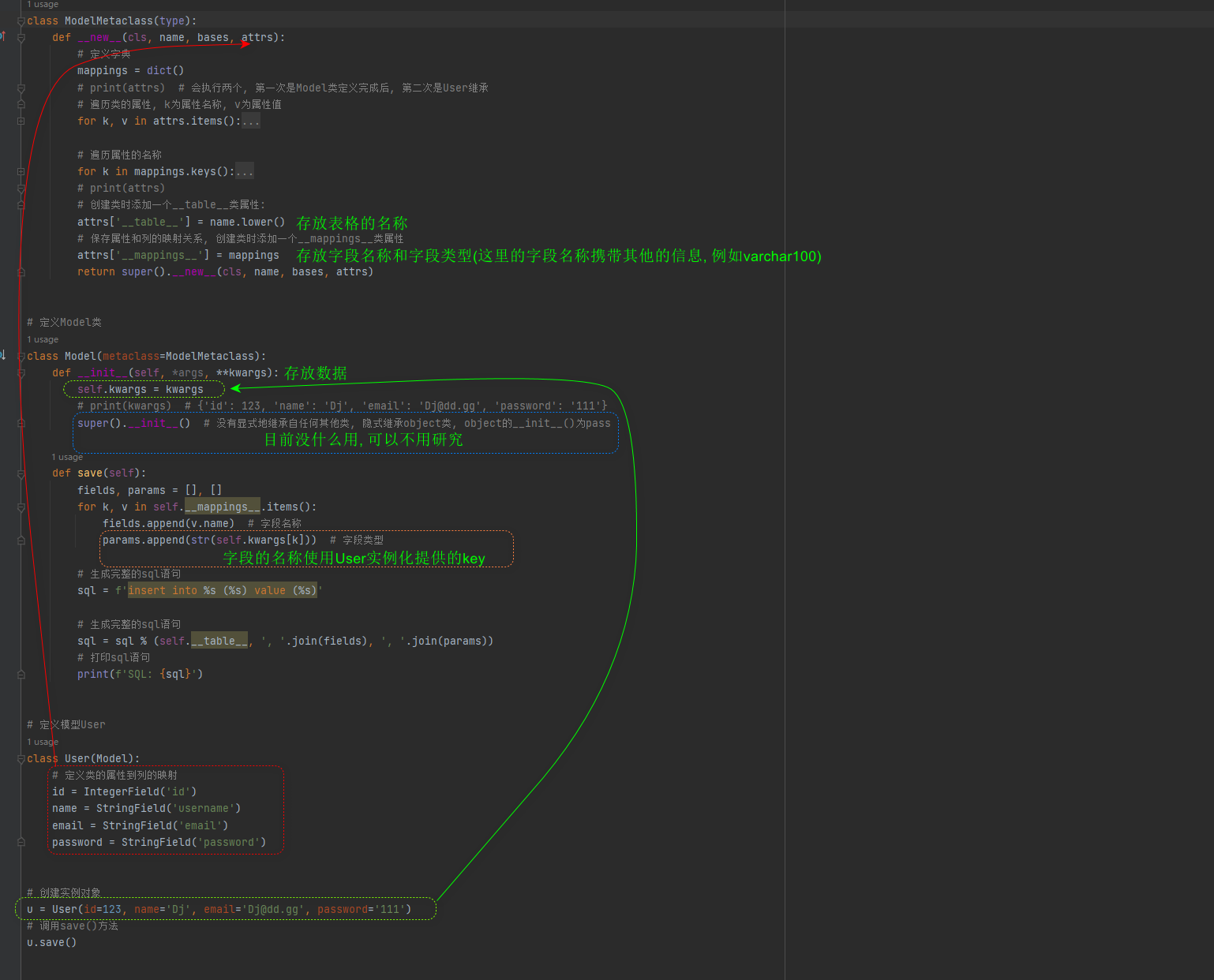
根据这一原理 , 我们可自主开发个人的ORM框架 , 分别定义模型字段 , 元类 , 模型基本类 , 代码如下 :
class Field ( object ) :
def __init__ ( self, name, column_type) :
self. name = name
self. column_type = column_type
def __str__ ( self) :
return f'< { self. __class__. __name__} : { self. name} >' class StringField ( Field) :
def __init__ ( self, name) :
super ( ) . __init__( name, 'varchar(100)' )
class IntegerField ( Field) :
def __init__ ( self, name) :
super ( ) . __init__( name, 'bigint' )
class ModelMetaclass ( type ) :
def __new__ ( cls, name, bases, attrs) :
mappings = dict ( )
for k, v in attrs. items( ) :
if isinstance ( v, Field) :
print ( f'Found mappings: { k} ==> { v} ' )
mappings[ k] = v
for k in mappings. keys( ) :
attrs. pop( k)
attrs[ '__table__' ] = name. lower( )
attrs[ '__mappings__' ] = mappings
return super ( ) . __new__( cls, name, bases, attrs)
class Model ( metaclass= ModelMetaclass) :
def __init__ ( self, * args, ** kwargs) :
self. kwargs = kwargs
super ( ) . __init__( )
def save ( self) :
fields, params = [ ] , [ ]
for k, v in self. __mappings__. items( ) :
fields. append( k)
params. append( v)
sql = r'insert into %s (%s) values(%s)'
sql = sql % ( self. __table__, ',' . join( fields) , ',' . join( params) )
print ( f'SQL: { sql} ' )
上述代码是我们自定义的ORM框架 , 设计逻辑参考Django的ORM框架 .
为了验证自定义的ORM框架的功能 , 通过定义模型User并使其继承父类Model ,
再由模型User调用父类Model的save方法 , 观察save方法的输出结果 , 实现代码如下 :
class User ( Model) :
id = IntegerField( 'id' )
name = StringField( 'username' )
email = StringField( 'email' )
password = StringField( 'password' )
u = User( id = 123 , name= 'Dj' , email= 'Dj@dd.gg' , password= '111' )
u. save( )
在PyCharm里运行上述代码并查看程序的输出结果 , 当调用save ( ) 方法时 ,
程序会将实例化对象u的数据生成相应的SQL语句 , 只要在ORM框架里实现数据库连接 ,
并执行SQL语句即可实现数据库的数据操作 , 运行结果如图 7 - 4 所示 .
图 7 - 4 运行结果
数据迁移是将项目里定义的模型生成相应的数据表 , 在 5.1 .3 小节已简单介绍过模型的数据迁移操作 ,
本节将会深入讲述数据迁移的操作 , 包括数据表的创建和更新 .
首次在项目里定义模型时 , 项目所配置的数据库里并没有创建任何数据表 ,
想要通过模型创建数据表 , 可使用Django的操作指令完成创建过程 .
以 7.1 .1 小节的MyDjango为例 ,
from django. db import models
class PersonInfo ( models. Model) :
id = models. AutoField( primary_key= True )
name = models. CharField( max_length= 20 )
age = models. IntegerField( )
hire_date = models. DateField( )
def __str__ ( self) :
return self. name
class Meta :
verbose_name = '人员信息'
在PyCharm的Terminal窗口下输入Django的操作指令 :
D: \MyDjango> python manage. py makemigrations
Migrations for 'index' :
index\migrations\0001_initial. py
- Create model PersonInfo
当makemigrations指令执行成功后 , 在项目应用index的migrations文件夹里创建 0001 _initial . py文件 ,
如果项目里有多个App , 并且每个App的models . py文件里定义了模型对象 ,
当首次执行makemigrations ( 进行迁移 ) 指令时 , Django就在每个App的migrations文件夹里创建 0001 _initial . py文件 .
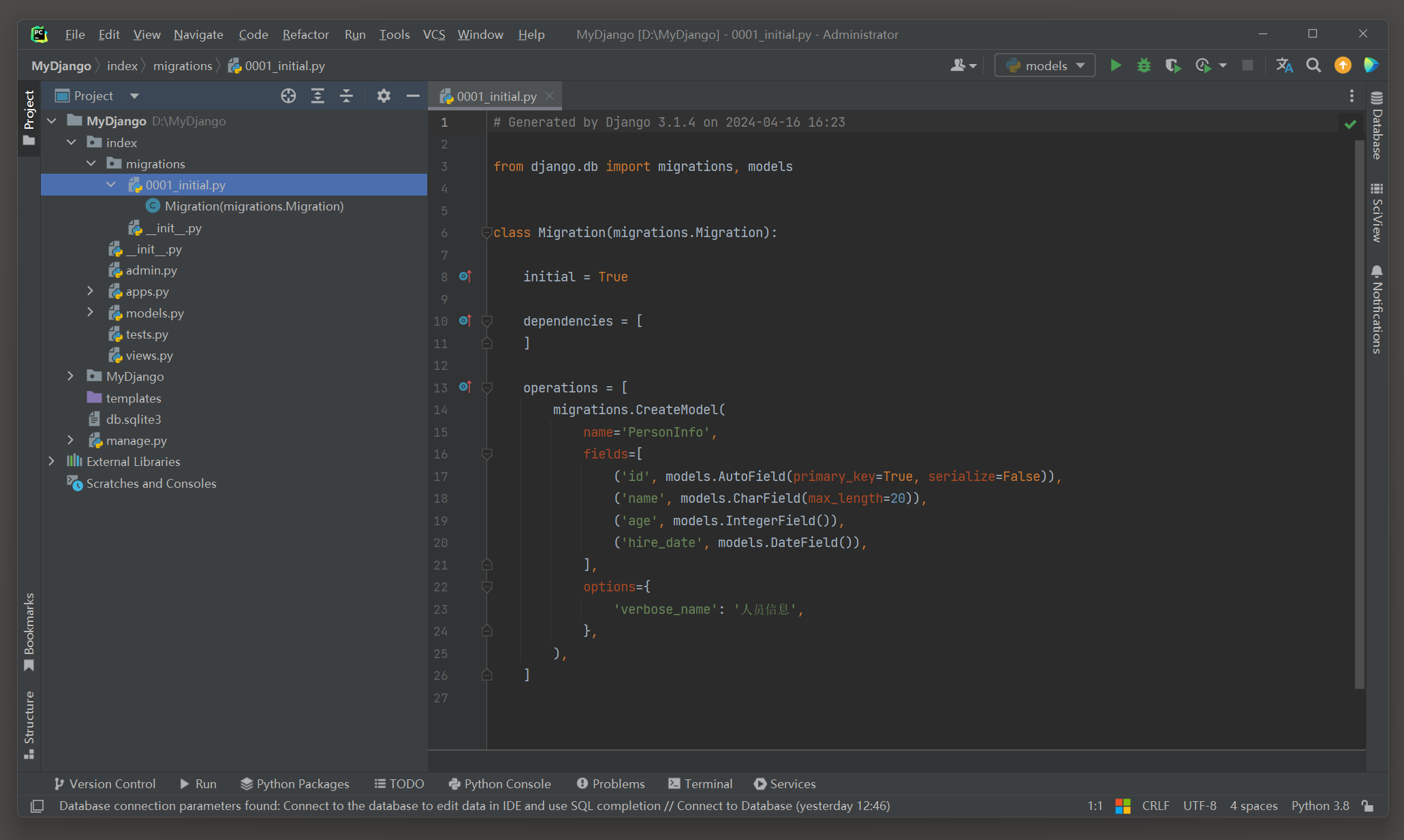
打开查看 0001 _initial . py文件 , 文件内容如图 7 - 5 所示 .
图 7 - 5 0001 _initial . py文件内容
0001 _initial . py文件将models . py定义的模型生成数据表的脚本代码 , 该文件的脚本代码可被migrate指令执行 ,
migrate指令会根据脚本代码的内容在数据库里创建相应的数据表 ,
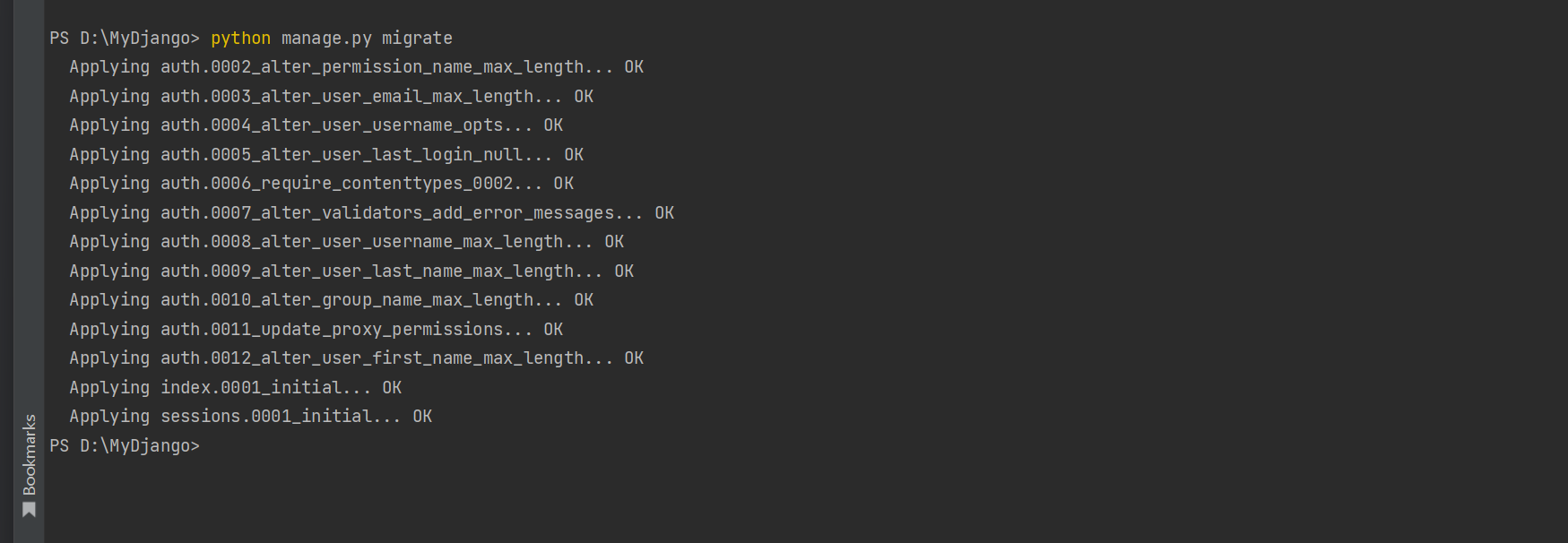
只要在PyCharm的Terminal窗口下输入migrate ( 迁移 ) 指令即可完成数据表的创建 , 代码如下 :
D: \MyDjango> python manage. py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations:
Applying contenttypes. 0001_initial. . . OK
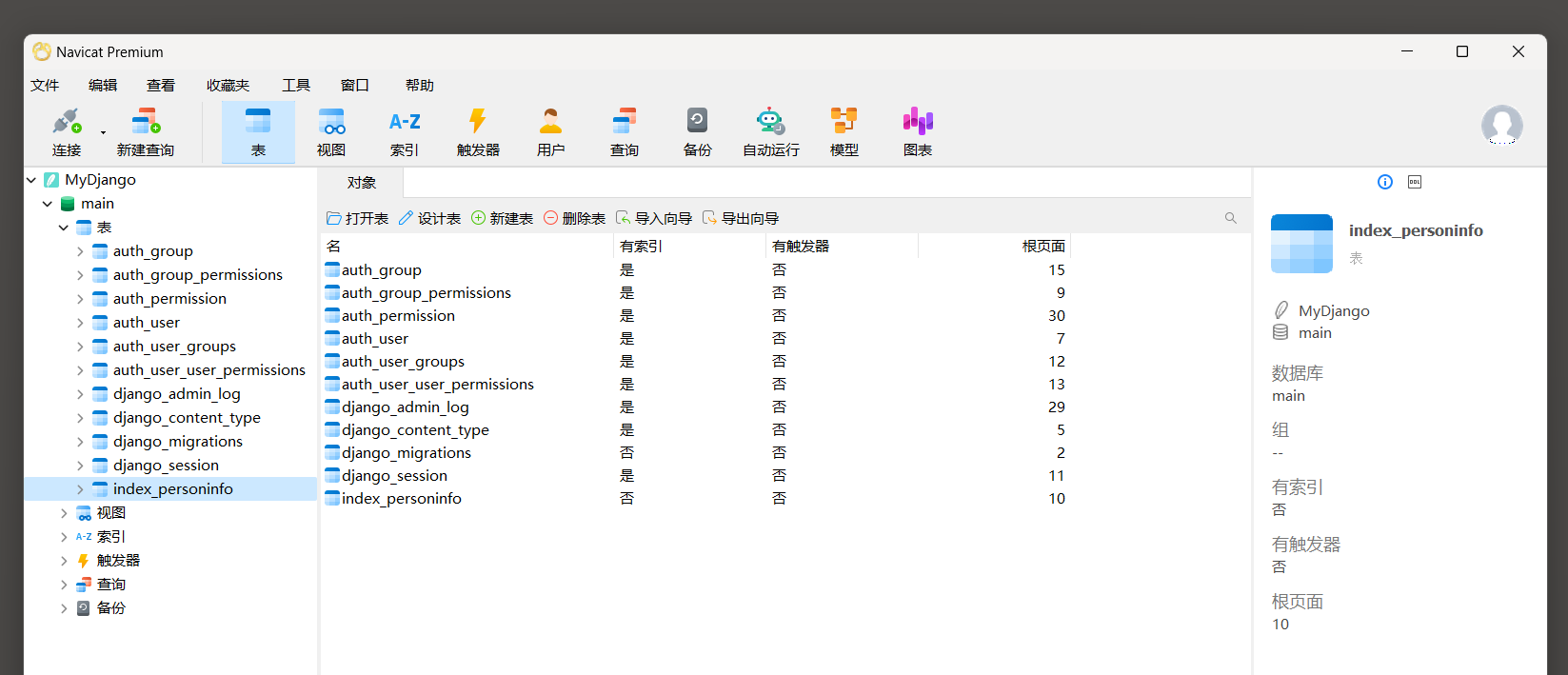
指令运行完成后 , 打开数据库就能看到新建的数据表 , 其中数据表index_personinfo由项目应用index定义的模型PersonInfo创建 ,
而其他数据表是Django内置的功能所使用的数据表 , 分别是会话Session , 用户认证管理和Admin后台系统等 .
在Django中 , 使用的ORM ( 对象关系映射 ) 来定义模型时 , Django会自动为你创建数据库表来存储这些模型的数据 .
默认情况下 , 这些表的名称会带有一些前缀或后缀 , 这主要是为了遵循Django的命名规范 , 确保表名的唯一性 , 并避免潜在的命名冲突 .
表名通常会包含应用名作为前缀 .
在开发过程中 , 开发者因为开发需求而经常调整数据表的结构 , 比如新增功能 , 优化现有功能等 .
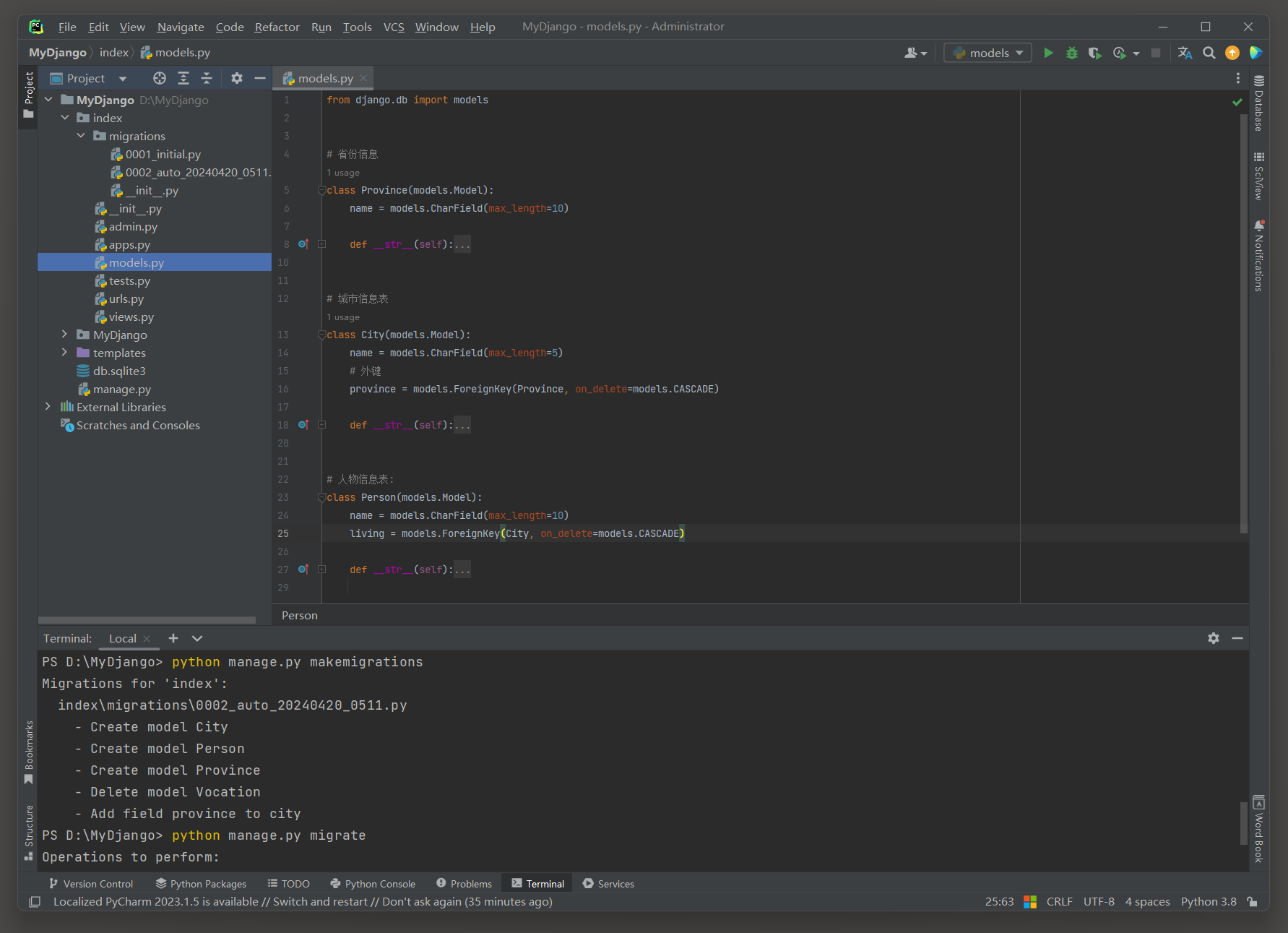
假如在上述例子里新增模型Vocation及其数据表 , 为了保证不影响现有的数据表 , 如何通过新增的模型创建相应的数据表?
针对上述问题 , 我们只需再次执行makemigrations和migrate指令即可 , 比如在index的models . py里定义模型Vocation , 代码如下 :
class Vocation ( models. Model) :
id = models. AutoField( primary= True )
job = models. CharField( max_length= 20 )
title = models. CharField( max_length= 20 )
name = models. ForeignKey( PersonInfo, on_delete= models. Case)
def __str__ ( self) :
return str ( self. id )
class Meta :
verbose_name = '职业信息'
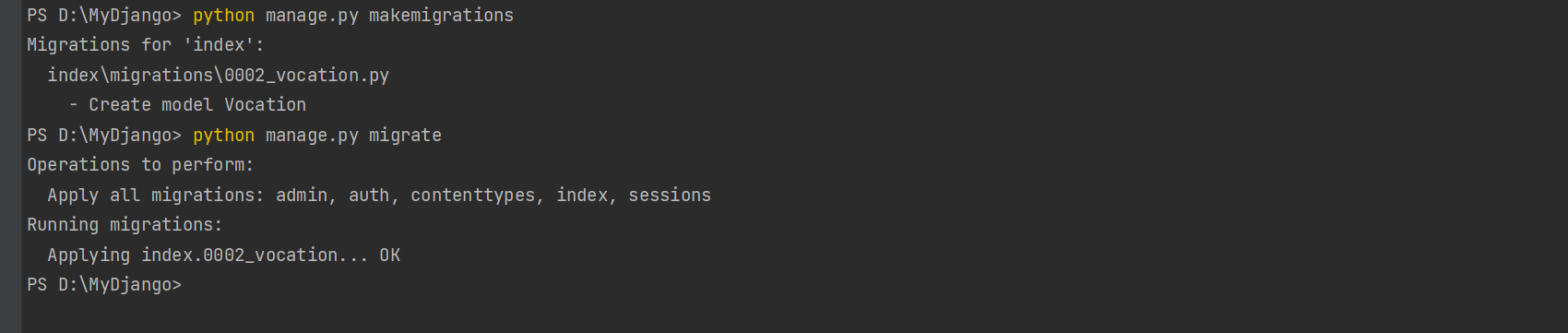
在PyCharm的Terminal窗口下输入并运行makemigrations指令 ,
Django会在index的migrations文件夹里创建 0002 _vocation . py文件 ;
然后输入并运行migrate指令即可完成数据表index_vocation的创建 .
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' :
index\migrations\0002_vocation. py
- Create model Vocation
PS D: \MyDjango> python manage. py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations:
Applying index. 0002_vocation. . . OK
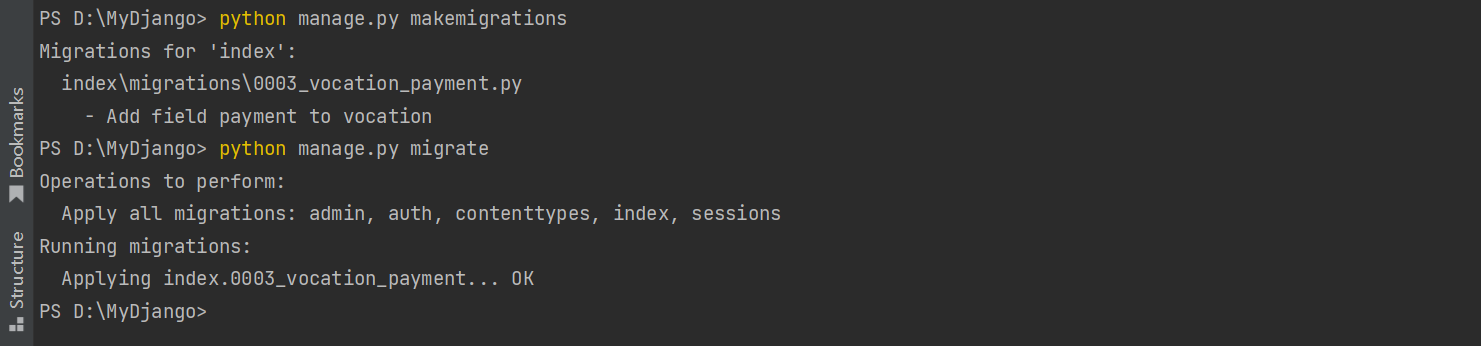
makemigrations和migrate指令还支持模型的修改 , 从而修改相应的数据表结构 , 比如在模型Vocation里新增字段payment , 代码如下 :
class Vocation ( models. Model) :
id = models. AutoField( primary_key= True )
job = models. CharField( max_length= 20 )
title = models. CharField( max_length= 20 )
payment = models. IntegerField( null= True , blank= True )
name = models. ForeignKey( PersonInfo, on_delete= models. CASCADE)
def __str__ ( self) :
return str ( self. id )
class Meta :
verbose_name = '职业信息'
在Django的模型 ( models ) 中 , blank 和 null 是两个用于字段定义的选项 , 它们各自具有不同的意义 :
null : 这个选项用于数据库层面 , 决定是否允许该字段在数据库中为NULL .
null = True 意味着在数据库中这个字段可以没有值 ( 即NULL ) , 而 null = False 则意味着这个字段在数据库中必须有值 .
blank : 这个选项用于表单验证层面 .
