文章目录
- 摘要
- 1、引言
- 2、相关工作
- 2.1、图像去模糊
- 2.2、生成对抗网络
- 3、DeblurGAN-v2 架构
- 3.1、特征金字塔去模糊
- 3.2、骨干网络的选择:性能与效率之间的权衡
- 3.3、双尺度RaGAN-LS判别器
- 3.4、训练数据集
- 4、实验评估
- 4.1、实现细节
- 4.2、在GoPro数据集上的定量评估
- 4.3、Kohler数据集上的定量评估
- 4.4、DVD数据集上的定量评估
- 4.5、Lai数据集上的主观评估
- 4.6、消融研究与分析
- 4.7、扩展至一般图像恢复
- 5、结论
摘要
我们提出了一种新的端到端生成对抗网络(GAN),用于单图像运动去模糊,名为DeblurGAN-v2,该网络大大提升了去模糊的效率、质量和灵活性。DeblurGAN-v2基于具有双尺度判别器的相对论条件GAN。我们首次将特征金字塔网络引入去模糊领域,作为DeblurGAN-v2生成器的核心构建块。它可以灵活地与各种骨干网络配合使用,以在性能和效率之间取得平衡。使用先进的骨干网络(例如,Inception-ResNet-v2)可以带来稳固的先进的去模糊效果。同时,使用轻量级骨干网络(例如,MobileNet及其变体),DeblurGAN-v2的速度比最近的竞争对手快10到100倍,同时保持接近最先进的结果,这意味着有实时视频去模糊的选项。我们证明,在去模糊质量(客观和主观)以及效率方面,DeblurGAN-v2在几个流行的基准测试上均获得了极具竞争力的性能。此外,我们还展示了该架构对于一般图像恢复任务的有效性。我们的代码、模型和数据可在以下网址获取:https://github.com/KupynOrest/DeblurGANv2。
1、引言
本文着重关注单图像盲运动去模糊这一具有挑战性的设置。运动模糊通常出现在手持相机拍摄的照片或包含移动物体的低帧率视频中。模糊会降低人类的感知质量,并对后续的计算机视觉分析构成挑战。现实世界的模糊通常具有未知且空间变化的模糊核,且进一步受到噪声和其他伪影的复杂化影响。
深度学习的近期繁荣已经在图像恢复领域取得了显著进展[48,28]。具体来说,生成对抗网络(GANs)[9]通常能够产生比经典前馈编码器更锐利、更合理的纹理,并在图像超分辨率[23]和图像修复[53]方面取得了成功。最近,[21]通过将其视为特殊的图像到图像转换任务[13],将GAN引入去模糊领域。提出的模型名为DeblurGAN,已被证明能够从合成和现实世界的模糊图像中恢复出视觉上令人愉悦且清晰的图像。当时,DeblurGAN的速度也比其最接近的竞争对手快5倍[33]。
在DeblurGAN成功的基础上,本文旨在推动基于GAN的运动去模糊技术的进一步发展。我们引入了一个新的框架来改进DeblurGAN,称为DeblurGAN-v2,以在去模糊性能、推理效率以及质量和效率谱上的高灵活性方面取得提升。我们的创新总结如下:
-
框架层面:我们为去模糊任务构建了一个新的条件GAN框架。对于生成器,我们首次将最初为对象检测开发的特征金字塔网络(FPN)[27]引入图像恢复任务中。对于判别器,我们采用带有包裹在内的最小平方损失的相对论判别器[16],并且设置两列,分别评估全局(图像)和局部(块)尺度。
-
骨干层面:尽管上述框架对生成器骨干的选择是无关的,但选择会影响去模糊的质量和效率。为了追求最先进的去模糊质量,我们插入了复杂的Inception-ResNet-v2骨干。为了转向更高效的模型,我们采用了MobileNet,并进一步创建了其变体,即具有深度可分离卷积的MobileNet(MobileNet-DSC)。后两者在尺寸上非常紧凑,推理速度也非常快。
