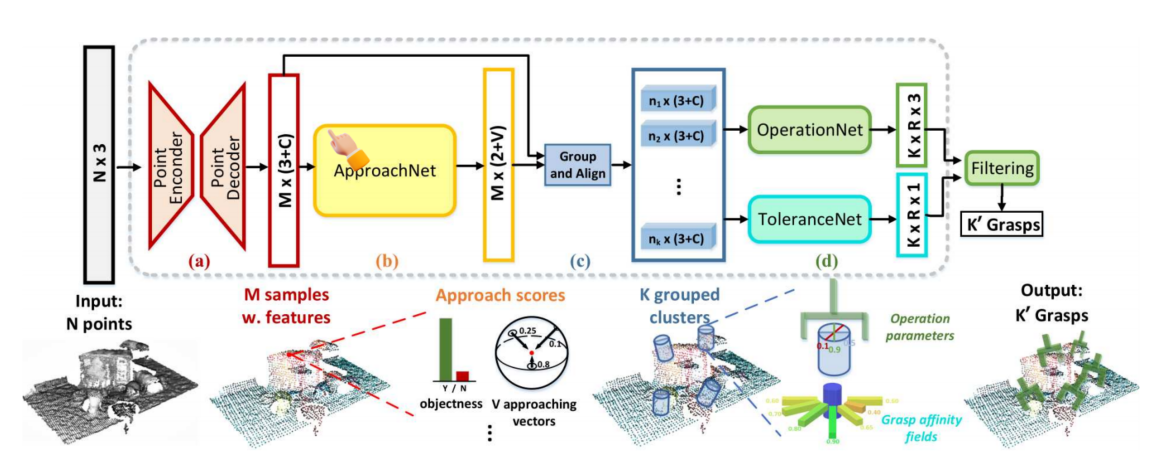
目录
摘要
Abstract
文献阅读:基于IGRA-ISSA-LSTM模型的水质预测
现有问题
提出方法
方法论
灰色关联分析(GRA)
改进的灰色关联分析(IGRA)
麻雀搜索算法(SSA)
改进的麻雀搜索算法(ISSA)
IGRA-LSTM模型
IGRA-ISSA-LSTM预测模型
总体框架
工作流程
研究实验
数据集
评估指标
实验结果
总结
摘要
本周阅读的文献《Water quality prediction based on IGRA‑ISSA‑LSTM model》中,提出了一种新的基于改进的灰色关联分析(IGRA)、改进的麻雀搜索算法(ISSA)和LSTM的混合水质预测模型IGRA-ISSA-LSTM。采用改进的灰色关联分析确定DO、pH、KMnO 4等水质指标之间的相关性,准确分析了预测变量与剩余变量之间的关系,减少数据维度以此避免LSTM维数灾问题。采用改进的麻雀搜索算法提高寻找最优LSTM超参数的能力,提高模型预测精度。在钱塘江上的试验比较了IGRA和GRA在特征选择方面的优势,以及IGRA-ISSA-LSTM预测方面的优势。结果表明准确分析水质指标间的相关性可以提高模型的预测精度。
Abstract
The literature "Water quality prediction based on IGRA ISSA LSTM model" read this week, proposes a new mixed water quality prediction model IGRA-ISSA-LSTM based on improved grey correlation analysis (IGRA), improved sparrow search algorithm (ISSA), and LSTM. The improved grey correlation analysis was used to determine the correlation between water quality indicators such as DO, pH, and KMnO4. The relationship between predicted variables and residual variables was accurately analyzed to reduce data dimensions and avoid the problem of LSTM dimensionality disaster. Adopting an improved sparrow search algorithm to enhance the ability to find the optimal LSTM hyperparameters and improve the accuracy of model prediction. The experiment on the Qiantang River compared the advantages of IGRA and GRA in feature selection, as well as the advantages of IGRA-ISSA-LSTM prediction. The results indicate that accurately analyzing the correlation between water quality indicators can improve the prediction accuracy of the model.