当 blank = True 时 , 该字段在Django的表单验证中是可以不填的 .
也就是说 , 如果用户在表单中没有为这个字段提供值 , Django不会因为这个字段没有值而抛出验证错误 .
相反 , blank = False 意味着在表单验证时这个字段是必填的 .
on_delete选项 :
models . CASCADE : 当被引用的对象被删除时 , 也删除包含外键的对象 .
如果数据库层级设置了级联删除 , 那么依赖的对象会被数据库自动删除 . 否则 , Django不会执行任何操作 .
models . PROTECT : 阻止删除被引用的对象 , 如果有关联的对象存在 .
models . SET_NULL : 设置外键字段为NULL . 这要求外键字段具有null = True .
models . SET_DEFAULT : 设置外键字段为它的默认值 . 这要求外键字段具有default值。
models . SET ( value ) : 设置外键字段为给定的值 .
models . DO_NOTHING : 不做任何事情 .
新增模型字段必须将属性null和blank设为True或者为模型字段设置默认值 ( 设置属性default ) ,
否则执行makemigrations指令会提示字段修复信息 , 如图 7 - 6 所示 .
图 7 - 6 字段修复信息
当makemigrations指令执行完成后 , 在index的migrations文件夹创建相应的 . py文件 ,
只要再次执行migrate指令即可完成数据表结构的修改 .
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' :
index\migrations\0003_vocation_payment. py
- Add field payment to vocation
PS D: \MyDjango> python manage. py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations:
Applying index. 0003_vocation_payment. . . OK
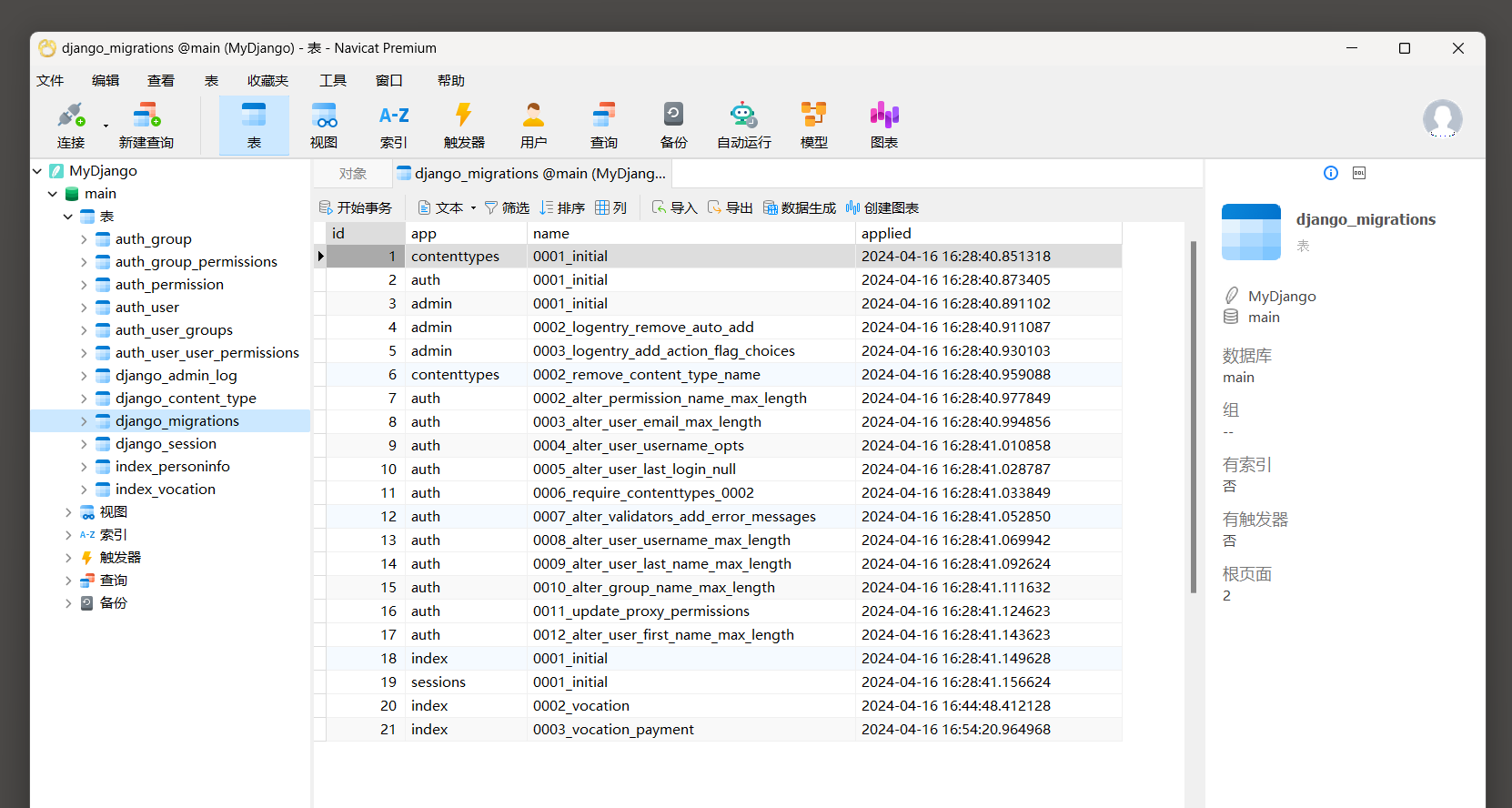
每次执行migrate指令时 , Django都能精准运行migrations文件夹尚未被执行的 . py文件 ,
它不会对同一个 . py文件重复执行 , 因为每次执行时 , Django会将该文件的执行记录保存在数据表django_migrations中 ,
数据表的数据信息如图 7 - 7 所示 .
如果要重复执行migrations文件夹的某个 . py文件 , 就只需在数据表里删除相应的文件执行记录 .
一般情况下不建议采用这种操作 , 因为这样很容易出现异常 ,
比如数据表已存在的情况下 , 再次执行相应的 . py文件会提示table "xxx" already exists异常 .
图 7 - 7 数据表django_migrations
migrate指令还可以单独执行某个 . py文件 , 首次在项目中使用migrate指令时 , Django会默认创建内置功能的数据表 ,
如果只想执行index的migrations文件夹的某个 . py文件 , 那么可以在migrate指令里指定文件名 , 代码如下 :
D: \MyDjango> python manage. py migrate index 0001_initial
Operations to perform:
Target specific migration: 0001_initial, from index
Running migrations:
Applying index. 0001_initial. . . OK
在migrate指令末端设置项目应用名称index和migrations文件夹的 0001 _initial文件名 ,
三者 ( migrate指令 , 项目应用名称index和 0001 _initial文件名 ) 之间使用空格隔开即可 , 指令执行完成后 ,
数据库只有数据表django_migrations和index_personinfo .
我们知道 , migrate指令根据migrations文件夹的 . py文件创建数据表 ,
但在数据库里 , 数据表的创建和修改离不开SQL语句的支持 , 因此Django提供了sqlmigrate指令 ,
该指令能将 . py文件转化成相应的SQL语句 .
以index的 0001 _initial . py文件为例 , 在PyCharm的Terminal窗口输入sqlmigrate指令 ,
指令末端必须设置项目应用名称和migrations文件夹的某个 . py文件名 , 三者之间使用空格隔开即可 , 指令输出结果如图 7 - 8 所示 .
PS D: \MyDjango> python manage. py sqlmigrate index 0001_initial
BEGIN;
- -
- - Create model PersonInfo
- -
CREATE TABLE "index_personinfo" ( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"name" varchar( 20 ) NOT NULL, "age" integer NOT NULL, "hire_date" date NOT NULL) ;
COMMIT;
图 7 - 8 sqlmigrate指令
除此之外 , Django还提供了很多数据迁移指令 , 如squashmigrations , inspectdb , showmigrations ,
sqlflush , sqlsequencereset和remove_stale_contenttypes , 这些指令在 1.9 .1 小节里已说明过了 , 此处不再重复讲述 .
当我们在操作数据迁移时 , Django会对整个项目的代码进行检测 , 它首先执行check指令 ,
只要项目里某个功能文件存在异常 , Django就会终止数据迁移操作 .
也就是说 , 在执行数据迁移之前 , 可以使用check指令检测整个项目 , 项目检测成功后再执行数据迁移操作 , 如图 7 - 9 所示 .
PS D: \MyDjango> python manage. py check
System check identified no issues ( 0 silenced) .
图 7 - 9 check指令
在实际开发过程中 , 我们经常对数据库的数据进行导入和导出操作 , 比如网站重构 , 数据分析和网站分布式部署等 .
一般情况下 , 我们使用数据库可视化工具来实现数据的导入和导出 , 以Navicat Premium为例 ,
打开某个数据表 , 单击 '导入' 或 '导出' 按钮 , 按照操作提示即可完成 , 如图 7 - 10 所示 .
图 7 - 10 数据的导入与导出
使用数据库可视化工具导入某个表的数据时 , 如果当前数据表设有外键字段 ,
就必须将外键字段关联的数据表的数据导入 , 再执行当前数据表的数据导入操作 , 否则数据无法导入成功 .
因为外键字段指向它所关联的数据表 , 如果关联的数据表没有数据 ,
外键字段就无法与关联的数据表生成数据关系 , 从而使当前数据表的数据导入失败 .
除了使用数据库可视化工具实现数据的导入与导出之外 , Django还为我们提供操作指令 ( loaddata和dumpdata ) 来实现数据的导入与导出操作 .
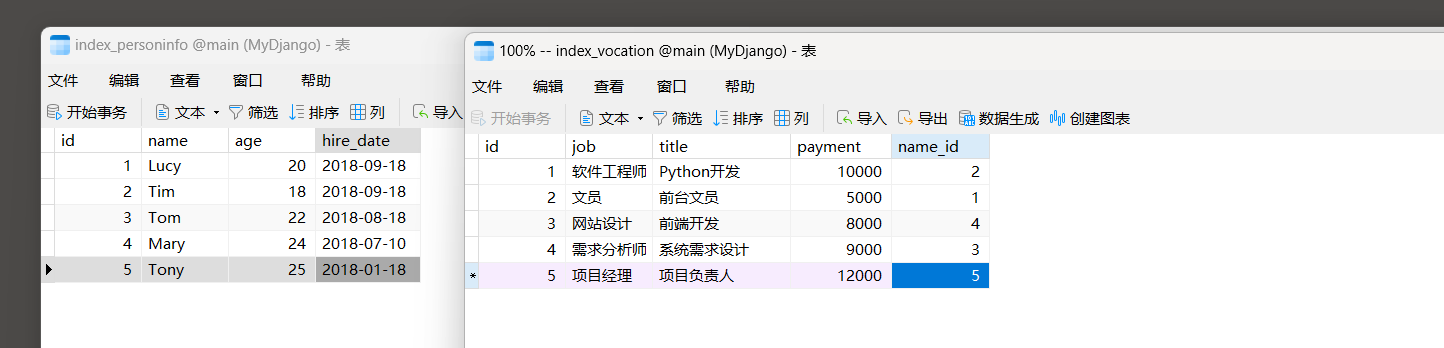
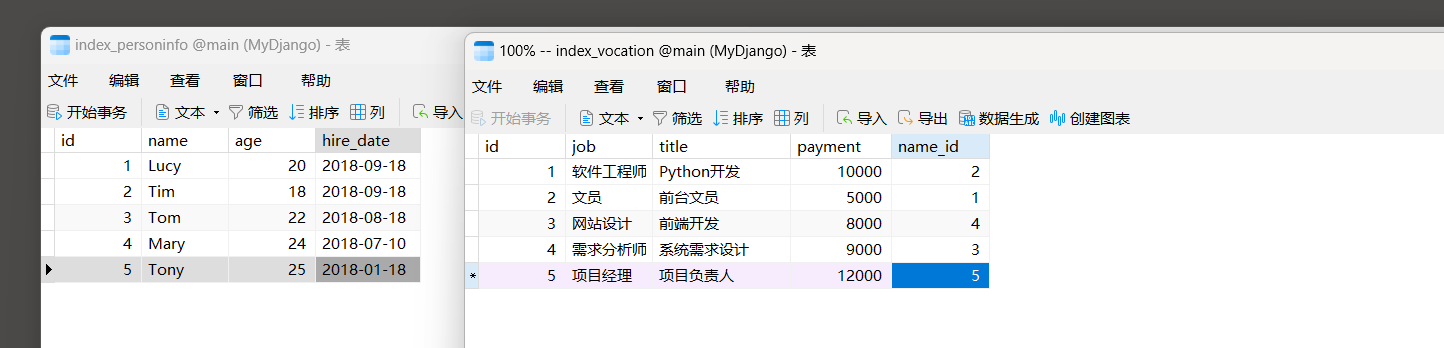
以 7.1 .3 小节的MyDjango为例 , 在数据表index_vocation和index_personinfo中分别添加数据 , 如图 7 - 11 所示 .
图 7 - 11 数据表index_vocation和index_personinfo
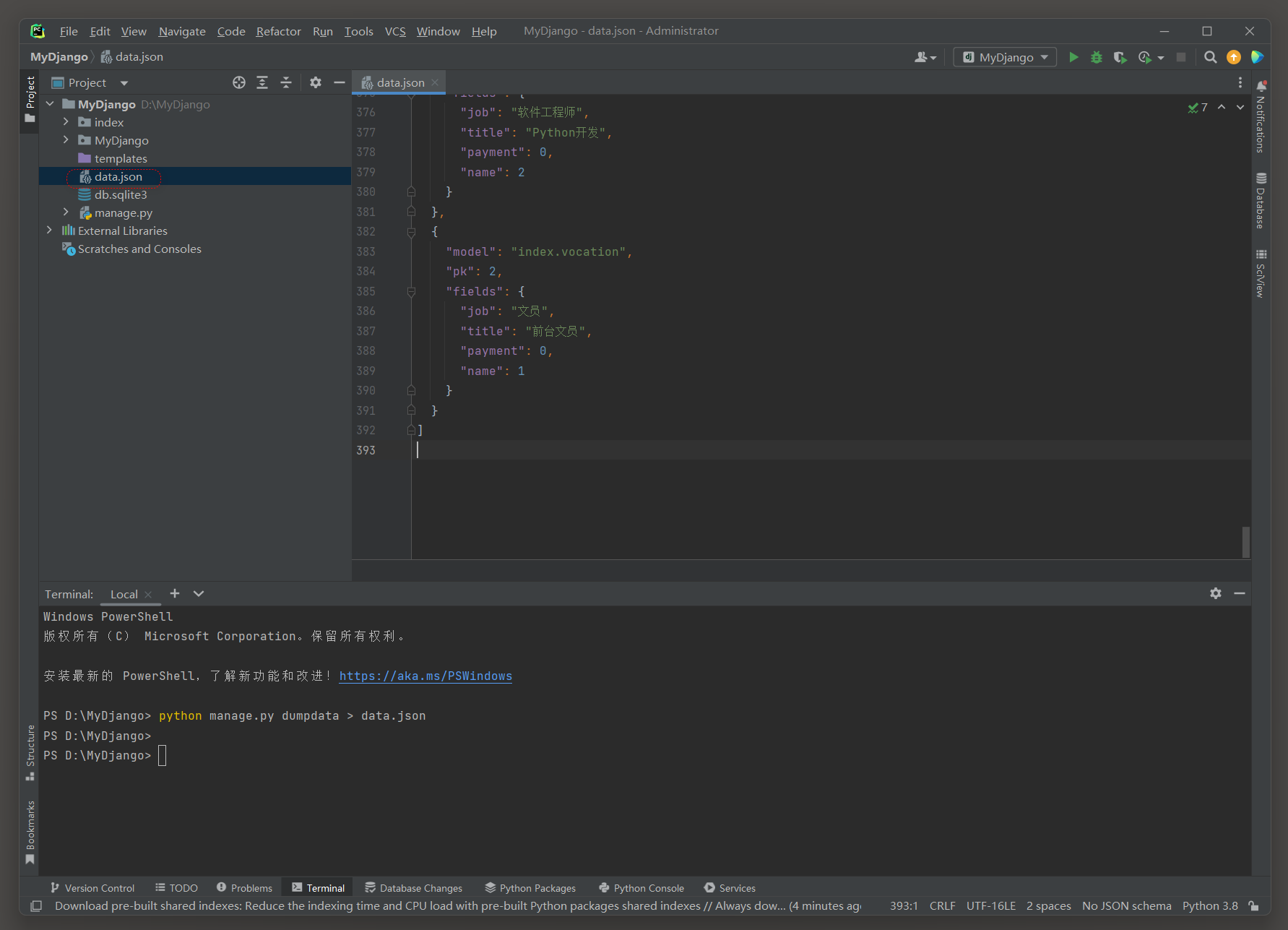
在PyCharm的Terminal窗口输入dumpdata指令 , 将整个项目的数据从数据库里导出并保存到data . json文件 , 其指令如下 :
D: \MyDjango> python manage. py dumpdata > data. json
dumpdata指令末端使用了符号 '>' 和文件名data . json , 这是将项目所有的数据都存放在data . json文件中 ,
并且data . json的文件路径在项目的根目录 ( 与项目的manage . py文件在同一个路径 ) .
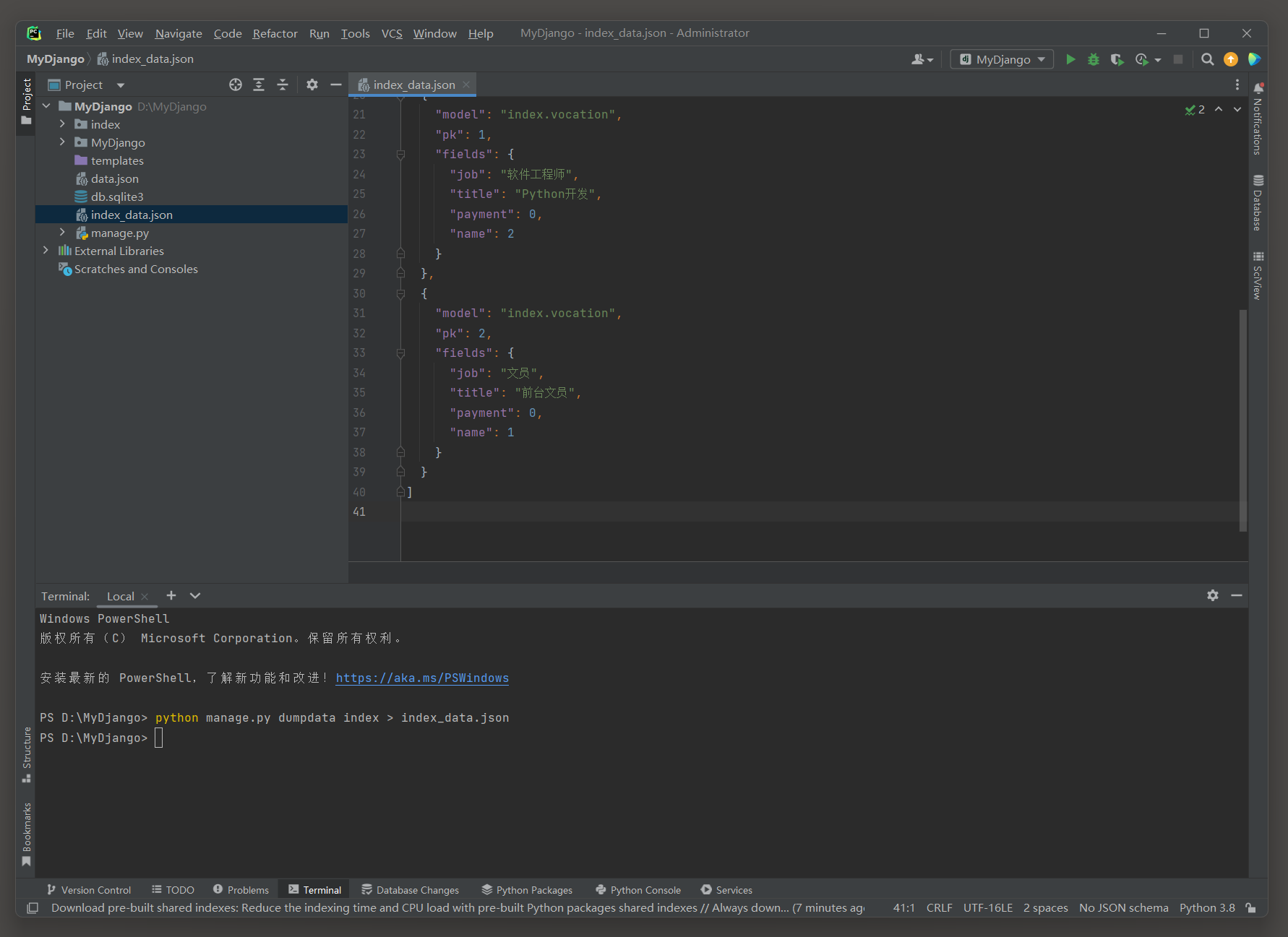
如果只想导出某个项目应用的所有数据或者项目应用里某个模型的数据 ,
那么可在dumpdata指令末端设置项目名称或项目名称的某个模型名称 , 代码如下 :
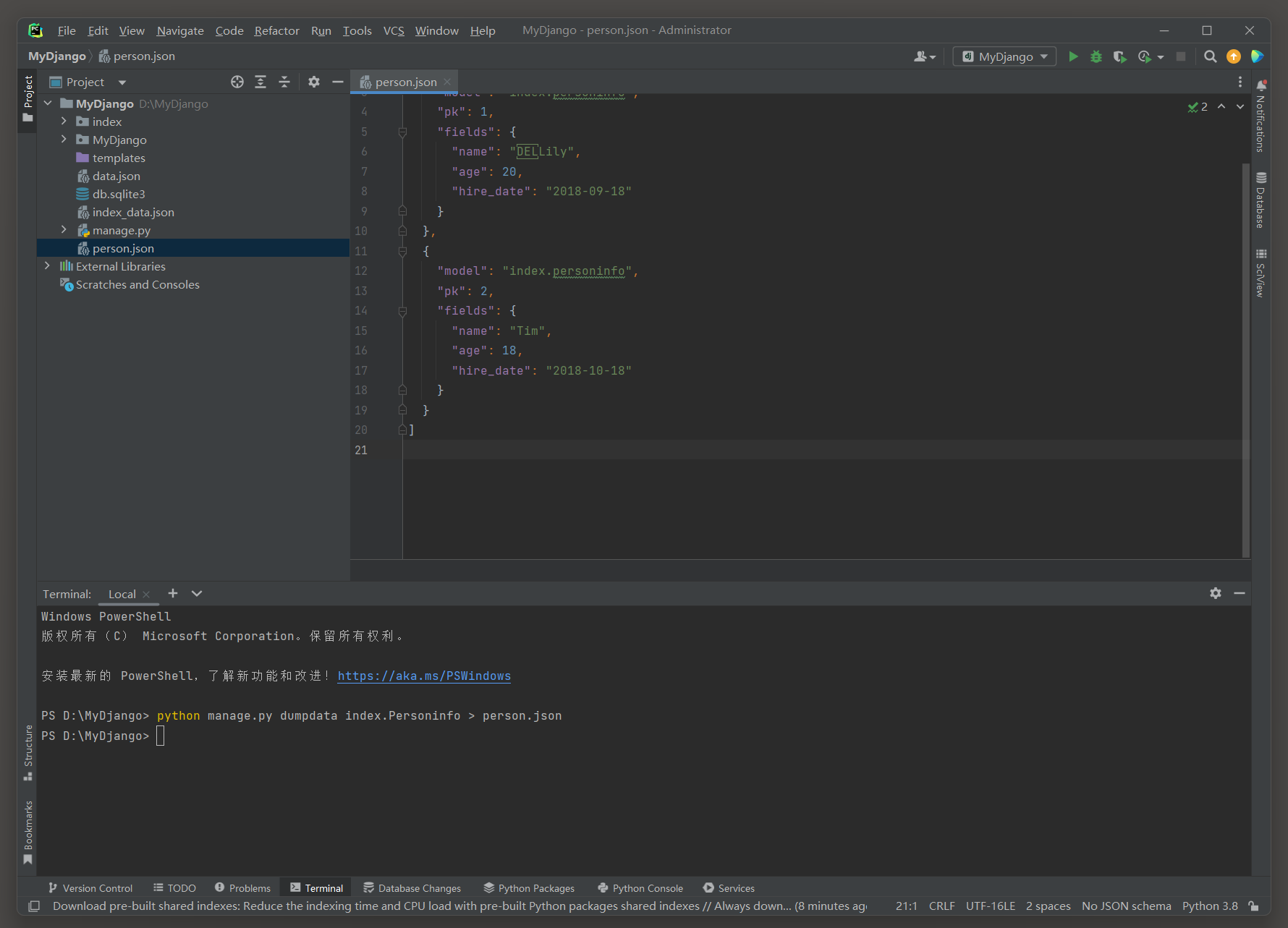
D: \MyDjango> python manage. py dumpdata index > index_data. json
D: \MyDjango> python manage. py dumpdata index. Personinfo > person. json
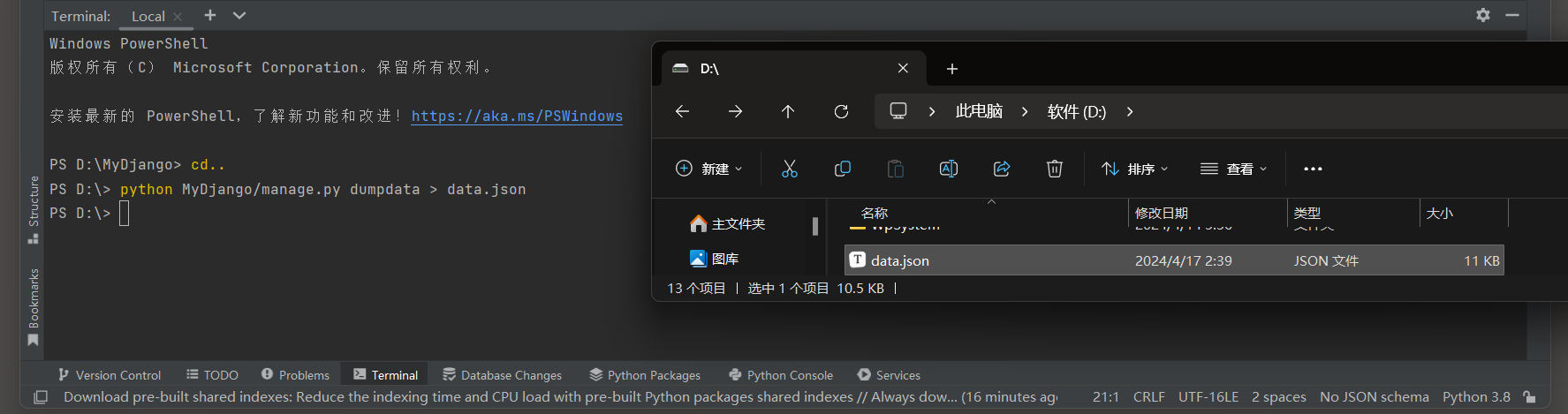
一般情况下 , 使用dumpdata指令导出的数据文件都存放在项目的根目录 ,
因为在输入指令时 , PyCharm的Terminal窗口的命令行所在路径为项目的根目录 , 若想更换存放路径 ,
则可改变命令行的当前路径 , 比如将数据文件存放在D盘 , 其指令如下 :
D: \MyDjango> cd . .
