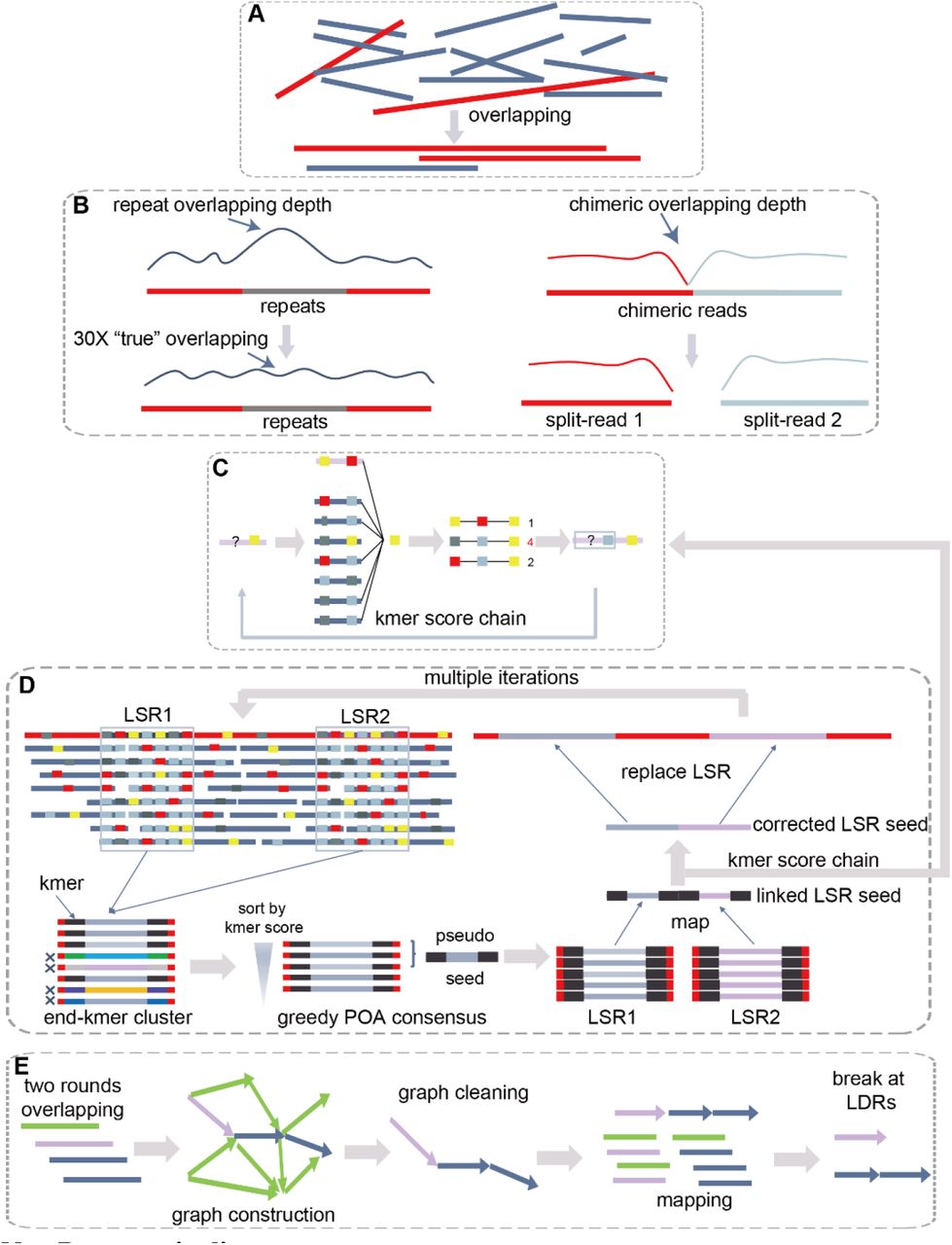
简介
NextDenovo 是一种针对长序列读取(包括CLR和ONT技术)的新型基因组组装工具。它采取了一种“先校正错误再进行组装”的方法,这与canu工具类似,但对于PacBio HiFi读取数据则无需进行校正。相较于其他工具,NextDenovo在计算资源和存储空间的需求上要小得多。完成组装后,每个碱基的准确率可以达到98%至99.8%。如果您希望进一步提升单个碱基的精确度,可以尝试使用NextPolish工具进行优化。
在性能对比测试中,我们将NextDenovo与其它几种组装工具进行了比较,测试所用的数据包括来自人类和果蝇的Oxford Nanopore长序列读取,以及来自拟南芥的PacBio连续长序列读取(CLR)。结果显示,NextDenovo在生成较少片段的连续性组装方面表现更佳。此外,NextDenovo在组装的一致性和单个碱基的精确度上也展现出了较高的准确性水平。
安装
-
直接下载
wget https://github.com/Nextomics/NextDenovo/releases/latest/download/NextDenovo.tgz
tar -vxzf NextDenovo.tgz && cd NextDenovo
-
自己编译(可选)
git clone git@github.com:Nextomics/NextDenovo.git
cd NextDenovo && make
使用
准备输入
# 准备input.fofn
ls reads1.fasta reads2.fastq reads3.fasta.gz reads4.fastq.gz ... > input.fofn
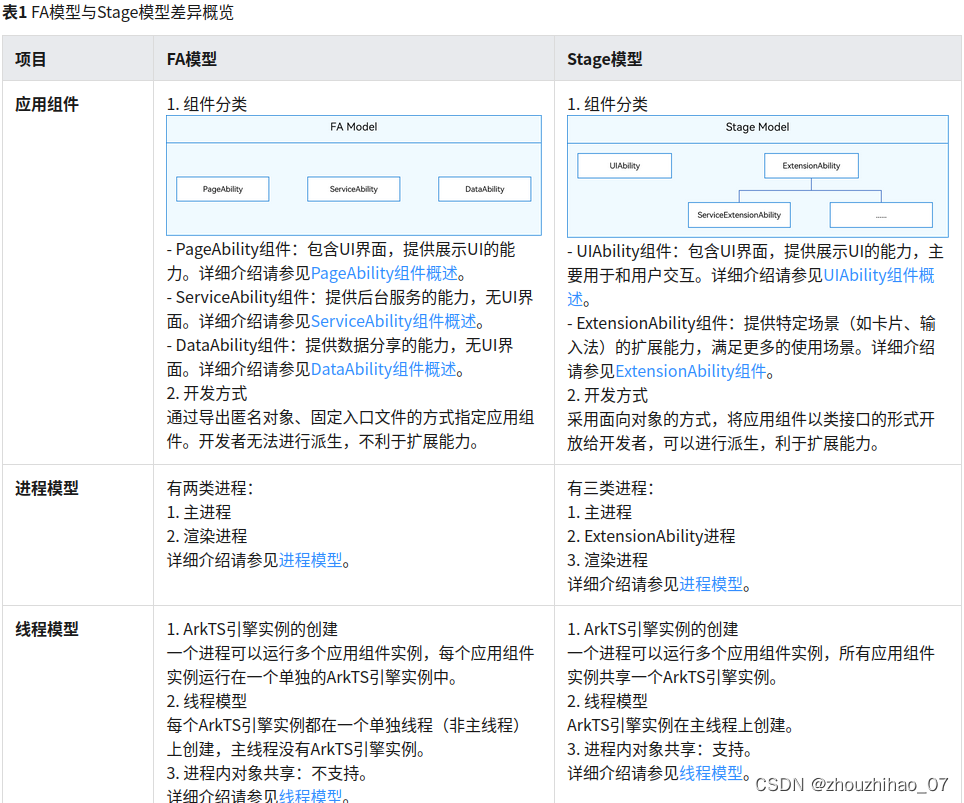
*配置文件
配置文件是一个文本文件,其中包含一组参数(键=值对),用于设置 NextDenovo 的运行时参数。以下是一个典型的配置文件,也位于 doc/run.cfg 中。
[General]
job_type = sge # local, sge, pbs, lsf, slurm… (default: sge)
job_prefix = nextDenovo
task = all
rewrite = yes
deltmp = yes
parallel_jobs = 22 # 线程
input_type = raw
read_type = ont # clr, ont, hifi 数据类型
input_fofn = input.fofn # 输入文件
workdir = HG002_NA24385_son_assemble # 工作目录
[correct_option]
read_cutoff = 1k # reads 截断 过滤器读取长度< read_cutoff(默认值:1k)
genome_size = 3g # estimated genome size 基因组大小
sort_options = -m 50g -t 30 # sort 内存+线程