-
实验层面:我们在三个流行的基准测试上进行了广泛的实验,以展示DeblurGAN-v2实现的最新(或接近最新)性能(PSNR、SSIM和感知质量)。在效率方面,使用MobileNet-DSC的DeblurGAN-v2比DeblurGAN[21]快11倍,比[33, 45]快100倍以上,并且模型大小仅为4MB,这暗示了实时视频去模糊的可能性。我们还对真实模糊图像的去模糊质量进行了主观研究。最后,我们还展示了我们的模型在一般图像恢复任务中的潜力,作为额外的灵活性。
2、相关工作
2.1、图像去模糊
单图像运动去模糊传统上被视为一个反卷积问题,可以通过盲去模糊或非盲去模糊的方式来解决。前者假设给定或预先估计的模糊核[39,52]。后者更为现实,但高度病态。早期的模型依赖于自然图像先验来正则化去模糊过程[20,36,25,5]。然而,大多数手工设计的先验不能很好地捕获真实图像中复杂的模糊变化。
新兴的深度学习技术推动了图像恢复任务的突破。Sun等人[43]利用卷积神经网络(CNN)来估计模糊核。Gong等人[8]使用全卷积网络来估计运动流。除了这些基于核的方法外,还探索了端到端的无核CNN方法,直接从模糊的输入中恢复出清晰的图像,例如[33, 35]。Tao等人[45]的最新工作将[33]中的多尺度CNN扩展为尺度循环CNN用于盲图像去模糊,取得了令人印象深刻的结果。
GAN在图像恢复方面的成功也影响了单图像去模糊,自Ramakrishnan等人[37]首次通过参考图像翻译思想[13]解决图像去模糊问题以来。最近,Kupyn等人[21]引入了DeblurGAN,它利用了带有梯度惩罚[10]和感知损失[15]的Wasserstein GAN[2]。
2.2、生成对抗网络
GAN(生成对抗网络)由两个模型组成:判别器D和生成器G,它们形成了一个两人极小极大博弈。生成器学习产生人工样本,并经过训练来欺骗判别器,其目标是捕获真实数据的分布。特别是,作为流行的GAN变体,条件GANs[31]已被广泛应用于图像到图像的翻译问题,其中图像恢复和增强是特殊情况。它们除了将潜在代码作为输入外,还将标签或观察到的图像作为输入。
该极小极大博弈中的价值函数 V(D, G) 定义为以下形式[9](假-真标签设为 0-1):
min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \begin{aligned} \min _{G} \max _{D} V(D, G) & =\mathbb{E}_{x \sim p_{\text {data }}(x)}[\log D(x)] \\ & +\mathbb{E}_{z \sim p_{z}(z)}[\log (1-D(G(z)))] \end{aligned} GminDmaxV(D,G)=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
这样的目标函数非常难以优化,并且需要在训练过程中应对许多挑战,例如模式崩溃和梯度消失/爆炸。为了解决梯度消失问题并稳定训练,最小二乘GAN的判别器[30]试图引入一个损失函数,该函数提供更平滑且不饱和的梯度。作者观察到[9]中的对数型损失很快就会饱和,因为它忽略了 x 到决策边界的距离。相比之下,L2损失提供了与该距离成比例的梯度,因此远离边界的假样本会受到更大的惩罚。提出的损失函数还最小化了Pearson χ2散度,这有助于更好的训练稳定性。LSGAN的目标函数可以表示为:
min D V ( D ) = 1 2 E x ∼ p data ( x ) [ ( D ( x ) − 1 ) 2 ] + 1 2 E z ∼ p z ( z ) [ D ( G ( z ) ) 2 ] min G V ( G ) = 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − 1 ) 2 ] \begin{aligned} \min _{D} V(D) & =\frac{1}{2} \mathbb{E}_{x \sim p_{\text {data }}(x)}\left[(D(x)-1)^{2}\right] \\ & +\frac{1}{2} \mathbb{E}_{z \sim p_{z}(z)}\left[D(G(z))^{2}\right] \\ \min _{G} V(G) & =\frac{1}{2} \mathbb{E}_{z \sim p_{z}(z)}\left[(D(G(z))-1)^{2}\right] \end{aligned} DminV(D)GminV(G)=21Ex∼pdata (x)[(D(x)−1)2]+21Ez∼pz(z)[D(G(z))2]=21Ez∼pz(z)[(D(G(z))−1)2]
对GAN的另一项相关改进是相对论GAN[16]。它使用相对论判别器来估计给定真实数据比随机采样的假数据更真实的概率。正如作者所主张的那样,这会考虑到先验知识,即迷你批次中有一半的数据是假的。与其他GAN类型(包括在DeblurGAN-v1中使用的WGAN-GP[10])相比,相对论判别器显示出更稳定且计算效率更高的训练过程。
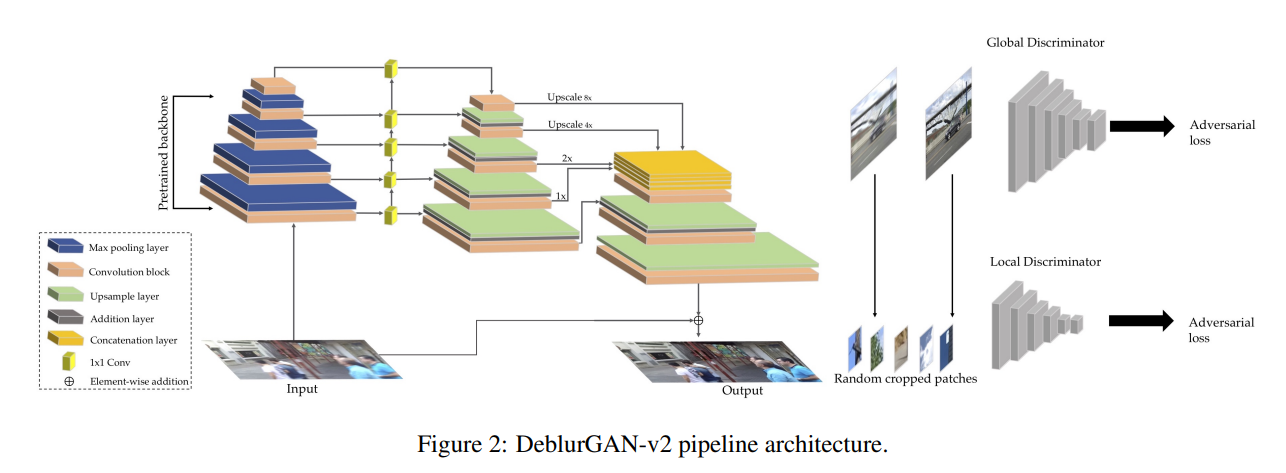
3、DeblurGAN-v2 架构
DeblurGAN-v2 架构的概述如图2所示。它通过训练好的生成器从单个模糊图像
I
B
I_{B}
IB 中恢复出清晰的图像
I
S
I_{S}
IS。
3.1、特征金字塔去模糊
现有的用于图像去模糊(以及其他恢复问题)的卷积神经网络(CNNs)通常参考ResNet-like结构。大多数最先进的方法[33,45]处理不同级别的模糊,利用多流CNN和在不同尺度上的输入图像金字塔。然而,处理多个尺度的图像既耗时又占用内存。据我们所知,我们首次将特征金字塔网络(FPN)的思想引入图像去模糊(更广泛地说,图像恢复和增强领域)。我们将这种新颖的方法视为一种轻量级的替代方案,用于整合多尺度特征。
FPN模块最初是为目标检测而设计的[27]。它生成多个特征图层,这些图层编码不同的语义并包含更好的质量信息。FPN包含一个自下而上的路径和一个自上而下的路径。自下而上的路径是通常用于特征提取的卷积网络,沿此路径空间分辨率会下采样,但会提取和压缩更多的语义上下文信息。通过自上而下的路径,FPN从语义丰富的图层中重构出更高的空间分辨率。自下而上和自上而下路径之间的横向连接补充了高分辨率的细节并有助于定位目标。
我们的架构包含一个FPN骨干网络,我们从其中提取五个不同尺度的最终特征图作为输出。这些特征随后被上采样到与输入相同大小的 1 4 \frac{1}{4} 41 ,并连接成一个包含不同级别语义信息的张量。此外,我们在网络的末端增加了两个上采样和卷积层,以恢复原始图像大小并减少伪影。与[21,29]类似,我们从输入到输出引入了一个直接的跳跃连接,以便学习主要集中在残差上。输入图像被归一化到[-1, 1]范围。我们还使用tanh激活层将输出保持在相同的范围内。除了多尺度特征聚合能力外,FPN还在准确性和速度之间达到了平衡:请参见实验部分。
3.2、骨干网络的选择:性能与效率之间的权衡