D: \> python MyDjango/ manage. py dumpdata > data. json
若想将导出的数据文件重新导入数据库里 , 则可使用loaddata指令完成 ,
该指令使用方式相对单一 , 只需在指令末端设置需要导入的文件名即可 :
( 注意看上面的图片 , 导出的文件编码为utf16- 16 le , 导入文件使用Utf- 8 解码会报错 , 需要手动转码 . )
D: \MyDjango> python manage. py loaddata data. json
Installed 44 object ( s) from 1 fixture( s)
loaddata指令根据数据文件的model属性来确定当前数据所属的数据表 , 并将数据插入数据表 , 从而完成数据导入 .
一般情况下 , 数据的导出和导入最好以整个项目或整个项目应用的数据为单位 ,
因为数据表之间可能存在外键关联 , 如果只导入某张数据表的数据 , 就必须考虑该数据表是否设有外键 , 并且外键所关联的数据表是否已有数据 .
一个模型对应数据库的一张数据表 , 但是每张数据表之间是可以存在外键关联的 , 表与表之间有 3 种关联 : 一对一 , 一对多和多对多 .
自关联 ( 或自连接 ) 在关系型数据库中并不是一个独立的表关系类型 , 更多的是一种查询技术或策略 , 用于将同一个表与其自身进行连接 .
从某种角度看 , 自关联可以看作是表与其自身之间的一种特殊的一对多或多对一关系 .
一对一建表原则 : 当两个表之间存在一对一关系时 , 从表的主键作为主表的外键 , 建立主从关系 .
一对多建表原则 : 在从表 ( 多方 , 增加数据 ) 创建一个字段 , 字段作为外键指向主表 ( 一方 , 数据基本固定 ) 的主键 .
多对多关系建表原则 : 需要创建第三张表 , 中间表中至少两个字段 , 这两个字段分别作为外键指向各自一方的主键 .
一对一关系存在于两张数据表中 , 第一张表的某一行数据只与第二张表的某一行数据相关 ,
同时第二张表的某一行数据也只与第一张表的某一行数据相关 , 这种表关系被称为一对一关系 , 以表 7 - 1 和表 7 - 2 为例进行说明 .
学生id(主键) 姓名 班级 教室 1001张三三年级一班3011002李四三年级二班3021003王五三年级三班303
表 7 - 1 一对一关系的第一张表 ( 主表 )
学生信息id(主键) 年龄 联系电话 外键 10013010000-120100110023020000-121100210033030000-1221003
表 7 - 2 一对一关系的第二张表 ( 从表 )
表 7 - 1 和表 7 - 2 的字段ID分别是一一对应的 , 并且不会在同一表中有重复ID ,
使用这种外键关联通常是一张数据表设有太多字段 , 将常用的字段抽取出来并组成一张新的数据表 .
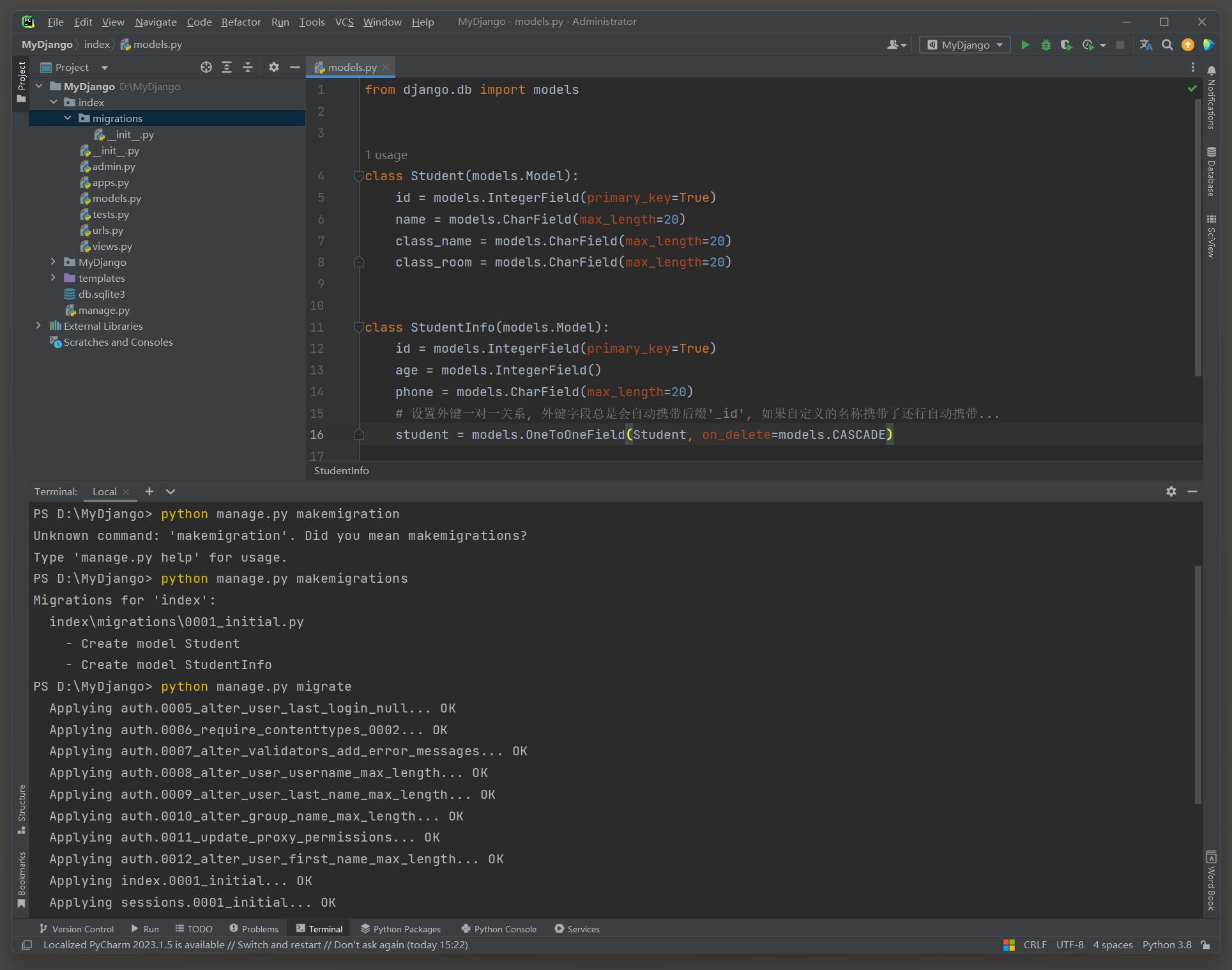
在模型中可以通过OneToOneField来构建数据表的一对一关系 , 代码如下 :
from django. db import models
class Student ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
class_name = models. CharField( max_length= 20 )
class_room = models. CharField( max_length= 20 )
class StudentInfo ( models. Model) :
id = models. IntegerField( primary_key= True )
age = models. IntegerField( )
phone = models. CharField( max_length= 20 )
student = models. OneToOneField( Student, on_delete= models. CASCADE)
对上述模型执行数据迁移 , 在数据库中分别创建数据表Performer和Performer_info ,
打开Navicat Premium查看两张数据表的表关系 , 如图 7 - 12 所示 .
图 7 - 12 数据表关系
一对多关系存在于两张或两张以上的数据表中 , 第一张表的某一行数据可以与第二张表的一到多行数据进行关联 ,
但是第二张表的每一行数据只能与第一张表的某一行进行关联 , 以表 7 - 3 和表 7 - 4 为例进行说明 .
部门id(主键) 名称 简介 1A部门前端2B部门后端3 C部门测试
表 7 - 3 一对多关系的第一张表 ( 主表 )
员工id(主键) 姓名 部门id(外键) 1001张三11002李四11003王五21004赵六21005钱七3
表 7 - 4 一对多关系的第二张表 ( 从表 )
在表 7 - 3 , 7 - 4 中 , ID是唯一的 , 但表 7 - 4 的外键字段ID允许重复 , 字段ID相同的数据对应表 7 - 3 某一行数据 , 这种表关系在日常开发中最为常见 .
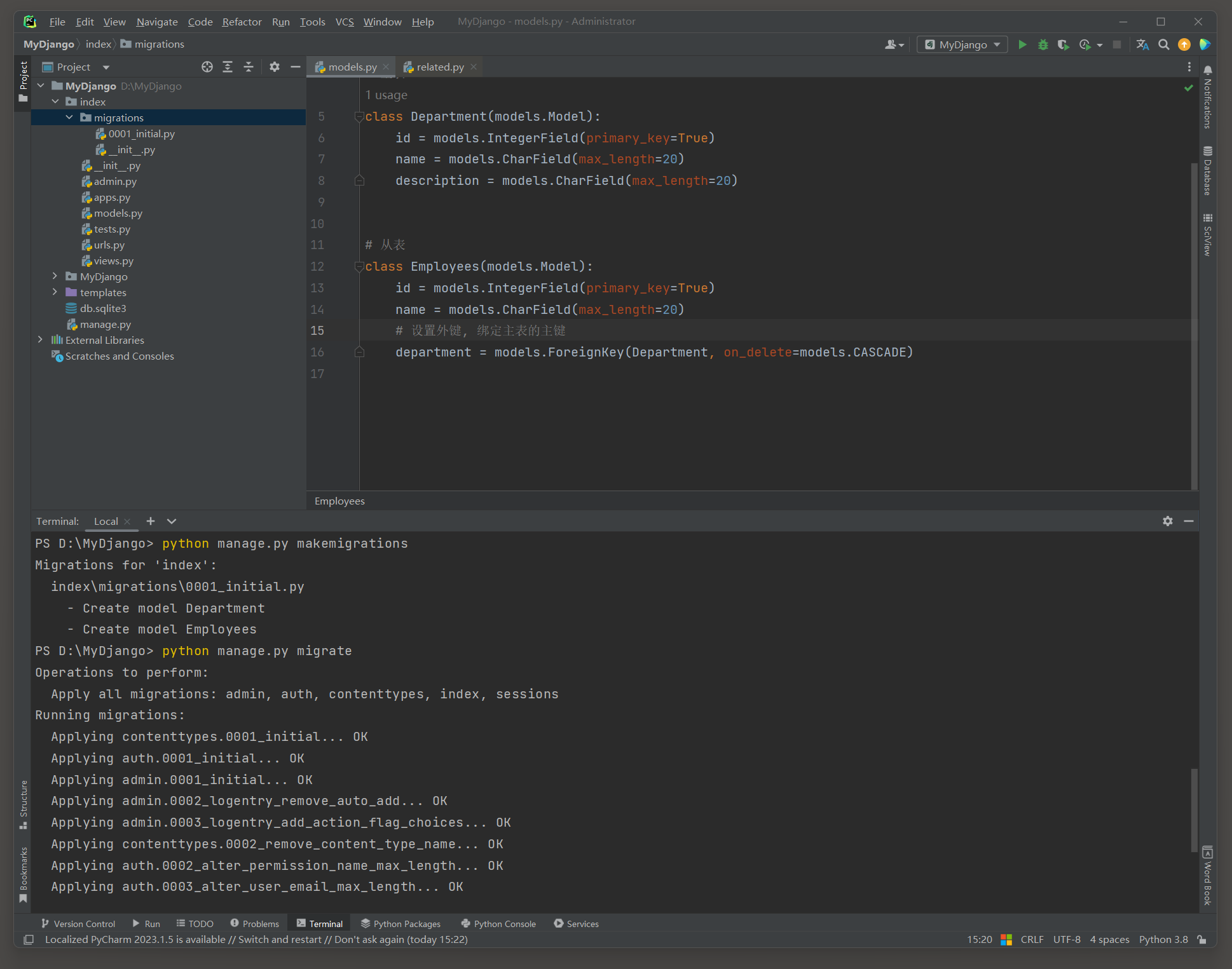
在模型中可以通过ForeignKey来构建数据表的一对多关系 , 代码如下 :
from django. db import models
class Department ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
description = models. CharField( max_length= 20 )
class Employees ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
department = models. ManyToManyField( Department)
删除 0001 _initial . py文件和所有表格 .
对上述模型执行数据迁移 , 在数据库中分别创建数据表Employees和Department ,
然后打开Navicat Premium查看两张数据表的表关系 , 如图 7 - 13 所示 .
图 7 - 13 数据表关系
多对多关系存在于两张或两张以上的数据表中 , 第一张表的某一行数据可以与第二张表的一到多行数据进行关联 ,
同时第二张表中的某一行数据也可以与第一张表的一到多行数据进行关联 , 以表 7 - 5 和表 7 - 6 为例进行说明 .
学生id(主键) 姓名 年龄 1001张三181002李四191003王五20
表 7 - 5 多对多关系的第一张表
课程id 名称 授课老师 2001Python张老师2002Java李老师2003Linux王老师
表 7 - 6 多对多关系的第二张表
表 7 - 5 和表 7 - 6 的数据关系如表 7 - 7 所示 .
序号id 学生id 课程id 110012001210012002310022002410022003510032002
表 7 - 7 两张表的数据关系
在多对多关系中 , 涉及到的三张表通常可以按照其功能和作用进行称呼 .
一般来说 , 这三张表可以分别称为主表 , 关系表和副表或字典表 .
* 1. 主表 : 主表通常存储主要的数据实体信息 .
在多对多关系中 , 主表可能包含一种类型的实体数据 .
例如 , 在一个学生和课程的多对多关系中 , 学生信息表就可以作为主表 .
* 2. 关系表 : 关系表用于记录主表和副表之间的关联关系 .
它通常包含两个外键字段 , 分别指向主表和副表的主键 , 表示它们之间的多对多关联 .
在上面的例子中 , 一个名为 '学生课程关系' 的表就可以作为关系表 , 其中包含学生的ID和课程的ID , 用于记录每个学生选修了哪些课程 .
* 3. 副表或字典表 : 副表或字典表通常存储另一种类型的实体数据 .
与主表类似 , 但它与主表通过关系表进行关联 .
在上面的例子中 , 课程信息表就可以作为副表或字典表 .
从 3 张数据表中可以发现 , 一个学生可以参加选修多个课程 , 而一个课程也可以有多个学生选修 .
表 7 - 5 和表 7 - 6 的字段ID都是唯一的 .
从表 7 - 7 中可以发现 , 学生ID和课程ID出现了重复的数据 , 分别对应表 7 - 5 和表 7 - 6 的字段ID ,
多对多关系需要使用新的数据表来管理两张表的数据关系 .
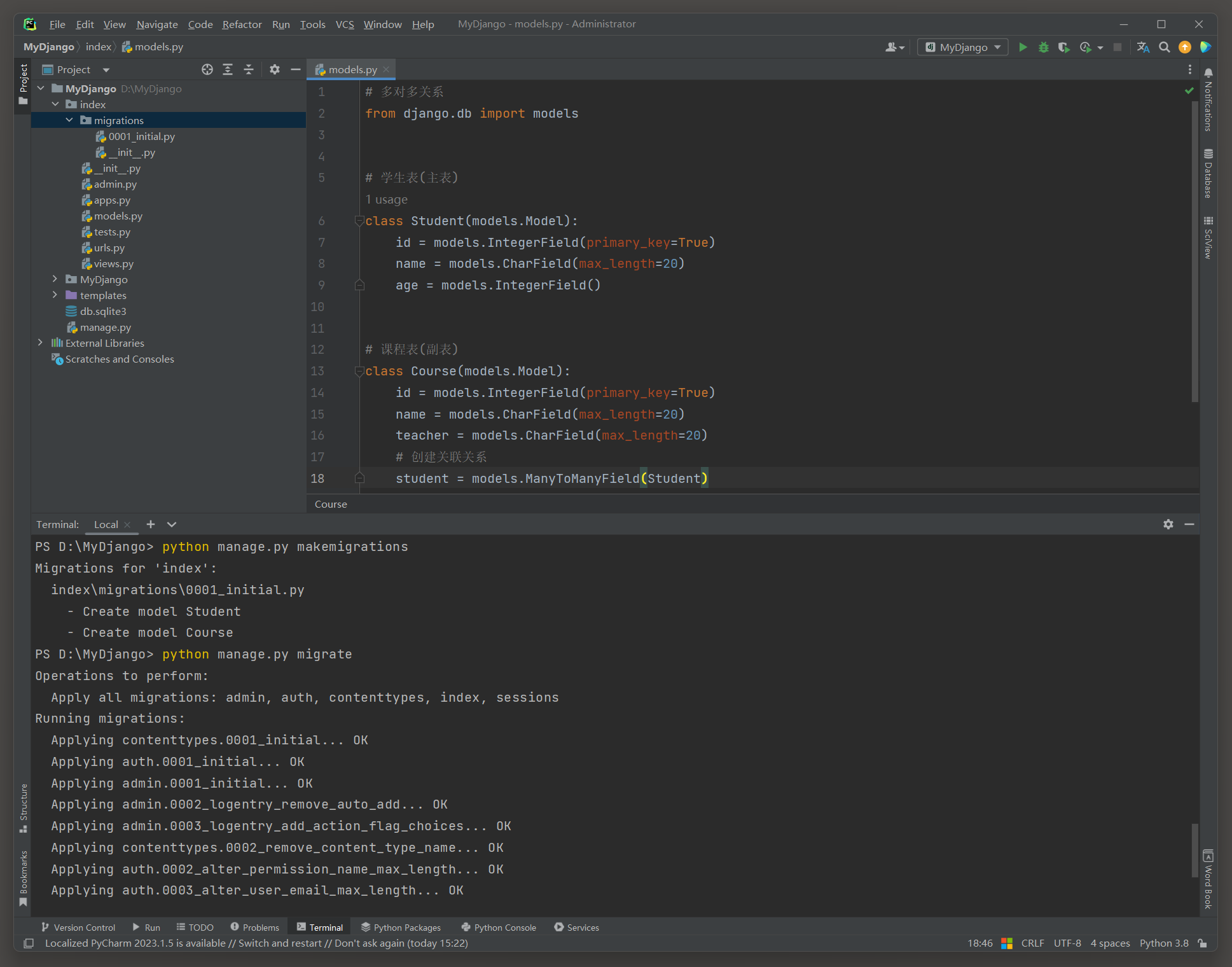
在模型中可以通过ManyToManyField来构建数据表的多对多关系 , 代码如下 :
from django. db import models
class Student ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
age = models. IntegerField( )
class Course ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
teacher = models. CharField( max_length= 20 )
student = models. ManyToManyField( Student)
删除 0001 _initial . py文件和所有表格 .
数据表之间创建多对多关系时 , 只需在项目里定义两个模型对象即可 ,
在执行数据迁移时 , Django自动生成 3 张数据表来建立多对多关系 , 如图 7 - 14 所示 .
图 7 - 14 数据表关系 ( 第三张表的名称 = appname_ + 外键所在表的表名 + _ + 外键字段 = index_course_student . )
综上所述 , 模型之间的关联是由OneToOneField , ForeignKey和ManyToManyField外键字段实现的 ,
每个字段设有特殊的参数 , 参数说明如下 :
● to : 必选参数 , 关联的模型名称 .
● on_delete : 仅限于OneToOneField , ForeignKey , 必选参数 , 设置数据的删除模式 ,
删除模型包括 , CASCADE , PROTECT , SET_NULL , SET_DEFAULT , SET和DO_NOTHING .
● limit_choices_to : 设置外键的下拉框选项 , 用于模型表单和Admin后台系统 .
● related_name : 用于模型之间的关联查询 , 如反向查询 .
● related_query_name : 设置模型的查询名称 , 用于filter或get查询 ,
若设置参数related_name , 则以该参数为默认值 , 若没有设置 , 则以模型名称的小写为默认值 .
● to_field : 设置外键与其他模型字段的关联性 , 默认关联主键 , 若要关联其他字段 , 则该字段必须具有唯一性 .
● db_constraint : 在数据库里是否创建外键约束 , 默认值为True .
● swappable : 设置关联模型的替换功能 , 默认值为True , 比如模型A关联模型B , 想让模型C继承并替换模型B , 使得模型A与模型C之间关联 .
● symmetrical : 仅限于ManyToManyField , 设置多对多字段之间的对称模式 .
● through : 仅限于ManyToManyField , 设置自定义模型C , 用于管理和创建模型A和B的多对多关系 .
● through_fields : 仅限于ManyToManyField , 设置模型C的字段 , 确认模型C的哪些字段用于管理模型A和B的多对多关系 .
● db_table : 仅限于ManyToManyField , 为管理和存储多对多关系的数据表设置表名称 .
在 Django 的早期版本中 , ManyToManyField 的 to 参数确实可以是字符串形式的模型名称 ,
这是为了在定义模型时允许引用尚未定义的模型 .
但是 , 在 Django 的后续版本中 , 这种使用字符串引用模型的方式逐渐被认为是不好的实践 ,
并在 Django 3.1 中被完全废弃了 ( 可以用 , 但是不推荐 ! ) .
from django. db import models
class Student ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
age = models. IntegerField( )
course = models. ManyToManyField( 'Course' )
class Course ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
teacher = models. CharField( max_length= 20 )
自动创建的第三张表的外键默认使用CASCADE级联操作 .
这意味着当关联的一个对象被删除时 , 第三张表中的相关记录也会被删除 .
如果你需要不同的级联行为 , 你应该使用自定义的中间模型 , 并在该模型的ForeignKey字段上明确设置on_delete参数 .
在Django中 , 使用ManyToManyField时 , Django会为自动创建一个中间表来管理两个模型之间的多对多关系 .
但是 , 如果需要更细粒度的控制 , 或者想要手动创建中间表的记录 , 可以通过中间模型 ( 使用through参数指定 ) 来实现 .
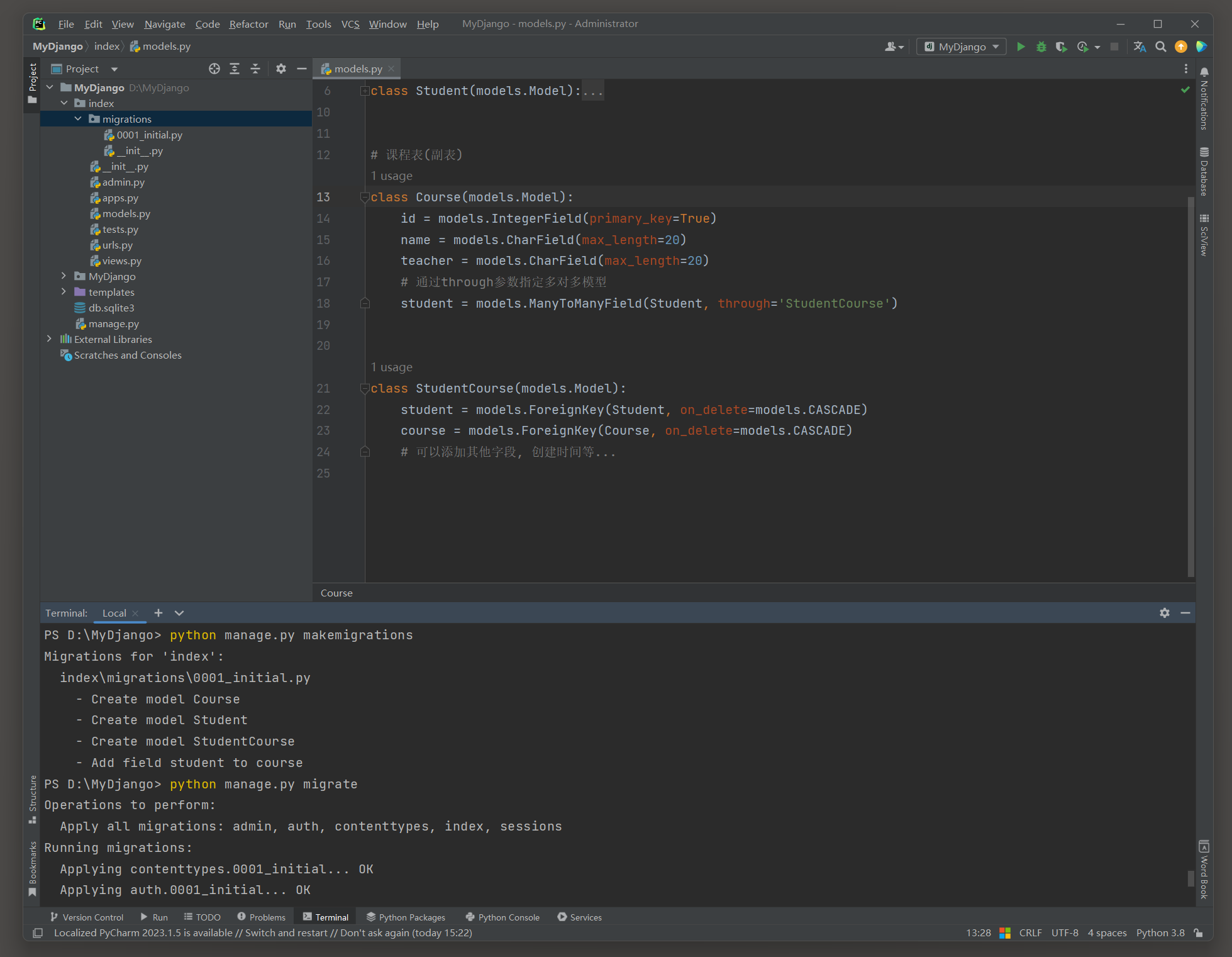
首先 , 定义两个模型 , 并通过ManyToManyField和through参数指定一个中间模型 :
from django. db import models
class Student ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
age = models. IntegerField( )
class Course ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
teacher = models. CharField( max_length= 20 )
student = models. ManyToManyField( Student, through= 'StudentCourse' )
class StudentCourse ( models. Model) :
student = models. ForeignKey( Student, on_delete= models. CASCADE)
course = models. ForeignKey( Course, on_delete= models. CASCADE)
本节讲述如何使用ORM框架实现数据新增 , 修改 , 删除 , 查询 , 执行SQL语句和实现数据库事务等操作 , 具体说明如下 :
● 数据新增 : 由模型实例化对象调用内置方法实现数据新增 , 比如单数据新增调用create , 查询与新增调用get_or_create ,
修改与新增调用update_or_create , 批量新增调用bulk_create .
