设计一个基于matlab的汽车牌照识别程序,能够实现车牌图像预处理,车牌定位,字符分割,然后通过神经网络对车牌进行字符识别,最终从一幅图像中提取车牌中的字母和数字,给出文本形式的车牌号码。
关键词:车牌识别,matlab,神经网络
一、引言
随着我国交通运输的不断发展,智能交通系统(Intelligent Traffic System,简称ITS)的推广变的越来越重要,而作为ITS的一个重要组成部分,车辆牌照识别系统(vehicle license plate recognition system,简称LPR)对于交通管理、治安处罚等工作的智能化起着十分重要的作用。它可广泛应用于交通流量检测,交通控制于诱导,机场,港口,小区的车辆管理,不停车自动收费,闯红灯等违章车辆监控以及车辆安全防盗等领域,具有广阔的应用前景。由于牌照是机动车辆管理的唯一标识符号,因此,车辆牌照识别系统的研究在机动车管理方面具有十分重要的实际意义。
二、车辆牌照识别系统工作原理
车辆牌照识别系统的基本工作原理为:将摄像头拍摄到的包含车辆牌照的图像通过视频卡输入到计算机中进行预处理,再由检索模块对牌照进行搜索、检测、定位,并分割出包含牌照字符的矩形区域,然后对牌照字符进行二值化并将其分割为单个字符,然后输入JPEG或BMP格式的数字,输出则为车牌号码的数字。

三、车辆牌照识别系统组成
图像预处理:对汽车图像进行图像转换、图像增强和边缘检测等。
车牌定位:从预处理后的汽车图像中分割出车牌图像。即在一幅车辆图像中找到车牌所在的位置。
字符分割:对车牌图像进行几何校正、去噪、二值化以及字符分割以从车牌图像中分离出组成车牌号码的单个字符图像
字符识别:对分割出来的字符进行预处理(二值化、归一化),然后分析提取,对分割出的字符图像进行识别给出文本形式的车牌号码。
四、汽车牌照识别系统的matlab实现
4.1 图像预处理与车牌定位
输入的彩色图像包含大量颜色信息,会占用较多的存储空间,且处理时也会降低系统的执行速度,因此对图像进行识别等处理时,常将彩色图像转换为灰度图像,以加快处理速度。对图像进行灰度化处理、边缘提取、再利用形态学方法对车牌进行定位。具体步骤如下:首先对图像进行灰度转换,二值化处理然后采用4X1的结构元素对图像进行腐蚀,去除图像的噪声。采用25X25的结构元素,对图像进行闭合应算使车牌所在的区域形成连通。在进行形态学滤波去除其它区域。
I=imread('DSC01344.jpg');%读取图像figure();subplot(3,2,1),imshow(I),title('原始图像');
I1=rgb2gray(I);%转化为灰度图像subplot(3,2,2),imshow(I1),title('灰度图像');
I2=edge(I1,'roberts',0.09,'both');%采用roberts算子进行边缘检测subplot(3,2,3),imshow(I2),title('边缘检测后图像');
se=[1;1;1];%线型结构元素I3=imerode(I2,se);%腐蚀图像二值化处理然后采用4X1的结构元素对图像进行腐蚀, %去除图像的噪声subplot(3,2,4),imshow(I3),title('腐蚀后边缘图像');
se=strel('rectangle',[25,25]);矩形结构元素I4=imclose(I3,se);%图像聚类、填充图像imclose:闭合subplot(3,2,5),imshow(I4),title('填充后图像');
I5=bwareaopen(I4,2000);%去除聚团灰度值小于2000的部分subplot(3,2,6),imshow(I5),title('形态滤波后图像');