文献阅读:基于IGRA-ISSA-LSTM模型的水质预测
Water quality prediction based on IGRA-ISSA-LSTM model | Water, Air, & Soil PollutionIt is essential to make an accurate prediction of the concentration of dissolved oxygen (DO), hydrogen ion concentration (pH), and potassium permanganate (![]() https://doi.org/10.1007/s11270-023-06117-x
https://doi.org/10.1007/s11270-023-06117-x
- Published: 02 March 2023
现有问题
- 在过去的研究中广泛采用机器学习方法和LSTM结合的方法进行水质预测,但这些研究中LSTM的参数都是根据经验选择的,这增加了经验选择参数的盲目性,也限制了模型的适用性,因此,有必要找到LSTM的最佳超参数。麻雀搜索算法(SSA)作为一种新的算法,具有收敛速度快、目标限制低、所需调整参数少等优点。但是SSA仍然存在着容易陷入局部最优的缺陷。
- 特征选择是水质预测中首先要考虑的问题。特征选择可以从本质上减少神经网络的维数灾难现象,提高预测精度。灰色关联分析(GRA)满足基本关联分析的需要,然而GRA在处理大数据样本时存在区分度低的问题。
提出方法
- 高维数据的输入会削弱模型的计算能力和泛化能力,而降维可以通过增强数据的可读性来提高模型的预测能力。采用改进的灰色关联分析(IGRA)确定DO、pH、KMnO 4等水质指标之间的相关性,准确分析了预测变量与剩余变量之间的关系,解决长短期记忆(LSTM)维数灾问题,增强模型的学习能力。
- 具有最优参数的LSTM将具有更好的预测效果,为了避免SSA陷入局部最优,提高寻找最优LSTM超参数的能力,建立了基于改进麻雀搜索算法(ISSA)的LSTM模型,并对学习速率、批量大小、训练次数、隐层节点和全连通隐层节点5个参数进行了自动优化,能够准确预测DO、pH和KMnO 4的浓度。