● 数据修改必须执行一次数据查询 , 再对查询结果进行修改操作 , 常用方法有 : 模型实例化 , update方法和批量更新bulk_update .
● 数据删除必须执行一次数据查询 , 再对查询结果进行删除操作 , 若删除的数据设有外键字段 , 则删除结果由外键的删除模式决定 .
● 数据查询分为单表查询和多表查询 , Django提供多种不同查询的API方法 , 以满足开发需求 .
● 执行SQL语句有 3 种方法实现 , extra , raw和execute , 其中extra和raw只能实现数据查询 , 具有一定的局限性 ;
而execute无须经过ORM框架处理 , 能够执行所有SQL语句 , 但很容易受到SQL注入攻击 .
● 数据库事务是指作为单个逻辑执行的一系列操作 , 这些操作具有原子性 , 即这些操作要么完全执行 , 要么完全不执行 ,
常用于银行转账和火车票抢购等 .
Django对数据库的数据进行增 , 删 , 改操作是借助内置ORM框架所提供的API方法实现的 ,
简单来说 , ORM框架的数据操作API是在QuerySet类里面定义的 , 然后由开发者自定义的模型对象调用QuerySet类 , 从而实现数据操作 .
以 7.1 .3 小节的MyDjango为例 , 分别在数据表index_personinfo和index_vocation中添加数据 , 如图 7 - 15 所示 .
图 7 - 15 数据表index_personinfo和index_vocation ( 数据保持在配置资源内了 )
为了更好地演示数据库的增 , 删 , 改操作 ,
在MyDjango项目使用Shell模式 ( 启动命令行和执行脚本 ) 进行讲述 , 该模式方便开发人员开发和调试程序 .
在PyCharm的Terminal下开启Shell模式 , 输入 : python manage . py shell 指令即可开启 , 如图 7 - 16 所示 .
图 7 - 16 启动Shell模式
在Shell模式下 , 若想对数据表index_vocation插入数据 , 则可输入以下代码实现 :
>> > from index. models import *
>> > v = Vocation( )
>> > v. job = '测试工程师'
>> > v. title = '系统测试'
>> > v. payment = 0
>> > v. name_id = 3
>> > v. save( )
>> > v. id
6
上述代码是对模型Vocation进行实例化 , 再对实例化对象的属性进行赋值 , 从而实现数据表index_vocation的数据插入 , 代码说明如下 :
( 1 ) 从项目应用index的models . py文件中导入模型Vocation .
( 2 ) 对模型Vocation声明并实例化 , 生成对象v .
( 3 ) 对对象v的属性进行逐一赋值 , 对象v的属性来自于模型Vocation所定义的字段 .
完成赋值后 , 再由对象v调用save方法进行数据保存 .
save ( ) 方法返回的是一个元组 , 其中第一个元素是已存在的对象或新创建的对象 , 第二个元素是一个布尔值 , 表示是否创建了新对象 .
需要注意的是 , 模型Vocation的外键命名为name , 但在数据表index_vocation中变为name_id ,
因此对象v设置外键字段name的时候 , 外键字段应以数据表的字段名为准 ( 外键都需要在name后加_id ) .
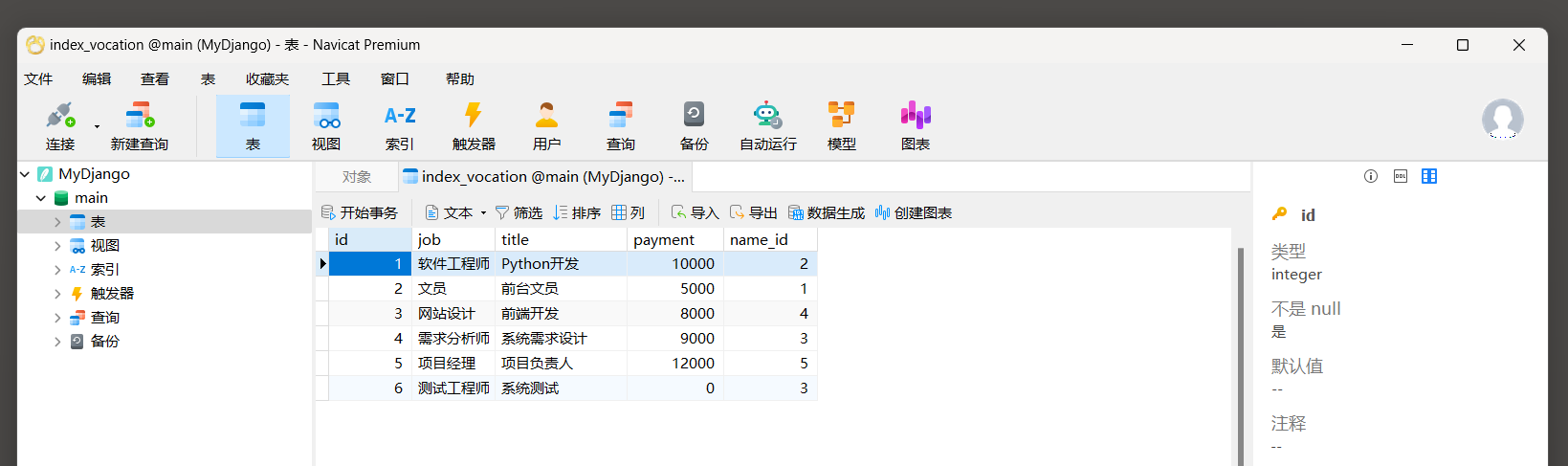
上述代码运行结束后 , 在数据表index_vocation里查看数据的插入情况 , 如图 7 - 17 所示 .
图 7 - 17 数据入库
在Django框架中 , 每个模型 ( Model ) 类都默认拥有一个名为objects的属性 , 它是一个Manager对象 .
Manager类提供了数据库查询的接口 , 使得开发者能够方便地与数据库进行交互 .
以下是一些常用的objects方法 :
all ( ) : 返回模型表中所有的对象 .
all_objects = MyModel . objects . all ( )
filter ( ) : 根据给定的条件过滤对象 .
filtered_objects = MyModel . objects . filter ( field_name = 'value' )
get ( ) : 返回满足条件的单个对象 . 如果找到多个对象或没有对象 , 它会引发异常 .
single_object = MyModel . objects . get ( field_name = 'value' )
exclude ( ) : 排除满足条件的对象 .
excluded_objects = MyModel . objects . exclude ( field_name = 'value' )
order_by ( ) : 对查询结果进行排序 .
ordered_objects = MyModel . objects . order_by ( 'field_name' )
values ( ) : 返回一个包含字典的QuerySet , 每个字典表示一个对象 , 字典的键是字段名 .
values_list = MyModel . objects . values ( 'field1' , 'field2' )
values_list ( ) : 返回一个包含元组的QuerySet , 每个元组表示一个对象 , 元组的元素是字段的值 .
values_list = MyModel . objects . values_list ( 'field1' , 'field2' )
count ( ) : 返回查询结果中的对象数量 .
count = MyModel . objects . count ( )
first ( ) 和 last ( ) : 分别返回查询结果中的第一个和最后一个对象 .
first_object = MyModel . objects . first ( )
last_object = MyModel . objects . last ( )
exists ( ) : 如果查询结果中存在任何对象 , 返回True .
exists = MyModel . objects . filter ( field_name = 'value' ) . exists ( )
create ( ) :创建一个新对象并保存到数据库中。
new_object = MyModel . objects . create ( field_name = 'value' )
update ( ) :更新满足条件的对象的字段值。
MyModel . objects . filter ( field_name = 'old_value' ) . update ( field_name = 'new_value' )
delete ( ) :删除满足条件的对象。
MyModel . objects . filter ( field_name = 'value' ) . delete ( )
这些只是objects管理器提供的一些常用方法 , Django ORM还提供了许多其他功能强大的查询方法和表达式 , 可以根据具体需求进行组合使用 .
除了上述方法外 , 数据插入还有以下 3 种常见方法 , 代码如下 :
>> > v = Vocation. objects. create( job = '测试工程师' , title = '系统测试' , payment = 0 , name_id = 3 )
>> > v. id
>> > d = dict ( job = '测试工程师' , title = '系统测试' , payment = 0 , name_id = 3 )
>> > v = Vocation. objects. create( ** d)
>> > v. id
>> > v= Vocation( job = '测试工程师' , title = '系统测试' , payment = 0 , name_id = 3 )
>> > v. save( )
>> > v. id
执行数据插入时 , 为了保证数据的有效性 , 我们需要对数据进行去重判断 , 确保数据不会重复插入 .
以往的方案都是对数据表进行查询操作 , 如果查询的数据不存在 , 就执行数据插入操作 .
为了简化这一过程 , Django提供了get_or_create方法 , 使用如下 :
>> > d = dict ( job = '测试工程师' , title = '系统测试' , payment = 10 , name_id = 3 )
>> > v = Vocation. objects. get_or_create( ** d)
>> > v
( < Vocation: 7 > , True )
>> > v[ 0 ]
< Vocation: 7 >
>> > v[ 0 ] . id
7
get_or_create根据每个模型字段的值与数据表的数据进行判断 , 判断方式如下 :
● 只要有一个模型字段的值与数据表的数据不相同 ( 除主键之外 ) , 就会执行数据插入操作 .
● 如果每个模型字段的值与数据表的某行数据完全相同 , 就不执行数据插入 , 而是返回这行数据的数据对象 ,
比如对上述的字典d重复执行get_or_create , 第一次是执行数据插入 ( 若执行结果显示为True , 则代表数据插入 ) ,
第二次是返回数据表已有的数据信息 ( 若执行结果显示为False , 则数据表已存在数据 , 不再执行数据插入 ) , 如图 7 - 18 所示 .
>> > d = dict ( job = '测试工程师' , title = '系统测试' , payment = 11 , name_id = 3 )
>> > v = Vocation. objects. get_or_create( ** d)
>> > v
( < Vocation: 8 > , True )
>> > d = dict ( job = '测试工程师' , title = '系统测试' , payment = 11 , name_id = 3 )
>> > v = Vocation. objects. get_or_create( ** d)
>> > v
( < Vocation: 8 > , False )
图 7 - 18 执行结果
除了get_or_create之外 , Django还定义了update_or_create方法 , 这是判断当前数据在数据表里是否存在 .
若存在 , 则进行更新操作 , 否则在数据表里新增数据 , 使用说明如下 :
>> > d = dict ( job = '软件工程师' , title = 'Java开发' , payment = 8000 , name_id = 2 )
>> > v = Vocation. objects. update_or_create( ** d)
>> > v
( < Vocation: 9 > , True )
>> > v = Vocation. objects. update_or_create( ** d, defaults = { 'title' : 'Java' } )
>> > v
( < Vocation: 9 > , False )
>> > v[ 0 ] . title
'Java'
update_or_create是根据字典d的内容查找数据表的数据 , 如果能找到相匹配的数据 ,
就执行数据修改 , 修改内容以字典格式传递给参数defaults即可 ;
如果在数据表找不到匹配的数据 , 就将字典d的数据插入数据表里 .
如果要对某个模型执行数据批量插入操作 , 那么可以使用bulk_create方法实现 ,
只需将数据对象以列表或元组的形式传入bulk_create方法即可 :
>> > v1 = Vocation( job = '财务' , title = '会计' , payment = 0 , name_id = 1 )
>> > v2 = Vocation( job = '财务' , title = '出纳' , payment = 0 , name_id = 1 )
>> > ojb_list = [ v1, v2]
>> > v = Vocation. objects. bulk_create( ojb_list)
>> > v
[ < Vocation: None > , < Vocation: None > ]
>> > v = Vocation. objects. bulk_create( ojb_list)
>> > v
[ < Vocation: None > , < Vocation: None > ]
在使用bulk_create之前 , 数据类型为模型Vocation的实例化对象 ,
并且在实例化过程中设置每个字段的值 , 最后将所有实例化对象放置在列表或元组里 ,
以参数的形式传递给bulk_create , 从而实现数据的批量插入操作 .
数据修改的步骤与数据插入的步骤大致相同 , 唯一的区别在于数据对象来自数据表 ,
因此需要执行一次数据查询 , 查询结果以对象的形式表示 , 并将对象的属性进行赋值处理 , 代码如下 :
>> > v = Vocation. objects. get( id = 1 )
>> > v
< Vocation: 1 >
>> > v. payment = 20000
>> > v. save( )
上述代码获取数据表index_vocation里主键id等于 1 的数据对象v , 然后修改数据对象v的payment属性 , 从而完成数据修改操作 .
打开数据表index_vocation查看数据修改情况 , 如图 7 - 19 所示 .
图 7 - 19 运行结果
除此之外 , 还可以使用update方法实现数据修改 , 使用方法如下 :
>> > Vocation. objects. filter ( job = '测试工程师' ) . update( job = '测试员' )
1
>> > d= dict ( job = '测试员' )
>> > Vocation. objects. filter ( job = '测试工程师' ) . update( ** d)
0
>> > Vocation. objects. update( payment = 6666 )
16
>> > from django. db. models import F
>> > v = Vocation. objects. filter ( job = '测试员' )
>> > v. update( payment = F( 'payment' ) + 1 )
1
在Django 2.2 或以上版本新增了数据批量更新方法bulk_update , 它的使用与批量新增方法bulk_create相似 , 使用说明如下 :
( bulk_update方法接受两个主要的参数 :
一个对象列表 , 这些对象是想要更新的数据库记录 .
一个字段名列表 , 这些是想要更新的字段 . 其他字段 , 即使有变化 , 也不会被更新到数据库中 .
这个方法允许你一次性更新多个对象的某些字段 , 而不是分别对每个对象调用save ( ) 方法 , 显著减少与数据库的交互次数 , 从而提高性能 . )
>> > v1 = Vocation. objects. create( job = '财务' , title = '会计' , name_id = 1 )
>> > v2 = Vocation. objects. create( job = '财务' , title = '出纳' , name_id = 1 )
>> > v1. payment = 1000
>> > v2. title = '行政'
>> > Vocation. objects. bulk_update( [ v1, v2] , fields = [ 'payment' , 'title' ] )
数据删除有 3 种方式 : 删除一行数据 , 删除多行数据和删除数据表的全部数据 , 实现方式如下 :
( delete ( ) 方法通常会返回一个元组 , 包含两个元素 :
第一个元素 : 是一个整数 , 表示被删除的记录数 .
第二个元素 : 是一个字典 , 其中的键是被删除对象所代表的模型的名称 , 值是被删除的记录数 . )
>> > Vocation. objects. get( id = 1 ) . delete( )
( 1 , { 'index.Vocation' : 1 } )
>> > Vocation. objects. filter ( job = '财务' ) . delete( )
( 8 , { 'index.Vocation' : 8 } )
>> > Vocation. objects. all ( ) . delete( )
( 4 , { 'index.Vocation' : 4 } )
删除数据的过程中 , 如果删除的数据设有外键字段 , 就会同时删除外键关联的数据 .
比如删除数据表index_personinfo里主键等于 3 的数据 ( 简称为数据A ) , 在数据表index_vocation里 ,
有些数据 ( 简称为数据B ) 关联了数据A , 那么在删除数据A时 , 也会同时删除数据B , 代码如下 :
>> > PersonInfo. objects. get( id = 3 ) . delete( )
>> > ( 2 , { 'index.Vocation' : 1 , 'index.PersonInfo' : 1 } )
从 7.2 节得知 , 外键字段的参数on_delete用于设置数据删除模式 , 比如上述例子的模型Vocation将外键字段name设为CASCADE模式 ,
不同的删除模式会影响数据删除结果 , 说明如下 :
● PROTECT模式 : 如果删除的数据设有外键字段并且关联其他数据表的数据 , 就提示数据删除失败 .
● SET_NULL模式 : 执行数据删除并把其他数据表的外键字段设为Null , 外键字段必须将属性Null设为True , 否则提示异常 .
● SET_DEFAULT模式 : 执行数据删除并把其他数据表的外键字段设为默认值 .
● SET模式 : 执行数据删除并把其他数据表的外键字段关联其他数据 .
● DO_NOTHING模式 , 不做任何处理 , 删除结果由数据库的删除模式决定 .
在修改数据时 , 往往只修改某行数据的内容 , 因此在修改数据之前还要对模型进行查询操作 ,
确定数据表某行的数据对象 , 最后才执行数据修改操作 .
我们知道数据库设有多种数据查询方式 , 如单表查询 , 多表查询 , 子查询和联合查询等 ,
而Django的ORM框架对不同的查询方式定义了相应的API方法 .
将数据恢复成这样 . . . .
以数据表index_personinfo和index_vocation为例 ,
在MyDjango项目的Shell模式下使用ORM框架提供的API方法实现数据查询 .
>> > from index. models import *
>> > Vocation. objects. all ( )
< QuerySet [ < Vocation: 1 > , < Vocation: 2 > , < Vocation: 3 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > v = Vocation. objects. all ( )
>> > v
< QuerySet [ < Vocation: 1 > , < Vocation: 2 > , < Vocation: 3 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > v[ 0 ]
< Vocation: 1 >
v[ 0 ]
>> > v[ 0 ] . job
'软件工程师'
def __str__ ( self) :
return self. name
>> > P = PersonInfo. objects. all ( )
>> > P
< QuerySet [ < PersonInfo: Lucy> , < PersonInfo: Tim> , < PersonInfo: Mary> , < PersonInfo: Tony> , < PersonInfo: Tom> ] >
def __str__ ( self) :
return str ( self. id )
>> > v = Vocation. objects. all ( )
>> > v
< QuerySet [ < Vocation: 1 > , < Vocation: 2 > , < Vocation: 3 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > v = Vocation. objects. all ( ) [ : 3 ]
>> > v
< QuerySet [ < Vocation: 1 > , < Vocation: 2 > , < Vocation: 3 > ] >
>> > v = Vocation. objects. values( 'job' )
>> > v
< QuerySet [ { 'job' : '软件工程师' } , { 'job' : '文员' } , { 'job' : '网站设计' } , { 'job' : '需求分析师' } , { 'job' : '项目经理' } ] >
>> > v[ 1 ] [ 'job' ]
'文员'
>> > v = Vocation. objects. values_list( 'job' ) [ : 3 ]
>> > v
< QuerySet [ ( '软件工程师' , ) , ( '文员' , ) , ( '网站设计' , ) ] >
value方法通常用于获取特定字段的值 , 通常返回一个字典集合 , < QuerySet [ { 'job' : '软件工程师' } , { 'job' : '文员' } , . . . ] >
filter方法则用于筛选满足某些条件的记录 , 并返回一个记录对象的集合 , < QuerySet [ < Vocation : 1 > , < Vocation : 2 > , . . . >
>> > v = Vocation. objects. get( id = 2 )
>> > v
< Vocation: 2 >
>> > v. job
'文员'
>> > v = Vocation. objects. get( id = 2 , job = '文员' )
>> > v
< Vocation: 2 >
>> > v. job
'文员'
>> > v = Vocation. objects. filter ( id = 2 )
>> > v
< QuerySet [ < Vocation: 2 > ] >
>> > v[ 0 ] . job
>> > v = Vocation. objects. filter ( job= '网站设计' , id = 3 )
>> > v
< QuerySet [ < Vocation: 3 > ] >
>> > d= dict ( job= '网站设计' , id = 3 )
>> > v = Vocation. objects. filter ( ** d)
>> > from django. db. models import Q
>> > v = Vocation. objects. filter ( Q( job = '网站设计' ) | Q( id = 4 ) )
>> > v
< QuerySet [ < Vocation: 3 > , < Vocation: 4 > ] >
>> > v = Vocation. objects. filter ( ~ Q( job = '网站设计' ) )
>> > v
< QuerySet [ < Vocation: 1 > , < Vocation: 2 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > v = Vocation. objects. exclude( job = '网站设计' )
>> > v
< QuerySet [ < Vocation: 1 > , < Vocation: 2 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > v = Vocation. objects. filter ( job = '网站设计' ) . count( )
1
>> > v = Vocation. objects. values( 'job' ) . filter ( job = '网站设计' ) . distinct( )
>> > v
< QuerySet [ { 'job' : '网站设计' } ] >
>> > v = Vocation. objects. order_by( '-id' )
>> > v
< QuerySet [ < Vocation: 5 > , < Vocation: 4 > , < Vocation: 3 > , < Vocation: 2 > , < Vocation: 1 > ] >
>> > v = Vocation. objects. order_by( 'payment' )
>> > for i in v:
. . . i. payment
. . .
5000
8000
9000
10000
12000
聚合查询 , 实现对数据值求和 , 求平均值等 , 由annotate ( 分组使用 ) 和aggregate ( 不分组使用 ) 方法实现 .
annotate类似于SQL里面的GROUP BY方法 .
annotate方法允许你为每个对象添加聚合计算的字段 , 并返回一个新的查询集 ,
这个查询集中的每个对象都包含这些额外的聚合字段 .
这对于按组进行统计特别有用 , 例如计算每个组的平均值 , 总和等 .
aggregate方法用于在整个查询集上执行聚合操作 , 并返回一个包含聚合结果的字典 .
它主要用于计算跨所有对象的统计信息 , 例如计数 , 总和 , 平均值等 .
aggregate的结果是一个字典 , 其中每个键是聚合操作的别名 , 值是相应的聚合结果 .
annotate和aggregate方法中的表达式可以赋值给一个变量 , 这个变量的名称则是别名 .
>> > from django. db. models import Sum
>> > v = Vocation. objects. values( 'job' ) . annotate( Sum( 'id' ) )
>> > print ( v. query)
SELECT "index_vocation" . "job" , SUM( "index_vocation" . "id" ) AS "id__sum"
FROM "index_vocation" GROUP BY "index_vocation" . "job"
>> > for i in v:
. . . i
. . .
{ 'job' : '文员' , 'id__sum' : 2 }
{ 'job' : '网站设计' , 'id__sum' : 3 }
{ 'job' : '软件工程师' , 'id__sum' : 1 }
{ 'job' : '需求分析师' , 'id__sum' : 4 }
{ 'job' : '项目经理' , 'id__sum' : 5 }
>> > v = Vocation. objects. values( 'job' ) . annotate( sum_id = Sum( 'id' ) )
>> > v
< QuerySet [ { 'job' : '文员' , 'sum_id' : 2 } , { 'job' : '网站设计' , 'sum_id' : 3 } ,
{ 'job' : '软件工程师' , 'sum_id' : 1 } , { 'job' : '需求分析师' , 'sum_id' : 4 } ,
{ 'job' : '项目经理' , 'sum_id' : 5 } ] >
>> > from django. db. models import Count
>> > from django. db. models import Count
>> > v = Vocation. objects. aggregate( Count( 'id' ) )
>> > v
{ 'id__count' : 5 }
>> > v = Vocation. objects. aggregate( id_count = Count( 'id' ) )
>> > v
{ 'id_count' : 5 }
>> > from django. db. models import Min, Max, Avg
>> > min_payment = Vocation. objects. aggregate( min_payment = Min( 'payment' ) ) [ 'min_payment' ]
>> > min_payment
5000
>> > max_payment = Vocation. objects. aggregate( max_payment = Max( 'payment' ) ) [ 'max_payment' ]
>> > max_payment
12000
>> > avg_payment = Vocation. objects. aggregate( avg_payment = Avg( 'payment' ) ) [ 'avg_payment' ]
>> > avg_payment
8800.0
union , intersection和difference语法用于集合操作 .
>> > v1 = Vocation. objects. filter ( payment__gt= 9000 )
>> > v1
< QuerySet [ < Vocation: 1 > , < Vocation: 5 > ] >
>> > v2 = Vocation. objects. filter ( payment__gt= 5000 )
>> > v2
< QuerySet [ < Vocation: 1 > , < Vocation: 3 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > v1. union( v2)
< QuerySet [ < Vocation: 1 > , < Vocation: 3 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > v1. intersection( v2)
< QuerySet [ < Vocation: 1 > , < Vocation: 5 > ] >
>> > v2. difference( v1)
< QuerySet [ < Vocation: 3 > , < Vocation: 4 > ] >
上述例子讲述了开发中常用的数据查询方法 , 但有时需要设置不同的查询条件来满足多方面的查询要求 .
上述的查询条件filter和get是使用等值的方法来匹配结果 .
若想使用大于 , 不等于或模糊查询的匹配方法 , 则可在查询条件filter和get里使用表 7 - 8 所示的匹配符实现 .
匹配符 使用 说明 __exactfilter(job__exact='开发')精确等于, 如SQL 的 like '开发'__iexactfilter(job_iexact='开发')精确等于并忽略大小写__containsfilter(job_contains='开发')模糊匹配, 如SQL 的 like '%开发%'__icontainsfilter(job_icontains='开发')模糊匹配,忽略大小写__gtfilter(id__gt=5)大于__gtefilter(id__gte=5)大于等于__ltfilter(id__lt=5)小于__ltefilter(id__lte=5)小于等于__infilter(id__in=[1,2,3])判断是否在列表内__startswithfilter(job_startswith='开发')以......开头__istartswithfilter(job_istartswith='开发')以......开头并忽略大小写__endswithfilter(job_endswith='开发')以......结尾__iendswithfilter(job_iendswith='开发')以......结尾并忽略大小写__rangefilter(id__range=[1,10])在......范围内__yearfilter(date__year=2018)日期字段的年份__monthfilter(date__month=12)日期字段的月份_dayfilter(date__day=30)日期字段的天数__isnullfilter(job_isnull=True/False)判断是否为空
表 7 - 8 匹配符的使用及说明
从表 7 - 8 中可以看到 , 只要在查询的字段末端设置相应的匹配符 , 就能实现不同的数据查询方式 .
例如在数据表index_vocation中查询字段payment大于 8000 的数据 , 在Shell模式下使用匹配符__gt执行数据查询 , 代码如下 :
>> > from index. models import *
>> > v = Vocation. objects. filter ( payment__gt= 8000 )
>> > v
< QuerySet [ < Vocation: 1 > , < Vocation: 4 > , < Vocation: 5 > ] >
综上所述 , 在查询数据时可以使用查询条件get或filter实现 , 但是两者的执行过程存在一定的差异 , 说明如下 :
● 查询条件get : 查询字段必须是主键或者唯一约束的字段 , 并且查询的数据必须存在 ,
如果查询的字段有重复值或者查询的数据不存在 , 程序就会抛出异常信息 .
● 查询条件filter : 查询字段没有限制 , 只要该字段是数据表的某一字段即可 .
查询结果以列表形式返回 , 如果查询结果为空 ( 查询的数据在数据表中找不到 ) , 就返回空列表 .
( 在Django的ORM ( 对象关系映射 ) 中 , filter ( ) 方法用于根据给定的条件过滤查询集 ( QuerySet ) ,
返回一个新的查询集 , 其中包含满足条件的所有对象 , 而 . first ( ) 方法则是用来获取查询集中的第一个对象 .
即使在查询预期只有一条数据的情况下 , 使用filter ( ) 方法配合 . first ( ) 通常也是一个更稳健的做法 , 而不是直接使用get ( ) 方法 .
这是因为get ( ) 方法在找不到任何匹配记录时会抛出DoesNotExist异常 ,
这可能会中断程序的正常流程 , 尤其是在处理用户输入或外部数据源时 .
filter ( ) . first ( ) 能更清晰地表达了意图——想要获取查询集中的第一个对象 .