新的嵌入FPN的架构在选择特征提取器骨干网络时是无关紧要的。由于这种即插即用的特性,我们有权在准确性和效率的范围内灵活选择。默认情况下,我们选择使用ImageNet预训练的骨干网络来传递更多与语义相关的特征。作为一种选择,我们使用Inception-ResNet-v2[44]来追求强大的去模糊性能,尽管我们发现其他骨干网络,如SEResNeXt[12],同样有效。
由于移动设备上进行图像增强的需求日益普及,对高效恢复模型的需求也引起了越来越多的关注[54,50,47]。为了探索这一方向,我们选择MobileNet V2骨干网络[40]作为一个选项。为了进一步降低复杂性,我们在DeblurGANv2和MobileNet V2的基础上尝试了另一种更激进的选择,即将整个网络(包括不在骨干网络中的部分)中的所有常规卷积替换为深度可分离卷积[6]。所得模型称为MobileNet-DSC,可以提供极轻量级且高效的图像去模糊效果。
为了向实践者释放这种重要的灵活性,在我们的代码中,我们已经将骨干网络的切换实现为简单的单行命令:它可以与许多最先进的预训练网络兼容。
3.3、双尺度RaGAN-LS判别器
在DeblurGAN中使用的WGAN-GP判别器基础上,我们在DeblurGAN-v2中提出了几项升级。我们首先在LSGAN[30]的成本函数上采用了相对论“包装”方法[16],创建了一个新的RaGAN-LS损失:
L D RaLSGAN = E x ∼ p data ( x ) [ ( D ( x ) − E z ∼ p z ( z ) D ( G ( z ) ) − 1 ) 2 ] + E z ∼ p z ( z ) [ ( D ( G ( z ) ) − E x ∼ p data ( x ) D ( x ) + 1 ) 2 ] \begin{aligned} L_{D}^{\text {RaLSGAN }} & =\mathbb{E}_{x \sim p_{\text {data }}(x)}\left[\left(D(x)-\mathbb{E}_{z \sim p_{z}(z)} D(G(z))-1\right)^{2}\right] \\ & +\mathbb{E}_{z \sim p_{z}(z)}\left[\left(D(G(z))-\mathbb{E}_{x \sim p_{\text {data }}(x)} D(x)+1\right)^{2}\right] \end{aligned} LDRaLSGAN =Ex∼pdata (x)[(D(x)−Ez∼pz(z)D(G(z))−1)2]+Ez∼pz(z)[(D(G(z))−Ex∼pdata (x)D(x)+1)2]
与使用WGAN-GP目标相比,观察到这种方法可以使训练更快且更稳定。我们还根据经验得出结论,生成的结果具有更高的感知质量和更清晰的输出。相应地,DeblurGANv2生成器的对抗损失 L a d v L_{adv} Ladv将针对G优化(2)。
扩展至全局和局部尺度。Isola等人[13]建议使用PatchGAN判别器,该判别器在大小为70×70的图像块上操作,这证明可以产生比标准“全局”判别器(对整个图像进行操作)更清晰的结果。PatchGAN的想法在DeblurGAN中得到了采纳[21]。
然而,我们观察到,对于高度不均匀的模糊图像,尤其是涉及复杂物体运动的情况时,“全局”尺度对于判别器来说仍然非常重要,以便纳入完整的空间上下文[14]。为了充分利用全局和局部特征,我们提出使用双尺度判别器,由一个在像[13]那样的补丁级别上操作的局部分支和一个接收整个输入图像的全局分支组成。我们观察到,这样可以让DeblurGAN-v2更好地处理更大且更复杂的真实模糊情况。