方法论
灰色关联分析(GRA)
灰色关联分析方法,是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。灰色关联分析的基本思想是根据序列曲线集合形状的相似程度来判断其联系是否紧密。曲线越接近,相应序列之间的关联度就越大,反之则越小。灰色关联分析主要有两个作用:一是综合评价,给出研究对象或者方案的优劣排名。二是系统分析,判断影响系统发展的因素的重要性。
GRA由参考序列和比较序列的识别、初始化、灰色关联系数的计算和关联度的计算四个过程组成。在这项研究中DO、pH和KMnO4的值被当作参考系列,其他指标测量水质被当作比较系列。

改进的灰色关联分析(IGRA)
相关度是衡量两类数据相关程度的指标,相关度越大,说明两类特征的相关性越强。IGRA通过结合形状相似性相关系数和距离相似性相关系数,提高了GRA的灰色相关系数。具体步骤如下。
- 从比较序列中减去参考序列以形成减法矩阵,如等式(1)所示。
- 形状相似性相关系数是通过引入Δ x(k)而形成的,如等式(2)所示。
- 将参考序列与比较序列相除以形成除法矩阵,如等式(3)所示。
- 距离相似性相关系数是通过引入Δ λ x(k)而形成的,如等式(4)所示。
- 最后确定了综合关联度,如等式(5)所示。
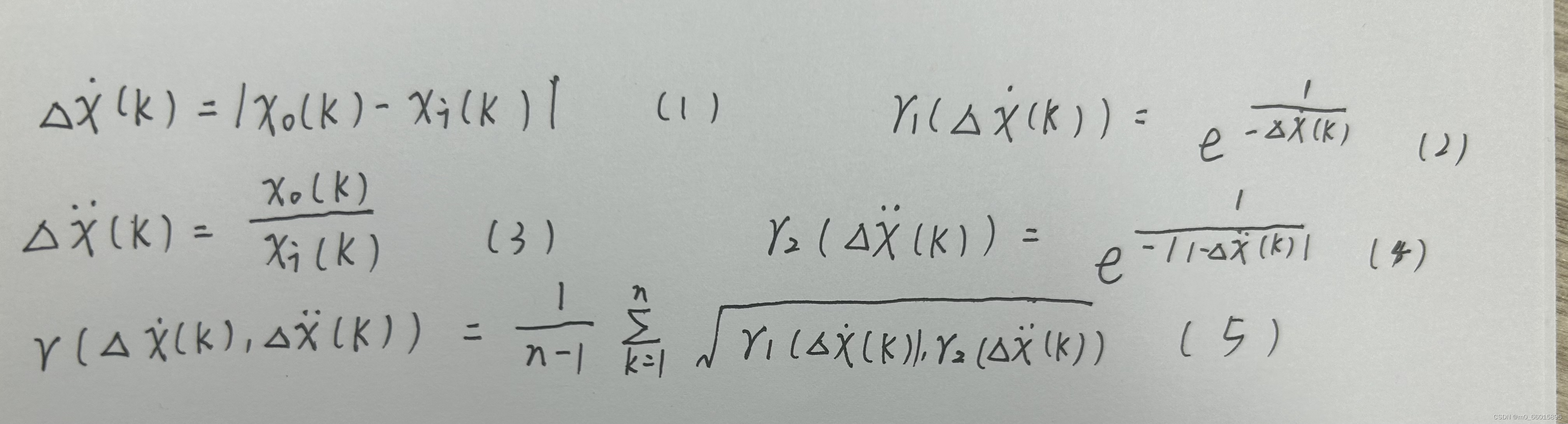
麻雀搜索算法(SSA)
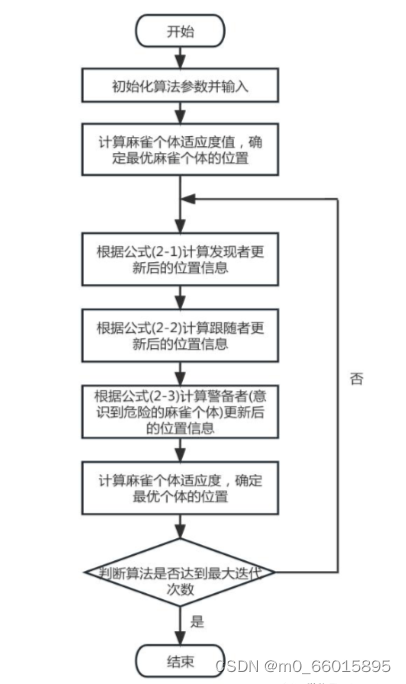
算法原理
研究发现,麻雀群内部在觅食过程中有着明确分工。内部麻雀分为两种不同类型,一种为发现者,另外为跟随者。在种群中,发现者麻雀和跟随者麻雀两者的身份是不固定的,可以灵活转变身份。同时,麻雀种群内部也会因为争夺食物而引起竞争。另外,由于种群中靠外部的麻雀更容易受到捕食者的攻击,所以麻雀种群中的个体会不断调整自身位置,向相邻的同伴靠拢或向内部聚集,以此减少被捕食的风险。