而使用filter ( ) [ 0 ] 来访问查询集中的第一个对象也是不推荐的做法 , 尽管在某些情况下它可能看起来简洁 ,
如果查询集为空 ( 即没有找到任何匹配的对象 ) , 尝试访问 [ 0 ] 会抛出一个IndexError异常 . )
在日常的开发中 , 常常需要对多张数据表同时进行数据查询 .
多表查询需要在数据表之间建立表关系才能够实现 .
一对多或一对一的表关系是通过外键实现关联的 , 而多表查询分为正向查询和反向查询 .
以模型PersonInfo和Vocation为例 , 模型Vocation定义的外键字段name关联到模型PersonInfo .
如果查询对象的主体是模型Vocation , 通过外键字段name去查询模型PersonInfo的关联数据 , 那么该查询称为正向查询 ;
如果查询对象的主体是模型PersonInfo , 要查询它与模型Vocation的关联数据 , 那么该查询称为反向查询 .
在Django中 , 默认的反向查询是通过模型类名的小写形式加上_set来实现的 .
无论是正向查询还是反向查询 , 两者的实现方法大致相同 , 代码如下 :
>> > v = Vocation. objects. filter ( id = 1 ) . first( )
>> > v. name
< PersonInfo: Tim>
>> > v. name. hire_date
datetime. date( 2018 , 9 , 18 )
>> > p = PersonInfo. objects. filter ( id = 2 ) . first( )
>> > v = p. vocation_set. first( )
>> > v. job
'软件工程师'
>> > v = p. vocations. first( )
>> > v. job
修改一下Vocation外键字段的related_name参数 .
这个参数在后续添加 , 可能会报错 :
django . db . utils . OperationalError : foreign key mismatch - "index_vocation" referencing "index_personinfo"
如果出现这个情况备份数据 , 后删除表格和迁移记录 , 重新生成迁移文件 , 在恢复数据 . . .
class Vocation ( models. Model) :
id = models. AutoField( primary_key= True )
job = models. CharField( max_length= 20 )
title = models. CharField( max_length= 20 )
payment = models. IntegerField( null= True , blank= True )
name = models. ForeignKey( PersonInfo, on_delete= models. CASCADE, related_name= 'vocations' )
def __str__ ( self) :
return str ( self. id )
class Meta :
verbose_name = '职业信息'
python manage. py makemigrations
python manage. py migrate
python manage. py shell
>> > from index. models import *
>> > p = PersonInfo. objects. filter ( id = 2 ) . first( )
>> > v = p. personinfo. first( )
>> > v
< Vocation: 1 >
>> > v. job
'软件工程师'
正向查询和反向查询还能在查询条件 ( filter或get ) 里使用 , 这种方式用于查询条件的字段不在查询当前对象里 , 而是在另一张关系表中 ,
比如查询对象为模型Vocation , 查询条件是模型PersonInfo的某个字段 , 对于这种查询可以采用以下方法实现 :
>> > v = Vocation. objects. filter ( name__name= 'Tim' ) . first( )
>> > v. name. hire_date
datetime. date( 2018 , 9 , 18 )
p = PersonInfo. objects. filter ( vocations__job= '网站设计' ) . first( )
>> > v = p. vocations. first( )
>> > v. job
'网站设计'
无论是正向查询还是反向查询 , 它们在数据库里需要执行两次SQL查询 ,
第一次是查询某张数据表的数据 , 再通过外键关联获取另一张数据表的数据信息 .
为了减少查询次数 , 提高查询效率 , 我们可以使用select_related或prefetch_related方法实现 ,
该方法只需执行一次SQL查询就能实现多表查询 .
select_related主要针对一对一和一对多关系进行优化 , 它是使用SQL的JOIN语句进行优化的 ,
通过减少SQL查询的次数来进行优化和提高性能 , 其使用方法如下 :
>> > p = PersonInfo. objects. select_related( 'vocations' ) . values( 'name' , 'vocations__payment' )
>> > print ( p. query)
SELECT "index_personinfo" . "name" , "index_vocation" . "payment"
FROM "index_personinfo"
LEFT OUTER JOIN "index_vocation"
ON ( "index_personinfo" . "id" = "index_vocation" . "name_id" )
>> > p
< QuerySet [ { 'name' : 'Lucy' , 'vocations__payment' : 5000 } , { 'name' : 'Tim' , 'vocations__payment' : 10000 } ,
{ 'name' : 'Mary' , 'vocations__payment' : 8000 } , { 'name' : 'Tony' , 'vocations__payment' : 12000 } ,
{ 'name' : 'Tom' , 'vocations__payment' : 9000 } ] >
>> > v = Vocation. objects. select_related( 'name' ) . values( 'name' , 'name__age' )
>> > print ( v. query)
SELECT "index_vocation" . "name_id" , "index_personinfo" . "age"
FROM "index_vocation"
INNER JOIN "index_personinfo"
ON ( "index_vocation" . "name_id" = "index_personinfo" . "id" )
>> > v
< QuerySet [ { 'name' : 2 , 'name__age' : 18 } , { 'name' : 1 , 'name__age' : 20 } ,
{ 'name' : 4 , 'name__age' : 24 } , { 'name' : 3 , 'name__age' : 22 } ,
{ 'name' : 5 , 'name__age' : 25 } ] >
>> > v = Vocation. objects. select_related( 'name' ) . filter ( payment__gt= 8000 )
>> > print ( v. query)
SELECT "index_vocation" . "id" , "index_vocation" . "job" ,
"index_vocation" . "title" , "index_vocation" . "payment" ,
"index_vocation" . "name_id" , "index_personinfo" . "id" ,
"index_personinfo" . "name" , "index_personinfo" . "age" ,
"index_personinfo" . "hire_date"
FROM "index_vocation"
INNER JOIN "index_personinfo"
ON ( "index_vocation" . "name_id" = "index_personinfo" . "id" )
WHERE "index_vocation" . "payment" > 8000
>> > v
< QuerySet [ < Vocation: 1 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > v[ 0 ] . name. age
18
除此之外 , select_related还可以支持 3 个或 3 个以上的数据表同时查询 , 以下面的例子进行说明 .
from django. db import models
class Province ( models. Model) :
name = models. CharField( max_length= 10 )
def __str__ ( self) :
return str ( self. name)
class City ( models. Model) :
name = models. CharField( max_length= 5 )
province = models. ForeignKey( Province, on_delete= models. CASCADE)
def __str__ ( self) :
return str ( self. name)
class Person ( models. Model) :
name = models. CharField( max_length= 10 )
living = models. ForeignKey( City, on_delete= models. CASCADE)
def __str__ ( self) :
return str ( self. name)
在同一个文件中修改模型 , 在执行数据库迁移会将不存在的模型删除 .
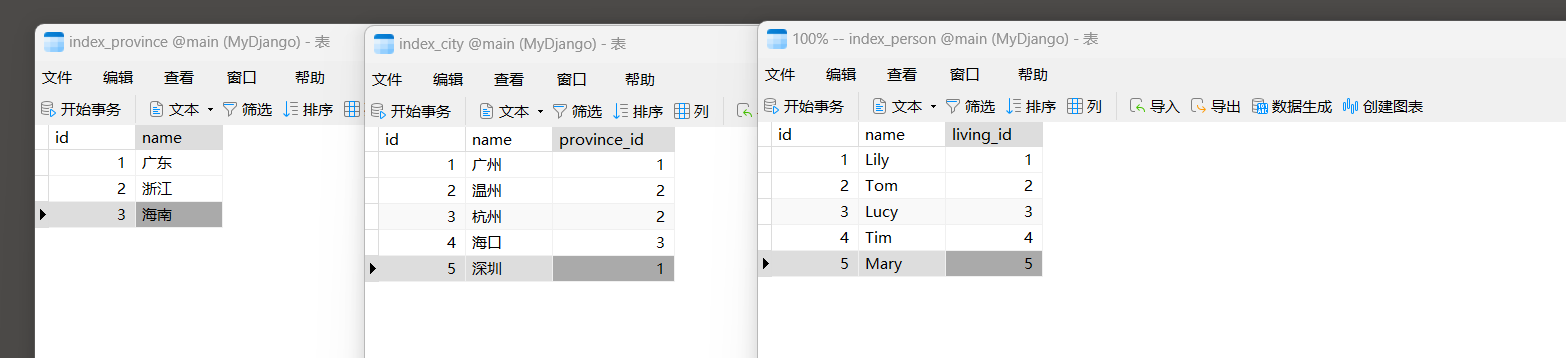
在上述模型中 , 模型Person通过外键living关联模型City , 模型City通过外键province关联模型Province , 从而使 3 个模型形成一种递进关系 .
我们对上述新定义的模型执行数据迁移并在数据表里插入数据 , 如图 7 - 20 所示 .
图 7 - 20 数据表信息
例如 , 查询Tom现在所居住的省份 , 首先通过模型Person和模型City查出Tom所居住的城市 ,
然后通过模型City和模型Province查询当前城市所属的省份 .
因此 , select_related的实现方法如下 :
p = Person. objects. select_related( 'living__province' )
print ( p. query)
SELECT "index_person" . "id" , "index_person" . "name" , "index_person" . "living_id" , "index_city" . "id" , "index_city" . "name" , "index_city" . "province_id" ,
"index_province" . "id" , "index_province" . "name"
FROM "index_person"
INNER JOIN "index_city" ON ( "index_person" . "living_id" = "index_city" . "id" )
INNER JOIN "index_province" ON ( "index_city" . "province_id" = "index_province" . "id" )
>> > p = Person. objects. select_related( 'living__province' ) . get( name= 'Tom' )
>> > p
< Person: Tom>
>> > p. living
< City: 温州>
>> > p. living. province
< Province: 浙江省>
从上述例子可以发现 , 通过设置select_related的参数值可实现 3 个或 3 个以上的多表查询 .
例子中的参数值为living__province , 参数值说明如下 :
● living是模型Person的外键字段 , 该字段指向模型City .
● province是模型City的外键字段 , 该字段指向模型Province .
两个外键字段之间使用双下画线连接 , 在查询过程中 , 模型Person的外键字段living指向模型City ,
再从模型City的外键字段province指向模型Province , 从而实现 3 个或 3 个以上的多表查询 .
prefetch_related和select_related的设计目的很相似 ( 结果一样 ) , 都是为了减少SQL查询的次数 , 但是实现的方式不一样 .
select_related是由SQL的JOIN语句实现的 , 但是对于多对多关系 , 使用select_related会增加数据查询时间和内存占用 ;
而prefetch_related是分别查询每张数据表 , 然后由Python语法来处理它们之间的关系 ,
因此对于多对多关系的查询 , prefetch_related更有优势 .
我们在index的models . py里定义模型Performer和Program , 分别代表人员信息和节目信息 ,
然后对模型执行数据迁移 , 生成相应的数据表 , 模型定义如下 :
from django. db import models
class Performer ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
nationality = models. CharField( max_length= 20 )
def __str__ ( self) :
return str ( self. name)
class Program ( models. Model) :
id = models. IntegerField( primary_key= True )
name = models. CharField( max_length= 20 )
performer = models. ManyToManyField( Performer)
def __str__ ( self) :
return str ( self. name)
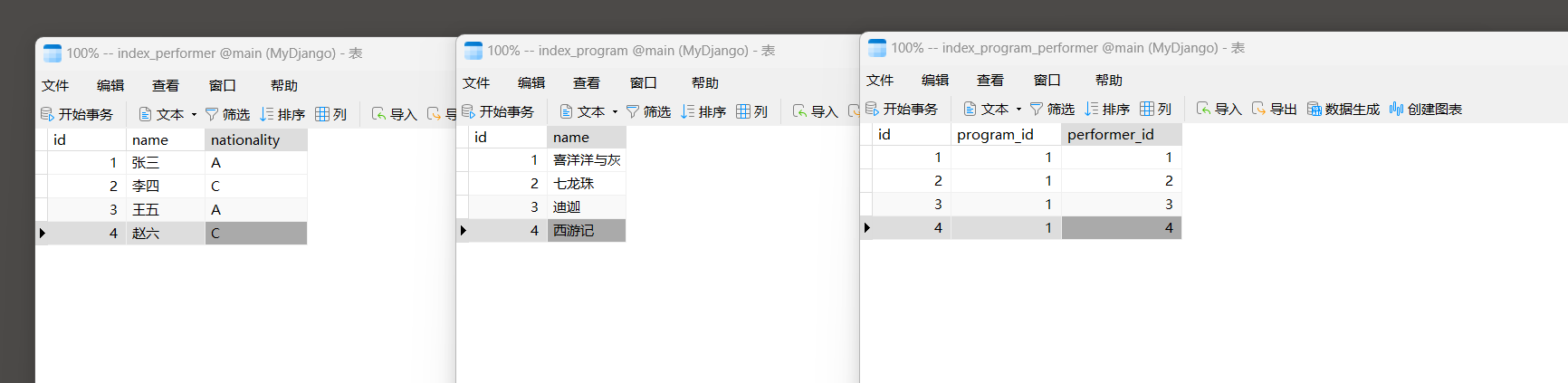
数据迁移成功后 , 在数据表index_performer和index_program中分别添加人员信息和节目信息 ,
然后在数据表index_program_performer中设置多对多关系 , 如图 7 - 21 所示 .
图 7 - 21 数据表信息
例如 , 查询 '喜洋洋与灰太狼' 节目有多少个人员参与演出 ,
首先从节目表index_program里找出 '喜洋洋与灰太狼' 的数据信息 , 然后通过外键字段performer获取参与演出的人员信息 , 实现过程如下 :
>> > p = Program. objects. prefetch_related( 'performer' ) . filter ( name= '喜洋洋与灰太狼' ) . first( )
>> > p
< Program: 喜洋洋与灰太狼>
>> > p. performer. all ( )
< QuerySet [ < Performer: 张三> , < Performer: 李四> , < Performer: 王五> , < Performer: 赵六> ] >
从上述例子看到 , prefetch_related的使用与select_related有一定的相似之处 .
如果是查询一对多关系的数据信息 , 那么两者皆可实现 , 但select_related的查询效率更佳 .
除此之外 , Django的ORM框架还提供很多API方法 , 可以满足开发中各种复杂的需求 ,
由于篇幅有限 , 就不再一一介绍了 , 有兴趣的读者可在官网上查阅 .
Django在查询数据时 , 大多数查询都能使用ORM提供的API方法 ,
但对于一些复杂的查询可能难以使用ORM的API方法实现 , 因此Django引入了SQL语句的执行方法 , 有以下 3 种实现方法 .
● extra : 结果集修改器 , 一种提供额外查询参数的机制 .
● raw : 执行原始SQL并返回模型实例对象 .
● execute : 直接执行自定义SQL .
extra适合用于ORM难以实现的查询条件 , 将查询条件使用原生SQL语法实现 , 此方法需要依靠模型对象 , 在某程度上可防止SQL注入 .
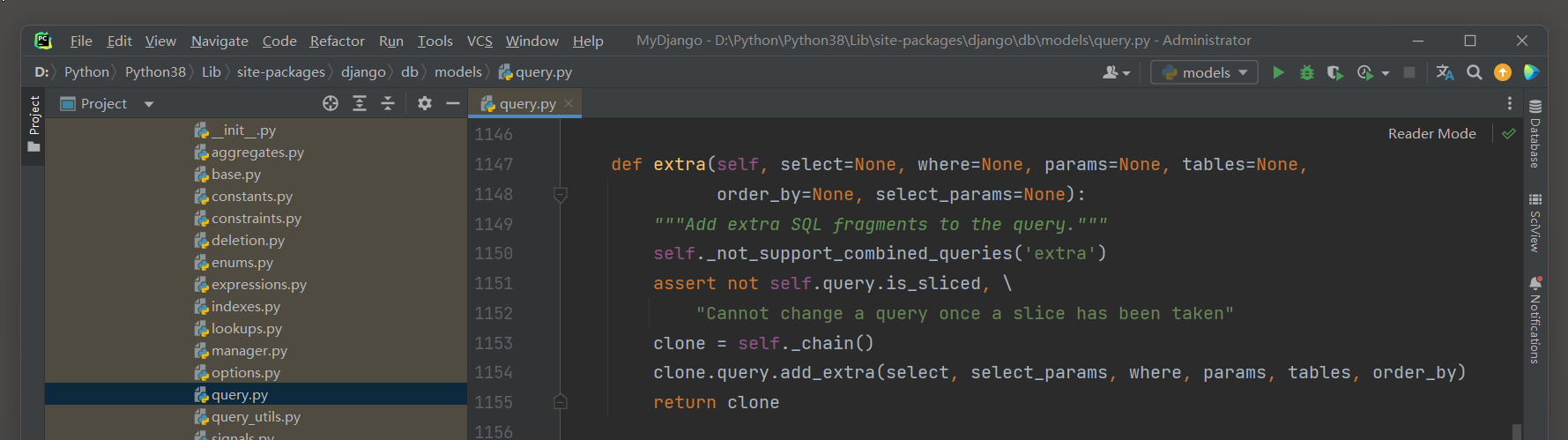
在PyCharm里打开extra源码 , 如图 7 - 22 所示 , 它一共定义了 6 个参数 , 每个参数说明如下 :
● select : 添加新的查询字段 , 即新增并定义模型之外的字段 .
● where : 设置查询条件 .
● params : 如果where设置了字符串格式化 % s , 那么该参数为where提供数值 .
● tables : 连接其他数据表 , 实现多表查询 .
● order_by : 设置数据的排序方式 .
● select_params : 如果select设置字符串格式化 % s , 那么该参数为select提供数值 .
图 7 - 22 extra源码
上述参数都是可选参数 , 我们可根据实际情况选择所需的参数 .
以模型Vocation为例 , 使用extra实现数据查询 , 代码如下 :
>> > v = Vocation. objects. extra( where= [ "job=%s" ] , params= [ '网站设计' ] )
>> > v
< QuerySet [ < Vocation: 3 > ] >
>> > print ( v. query)
SELECT "index_vocation" . "id" , "index_vocation" . "job" , "index_vocation" . "title" ,
"index_vocation" . "payment" , "index_vocation" . "name_id"
FROM "index_vocation" WHERE ( job= 网站设计)
>> > v = Vocation. objects. extra( select= { "seat" : "%s" } , select_params= [ 'seatInfo' ] )
>> > v
< QuerySet [ < Vocation: 1 > , < Vocation: 2 > , < Vocation: 3 > , < Vocation: 4 > , < Vocation: 5 > ] >
>> > print ( v. query)
SELECT ( seatInfo) AS "seat" , "index_vocation" . "id" , "index_vocation" . "job" ,
"index_vocation" . "title" , "index_vocation" . "payment" , "index_vocation" . "name_id"
FROM "index_vocation"
>> > v = Vocation. objects. extra( tables= [ 'index_personinfo' ] )
>> > print ( v. query)
SELECT "index_vocation" . "id" , "index_vocation" . "job" , "index_vocation" . "title" ,
"index_vocation" . "payment" , "index_vocation" . "name_id"
FROM "index_vocation" , "index_personinfo"
v = Vocation. objects. extra(
tables= [ 'index_personinfo' ] ,
where= [ "index_vocation.name_id = index_personinfo.id" ] )
print ( v. query)
SELECT "index_vocation" . "id" , "index_vocation" . "job" , "index_vocation" . "title" ,
"index_vocation" . "payment" , "index_vocation" . "name_id"
FROM "index_vocation" , "index_personinfo"
WHERE ( index_vocation. name_id = index_personinfo. id )
下一步分析raw的语法 , 它和extra所实现的功能是相同的 ,
只能实现数据查询操作 , 并且也要依靠模型对象 , 但从使用角度来说 , raw更为直观易懂 .
在PyCharm里打开raw源码 , 如图 7 - 23 所示 , 它一共定义了 4 个参数 , 每个参数说明如下 :
● raw_query : SQL语句 .
● params : 如果raw_query设置字符串格式化 % s , 那么该参数为raw_query提供数值 .
● translations : 为查询的字段设置别名 .
● using : 数据库对象 , 即Django所连接的数据库 .
图 7 - 23 raw源码
上述参数只有raw_query是必选参数 , 其他参数可根据需求自行选择 .
我们以模型Vocation为例 , 使用raw实现数据查询 , 代码如下 :
>> > v = Vocation. objects. raw( 'select * from index_vocation' )
>> > v
< RawQuerySet: select * from index_vocation>
>> > print ( v. query)
select * from index_vocation
>> > v[ 0 ]
< Vocation: 1 >
最后分析execute的语法 , 它执行SQL语句无须经过Django的ORM框架 .
我们知道Django连接数据库需要借助第三方模块实现连接过程 , 如MySQL的mysqlclient模块和SQLite的sqlite3模块等 ,
这些模块连接数据库之后 , 可通过游标的方式来执行SQL语句 , 而execute就是使用这种方式执行SQL语句 , 使用方法如下 :
>> > from django. db import connection
>> > cursor = connection. cursor( )
>> > cursor. execute( 'select * from index_vocation' )
>> > cursor. fetchone( )
( 1 , '软件工程师' , 'Python开发' , 10000 , 2 )
>> > cursor. fetchall( )
[ ( 2 , '文员' , '前台文员' , 5000 , 1 ) ,
( 3 , '网站设计' , '前端开发' , 8000 , 4 ) ,
( 4 , '需求分析师' , '系统需求设计' , 9000 , 3 ) ,
( 5 , '项目经理' , '项目负责人' , 12000 , 5 ) ]
execute能够执行所有的SQL语句 , 但很容易受到SQL注入攻击 , 一般情况下不建议使用这种方式实现数据操作 .
尽管如此 , 它能补全ORM框架所缺失的功能 , 如执行数据库的存储过程 .
事务是指作为单个逻辑执行的一系列操作 , 这些操作具有原子性 , 即这些操作要么完全执行 , 要么完全不执行 .
事务处理可以确保事务性单元内的所有操作都成功完成 , 否则不会执行数据操作 .
事务应该具有 4 个属性 : 原子性 ( Atomicity ) , 一致性 ( Consistency ) , 隔离性 ( Isolation ) , 持久性 ( Durability ) ,
这 4 个属性通常称为ACID特性 , 说明如下 :
● 原子性 : 一个事务是一个不可分割的工作单位 , 事务中包括的操作要么都做 , 要么都不做 .
● 一致性 : 事务必须使数据库从某个一致性状态变到另一个一致性状态 , 一致性与原子性是密切相关的 .
● 隔离性 : 一个事务的执行不能被其他事务干扰 , 即一个事务内部的操作及使用的数据对其他事务是隔离的 , 各个事务之间不能互相干扰 .
● 持久性 : 持久性也称永久性 ( Permanence ) , 指一个事务一旦提交 ,
它对数据库中数据的改变应该是永久性的 , 其他操作或故障不应该对其有任何影响 .
事务在日常开发中经常使用 , 比如银行转账 , 火车票抢购等 .
以银行转账为例 , 假定A账户目前有 100 元 , B账户向A账户转账 100 元 .
在这个转账的过程中 , 必须保证A账户的资金增加 100 元 , B账户的资金减少 100 元 ,
如果刚完成A账户增加 100 元的操作 , 系统就发生瘫痪而无法执行B账户减少 100 元的操作 , 这时A账户就凭空多出 100 元 .
为了解决这种问题 , 这个转账过程需由事务完成 , 说明如下 :
● 原子性和一致性 : B账户减少 100 元后 , A账户增加 100 元 .
假使交易途中发生故障 , B账户不应减少 100 元 , A账户也不应增加 100 元 .
● 隔离性 : 如果B账户执行两次转账 , 应有先后次序 , 两次交易不可在原来同一个余额上重复执行 , 以确保交易后A和B账户的余额正确 .
● 持久性 : 交易记录应在交易完成后永久记录 .
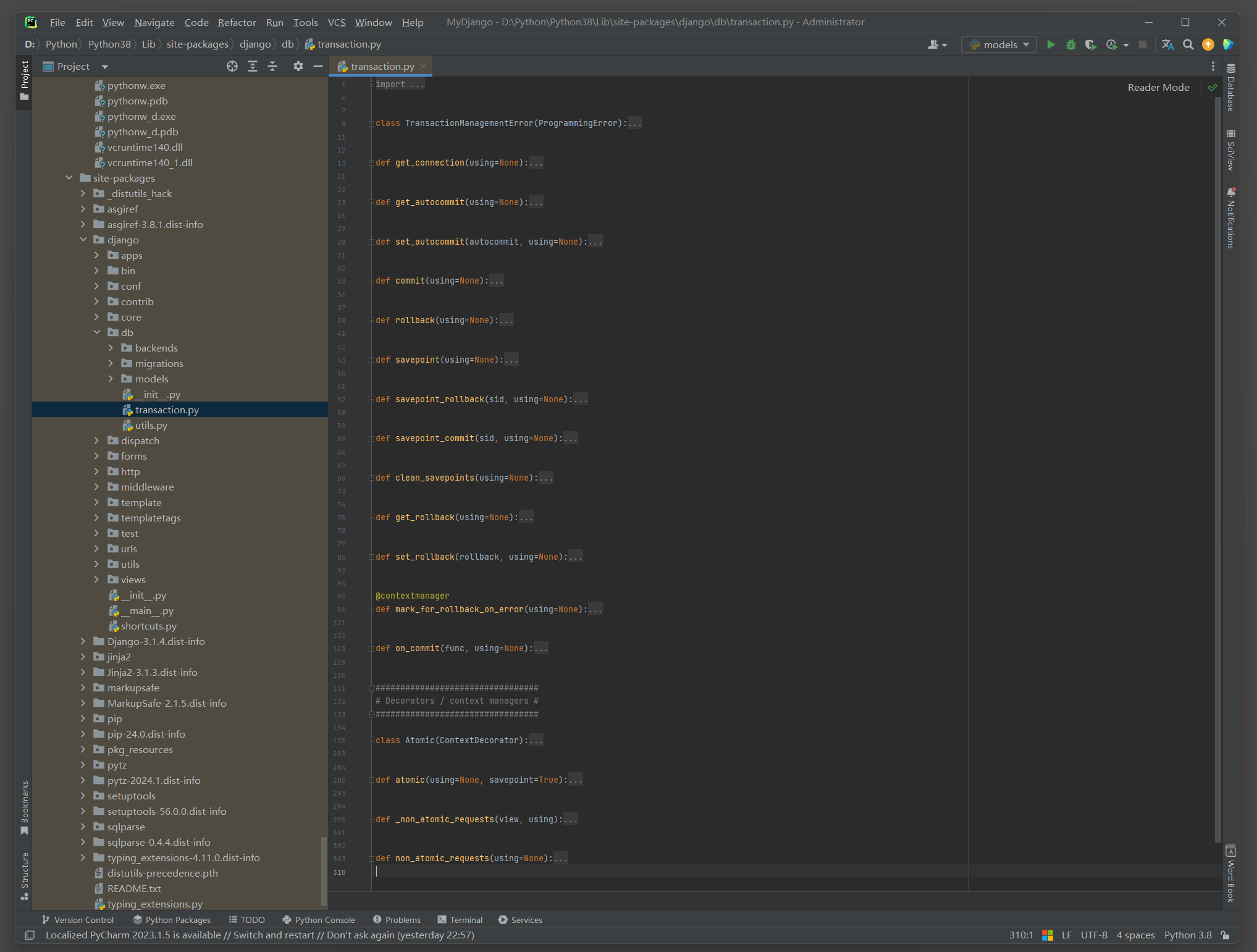
Django的事务定义在transaction . py文件中 , 在PyCharm里打开该文件并分析其定义的函数方法 , 如图 7 - 24 所示 .