[y,x,z]=size(I5);
I6=double(I5); % size(I6)为480*640,I6为二值化后的矩阵,只有0和1
Y1=zeros(y,1); % 把Y1初始化为全为0的480维列向量
for i=1:y %以下循环统计每行的像素点灰度值累积和,是为了找出车牌位置是以哪行开始以及截止
for j=1:x
if(I6(i,j,1)==1) % I6(i,j,1)就表示I6(i,j)那个1表示第三维度,I6(i,j,2)就会出错,超出矩阵维度
Y1(i,1)= Y1(i,1)+1;
end
end
end
[temp MaxY]=max(Y1); % temp=259是列向量Y1的最大值, MaxY=175是最大值对应索引值
figure();
subplot(3,2,1),plot(0:y-1,Y1),title('行方向像素点灰度值累计和'),xlabel('行值'),ylabel('像素'); 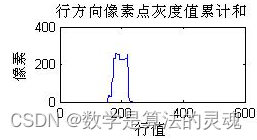
%%%%%%%求的车牌的行起始位置PY1和终止位置PY2%%%%%%%%%
%%% Y1是列向量,每个元素是每行的元素为1的总和
PY1=MaxY; %列向量Y1的最大值索引值赋给PY1,即该行的白点(因为白色是车牌号,黑色是背景) %最多即是车牌的行起始位置?错,行起始位置不一定白点最多,所以才有下面的对PY1 %的操作
%%%索引值自减直到索引到Y1中某行白点个数小于50为止的行数即为车牌行数起始位置
while ((Y1(PY1,1)>=50)&&(PY1>1)) %当Y1最大值>=50并且最大值索引>1时。MATLAB的索引从1开始
PY1=PY1-1; % 索引值自减1
end
PY2=MaxY; %PY2是行终止位置
%%%索引值自增直到索引到Y1中某行白点个数小于50为止的行数即为车牌行数起始位置
while ((Y1(PY2,1)>=50)&&(PY2<y)) %当Y1最大值>=50并且最大值索引<y时,停止循环
PY2=PY2+1; % 索引值自加1
end
IY=I(PY1:PY2,:,:); %把从PY1到PY2的所有行赋给IY
X1=zeros(1,x); % 把Y1初始化为全为0的640维行向量
for j=1:x %以下循环统计每列的像素点灰度值累积和
for i=PY1:PY2
if(I6(i,j,1)==1)
X1(1,j)= X1(1,j)+1;
end
end
end
subplot(3,2,2),plot(0:x-1,X1),title('列方向像素点灰度值累计和'),xlabel('列值'),ylabel('像数');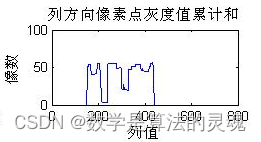
%%%%%%%求的车牌的列起始位置和终止位置%%%%%%%%%
%%%本方法与求车牌的行起始位置的求法不一样。就当做是介绍了两个方法
%%%方法1:找出最大行/列,然后从最大行/列开始索引自增自减来找到行/列起始/终止位置
%%%方法2:不用找出最大行/列,而是直接从1开始索引自增,以及从最后索引自减来找到起始/终止位置
PX1=1;
while ((X1(1,PX1)<3)&&(PX1<x)) %当检索到第一个某列的像素灰度值和>=3时停止循环。
PX1=PX1+1; %索引自加1
end
PX2=x;
while ((X1(1,PX2)<3)&&(PX2>PX1)) %倒着检索,当检索到第一个某列的像素灰度值和>=3时停止循环。
PX2=PX2-1;
end
PX1=PX1-1; %列起始位置索引为什么要减一
PX2=PX2+1;
%分割出车牌图像%