群智能算法现在经常被用来解决真实的问题,如信号处理,神经网络训练,整数约束和混合整数约束优化,函数优化和多目标优化。这些算法的可行性和有效性已经通过现实世界的结果得到了证明,麻雀搜索算法(Sparrow Search Algorithm, SSA)是受到麻雀种群的觅食行为和反捕食行为的启发,从而提出的利用麻雀的这种生物特性进行迭代寻优的优化算法。

算法流程
适应度得分越高的麻雀越有可能首先收集食物,在捕食过程中,一旦发现者找到食物,加入者立即放弃原来的位置,与发现者争夺食物;如果成功,他们可以要求食物的所有权;否则,他们继续以原始的方式行事。 麻雀种群遇到捕食者时,处于种群靠外面的麻雀会往种群中部或内部的同伴身边靠拢,这部分发现危险的麻雀称为警备者,当警备者处于边缘时就会发现危险然后调整位置,向其他麻雀靠拢,以此保证自己的安全。
改进的麻雀搜索算法(ISSA)
通过改变种群初始化方法、更新参与者公式、随机变异麻雀进行优化等措施,ISSA可以防止SSA陷入局部最优,提高算法的稳定性和全局寻优能力。改进步骤如下:
(1)正弦映射对总体进行建模。使用正弦模型初始化SSA算法的人数(麻雀数量),提高其全局优化能力。
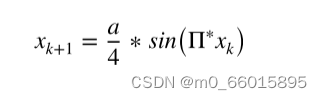
(2)在参与者更新公式中加入由改进的余弦因子控制的非线性权重。针对麻雀算法寻优能力不稳定,容易陷入全局最优的问题,引入修正余弦控制因子,自动平衡算法的全局和局部寻优能力。当一只麻雀加入一个群体时,它往往只关注一个发现者,错过其他发现者,他们有更好的机会看到猎物,进入局部最佳状态。考虑到这种情况,在参与者公式中添加了改进的余弦控制因子,从而增强了参与者的全局优化能力。
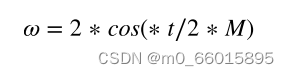
(3)Levy变异策略。结合了短距离和长距离,其中短距离步行可以提高麻雀仔细搜索附近环境的能力,远距离可以使麻雀跳出局部区域,扩大搜索范围。在SSA算法位置更新后,采用轮盘赌法选择更新种群,并引入Levy变异策略提高麻雀种群的多样性。