minimap2_options_raw = -t 8 # minimap2 选项,用于查找原始读取之间的重叠
pa_correction = 5
correction_options = -p 30
[assemble_option]
minimap2_options_cns = -t 8 # minimap2 选项,用于查找校正读数之间的重叠
nextgraph_options = -a 1
-
有关 correction_options 参数
使用选项 -p 或 --process 可以设定用于序列校正任务的并行进程数,默认设置为10个进程。
选项 -b 或 --blacklist 允许用户禁用数据过滤步骤,以便获得更多的校正后数据。
-s 或 --split 选项用于将校正后的序列种子与未校正的区域进行分离,默认不启用此功能。
启用 -fast 选项可以提升程序运行速度至原来的1.5至2倍,但这可能会略微牺牲校正的准确度,默认情况下此功能是关闭的。
-dbuf 选项用于关闭2bit文件格式的缓存,从而减少大约为输入总碱基数四分之一的内存使用量,该选项同样默认不启用。
-max_lq_length 参数用于设定校正序列种子中允许的连续低质量区域的最大长度。如果将此值设置得更大,可以获得更多的校正数据,但这会以牺牲校正的准确度为代价。默认情况下,该参数会根据使用的测序平台自动调整,对于PacBio平台是1k,对于ONT平台是10k。
运行
# 运行
nextDenovo run.cfg
结果
在目录 workdir/03.ctg_graph/ 下的文件 nd.asm.fasta 中,包含了以fasta格式存储的连续序列信息。每个序列的fasta头部信息包括了序列的ID、类型、长度以及节点数量。
在序列中,如果出现连续的小写字母的区域,则意味着该处的连接可能不够稳定。此外,序列中用单个小写字母表示的碱基是质量较低的。
在同一个目录下的另一个文件 nd.asm.fasta.stat 包含了一些基础的统计数据,如N50、N70、N90等指标,以及总的序列大小等信息。
要点
-
组装大小小于预期基因组大小时的参数调整
对于高度杂合的基因组,可以尝试设置nextgraph_options = -a 1 -A。否则,可以在nextgraph_options中将-q的值从5调整到16。测试表明,设置nextgraph_options = -a 1 -q 10通常能获得最佳结果。
-
nd.asm.p.fasta与最终组装结果nd.asm.fasta的区别
nd.asm.p.fasta理论上包含比nd.asm.fasta更多的结构和碱基错误。可以选择nd.asm.p.fasta作为最终组装结果,但应首先验证组装质量。
本文由 mdnice 多平台发布

![达梦数据查询语句不带模式名称,报错无效的表或视图名[某某表]](https://img-blog.csdnimg.cn/direct/0d72efec789f4e7d916d5984e6464667.png)