图 7 - 24 transaction . py文件
从transaction . py文件发现 , 该文件共定义了两个类和 16 个函数方法 , 而在开发中常用的函数方法如下 :
● atomic ( ) : 在视图函数或视图类里使用事务 .
● savepoint ( ) : 开启事务 .
● savepoint_rollback ( ) : 回滚事务 .
● savepoint_commit ( ) : 提交事务 .
以MyDjango为例 , 将模型Vocation作为事务的操作对象 , 分别在index的urls . py , views . py中定义路由信息和视图函数 , 代码如下 :
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. index, name= 'index' )
]
from django. shortcuts import render
from . models import *
from django. db import transaction
from django. db. models import F
@transaction. atomic
def index ( request) :
sid = transaction. savepoint( )
try :
pk = request. GET. get( 'pk' , '' )
if pk:
v = Vocation. objects. filter ( pk= pk)
v. update( payment= F( 'payment' ) + 1 )
print ( 'Done!' )
else :
Vocation. objects. update( payment= F( 'payment' ) - 1 )
transaction. savepoint_rollback( sid)
except Exception as e:
transaction. savepoint_rollback( sid)
print ( f'操作失败, 原因为: { e} ' )
return render( request, 'index.html' , locals ( ) )
上述代码的视图函数index是通过事务来操作模型Vocation的 , 函数的执行过程说明如下 :
( 1 ) 视图函数使用装饰器 @ transaction . atomic , 使函数支持事务操作 .
( 2 ) 在开始事务操作之前 , 必须使用savepoint方法来创建一个事务对象 , 便于Django的识别和管理 .
( 3 ) 事务操作引入try . . . except机制 , 如果在执行过程中发生异常 , 就执行事务回滚 , 使事务里所有的数据操作无效 , 确保数据的一致性 .
( 4 ) 在try模块里 , 首先获取请求参数pk ,
如果存在请求参数pk , 就根据请求参数id的值去查询模型Vocation的数据 , 并对字段payment执行自增 1 操作 ;
如果请求参数id不存在 , 就将模型Vocation的所有数据执行自减 1 操作和事务回滚 .
如果没有事务机制 , 那么当请求参数pk不存在时 , 模型Vocation的所有数据完成自减 1 操作后 , 数据表立即能看到操作结果 ;
而引入事务机制后 , 由于在自减 1 操作后设置了事务回滚 , 因此程序执行完成后 , 数据表的数据不会发生改变 .
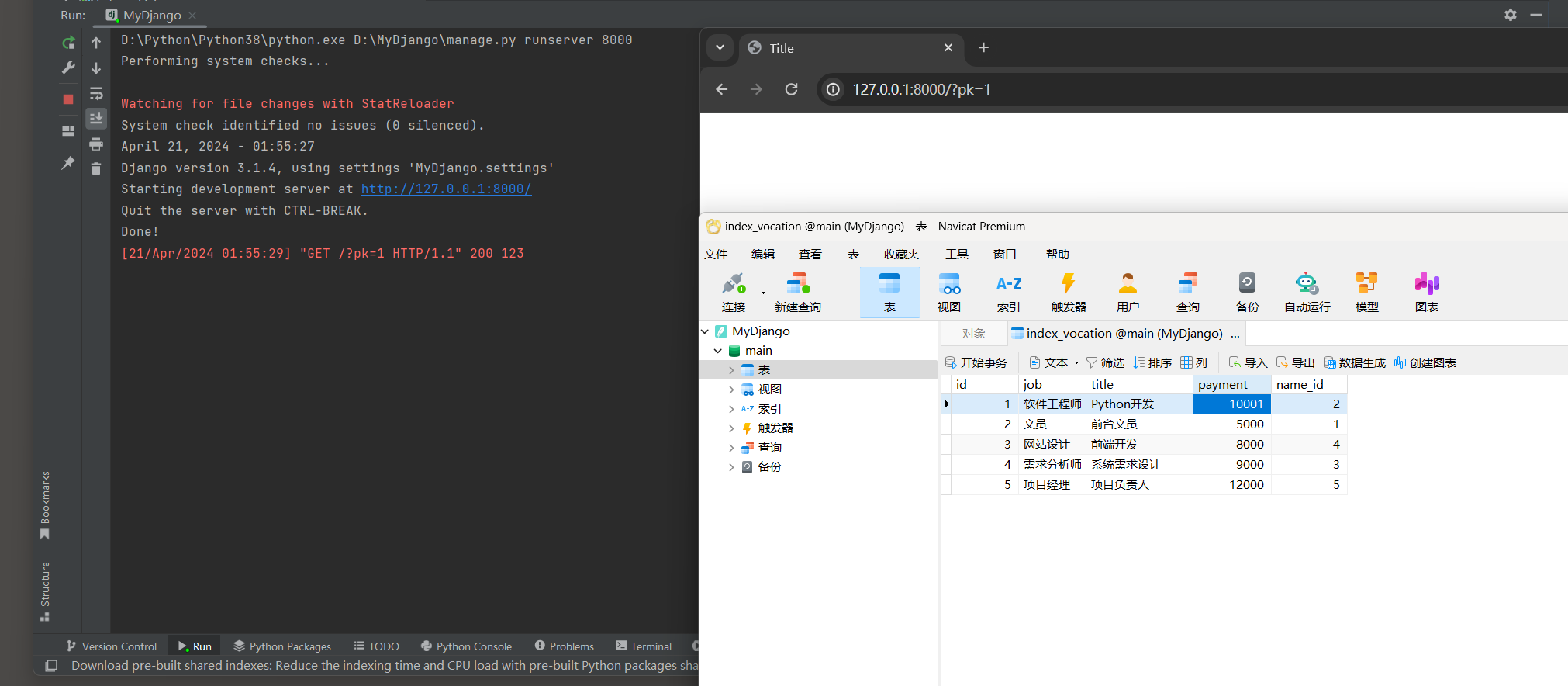
运行MyDjango项目 , 分别访问 : 127.0 .0 .1 : 8000 和 127.0 .0 .1 : 8000 /?pk= 1 ,
每次访问分别查看数据表index_vocation的数据变化情况 , 这样有助于读者深入了解事务机制的运行过程 .
除了在视图函数中使用装饰器 @ transaction . atomic之外 , 还可以在视图函数中使用with模块实现事务操作 , 代码如下 :
from django. db import transaction
from django. http import HttpResponse
def index ( request) :
with transaction. atomic( ) :
try :
my_instance = MyModel( field1= 'value1' , field2= 'value2' )
my_instance. save( )
except Exception as e:
return HttpResponse( "An error occurred: %s" % e)
return HttpResponse( "Operation successful" )
transaction . atomic ( ) 是一个上下文管理器 , 它会在其内部执行的代码块周围创建一个事务的边界 .
如果在该代码块内发生任何异常 , 事务将自动回滚 , 否则 , 如果代码块成功执行 , 事务将自动提交 .
在上面的示例中 , with transaction . atomic ( ) : 语句创建了一个事务 .
如果在with块内部执行数据库操作时发生任何异常 , Django将捕获这些异常 , 并回滚整个事务 .
如果with块成功执行完毕 , 则Django将自动提交事务 .
使用transaction . atomic ( ) 时 , 不需要显式地调用transaction . commit ( ) 或transaction . rollback ( ) , 因为Django会为你处理这些操作 .
这有助于简化代码 , 并减少因忘记提交或回滚事务而引发的问题 .
当网站的数据量越来越庞大时 , 使用单个数据库处理数据很容易使数据库系统瘫痪 , 从而导致整个网站瘫痪 .
为了减轻数据库系统的压力 , Django可以同时连接和使用多个数据库 .
我们通过简单的示例来讲述Django如何实现多数据库的连接与使用 .
以MyDjango为例 , 在项目里创建项目应用index和user ,
并在配置文件settings . py的INSTALLED_APPS中添加index和user , 目录结构如图 7 - 25 所示 .
Pycharm 内置 run manage . py Task选项 , 可以省去输入python manage . py的过程 .
manage. py@MyDjango > startapp user
D: \Python\Python38\python. exe "D:\Program Files\JetBrains\PyCharm 2023.1.4\plugins\python\helpers\pycharm\django_manage.py" startapp user D: / MyDjango
Tracking file by folder pattern: migrations
Following files were affected
D: \MyDjango\user\migrations\__init__. py
Process finished with exit code 0
INSTALLED_APPS = [
'django.contrib.admin' ,
'django.contrib.auth' ,
'django.contrib.contenttypes' ,
'django.contrib.sessions' ,
'django.contrib.messages' ,
'django.contrib.staticfiles' ,
'index.apps.IndexConfig' ,
'user'
]
图 7 - 25 目录结构
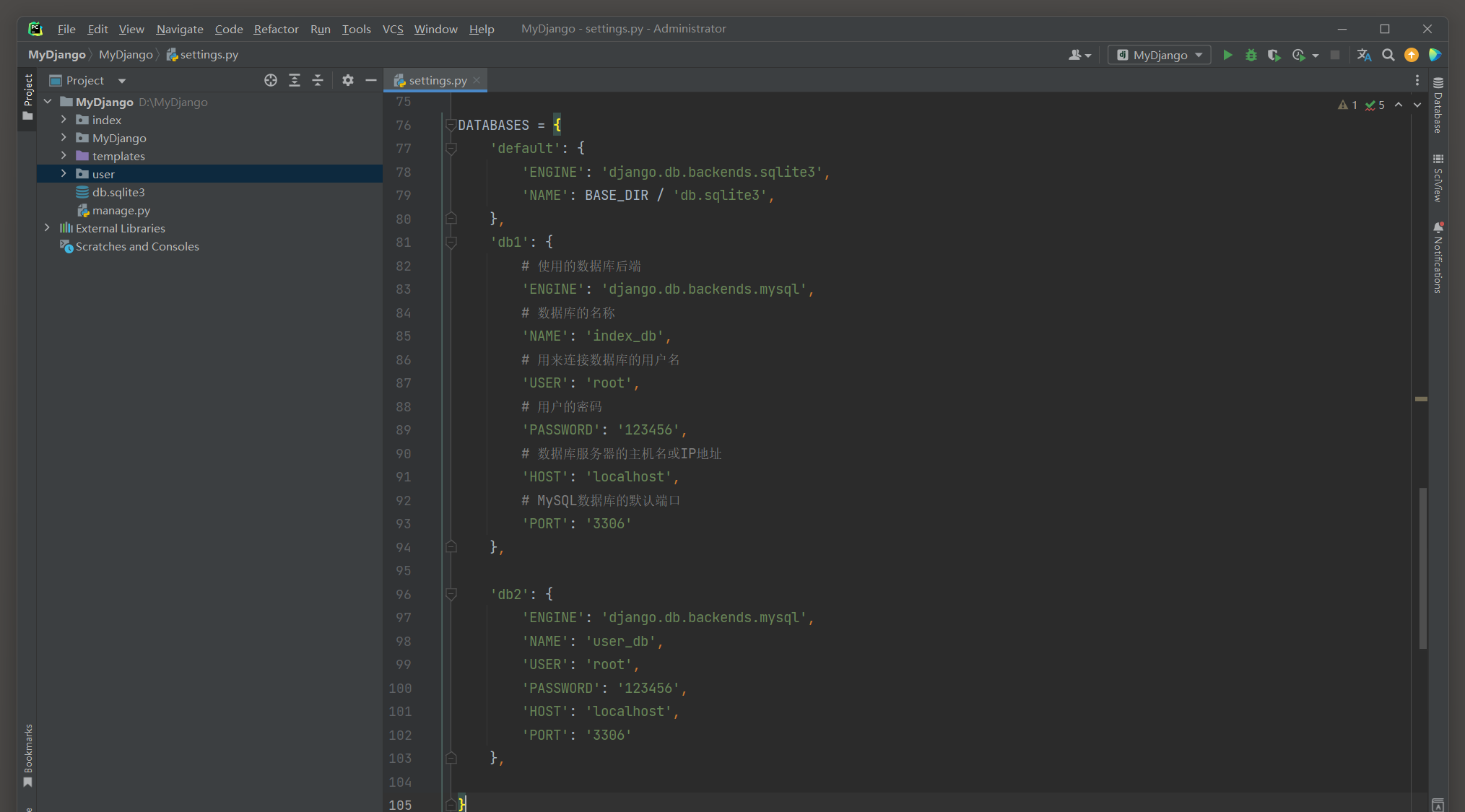
从 2.4 .3 小节得知 , Django连接多个数据库时从配置属性DATABASES添加数据库信息即可 , 并且每个数据库的信息是以字典的键值对表示的 .
本示例将连接 3 个数据库 , 分别是项目内置的db . sqlite3 , MySQL的indexdb和userdb , 配置信息如下 :
DATABASES = {
'default' : {
'ENGINE' : 'django.db.backends.sqlite3' ,
'NAME' : BASE_DIR / 'db.sqlite3' ,
} ,
'db1' : {
'ENGINE' : 'django.db.backends.mysql' ,
'NAME' : 'index_db' ,
'USER' : 'root' ,
'PASSWORD' : '123456' ,
'HOST' : 'localhost' ,
'PORT' : '3306'
} ,
'db2' : {
'ENGINE' : 'django.db.backends.mysql' ,
'NAME' : 'user_db' ,
'USER' : 'root' ,
'PASSWORD' : '123456' ,
'HOST' : 'localhost' ,
'PORT' : '3306'
} ,
}
由于项目连接了MySQL的index_db和user_db数据库 , 因此还需要在本地的MySQL数据库系统里创建相应的数据库 .
* 1. 打开Navicat Premium .
* 2. 连接MySQL数据库 .
* 3. 新建数据库 , 输入名称即可 , 其他选项空着即可 !
字符编码不选默认为UTF8mb4 , 排序规则不选默认为utf8mb4_bg_0900_ai_ci .
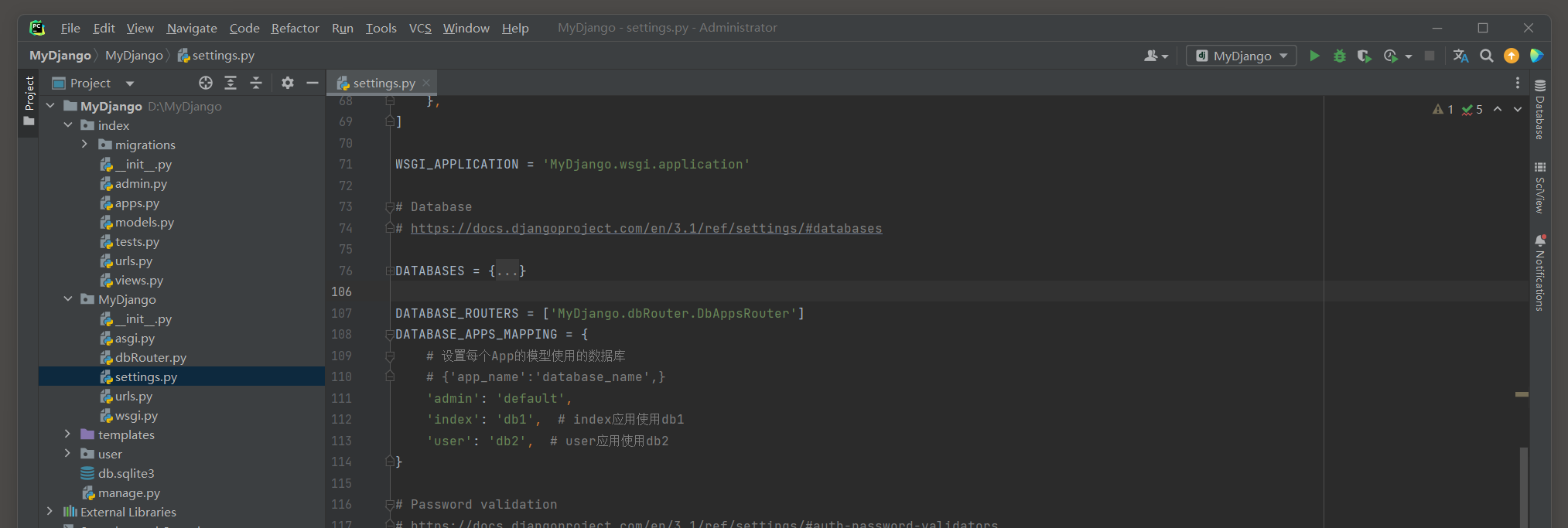
除了设置DATABASES属性之外 , 还需要设置配置属性DATABASE_ROUTERS和DATABASE_APPS_MAPPING , 配置信息如下 :
DATABASE_ROUTERS = [ 'MyDjango.dbRouter.DbAppsRouter' ]
DATABASE_APPS_MAPPING = {
'admin' : 'default' ,
'index' : 'db1' ,
'user' : 'db2' ,
}
DATABASE_ROUTERS指向MyDjango文件夹的dbRouter . py所定义的DbAppsRouter类 , 该类定义数据库读写 , 数据表关系和数据迁移等方法 ;
DATABASE_APPS_MAPPING用于设置数据库与项目应用的映射关系 ,
如项目应用index对应数据库db1 ( MySQL的index_db ) , 代表index的models . py所定义的模型都在数据库db1里创建数据表 .
由于DATABASE_ROUTERS指向MyDjango文件夹的dbRouter . py文件 ,
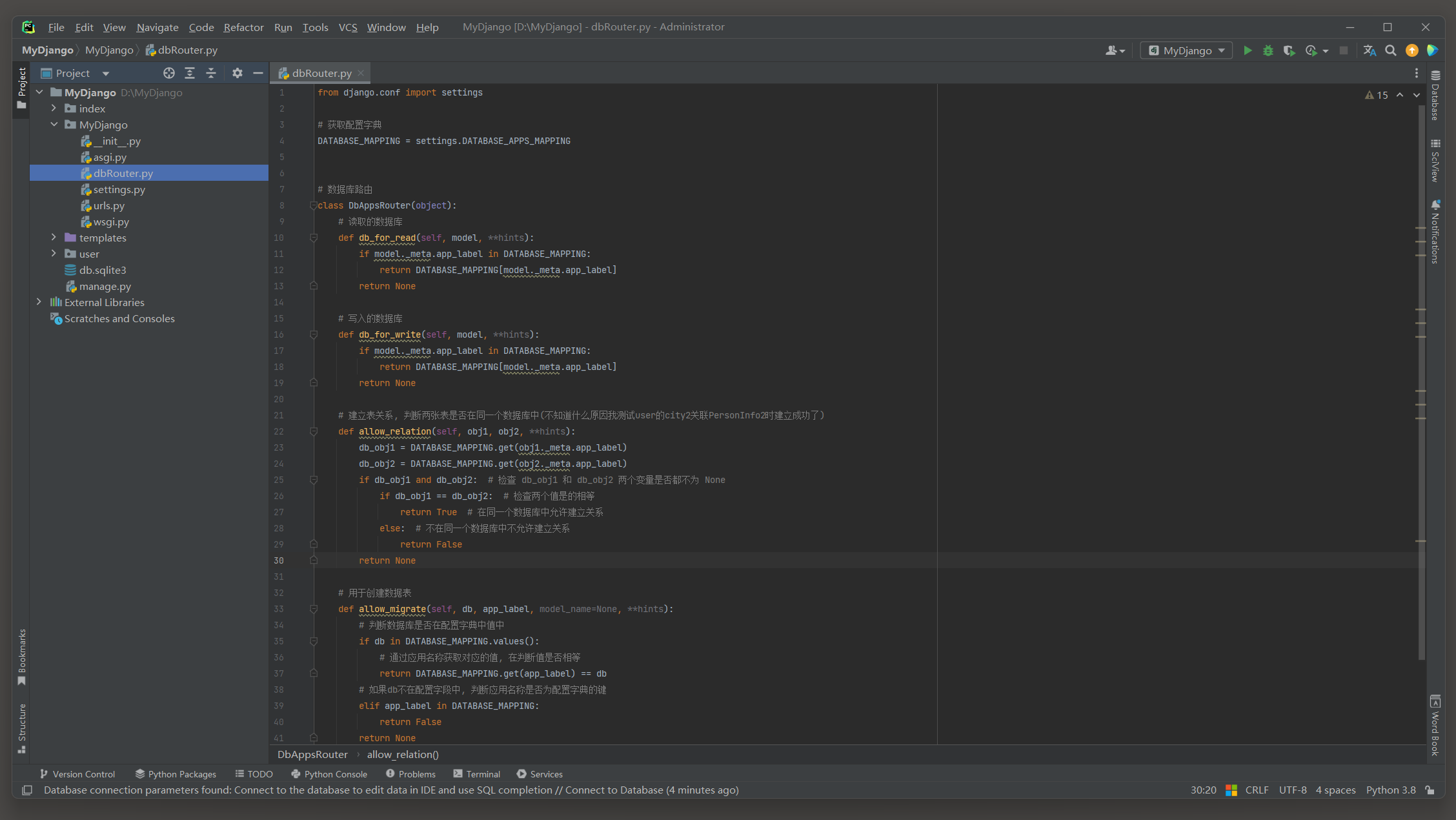
因此在MyDjango文件夹里创建dbRouter . py文件 , 文件名并不固定 , 读者可自行命名 .
我们在该文件里定义DbAppsRouter类 , 类名也可以自行命名 , 代码如下 :
from django. conf import settings
DATABASE_MAPPING = settings. DATABASE_APPS_MAPPING
class DbAppsRouter ( object ) :
def db_for_read ( self, model, ** hints) :
if model. _meta. app_label in DATABASE_MAPPING:
return DATABASE_MAPPING[ model. _meta. app_label]
return None
def db_for_write ( self, model, ** hints) :
if model. _meta. app_label in DATABASE_MAPPING:
return DATABASE_MAPPING[ model. _meta. app_label]
return None
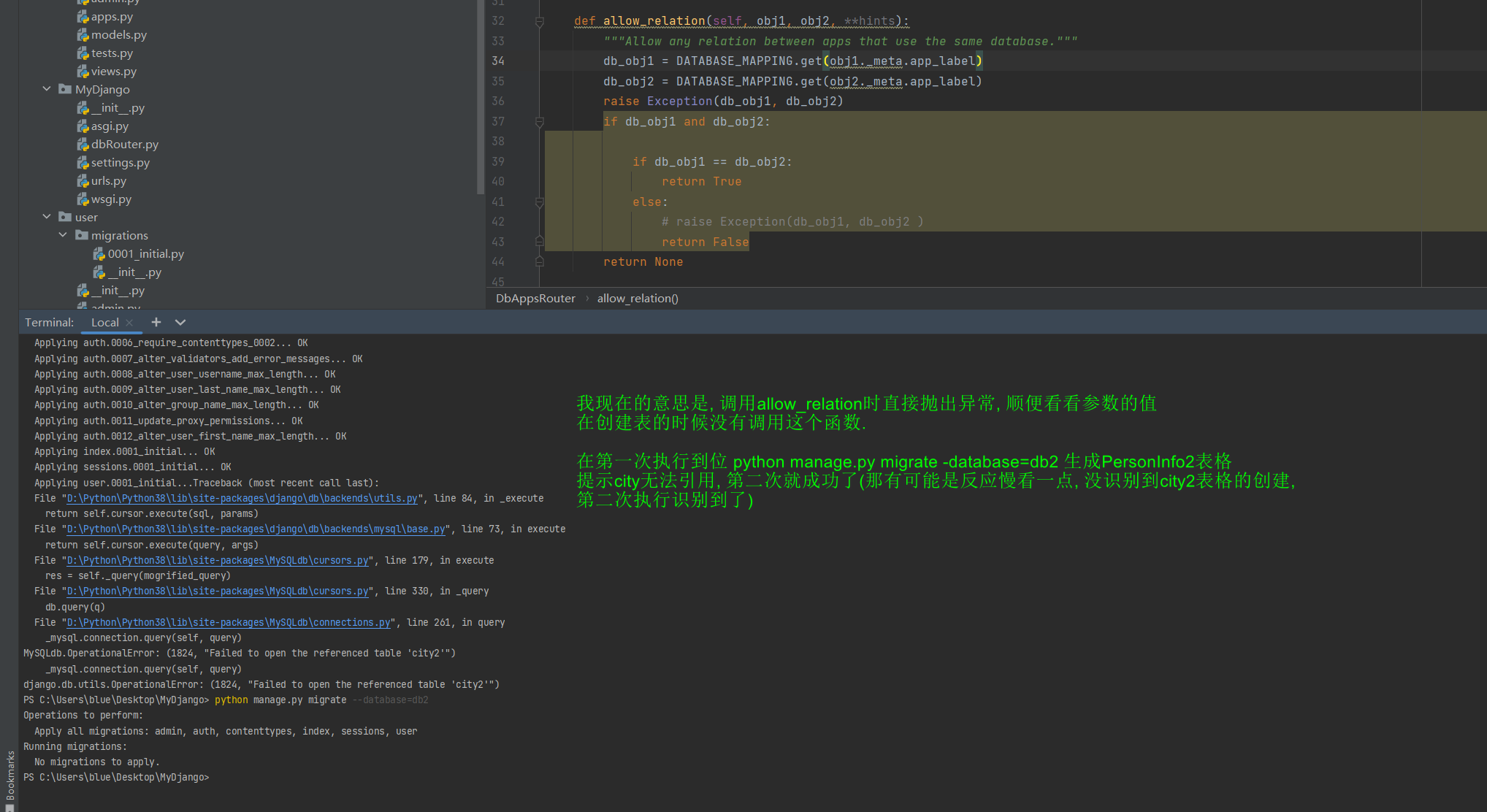
def allow_relation ( self, obj1, obj2, ** hints) :
db_obj1 = DATABASE_MAPPING. get( obj1. _meta. app_label)
db_obj2 = DATABASE_MAPPING. get( obj2. _meta. app_label)
if db_obj1 and db_obj2:
if db_obj1 == db_obj2:
return True
else :
return False
return None
def allow_migrate ( self, db, app_label, model_name= None , ** hints) :
if db in DATABASE_MAPPING. values( ) :
return DATABASE_MAPPING. get( app_label) == db
elif app_label in DATABASE_MAPPING:
return False
return None
Django 的多数据库支持允许同一个Django项目中使用多个数据库 .
这个路由类DbAppsRouter根据应用的标签 ( app_label ) 来决定应该将查询发送到哪个数据库 .
这个路由类需要 settings . py 文件中有一个 DATABASE_APPS_MAPPING 字典 ,
这个字典的键是应用的标签 ( app_label ) , 值是对应的数据库名称 .
这个类有以下几个方法 :
* 1. db_for_read ( self , model , * * hints ) : 这个方法决定了对于给定的模型 ( model ) 应该使用哪个数据库进行读取操作 .
