笔记内容是根据B站上面的一位老师的视频而记录了,因为我也还在学习,所以个人理解可能会出现错误,若有错误请指出。另外这篇文章会很长
B站视频连接、
numpy,matplotlib的学习记录
pandas 学习记录
SerIes结构,一图胜千言

Series创建
pd.Series(data=None, index=None, dtype=None, name=None, copy=False)
data就是输入的数据(列表,ndarray数组,字典)
index索引值,可以传递列表或者数组
dtype 指定数据类型,没有则自行推断
name 为Series指定一个名字
copy 表示对data进行拷贝,默认为False
列表创建
arr = [3,10,23,4,5]
s = pd.Series(arr)
print(s)
/*结果
0 3
1 10
2 23
3 4
4 5
index values
*/
# 通过标签取得对应的值或者修改对应的值,如果没有为-1的index,那么s[-1]会报错
字典创建
一个键对标一行,键是索引
d={'a':1,'b':2,'c':3}
s = pd.Series(d,index=list('cba'))
# 没有d对应的值,那么就是NaN
s = pd.Series(d,index=list('abd'))
print(s)
标量创建
s = pd.Series(100) ,就是只有一个
索引
下标索引
就是按照顺序来的

标签索引
就是第一列的那个,可以一次性访问多个,假设上面的Series的名字叫做s,那么s[[‘Beijing’,‘Guangzhou’]]就是取出来Beijing和Guangzhou对应的值
多标签会创建一个新的数组
s1 = s[[‘Beijing’,‘Guangzhou’]]
切片
如果是使用下标则包头不包尾,如果是使用标签则是包头又包尾
创建DataFrame对象
pandas.DataFrame(data=None,index=None,columns=None,dtype=None,copy=None)
data就是输入的数据
index就是行标签,不传就是RangeIndex(0,1,2,…,n)n代表data的元素个数
columns:列标签,不传就是RangeIndex(0,1,2,…,n)n代表data的元素个数
使用普通列表创建
data = [1,2,3,4,5,6]
df = pd.DataFrame(data)

使用嵌套列表创建
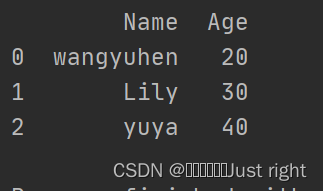
每个子列表就是一行数据
data = [['wangyuhen',20],['Lily',30],['yuya',40]]
df = pd.DataFrame(data,columns=['Name','Age'],dtype=int)
# dtype 指定数据类型,如果不符合由系统自行推断
字典嵌套列表
键对应的值的元素长度必须相同(也就是列表长度相同),如果传递了索引,那么索引的长度应该等于数组长度
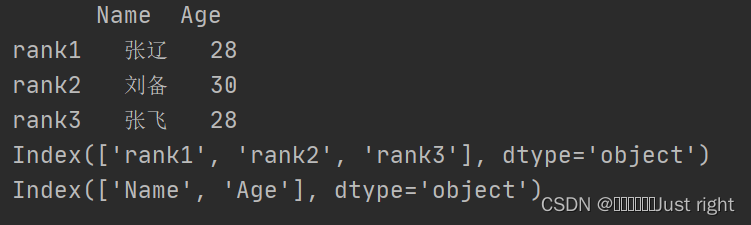
data={'Name':['张辽','刘备','张飞'],'Age':[28,30,28]}
index = ['rank1','rank2','rank3']
df = pd.DataFrame(data,index=index)
print(df)
print(df.index)
print(df.columns)
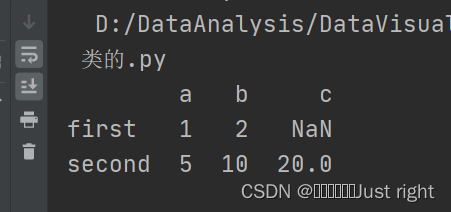
列表嵌套字典
字典的键作为列名
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data,index=['first','second'])
print(df)
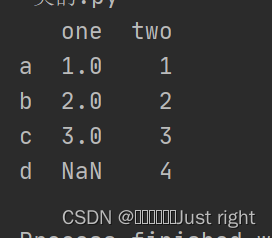
Series创建DataFrame对象
就是字典套Series
c = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(c)