dw=I(PY1:PY2,PX1:PX2,:);
subplot(3,2,3),imshow(dw),title('定位剪切后的彩色车牌图像')
4.2 车牌字符分割
确定车牌位置后下一步的任务就是进行字符切分分离出车牌号码的全部字符图像。
if isrgb(I)
I1 = rgb2gray(I); %将RGB图像转化为灰度图像
else I1=I; end
g_max=double(max(max(I1)));
g_min=double(min(min(I1)));
T=round(g_max-(g_max-g_min)/3); % T为二值化的阈值
[m,n]=size(I1); % d:二值图像
%h=graythresh(I1); %graythresh是一个函数,功能是使用最大类间方差法找
%到图片的一个合适的阈值。利用这个阈值通常比人为设定阈
%值能更好地把一张灰度图像转换为二值图像
I1=im2bw(I1,T/256);
subplot(3,2,4);
imshow(I1),title('二值化车牌图像');
I2=bwareaopen(I1,20);subplot(3,2,5);imshow(I2),title('形态学滤波后的二值化图像');
[y1,x1,z1]=size(I2);
I3=double(I2);
TT=1;
%%%%%%%去除图像顶端和底端的不感兴趣区域%%%%%
Y1=zeros(y1,1);
for i=1:y1
for j=1:x1
if(I3(i,j,1)==1)
Y1(i,1)= Y1(i,1)+1 ;
end
end
end
Py1=1;
Py0=1;
while ((Y1(Py0,1)<20)&&(Py0<y1))
Py0=Py0+1;
end
Py1=Py0;
while((Y1(Py1,1)>=20)&&(Py1<y1))
Py1=Py1+1;
end
I2=I2(Py0:Py1,:,:);
subplot(3,2,6);
imshow(I2),title('目标车牌区域');
%%%%%% 分割字符按行积累量%%%%%%%
X1=zeros(1,x1);
for j=1:x1
for i=1:y1
if(I3(i,j,1)==1)
X1(1,j)= X1(1,j)+1;
end
end
end
figure(5);
plot(0:x1-1,X1),title('列方向像素点灰度值累计和'),xlabel('列值'),ylabel('累计像素量');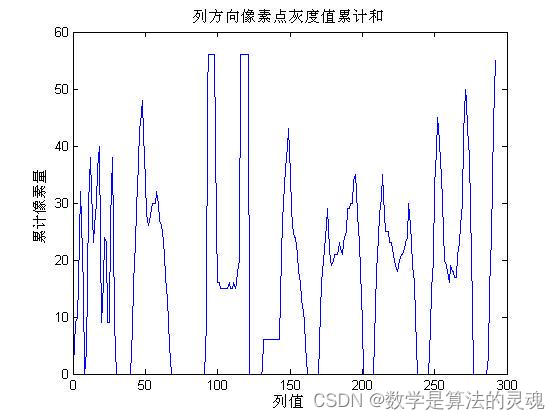
Px0=1;
Px1=1;
%%%%%%%%%%%%分割字符%%%%%%%%%%%%%%%%%%
for i=1:7
while ((X1(1,Px0)<3)&&(Px0<x1)) %从第一列循环直到某列像素和>=3停止循环
Px0=Px0+1;
end
Px1=Px0; %把第一个像素和>=3的列赋给Px1。以便从Px1开始检索字符,因为还需要用到Px0,所以不能 %再让Px0变化,把Px0值赋给Px1,这样就把终止列变成了Px1
while (((X1(1,Px1)>=3)&&(Px1<x1))||((Px1-Px0)<10)) %从PX1列开始循环直到某列像素和<3或者索引差 % (Px1-Px0)<10即每个字符的小于十个像素点
Px1=Px1+1;
end
Z=I2(:,Px0:Px1,:); %把二值化后的图像I2的Px0到Px1列剪切给Z
switch strcat('Z',num2str(i)) %把’Z’和数字连接起来变成’Z1’、’Z2’等。这一句在for循环中
%为什么不直接赋值,用什么for循环和switch搞得那么屌的样子?