_meta是Django模型的一个属性 , 它包含了模型的一些元信息 , 包括 app_label .
它首先检查模型的app_label是否在DATABASE_MAPPING字典中 , 如果在 , 就返回对应的数据库名称 .
如果不在 , 就返回None , 这表示将使用默认的数据库 .
* 2. db_for_write ( self , model , * * hints ) : 这个方法和db_for_read类似 ,
但是它是用来决定对于给定的模型应该使用哪个数据库进行写入操作的 .
* 3. allow_relation ( self , obj1 , obj2 , * * hints ) : 这个方法用来决定是否允许在两个对象之间建立关系 .
如果两个对象都在DATABASE_MAPPING中 , 并且它们映射到同一个数据库 , 那么就允许建立关系 . 否则 , 不允许 .
* 4. allow_migrate ( self , db , app_label , model_name = None , * * hints ) :
这个方法用来决定是否允许在特定的数据库上迁移特定的应用 .
如果数据库在DATABASE_MAPPING的值中 , 并且应用标签映射到这个数据库 , 那么就允许迁移 .
如果应用标签在DATABASE_MAPPING中 , 但是数据库并不匹配 , 那么不允许迁移 .
运行迁移命令 : 运行 python manage . py migrate 命令时 , Django会遍历所有已安装的应用 , 并检查它们的模型是否需要进行迁移 . 在这个过程中 , allow_migrate 方法会被调用 , 以确定模型应该迁移到哪个数据库 .
变量DATABASE_MAPPING从配置文件里获取配置属性DATABASE_APPS_MAPPING的值 ;
类DbAppsRouter根据变量DATABASE_MAPPING ( 数据库与项目应用的映射关系 ) 来设置数据库的读取 ( 类方法db_for_read ) ,
写入 ( 类方法db_for_write ) , 数据表关系 ( 类方法allow_relation ) 和数据迁移 ( 类方法allow_migrate ) .
综上所述 , 单个Django项目连接多数据库的操作如下 :
● 在配置文件settings . py里设置配置属性DATABASES , 属性值以字典形式表示 , 字典的每个键值对代表连接某个数据库 .
● 设置配置属性DATABASE_APPS_MAPPING , 它以字典形式表示 ,
每个键值对设置每个项目应用所使用的数据库 , 即数据库与项目应用的映射关系 .
● 设置配置属性DATABASE_ROUTERS , 它以列表形式表示 , 列表元素指向某个自定义类 ,
该类根据数据库与项目应用的映射关系来设置数据库的读取 , 写入 , 数据表关系和数据迁移 .
● 在MyDjango文件夹里创建dbRouter . py文件和定义DbAppsRouter类 , 该类是配置属性DATABASE_ROUTERS指向的自定义类 .
Django实现多数据库连接后 , 接下来讲述如何在开发过程中使用多数据库实现数据的读写操作 .
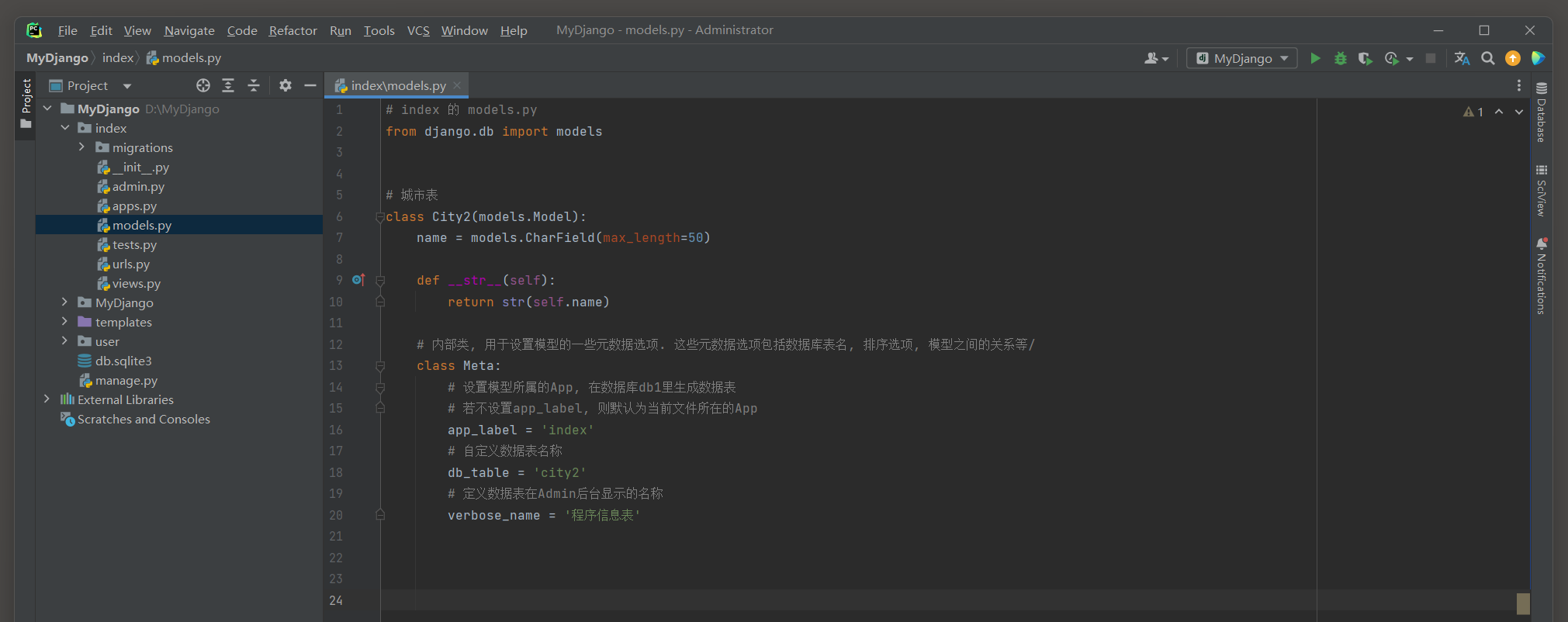
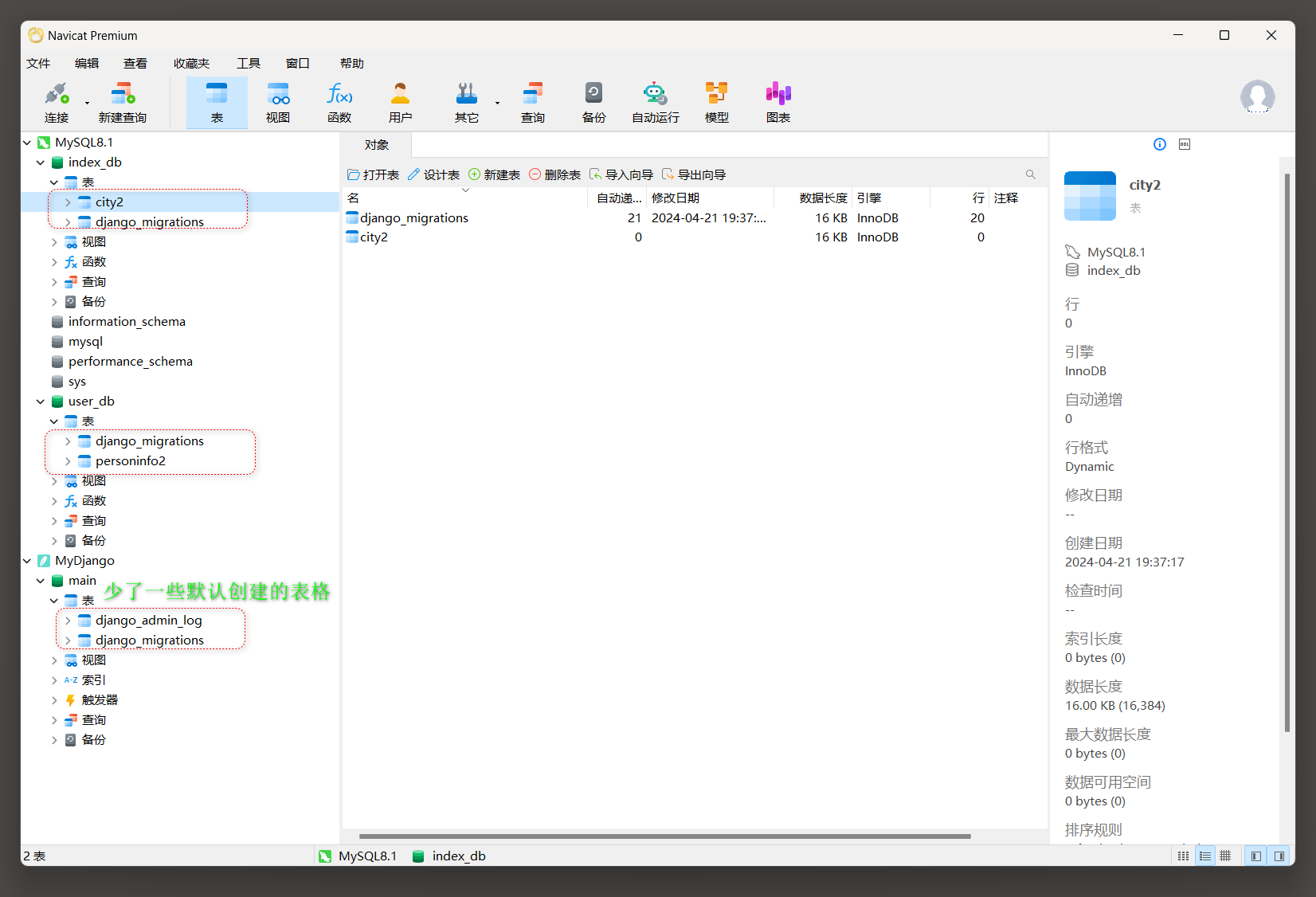
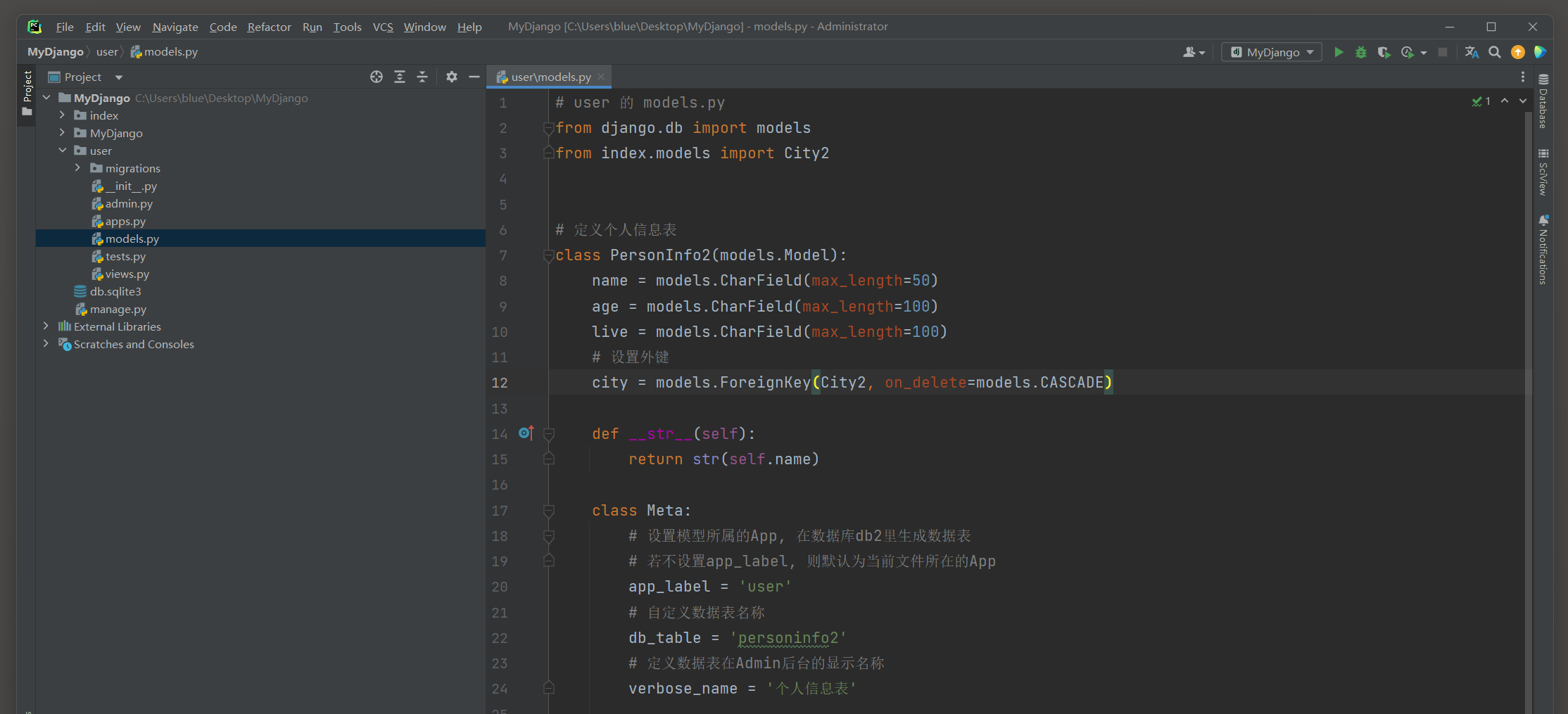
以 7.4 .1 小节的MyDjango为例 , 在项目应用index和user的models . py里分别定义模型City2和PersonInfo2 , 代码如下 :
from django. db import models
class City2 ( models. Model) :
name = models. CharField( max_length= 50 )
def __str__ ( self) :
return str ( self. name)
class Meta :
app_label = 'index'
db_table = 'city2'
verbose_name = '程序信息表'
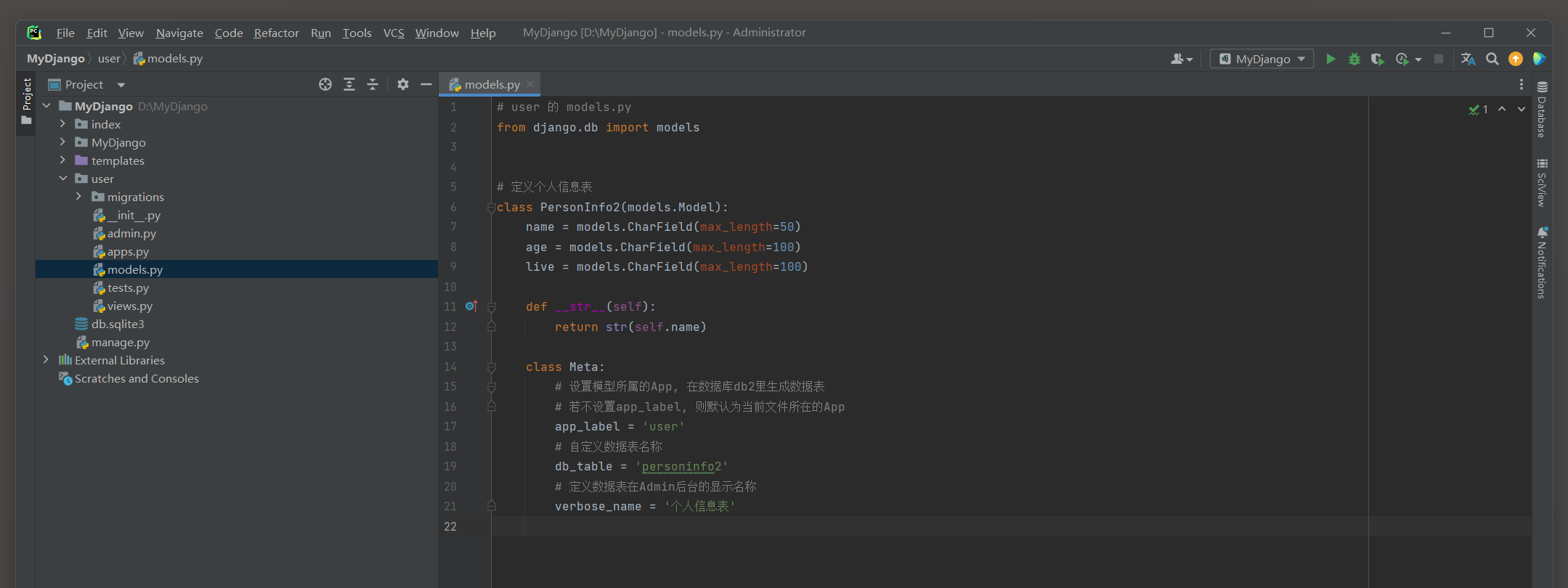
from django. db import models
class PersonInfo2 ( models. Model) :
name = models. CharField( max_length= 50 )
age = models. CharField( max_length= 100 )
live = models. CharField( max_length= 100 )
def __str__ ( self) :
return str ( self. name)
class Meta :
app_label = 'user'
db_table = 'personinfo2'
verbose_name = '个人信息表'
两个模型之间存在一对多关系 , 模型PersonInfo2的字段live代表个人的居住城市 , 但是字段live不能使用ForeignKey关联模型City2 ,
因为模型PersonInfo在数据库db2里创建数据表 , 模型City在数据库db1里创建数据表 , 两者隶属于不同的数据库 , 所以无法建立数据表关系 .
如果在模型PersonInfo中设置外键ForeignKey关联模型City , 在执行数据迁移时 ,
Django提示Cannot add foreign key constraint异常 , 如图 7 - 26 所示 ( 我测试建表成功 , 很不理解我的allow_relation怎么失效了 ) .
图 7 - 26 数据迁移
模型City和PersonInfo的Meta属性设置了app_label , 这是将模型归属到某个项目应用 ,
由于配置文件settings . py设置了DATABASE_APPS_MAPPING属性 , 将每个项目应用的模型指定了所属的数据库 ,
因此能确定模型City和PersonInfo在哪个数据库里创建数据表 .
下一步为模型City和PersonInfo执行数据迁移 , 在PyCharm的Terminal下输入并执行迁移指令makemigrations和migrate .
makemigrations指令在项目应用的migrations文件夹里创建 0001 _initial . py文件 ,
但执行migrate指令时 , Django不会在数据库db1和db2里创建模型City和PersonInfo的数据表 ,
只在Sqlite3数据库里创建Django内置功能的数据表 .
若要为模型City和PersonInfo创建相应的数据表 , 则需要在migrate指令中设置参数 , 具体如下 :
python manage. py makemigrations
python manage. py migrate
python manage. py migrate - - database= db1
python manage. py migrate - - database= db2
完成数据迁移后 , 分别访问数据库Sqlite3 , index_db和user_db , 查看是否生成了相应的数据表 , 如图 7 - 27 所示 .
图 7 - 27 数据表信息
无论Django连接单个数据库还是多个数据库 , 数据的读写方式都是相同的 ,
但多表查询必须保证两张数据表建立在同一个数据库 , 否则只能执行多次单表查询 .
以模型City2和PersonInfo2为例 , 模型PersonInfo2的字段live代表个人的居住城市 ,
它与模型City2可以构建外键关系 , 但两者隶属于不同的数据库 .
若查询居住在广州的人员信息 , 则只能分别对两个模型进行单独查询 , 在Django的Shell模式下实现查询过程 .
PS D: \MyDjango> python manage. py shell
. . .
>> > from user. models import PersonInfo2
>> > from index. models import City2
>> > City2. objects. create( name = '广州' )
< City2: 广州>
>> > d = dict ( name = 'Lucy' , age = 20 , live= '1' )
>> > PersonInfo2. objects. create( ** d)
< PersonInfo2: Lucy>
>> > c = City2. objects. filter ( name = '广州' ) . first( )
>> > c
< City2: 广州>
>> > c. id
1
>> > p = PersonInfo2. objects. filter ( live = str ( c. id ) )
>> > p
< QuerySet [ < PersonInfo2: Lucy> ] >
综上所述 , 单个Django项目连接并使用多数据库时需要注意以下几点 :
● 模型之间建立外键关联必须保证它们所对应的数据表建立在同一个数据库 .
● 定义模型时 , 可在Meta属性中设置app_label , 这是将模型归属到某个项目应用 , 从而确定模型在哪个数据库里创建数据表 .
● 执行数据迁移时 , migrate指令必须设置参数 , 否则只为默认的数据库创建数据表 .
● 无论连接单个数据库还是多个数据库 , 数据的读写方式都是相同的 .
from index. models import City2
class PersonInfo2 ( models. Model) :
. . .
city = models. ForeignKey( City2, on_delete= models. CASCADE)
PS C: \Users\blue\Desktop\MyDjango> python manage. py makemigrations
You are trying to add a non- nullable field 'city'
to personinfo2 without a default; we can't do that ( the database needs something to populate existing rows) .
Please select a fix:
1 ) Provide a one- off default now ( will be set on all existing rows with a null value for this column)
2 ) Quit, and let me add a default in models. py
Select an option: 1
>> > 1
python manage. py migrate - - database= db1
python manage. py migrate - - database= db2
插入数据 ( 原来的数据都删除了 . . . )
python manage. py shell
>> > from user. models import *
>> > from index. models import *
>> > City2. objects. create( name = '广州' )
< City2: 广州>
>> > c = City2. objects. get( pk= 1 )
>> > c
< City2: 广州>
>> > PersonInfo2. objects. create( name = 'qq' , age = 18 , live = '广州' , city_id = 1 )
< PersonInfo2: qq>
>> > p = PersonInfo2. objects. get( pk= 1 )
>> > p
PersonInfo2: qq>
>> > p = PersonInfo2. objects. filter ( id = 1 ) . first( )
>> > p. city_id
1
>> > p. city
< City2: 广州>
>> > p. city. name
'广州'
>> > c = City2. objects. get( pk= 1 )
>> > c. personinfo2_set. all ( )
ValueError: Cannot assign "<City: kid>" : the current database router prevents this relation.
. . . .
Exception: ( 'db1' , 'db2' )
正常情况下 , 系统的数据表都已被固化 , 也就是说 , 数据库的数据表在Django中已定义了具体的模型对象 ,
并且系统在运行中不再修改数据表的表结构 , 但对于一些特殊应用场景 , 我们需要动态创建数据表才能满足开发需求 .
比如现有一张存储商品信息的数据表 , 并且商品销量需要每天更新 .
如果将商品每天销量存储在商品信息表 , 那么全年累计下来 , 数据表就会产生 365 个字段 , 这样不符合数据表的设计思想 .
为了解决这种特殊开发需求 , 商品每天销量应使用新的数据表存储 ,
商品每天销量表的数据与商品信息表的数据相同 , 但商品每天销量表必须设有新字段记录当天销售量 , 并且表名应以当天日期表示 .
Django没有为我们提供动态创建模型和数据表的方法 , 因此需要在ORM的基础上进行自定义 .
以MyDjango为例 , 在项目中应用index的models . py定义函数create_model ( ) , create_db ( ) 和create_new_tab ( ) , 函数定义如下 :
from django. db import models
def crate_model ( name, fields, app_label, options= None ) :
"""
动态定义模型对象
:param name: 模型的命名
:param fields: 模型字段
:param: app_label: 模型所属的项目应用
:param: options 模型Meta类的属性设置
:return 返回模型对象
"""
class Meta :
pass
setattr ( Meta, 'app_label' , app_label)
if options is not None :
for key, value in options. items( ) :
setattr ( Meta, key, value)
attrs = { '__module__' : f' { app_label} .models' , 'Meta' : Meta}
attrs. update( fields)
return type ( name, ( models. Model, ) , attrs)
def create_db ( model) :
"""
使用ORM的数据迁移床架数据表
:param: model: 模型对象
"""
from django. db import connection
from django. db. backends. base. schema import BaseDatabaseSchemaEditor
try :
with BaseDatabaseSchemaEditor( connection) as editor:
editor. create_model( model= model)
except :
print ( '表格已经存在!!!' )
def create_new_tab ( model_name) :
"""
定义模型对象和创建相应数据表
:param model_name:
:return:
"""
fields = {
'id' : models. AutoField( primary_key= True ) ,
'product' : models. CharField( max_length= 20 ) ,
'sales' : models. IntegerField( ) ,
'__str__' : lambda self: str ( self. id )
}
options = {
'verbose_name' : model_name,
'db_table' : model_name
}
model_obj = crate_model( name= model_name, fields= fields, app_label= 'index' , options= options)
create_db( model_obj)
return model_obj
上述代码中 , 动态创建模型和数据表是由函数create_model ( ) , create_db ( ) 和create_new_tab ( ) 实现 , 各个函数实现的功能说明如下 :
( 1 ) create_model ( ) 是工厂函数 , 它负责对模型类进行加工并执行实例化 , 参数name代表模型名称 ;
参数fields以字典格式表示 , 每个键值对代表一个模型字段 ;
参数app_label代表模型定义在那个项目应用 ;
参数options设置模型Meta类的属性 .
( 2 ) create_db ( ) 根据模型对象在数据库中创建数据表 , 它调用ORM的BaseDatabaseSchemaEditor的实例方法create_model ( ) 创建数据表 ,
参数model代表已实例化的模型对象 .
( 3 ) 和create_new_tab ( ) 设置模型字段fields和模型Meta类 , 首先调用工厂函数create_model ( ) 生成模型的实例化对象m ,
然后调用create_db ( ) 并传入实例化对象m , 在数据库中生成相应的数据表 , 最后将模型的实例化对象m作为函数返回值 .