print(df)
列操作DataFrame
选取数据列
直接用标签名字来选择
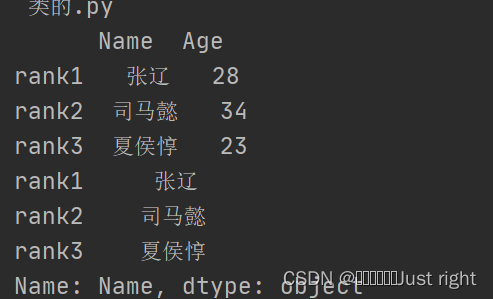
data={'Name':['张辽','司马懿','夏侯惇'],
'Age':[28,34,23]}
index=['rank1','rank2','rank3']
df = pd.DataFrame(data,index=index)
print(df)
print(df['Name'])
列添加
直接使用df[‘列’]=值
d = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
# 使用df['列']=值,插入新的数据列
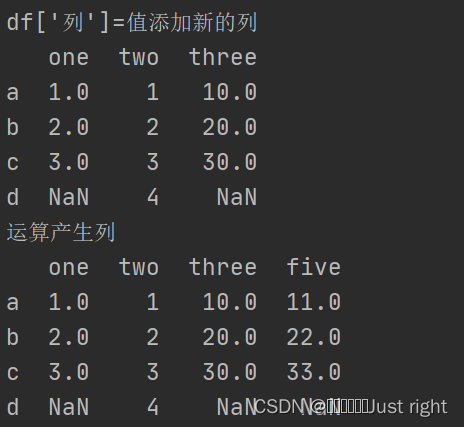
print("df['列']=值添加新的列")
df['three'] = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
print(df)
# 将已经存在的数据列相加运算,从而创建一个新的列
print("运算产生列")
df['five'] = df['one'] + df['three']
print(df)
insert方法添加
df.insert(loc, column, value, allow_duplicates=False)
# loc 就是插入的索引
# column :插入列的标签,可以是字符串,数字
# value:数值,Series或者数组
# allow_duplicates:允许重复列,默认为False
info = {'Name': ['王曦仪', '于风', '张蔷薇'],
'Age': [19, 19, 17]}
df = pd.DataFrame(info)
df.insert(1, column='Score', value=[99, 98, 98])
print(df)

删除数据列
del DataFrameName[‘列名’]
DataFrameName.pop(’列名’),这个有返回值
行操作 DataFrame
标签选取
借助于loc属性
DataFrameName.loc[列名]
DataFrameName.loc[行名,列名]
data = {'one':[1,2,3],'two':[1,2,3,4]}
df = pd.DataFrame(data,index=list('abcd'))
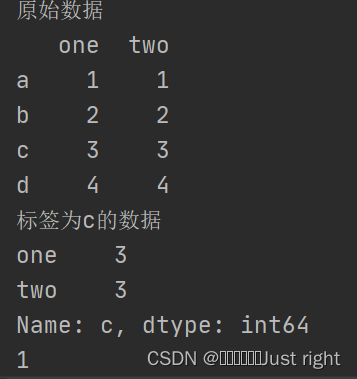
print('原始数据')
print(df)
print('标签为c的数据')
print(df.loc['c'])
print(df.loc[1,'two'])
也可以切片操作
df.loc[行名1:行名2,列名1:列名2]
df.iloc[行数1:行数2] 不包括行数2
添加行
这个有返回值
df.append(
other, ignore_index=False, verify_integrity=False, sort=False)
other:DataFrame或者Series/dic类对象,或者是这些对象的列表
ignore_index:默认为False,如果为True将不适用index标签,如果在行末追加新数据行就改为True,反之False
verify_integrity:为True,则在创建具有重复项的索引时引发ValueError,为False则不引发
sort:字面意思,排序
data={'Name':['张辽','张居正','王阳明','曹操'],'Age':[29,28,28,29],'Salary':[5000,7000,8000,10000]}
df = pd.DataFrame(data)
df=df.append({'Name':'刘备','Age':28},ignore_index=True)
print(df)
删除行
不会更改元数据,如果要改成更改元数据的,在drop中加一个inplace=True即可
dataFrameName.drop(行名也可以是索引名)
常见的一些函数
调用方式都是通过DataFrame对象名.