%答:因为每次循环的Z值不同,所以需要把Z值分别赋给Z1,Z2等。每次循
%环把不同的Z值赋给一个Zi. 每次循环得到的Z矩阵对应
case 'Z1'
PIN0=Z;
case 'Z2'
PIN1=Z;
case 'Z3'
PIN2=Z;
case 'Z4'
PIN3=Z;
case 'Z5'
PIN4=Z;
case 'Z6'
PIN5=Z;
otherwise
PIN6=Z;
end
figure(3);
subplot(1,7,i); %这条语句还在对于i的for循环中。一行七列的区块图像
imshow(Z); %由for循环依次显示出来 
Px0=Px1; %这句话作用是不是把每个字符的列起始位置赋值为上一个字符的结束位置end4.3 车牌字符识别
字符识别方法主要有基于模板匹配算法和基于人工神经网络算法。基于模板匹配算法是首先将分割后的字符二值化,并将其尺寸缩放为字符数据库中模板的大小,然后与所有模板进行匹配,最后选取最佳匹配作为结果。建立数字库对该方法在车牌识别过程中很重要, 数字库准确才能保证检测出的数据正确。基于人工神经元网络的算法有两种,一种是先对特征提取待识别字符,然后用所获得的特征训练神经网络分配器;另一种是直接将待处理图像输入网络由网络自动实现特征提取直至识别结果。在本程序中用基于人工神经元网络识别车牌字符。在车牌字符识别部分, 字符集中包含约50个汉字, 26个大写英文字母及10个阿拉伯数字。总的字符样本并不太多。
4.3.1 构造训练样本如下图所示的数字和字母,










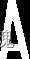







将样本进行归一化为5020大小,再将图像按列转换成一个10001的行向量,将上述18个图像的样本排列在一起构成100018的矩阵样本,尽可能多的采集汽车图像提取车牌,部分切分出车牌字符,构造出更多100018的矩形样本,用构造好的样本库对神经网络进行训练。
function inpt = pretreatment(I)
%YUCHULI Summary of this function goes here
% Detailed explanation goes here
if isrgb(I)
I1 = rgb2gray(I);
else
I1=I;
end
I1=imresize(I1,[50 20]);%将图片统一划为50*20大小.这里不管什么尺寸的矩阵都可以resize为自定义尺 %寸,就理解为缩放就行,并非有多少像素就必须resize为多少像素
I1=im2bw(I1,0.9);
[m,n]=size(I1);
inpt=zeros(1,m*n); %把inpt初始化为全为0的行向量
%%%%%%将图像按列转换成一个行向量,以下操作是对行向量inpt进行赋值操作
for j=1:n %列循环
for i=1:m %行循环
inpt(1,m*(j-1)+i)=I1(i,j); %把 I1的每一列元素依次存入行向量inpt。其中的m*(j-1)+i就是
%把第j列第i行像素赋给行向量inpt的对应索引为m*(j-1)+i处。例如 I1第1列的m个元素存入行向量inpt
%的前m个索引位置,第2列的m个元素存入行向量inpt的第m+1到2m个索引位置
end
end4.3.2 构造输入样本,按同样的方法,将前面分割出的样本归一化。

4.3.3 神经网络进行识别。
close all;
clear all;
%%%%归一化训练样本%%%%%%
I0=pretreatment(imread('0.jpg'));
I1=pretreatment(imread('1.jpg'));
I2=pretreatment(imread('2.jpg'));
I3=pretreatment(imread('3.jpg'));
I4=pretreatment(imread('4.jpg'));
I5=pretreatment(imread('5.jpg'));
I6=pretreatment(imread('6.jpg'));
I7=pretreatment(imread('7.jpg'));
I8=pretreatment(imread('8.jpg'));
I9=pretreatment(imread('9.jpg'));
I10=pretreatment(imread('A.jpg'));
I11=pretreatment(imread('C.jpg'));
I12=pretreatment(imread('G.jpg'));
I13=pretreatment(imread('L.jpg'));
I14=pretreatment(imread('M.jpg'));
I15=pretreatment(imread('R.jpg'));