最后在MyDjango的urls . py , 项目应用index的urls . py和views . py定义路由index和视图函数indexView ( ) , 定义过程如下 :
from django. contrib import admin
from django. urls import path, include
urlpatterns = [
path( 'admin/' , admin. site. urls) ,
path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) ) ,
]
from django. urls import path
from . views import *
urlpatterns = [
path( '' , index_view, name= 'index' )
]
from django. shortcuts import HttpResponse
from . models import create_new_tab
import time
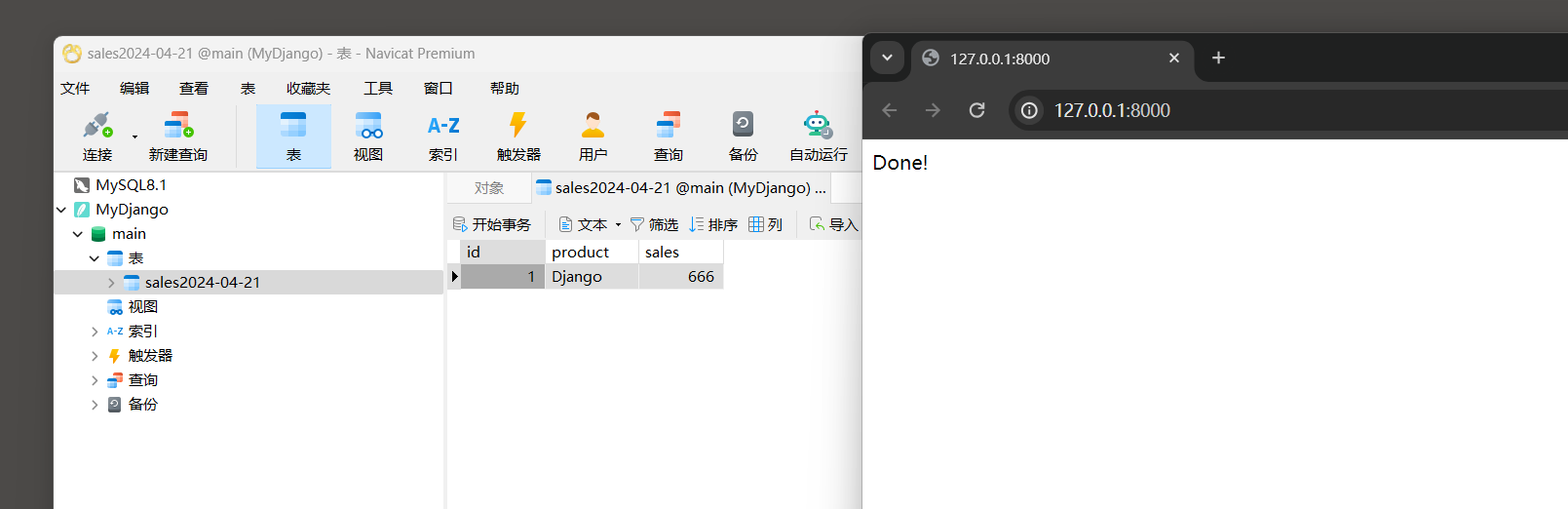
def index_view ( request) :
today = time. localtime( time. time( ) )
model_name = f'sales { time. strftime( "%Y-%m-%d" , today) } ' = create_new_tab( model_name)
model_name. objects. create(
product= 'Django' ,
sales= 666
)
return HttpResponse( 'Done!' )
视图函数indexView ( ) 调用models . py的create_new_tab ( ) 创建模型的实例化对象和数据表 ,
函数参数model_name代表模型名称和数据表名称 ;
函数createNewTab ( ) 的返回值是模型的实例化对象 , 通过操作模型实例化对象就能完成数据表的数据读写操作 .
运行MyDjango , 在浏览器访问 : http : / / 127.0 .0 .1 : 8000 / ,
然后使用数据库可视化工具Navicat Premium打开MyDjango的Sqlite3数据库文件 , 查看数据表的创建情况 , 如图 7 - 28 所示 .
def create_db ( model) :
from django. db import connections
from django. db. backends. base. schema import BaseDatabaseSchemaEditor
try :
index_db = connections[ 'db1' ]
with BaseDatabaseSchemaEditor( index_db) as editor:
editor. create_model( model= model)
except Exception as e:
print ( f' { e} ' )
当数据表的数据量过于庞大的时候 , 数据读写速度会变得越来越慢 , 从而增加了网站的响应时间 , 不利于用户体验 .
为了提高网站性能 , 我们可以对数据量比较大的数据表进行分表处理 , MySQL数据库内置了分表功能 , 分表使用数据表引擎MyISAM实现 .
MySQL设有多种引擎 , 常用的引擎有InnoDB , MyISAM , Memory和ARCHIVE , 每种引擎的说明如下 :
( 1 ) Innodb : 默认的数据库存储引擎 .
支持事务 , 行锁和外键约束 .
内置缓冲管理和缓冲索引 , 加快查询速度 ; 使用共享表空间存储 , 所有表和索引存放在同一个表空间中 .
( 2 ) MyISAM : 一张MyISAM表有三个文件 , 即索引文件 , 表结构文件和数据文件 ; ( 分表使用数据表引擎MyISAM实现 . )
不支持事务和外键约束 , 数据表的锁分别有读锁和写锁 , 读锁和写锁是互斥的 , 并且读写操作是串行 .
在同一时刻 , 两个进程对MyISAM表执行读取和写入操作 , 优先执行写入操作 ,
因此MyISAM表不太适合有大量写入操作 , 它使查询操作难以获得读锁 , 有可能造成永远阻塞 .
( 3 ) Memory : 用于将数据存在内存 , 以提高数据的访问速度 ;
因为数据存放于内存中 , 一旦服务器出现故障 , 数据都会丢失 ; 支持的锁粒度为表级锁 .
( 4 ) ARCHIVE : 用于数据表归档 , 仅支持基本的插入和查询功能 ; 它拥有很好的压缩机制 , 使用zlib压缩 , 常被用来当作数据仓库使用 .
在Django中 , ORM框架连接MySQL并创建数据表是默认使用InnoDB引擎 ,
如果要使用数据表引擎MyISAM实现分表功能 , 必须自定义创建数据表 .
以MyDjango为例 , 在配置文件settings . py中设置MySQL的连接方式 , 代码如下 :
DATABASES = {
'default' : {
'ENGINE' : 'django.db.backends.mysql' ,
'NAME' : 'mydjango' ,
'USER' : 'root' ,
'PASSWORD' : '123456' ,
'HOST' : 'localhost' ,
'PORT' : '3306' ,
} ,
}
在MyDjango连接本地MySQL之前 , 需要在本地MySQL中创建数据库mydjango , 确保Django启动的时候能正常连接 .
代码中还注释了配置属性OPTIONS的init_command , 这是将Django的所有数据表改为MyISAM引擎 .
在实际开发中 , 如果数据表引擎没有特殊要求 , 建议使用InnoDB引擎 , 因为它更适合于日常的业务需求 .
下一步在项目应用index的models . py定义数据表allperson , person0 , person1和person2 ,
这些数据表都是使用MyISAM引擎 , 详细的定义过程如下 :
from django. db import models
from django. db import connection
from django. db. backends. base. schema import BaseDatabaseSchemaEditor
def create_table ( sql) :
try :
with BaseDatabaseSchemaEditor( connection) as editor:
editor. execute( sql= sql)
except Exception as e:
print ( f' { e} ' )
tb_list = [ ]
for i in range ( 3 ) :
sql = f'''
create table if not exists person { i} (
id int primary key auto_increment,
name varchar(20),
age tinyint not null default 18
) ENGINE=MyISAM DEFAULT CHARSET=utf8
AUTO_INCREMENT=1
''' ( sql)
tb_list. append( f'person { i} ' )
tb_str = ',' . join( tb_list)
sql = f'''
create table if not exists allperson(
id int primary key auto_increment,
name varchar(20),
age tinyint not null default 18
) ENGINE=MERGE UNION=( { tb_str} ) INSERT_METHOD=LAST
CHARSET=utf8 AUTO_INCREMENT=1
''' ( sql)
class PersonInfo ( models. Model) :
id = models. AutoField( primary_key= True )
name = models. CharField( max_length= 20 )
age = models. IntegerField( default= 18 )
def __str__ ( self) :
return str ( self. name)
class Meta :
verbose_name = '人员信息'
managed = False
db_table = 'allperson'
上述代码中 , 我们使用ORM框架的BaseDatabaseSchemaEditor的实例方法execute ( ) 执行SQL语句 ,
SQL语句是创建数据表allperson , person0 , person1和person2 .
在SQL语句中 , 只需设置ENGINE = MyISAM就能修改数据表引擎 .
数据表创建成功后 . 我们还要为数据表allperson定义模型PersonInfo ,
通过操作模型PersonInfo就能实现数据表allperson的数据读写操作 ;
由于数据表allperson是由SQL语句创建 , 所以模型的Meta类必须设置参数managed和db_table .
在MyDjango中执行数据迁移 , 在迁移过程中 , Django自动执行index的models . py的代码 , 在数据库中创建相应的数据表 , 如图 7 - 29 所示 .
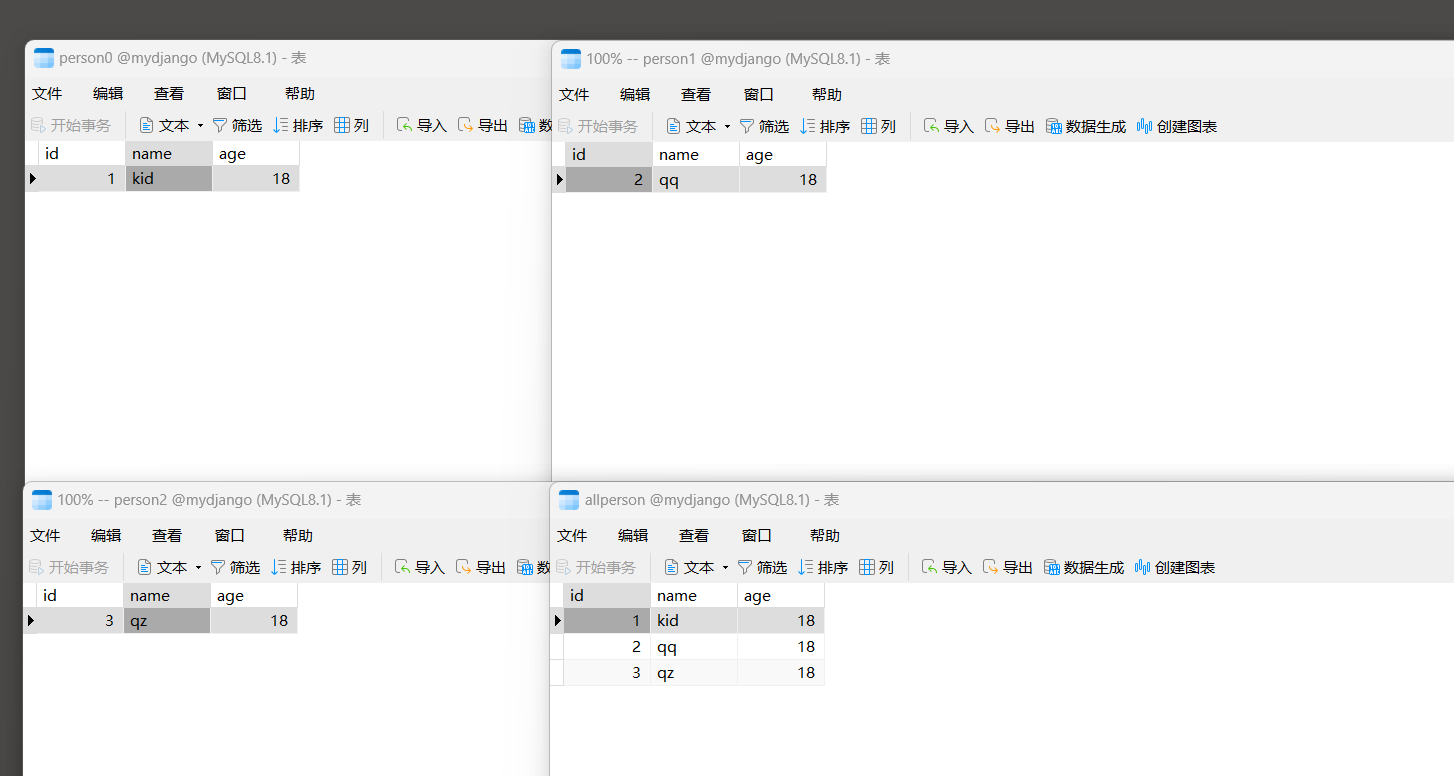
图 7 - 29 数据表信息 ( PersonInfo映射到allperson表 , allperson的数据分三张表存储 )
打开数据表person0 , person1和person2 , 分别为每张数据表添加数据内容 ,
并且打开数据表allperson就能看到数据表person0 , person1和person2的数据内容 , 如图 7 - 30 所示 .
图 7 - 30 数据表allperson , person0 , person1和person2
最后讲述如何在Django中使用MyISAM分表功能 ,
分别在MyDjango的urls . py和index的urls . py定义路由index , index的views . py视图函数indexView ( ) ,
编写templates的模板文件index . html , 代码如下 :
from django. urls import path, include
urlpatterns = [
path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) ) ,
]
from django. urls import path
from . views import *
urlpatterns = [
path( '' , index_view, name= 'index' )
]
from django. shortcuts import render
from . models import *
def index_view ( request) :
person_info = PersonInfo. objects. all ( )
return render( request, 'index.html' , locals ( ) )
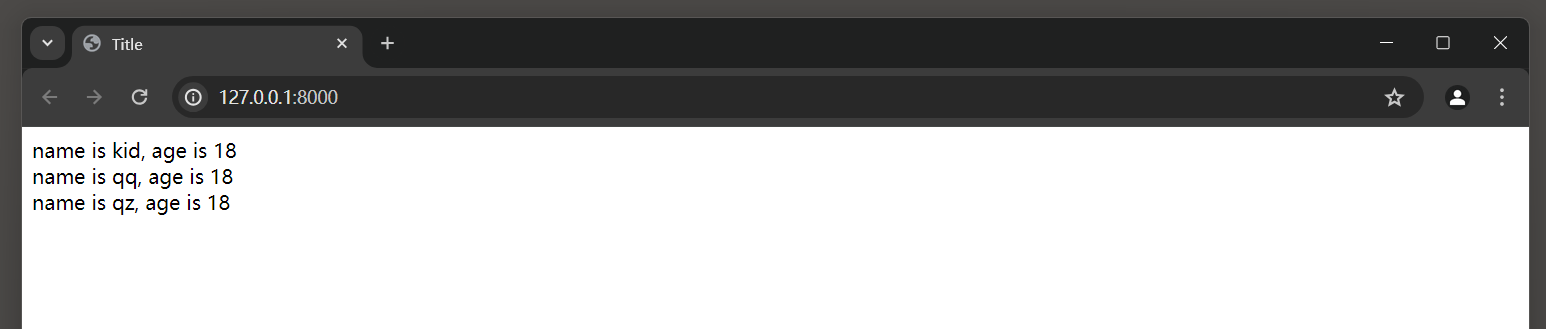
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < div> </ div> </ body> </ html> 视图函数indexView ( ) 查询模型PersonInfo的全部数据 , 模型PersonInfo映射数据表allperson ,
即查询数据表allperson的全部数据 , 数据表allperson的数据来自分表person0 , person1和person2 ;
将查询结果传递给模板文件index . html , 由模板语法将查询结果展示在网页上 .
运行MyDjango , 并访问 : http : / / 127.0 .0 .1 : 8000 / , 运行结果如图 7 - 31 所示 .
图 7 - 31 运行结果
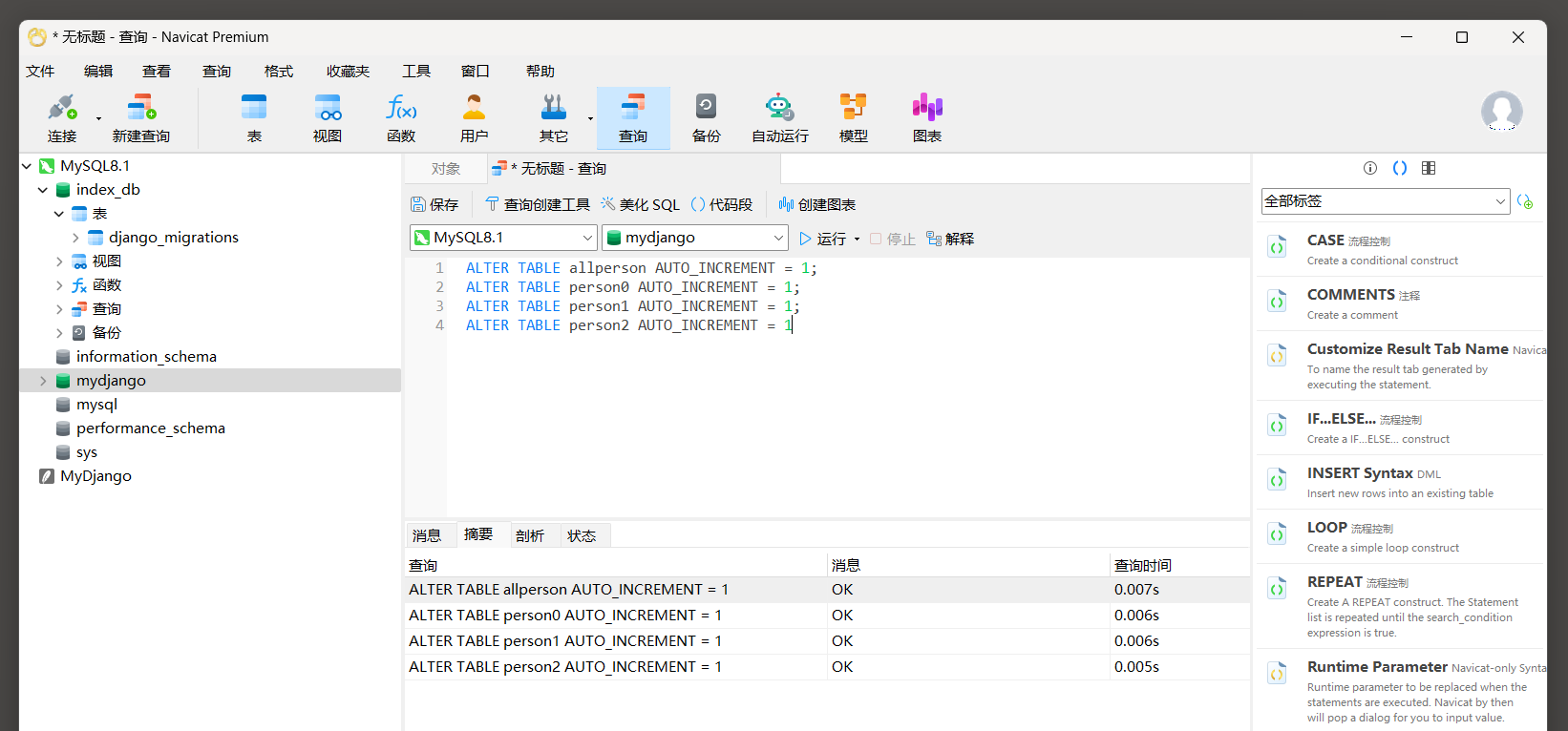
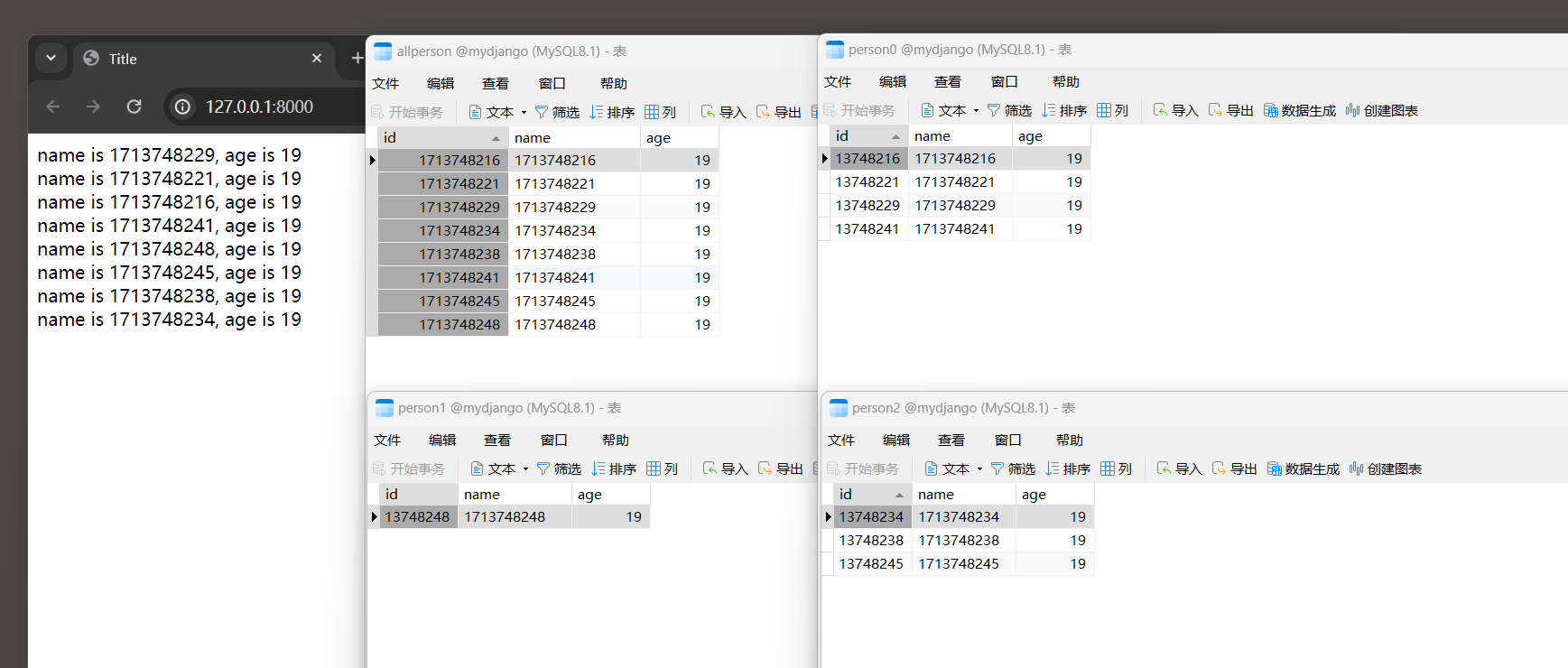
如果系统从设计之初就决定使用MyISAM分表功能 , 并且各个分表都需要写入数据 , 建议分表的主键id不要设为数字类型 ,
因为总表会将所有分表的数据汇总 , 假如每个分表的主键id都是从 1 开始计算并逐行递增 ,
那么总表的字段id会出现重复值而无法分辨数据是来自哪个分表 .
MyISAM分表功能是由一张总表和多张分表组成 , 总表是多张分表的数据汇总 , 便于查询数据 , 但是对总表进行数据新增 ,
它只会在最后的分表中插入数据 , 比如分表person0 , person1和person2 , MySQL只会在person2中插入数据 .
( 在Navicat Premium中往allperson表中写入数据 , 只会在person2中插入数据 )
如果要实现数据新增操作 , 可以在index的models . py定义各个分表的模型对象 ,
每次执行数据新增的时候 , 分别查询各个分表的数据量 , 将数据写入到数据量最小的分表中 ;
还可以使用随机函数random ( ) 将每次数据新增操作随机写入到某张分表中 .
总的来说 , 数据新增需要制定合理的新增策略 , 以使各个分表的数据量保持在合理的数值范围内 .
from django. shortcuts import render
from . models import *
import random
from django. db import connection
import time
def index_view ( request) :
person_info = PersonInfo. objects. all ( )
table_names = [ 'person0' , 'person1' , 'person2' ]
random_table = random. choice( table_names)
sql = "INSERT INTO %s (id, name, age) VALUES (%%s, %%s, %%s);" % random_table
timestamp = int ( time. time( ) )
time. sleep( 2 )
id_as_str = str ( timestamp)
with connection. cursor( ) as cursor:
cursor. execute( sql, ( timestamp, id_as_str, 19 ) )
return render( request, 'index.html' , locals ( ) )
ALTER TABLE allperson AUTO_INCREMENT = 1 ;
ALTER TABLE person0 AUTO_INCREMENT = 1 ;
ALTER TABLE person1 AUTO_INCREMENT = 1 ;
ALTER TABLE person2 AUTO_INCREMENT = 1
访问一次主页则会写入一条数据 , 主键为当前的时间戳 .
Django对各种数据库提供了很好的支持 , 包括PostgreSQL , MySQL , SQLite和Oracle ,
而且为这些数据库提供了统一的API方法 , 这些API统称为ORM框架 .
通过使用Django内置的ORM框架可以实现数据库连接和读写操作 .
模型定义讲述了模型字段和模型属性的设置 , 不同类型的模型字段对应不同的数据表字段 ;
模型属性可用于Django其他功能模块 , 如设置模型所属的App .
开发个人的ORM框架是从源码深入剖析Django的ORM框架底层原理 , 并参考此原理实现个人的ORM框架的开发 .
数据迁移是根据模型在数据库里创建相应的数据表 , 这一过程由Django内置的操作指令makemigrations和migrate实现 ,
此外还讲述数据迁移常见的错误以及其他数据迁移指令 .
数据导入与导出是对数据表的数据执行导入与导出操作 , 确保开发阶段 , 测试阶段和项目上线的数据互不影响 .
一个模型对应数据库的一张数据表 , 但是每张数据表之间是可以存在外键关联的 , 表与表之间有 3 种关联 : 一对一 , 一对多和多对多 .
数据新增 : 由模型实例化对象调用内置方法实现数据新增 ,
比如单数据新增调用create , 查询与新增调用get_or_create , 修改与新增调用update_or_create , 批量新增调用bulk_create .
数据修改 : 必须执行一次数据查询 , 再对查询结果进行修改操作 , 常用方法有 : 模型实例化 , update方法和批量更新bulk_update .
数据删除 : 必须执行一次数据查询 , 再对查询结果进行删除操作 , 若删除的数据设有外键字段 , 则删除结果由外键的删除模式决定 .
数据查询 : 分为单表查询和多表查询 , Django提供多种不同查询的API方法 , 以满足开发需求 .
执行SQL语句有 3 种方法实现 : extra , raw和execute , 其中extra和raw只能实现数据查询 , 具有一定的局限性 ;
而execute无须经过ORM框架处理 , 能够执行所有SQL语句 , 但很容易受到SQL注入攻击 .
数据库事务是指作为单个逻辑执行的一系列操作 ,
这些操作具有原子性 , 即这些操作要么完全执行 , 要么完全不执行 , 常用于银行转账和火车票抢购等 .
单个Django项目连接多数据库的操作如下 :
● 在配置文件settings . py里设置配置属性DATABASES , 属性值以字典形式表示 , 字典的每个键值对代表连接某个数据库 .
● 设置配置属性DATABASE_APPS_MAPPING , 它以字典形式表示 ,
每个键值对设置每个项目应用所使用的数据库 , 即数据库与项目应用的映射关系 .
● 设置配置属性DATABASE_ROUTERS , 它以列表形式表示 , 列表元素指向某个自定义类 ,
该类根据数据库与项目应用的映射关系来设置数据库的读取 , 写入 , 数据表关系和数据迁移 .
● 在MyDjango文件夹里创建dbRouter . py文件和定义DbAppsRouter类 , 该类是配置属性DATABASE_ROUTERS指向的自定义类 .
单个Django项目连接并使用多数据库时需要注意以下几点 :
● 模型之间建立外键关联必须保证它们所对应的数据表建立在同一个数据库 .
● 定义模型时 , 可在Meta属性中设置app_label , 这是将模型归属到某个项目应用 , 从而确定模型在哪个数据库里创建数据表 .
● 执行数据迁移时 , migrate指令必须设置参数 , 否则只为默认的数据库创建数据表 .
● 无论连接单个数据库还是多个数据库 , 数据的读写方式都是相同的 .
正常情况下 , 系统的数据表都已被固化 , 也就是说 , 数据库的数据表在Django中已定义了具体的模型对象 ,
并且系统在运行中不再修改数据表的表结构 , 但对于一些特殊应用场景 , 我们需要动态创建数据表才能满足开发需求 .
Django没有为我们提供动态创建模型和数据表的方法 , 因此需要在ORM的基础上进行自定义 .
当数据表的数据量过于庞大的时候 , 数据读写速度会变得越来越慢 , 从而增加了网站的响应时间 , 不利于用户体验 .
为了提高网站性能 , 我们可以对数据量比较大的数据表进行分表处理 , MySQL数据库内置了分表功能 , 分表使用数据表引擎MyISAM实现 .