整体损失函数。在训练图像恢复GAN时,需要在训练阶段比较重建图像和原始图像,采用某种度量标准。一个常见的选择是像素空间损失 L P L_{P} LP,例如最简单的 L 1 L_{1} L1或 L 2 L_{2} L2距离。正如[23]所指出的,使用 L P L_{P} LP往往会导致像素空间输出过于平滑。[21]建议使用感知距离[15]作为“内容”损失 L X L_{X} LX。与 L 2 L_{2} L2不同,它在VGG19[41]的conv3_3特征图上计算欧氏损失。我们整合了这些先前的智慧,并使用一个混合的三项损失来训练DeblurGAN-v2:
L G = 0.5 ∗ L P + 0.006 ∗ L X + 0.01 ∗ L a d v L_{G} = 0.5 * L_{P} + 0.006 * L_{X} + 0.01 * L_{adv} LG=0.5∗LP+0.006∗LX+0.01∗Ladv
L a d v L_{adv} Ladv项包含全局和局部判别器损失。此外,我们选择均方误差(MSE)损失作为 L P L_{P} LP:尽管DeblurGAN没有包含 L P L_{P} LP项,但我们发现它有助于纠正颜色和纹理失真。
3.4、训练数据集
GoPro数据集[33]使用GoPro Hero 4相机捕获每秒240帧(fps)的视频序列,并通过平均连续短曝光帧来生成模糊图像。它是图像运动模糊的一个常见基准,包含3,214对模糊/清晰图像。我们遵循相同的划分[33],使用2,103对图像进行训练,其余1,111对图像进行评估。
DVD数据集[42]收集了71个由各种设备(如iPhone 6s、GoPro Hero 4和Nexus 5x)以240fps拍摄的现实世界视频。作者通过平均连续短曝光帧来近似更长的曝光时间,生成了6708对合成模糊和清晰图像[46]。该数据集最初用于视频去模糊,但后来也被引入到图像去模糊领域。
NFS数据集[17]最初是为了基准视觉对象跟踪而提出的。它包含75个使用iPhone 6和iPad Pro的高帧率相机拍摄的视频。此外,还从YouTube收集了25个序列,这些序列是使用各种不同设备以240fps拍摄的。它涵盖了各种场景,包括运动、跳伞、水下、野生动物、路边和室内场景。

训练数据准备:传统上,模糊帧是通过连续清晰帧的平均值来生成的。然而,我们注意到直接平均帧时会出现不真实的重影效果,如图3(a)©所示。为了缓解这一问题,我们首先使用视频帧插值模型[34]将原始240fps视频增加到3840fps,然后在相同的时间窗口内(但现在有更多的帧)进行平均池化。这会导致更平滑和更连续的模糊效果,如图3(b)(d)所示。实验上,这种数据准备并没有明显影响PSNR/SSIM,但观察到视觉质量结果有所改善。
4、实验评估
4.1、实现细节
我们使用PyTorch[1]实现了我们所有的模型。我们通过从GoPro和DVD数据集中选择每秒的第二帧,以及从NFS数据集中选择每十帧,来组成我们的训练集,希望减少对任何特定数据集的过拟合。然后,我们在得到的约10,000对图像对上训练DeblurGANv2。我们评估了三种骨干网络:Inception-ResNetv2、MobileNet和MobileNet-DSC。前者针对高性能去模糊,而后两者更适合资源受限的边缘应用。具体来说,极其轻量级的DeblurGANv2(MobileNet-DSC)比DeblurGAN-v2(Inception-ResNet-v2)少用了96%的参数。