下面以df代替DataFrame对象名
| 名称 | 描述 | 例子 |
|---|---|---|
| T | 转置 | df.T |
| axes | 返回由行轴标签和列轴标签的列表 | df.axes |
| dtypes | 返回每列数据的数据类型 | df.dtypes |
| empty | 没有数据或者任意坐标轴的长度为0返回True | df.empty |
| columns | 返回所有列标签 | df.columns |
| shape | 返回含有行数和列数的元组 | df.shape |
| size | 返回元素个数 | df.size |
| values | 使用numpy数组表示DataFrame中的元素值 | df.values |
| rename | 修改列名的 | df.rename([index/column]={oldname:newname,…} |
| info | 打印信息 | df.info |
| sort_index(axis,ascending,inpalce) | 根据行或列进行排序 | 这个参数比较多,下面再看 |
| sor_values(by,axis,ascending,inplace,na_position) | 上同 | 上同 |
sort_index(axis,ascending,inplace)
axis:0按照行名排序,1按照列名排序
ascending:为True则升序,为False则降序
inplace:为False不影响源数据,反之影响
df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
#默认按照行进行升序排序,也可以写成axis=0,ascending=True
df.sort_index()
# 按照列标签进行升序排序
df.sort_index(axis=1)
# inplace=True,排序结果存放在元数据中
df.sort_index(axis=1,inplace=True)
sor_values(by,axis,ascending,inplace,na_position)
by:若axis=0,就是列名,若axis=1,就是行名
axis:为0就是列,为1就是行,默认按照列进行升序排序
ascending:为True就是升序,反之降序
inplace:为True影响元数据,反之不影响
na_position:为first就是NaN值排序排在第一,last就是排在最后
df = pd.DataFrame({'b':[1,2,3,2],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
# 按照b列进行升序排序
df.sort_values(by='b')
# 先按b列排序,再按a列升序排序
df.sort_values(by=list('ba'),ascending=[False,True])
# 按照行3进行升序排序
df.sort_values(by=3,axis=1)# 必须指定axis=1,要不然搞成了列了
# 按照行3升序,行0降序
df_sort_values(by=[3,0],axis=1,ascending=[True,False])
一些零碎的知识点
- 取数据的时候,先找标签,在找索引,都找不到就报错
- 通过name属性可以设置Series的名字:data.name=‘first’,通过index.name属性可以设置Series的index名字:index.name=‘index’
- 如果是根据ndarray创建的Series,一改都改,如果原数据源是非Series和ndarray类型时,对Series进行操作的时候不会改变元数据
了解之类的
DataFrame这个数据结构我觉得就像是表格,表格嘛,各个列的数据类型可以不一致.
一些技巧之类
- 查看前几条数据
pdName.head([n]) n就是几条数据,比如要查看前3条记录,那么n就是3,不写就是1,查看后几条数据就是tail(),和head一样 - reindex 重新索引,如果新设置的索引与旧的索引有不一致的地方,那么不一致地方的数据改成NaN,如果不想改成NaN可以通过fill_value来设置,fill_value=1.这个会重新生成对象
pdName.reindex(list(‘cde’)) - 对齐运算
按照索引进行对齐运算,没对齐的位置补NaN
s1 = pd.Series(np.random.rand(3), index=[“Kelly”,“Anne”,“T-C”])
s2 = pd.Series(np.random.rand(3), index=[“Anne”,“Kelly”,“LiLy”])
4.删除
pdName.drop(“索引”,inplace=False)
pdName.drop(“索引”,inplace=True)
当inplace=True时,作用到元数据,反之不作用
5. 添加
如果有该索引就是修改,无则添加
本人小白一个,若有错误请指出