IGRA-LSTM模型
根据相关分析结果,将GRA和IGRA选取的与DO、pH和KMnO4相关程度较高的3个水质特征分别作为神经网络的第二、第三和第四输入,DO、pH和KMnO4分别作为神经网络的第一输入。形成多输入单输出拓扑,如图所示。
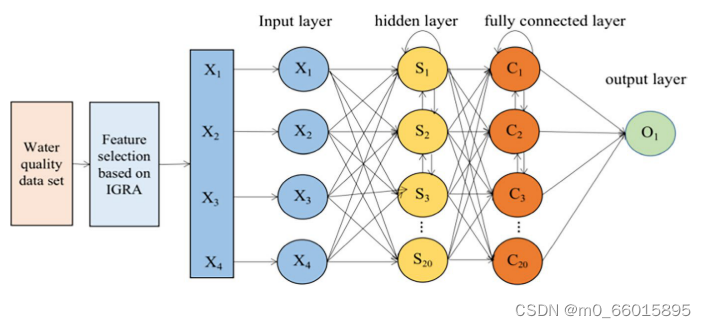
IGRA-ISSA-LSTM预测模型
总体框架
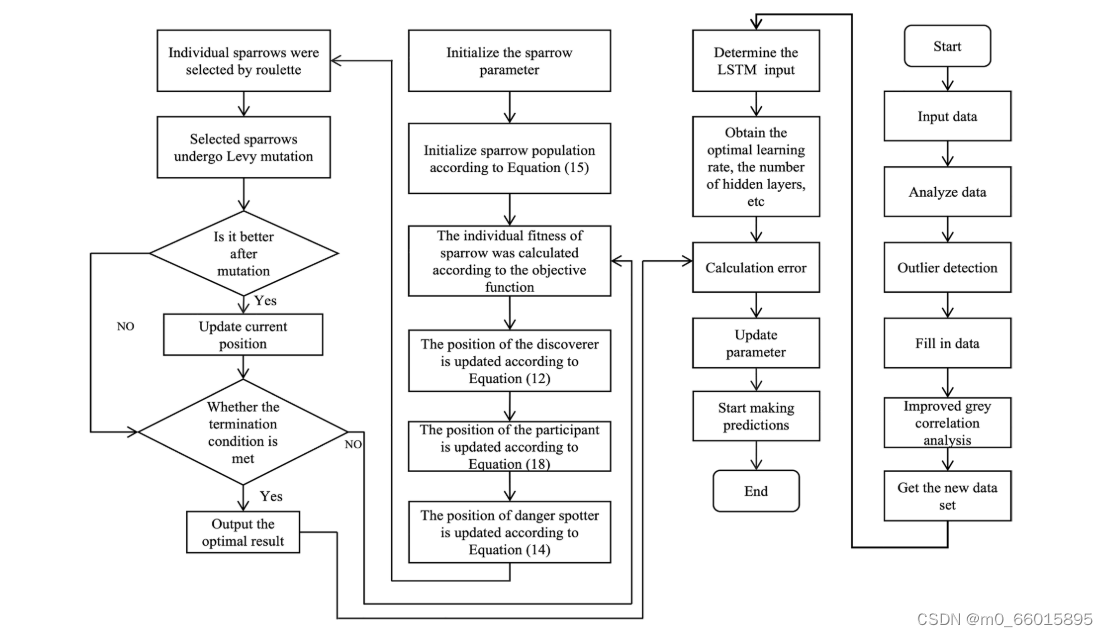
工作流程
- 首先评估数据部分,先使用隔离森林方法发现离群值并删除,然后使用拉格朗日插值法填充剔除的离群值和缺失数据
- 然后使用IGRA选择与DO、pH和KMnO 4相关性最高的几个水质指标,此外SSA也得到了改善。
- 最后,利用ISSA改变LSTM的拓扑结构,建立多输入单输出模型,预测水中DO、pH和KMnO 4含量,并对结果进行研究和比较。
研究实验
研究以DO、pH和KMnO4为例,检验IGRA-ISSA-LSTM水质预测模型的预测精度。
数据集
使用中国环境监测总站提供的钱塘江闸观测站2020年11月8日至2021年6月27日的实时数据。每4小时采样一组数据,共计1300组。(长江是强潮汐河口,由于径流和潮流的相互作用,水质波动很大。此外由于部分设备老化,很容易出现监测数据缺失的情况,因此很难准确预测水质。)
评估指标
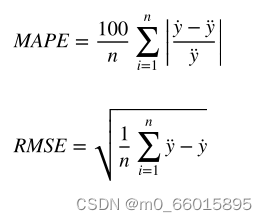
使用预测模型常用的四个评估指标,分别为平均绝对百分比(MAPE)、均方根误差(RMSE)、平均绝对误差(MAE)和决定系数(R2)。其中,为真值;
为预测值;
为平均值;n为数据量。模型的预测准确性随着MAPE、RMSE和MAE分数的降低而增加,模型拟合数据越好,R2分数越大。
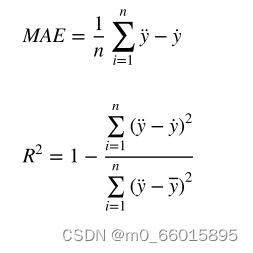
实验结果
一、验证基于IGRA-LSTM模型的水质模型预测效果