所有模型均使用单个Tesla-P100 GPU进行训练,采用Adam优化器[18],学习率初始设为10-4,进行150个周期的训练,接着再进行150个周期的训练,期间学习率线性衰减至10-7。在训练的前3个周期内,我们冻结了预训练骨干网络的权重,之后解冻所有权重并继续训练。未预训练的部分使用随机高斯分布进行初始化。整个训练过程需要5天才能收敛。由于模型是完全卷积的,因此可以应用于任意大小的图像。
4.2、在GoPro数据集上的定量评估
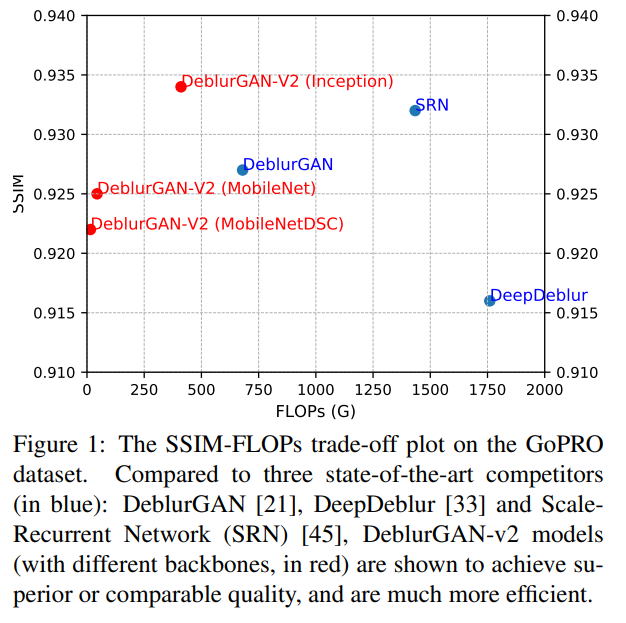
我们将我们的模型与一系列最先进的模型进行了比较:其中一个是Xu等人提出的传统方法[51],其余都是基于深度学习的模型,包括Sun等人提出的模型[43]、DeepDeblur[33]、SRN[45]和DeblurGAN[21]。我们在标准性能指标(PSNR、SSIM)和推理效率(在单个GPU上测量的平均每张图像的运行时间)上进行了比较。结果总结在表1中。
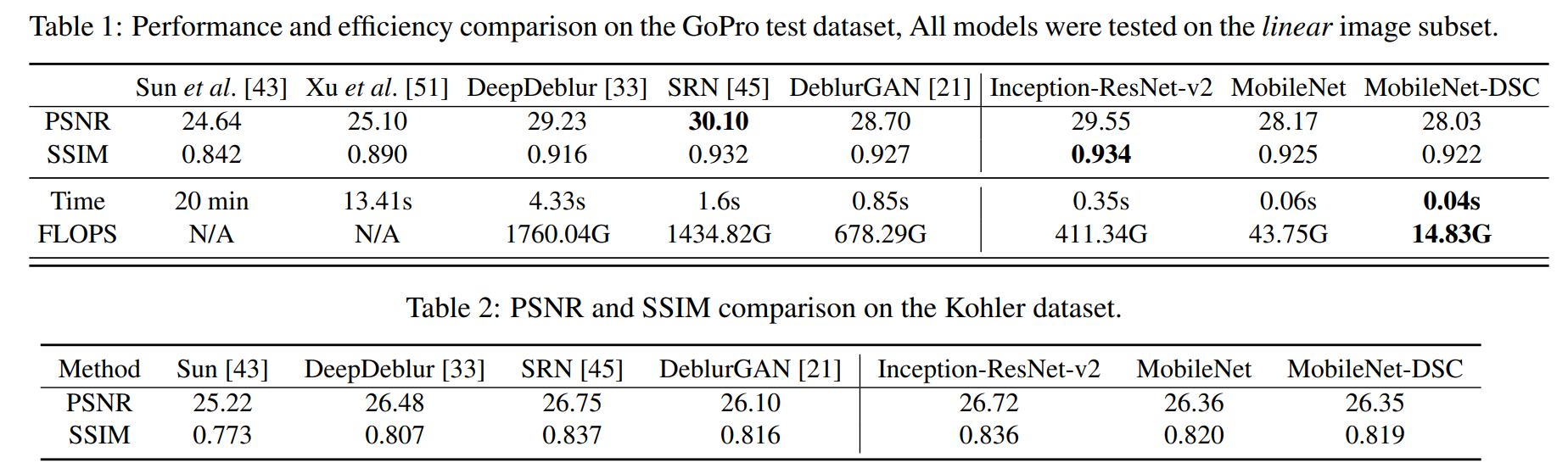
在PSNR/SSIM方面,DeblurGAN-v2(InceptionResNet-v2)和SRN排名前二:DeblurGAN-v2(Inception-ResNet-v2)的PSNR略低,这并不奇怪,因为它不是在纯MSE损失下训练的;但它在SSIM上超过了SRN。然而,我们很高兴地观察到,DeblurGAN-v2(InceptionResNet-v2)的推理时间比SRN少了78%。此外,我们的两个轻量级模型,DeblurGAN-v2(MobileNet)和DeblurGAN-v2(MobileNet-DSC),显示出的SSIM(0.925和0.922)与其他两种最新的深度去模糊方法,即DeblurGAN(0.927)和DeepDeblur(0.916),相当,但它们的运行速度却快达100倍。
特别值得一提的是,MobileNet-DSC每张图像仅需要0.04秒,这使得它甚至能够实现接近实时的视频帧去模糊,对于25帧每秒的视频来说尤为适用。据我们所知,DeblurGAN-v2(MobileNet-DSC)是目前唯一能够同时实现(相对)高性能和高推理效率的去模糊方法。
4.3、Kohler数据集上的定量评估
Kohler数据集[19]包含4张图像,每张图像都使用12种不同的模糊核进行模糊处理。它是评估盲去模糊算法的标准基准。该数据集是通过记录和分析真实的相机运动,然后在机器人平台上回放这些运动,从而记录一系列清晰图像,采样6D相机运动轨迹生成的。
比较结果如表2所示。与GoPro数据集类似,SRN和DeblurGAN-v2(Inception-ResNetv2)仍然是PSNR/SSIM表现最好的两个模型,但这次SRN在两者中略胜一筹。然而,请注意,与GoPro的情况类似,这一“几乎打成平手”的结果是在DeblurGAN-v2(Inception-ResNet-v2)的推理复杂度仅为SRN的五分之一的情况下实现的。此外,DeblurGAN-v2(MobileNet)和DeblurGAN-v2(MobileNet-DSC)在Kohler数据集的SSIM和PSNR上都超过了DeblurGAN,考虑到前两个模型的权重更轻,这一表现令人印象深刻。

图4展示了Kohler数据集上的视觉示例。DeblurGAN-v2有效地恢复了边缘和纹理,没有明显的伪影。对于这个特定的示例,SRN在放大时显示了一些颜色伪影。
4.4、DVD数据集上的定量评估
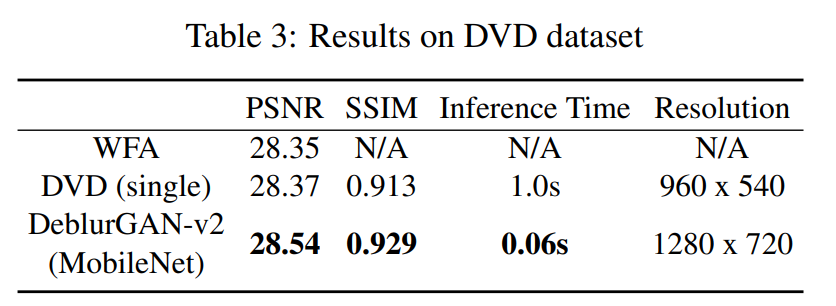