I16=pretreatment(imread('H.jpg'));
I17=pretreatment(imread('N.jpg'));
P=[I0',I1',I2',I3',I4',I5',I6',I7',I8',I9',I10',I11',I12',I13',I14',I15',I16',I17'];
%输出样本%%%
T=eye(18,18);
%%bp神经网络参数设置
%minmax()求矩阵每一行向量的最大值和最小值
%函数newff建立一个可训练的前馈网络。这需要4个输入参数。
%第一个参数是一个Rx2的矩阵以定义R个输入向量的最小值和最大值;
%第二个参数是一个设定每层神经元个数的数组;
%第三个参数是包含每层用到的传递函数名称的细胞数组;
%最后一个参数是用到的训练函数的名称。
net=newff(minmax(P),[1000,32,18],{'logsig','logsig','logsig'},'trainrp');
net.inputWeights{1,1}.initFcn ='randnr';
net.layerWeights{2,1}.initFcn ='randnr';
net.trainparam.epochs=5000;
net.trainparam.show=50;
%net.trainparam.lr=0.003;
net.trainparam.goal=0.0000000001;
net=init(net);%初始化权重和偏置的工作用命令init来实现。这个函数接收网络对象并初始化权 %重和偏置后返回网络对象
%%%训练样本%%%%
[net,tr]=train(net,P,T); %神经网络训练到此结束,返回[net,tr]会在后面用到
%%%%%%%测试%%%%%%%%%
%I=imread('DSC01323.jpg');
I=imread('DSC01344.jpg');
dw=location(I);%车牌定位
[PIN0,PIN1,PIN2,PIN3,PIN4,PIN5,PIN6]=StringSplit(dw);%字符分割及处理
%%%%%%%%%%%测试字符,得到识别数值%%%%
PIN0=pretreatment(PIN0);
PIN1=pretreatment(PIN1);
PIN2=pretreatment(PIN2);
PIN3=pretreatment(PIN3);
PIN4=pretreatment(PIN4);
PIN5=pretreatment(PIN5);
PIN6=pretreatment(PIN6);
P0=[PIN0',PIN1',PIN2',PIN3',PIN4',PIN5',PIN6']; %这一句是啥,为啥要加单引号?
for i=2:7 %从2开始是因为车牌第一个是汉字,从第二个开始是字母
T0= sim(net ,P0(:,i));%T0为P0(:,i)输入神经网络得到的输出,T0为34x1的列向量
T1 = compet (T0) ; % compet是神经网络的竞争传递函数,用于指出矩阵中每列的最大值。对 %应最大值的行的值为1,其他行的值都为0
d =find(T1 == 1) - 1 %找到T1的为1的元素的索引,然后再减1是因为:比如第1个元素是1,那么对应的值是0, 索引减1则就是第0个元素是1,就表示对应值为0。就是为了索引0到9为1时对应车牌数字是0到9
if (d==10) %从10开始是因为有0到9是数字,因此把第10个索引值位置设为A
str='A';
elseif (d==11)
str='C';
elseif (d==12)
str='G';
elseif (d==13)
str='L';
elseif (d==14)
str='M';
elseif (d==15)
str='R';
elseif (d==16)
str='H';
elseif (d==17)
str='N';
else
str=num2str(d);%这一句就是把车牌对应的数字转化为字符,因为上面是从10开始给str赋值的。
end
switch i %在for循环时,i为几就把执行对应case把对应str赋给对应的stri
case 2
str1=str;
case 3
str2=str;
case 4
str3=str;
case 5
str4=str;
case 6
str5=str;
otherwise
str6=str;
end
end
%%%%%%%显示定位后的分割出的车牌彩图,%%%
%%%%%%识别结果以标题形式显示在图上%%%s=strcat('渝',str1,str2,str3,str4,str5,str6);figure();imshow(dw),title(s);完整代码:
https://download.csdn.net/download/qq_38735017/87385508