接下来,我们在[42]中使用的DVD测试集上测试DeblurGAN-v2,但使用单帧设置(将所有帧视为单独的图像),而不使用多帧联合处理。我们与两种强大的视频去模糊方法进行比较:WFA[7]和DVD[42]。对于后者,我们采用作者在将单帧作为模型输入时自行报告的结果(表示为“single”),以便进行公平比较。如表6所示,DeblurGAN-v2(MobileNet)在性能上优于WFA和DVD(single),同时运行速度至少快17倍(DVD在降低分辨率至960x540上进行测试,而DeblurGAN-v2在1280x720上进行测试)。
尽管DeblurGAN-v2并未专门针对视频去模糊进行优化,但它显示出良好的潜力,我们将在未来的工作中将其扩展到视频去模糊领域。
4.5、Lai数据集上的主观评估
Lai数据集[22]包含不同质量和分辨率的真实模糊图像,这些图像是在各种场景中收集的。这些真实图像没有清晰/锐利的对应图像,因此无法进行全参考定量评估。遵循[22]的做法,我们进行了一项主观调查,以比较这些真实图像上的去模糊性能。
我们采用Bradley-Terry模型[3]来估计每种方法的主观得分,以便进行排名。这一流程遵循了先前的基准工作[24,26]。每张模糊图像都使用以下算法进行处理:Krishnan等人[20],Whyte等人[49],Xu等人[51],Sun等人[43],Pan等人[36],DeepDeblur[33],SRN[45],以及三种DeblurGAN-v2变体(Inception-ResNet-v2,MobileNet,MobileNet-DSC)。将十一种去模糊结果连同原始模糊图像一起发送进行成对比较,以构建获胜矩阵。我们从22位评分者处收集了成对比较结果。我们观察到评分者之间的一致性较好,个体差异较小,这使得得分可靠。
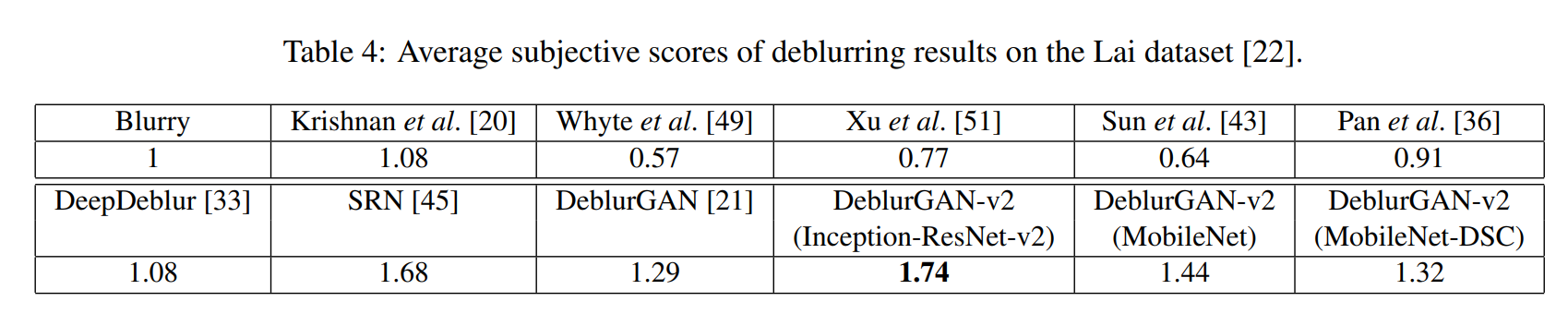
表4报告了主观得分。由于缺少真实值,我们没有对得分进行归一化处理。因此,重要的是得分排名,而不是绝对得分值。可以观察到,基于深度学习的去模糊算法通常比传统方法具有更理想的视觉效果(有些甚至使视觉质量比模糊输入更差)。DeblurGAN[21]的表现优于DeepDeblur[33],但落后于SRN[45]。使用Inception-ResNetv2作为骨干网络,DeblurGAN-v2在感知质量上明显优于SRN,成为主观质量方面的最佳表现者。与Inception-ResNet-v2版本相比,使用MobileNet和MobileNet-DSC作为骨干网络的DeblurGAN-v2在性能上略有下降。然而,与DeepDeblur和DeblurGAN相比,主观评分者仍然更偏爱这两者,同时它们的运行速度要快2-3个数量级。

图5展示了“face2”图像去模糊效果的视觉对比示例。DeblurGAN-v2(Inception-ResNet-v2)(5j)和SRN(5h)是最受欢迎的前两名结果,它们都在边缘清晰度和整体平滑度之间取得了很好的平衡。通过放大观察,我们发现SRN在这个示例中仍然产生了一些鬼影伪影,例如从衣领到右下脸部区域的白色“入侵”。相比之下,DeblurGAN-v2(Inception-ResNet-v2)显示了无伪影的去模糊效果。此外,DeblurGAN-v2(MobileNet)和DeblurGAN-v2(MobileNet-DSC)的结果也很平滑,视觉上比DeblurGAN更好,尽管它们的清晰度不如DeblurGAN-v2(Inception-ResNet-v2)。
4.6、消融研究与分析
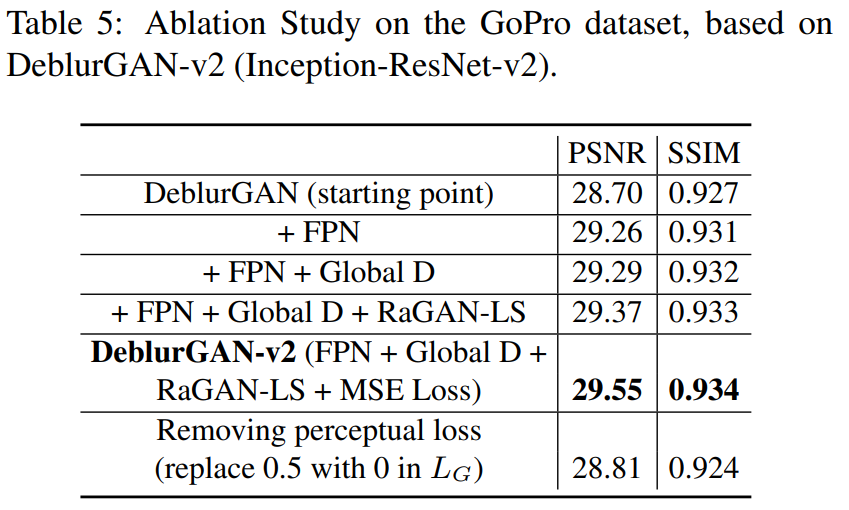
我们针对DeblurGAN-v2流程中的特定组件进行了消融研究。从原始的DeblurGAN(ResNet G,局部尺度的补丁D,WGAN-GP + 感知损失)开始,我们逐步在生成器(添加FPN)、判别器(添加全局尺度)和损失(将WGANGP损失替换为RaGAN-LS,并添加MSE项)中引入我们的修改。结果总结在表6中。我们可以看到,我们提出的所有组件都稳步提高了PSNR和SSIM。特别是,FPN模块贡献最大。此外,添加MSE或感知损失都有利于训练的稳定性和最终结果。

为了额外验证FPN的效率,我们尝试创建了一个“紧凑”版的SRN,其大约具有相同的浮点运算次数(456 GFLOPs),以匹配DeblurGAN-v2 InceptionResNet-v2(411 GFLOPs)。我们在每个EBlock/DBlock中减少了2/3的ResBlock数量,同时保持其3尺度的递归结构。然后,我们在GoPro数据集上与DeblurGAN-v2(Inception-ResNet-v2)进行比较,发现这个“紧凑”版的SRN仅实现了PSNR = 28.92 dB和SSIM = 0.9324。我们还尝试使用通道剪枝[11]来减少SRN的浮点运算次数,但结果并没有变得更好。
4.7、扩展至一般图像恢复
真实世界的自然图像通常会同时经历多种类型的退化(噪声、模糊、压缩等),而最近的一些工作致力于此类联合增强任务[32,55]。我们研究了DeblurGAN-v2在一般图像恢复任务上的效果。虽然这不是本文的主要焦点,但我们旨在展示DeblurGAN-v2的通用架构优越性,特别是相对于DeblurGAN所做的修改。
我们合成了一个新的具有挑战性的Restore数据集。我们从GoPRO中选取600张图像,从DVD中选取600张图像,这两组图像都已有运动模糊(与上述相同)。然后,我们使用albumentations库[4]进一步在这些图像上添加高斯噪声和斑点噪声、JPEG压缩以及上采样伪影。最终,我们分割出8000张图像用于训练,1200张用于测试。我们训练和比较了DeblurGAN-v2(Inception-ResNet-v2)、DeblurGAN-v2(MobileNet-DSC)和DeblurGAN。如表6和图6所示,DeblurGAN-v2(Inception-ResNet-v2)在PSNR、SSIM和视觉质量上均取得了最佳表现。

5、结论
本文介绍了DeblurGAN-v2,这是一个强大且高效的图像去模糊框架,具有令人鼓舞的定量和定性结果。DeblurGAN-v2能够在不同的主干网络之间进行切换,从而在性能和效率之间实现灵活的权衡。我们计划将DeblurGAN-v2扩展到实时视频增强和更好地处理混合退化问题。
致谢:O. Kupyn和T. Martyniuk得到了SoftServe、Let’s Enhance和UCU的支持。J. Wu和Z. Wang得到了NSF Award RI-1755701的支持。作者感谢Arseny Kravchenko、Andrey Luzan和Yifan Jiang的建设性讨论,以及Igor Krashenyi和Oles Dobosevych在计算资源方面的支持。


![[C++基础学习]----01-C++数据类型详解](https://img-blog.csdnimg.cn/direct/2184a99373804f359de6397e1cfe71d1.png)






![达梦数据查询语句不带模式名称,报错无效的表或视图名[某某表]](https://img-blog.csdnimg.cn/direct/0d72efec789f4e7d916d5984e6464667.png)