将GRA和IGRA选择的相关指标的历史数据以及预测指标的历史数据作为LSTM的输入,形成多输入单输出拓扑(如图10所示),预测第四天的DO、pH和KMnO 4浓度。下图分别是对DO、pH、KMnO4的预测结果,其中图(a)是GRA-LSTM模型的预测结果,图(b)是IGRA-LSTM模型的预测结果。

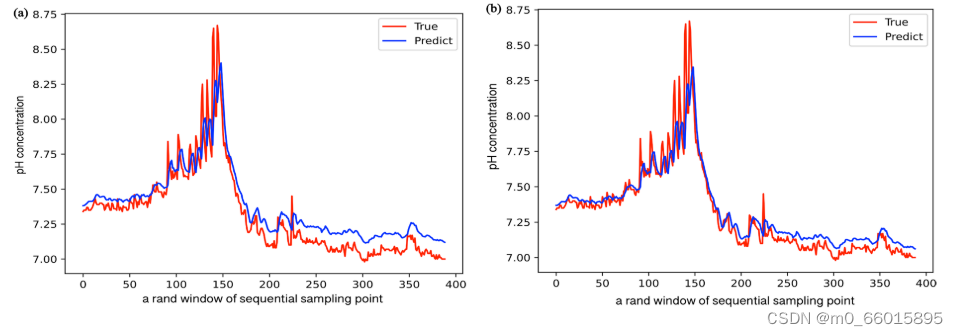
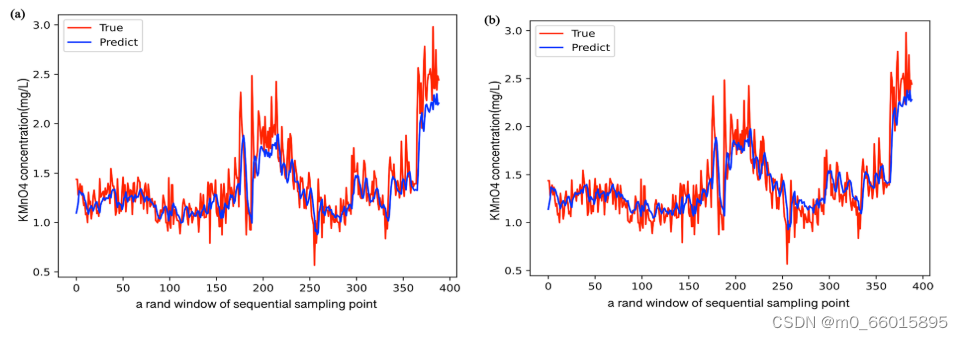
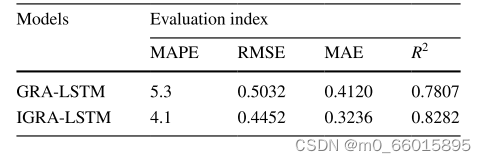
对于100-150范围内的峰值模拟,IGRA-LSTM提供了更好的拟合效果,这有助于在水质快速变化时确保模拟精度。对于后期的模拟过程,IGRA-LSTM具有较好的拟合度,可以保证水质的长期预测。在初步模拟和峰值模拟过程中,IGRA-LSTM表现更好,虽然存在欠拟合现象,但总体预测优于GRA-LSTM。
如表所示,与GRA-LSTM相比,基于IGRA-LSTM的DO、pH和KMnO 4预测都将MAPE、RMSE和MAE的值降低了,同时R2的值提高了。因此,IGRA可以有效地分析数据之间的关系,更准确地选择数据特征。

二、验证基于IGRA-ISSA-LSTM模型的水质预测效果
通过对IGRA的分析,选取与DO、pH和KMnO 4相关度较高的前3个水质指标分别作为神经网络的输入,建立了多输入单输出神经网络模型。在这项研究中,70%的数据集用作训练集,30%用作测试集,以预测第4天的DO,pH和KMnO 4浓度。下图显示了IGRA-ISSA-LSTM与其他三种模型在预测DO、pH和KMnO 4浓度方面的比较。
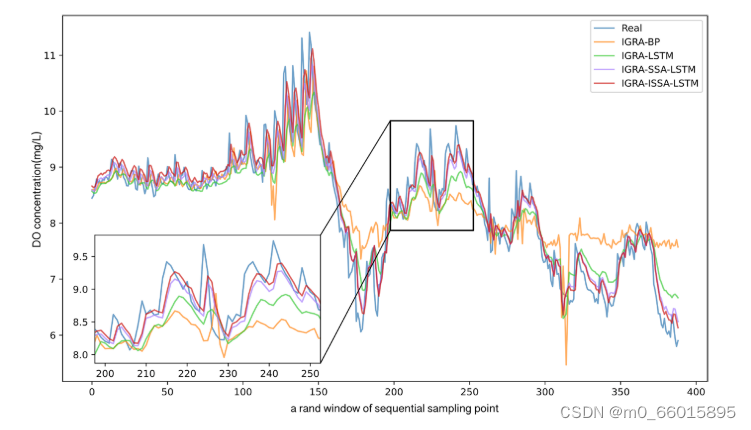
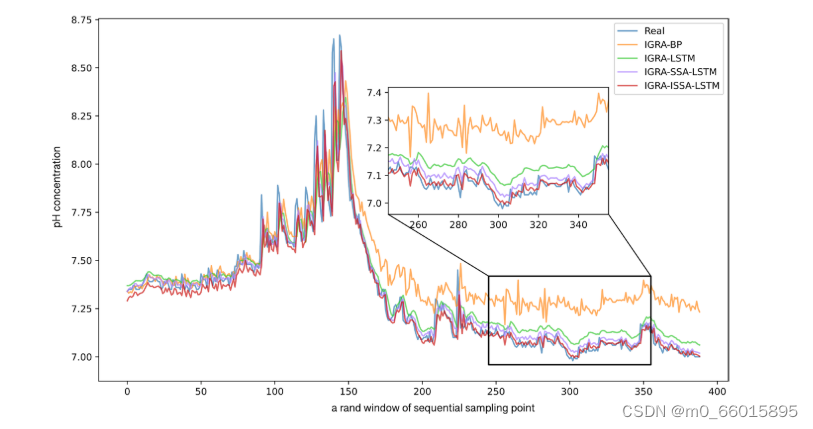
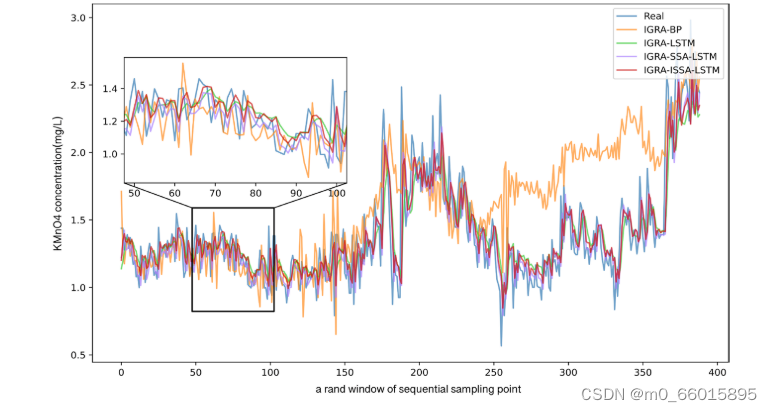
从图1可以看出,基于IGRA-ISSA-LSTM的DO预测整体拟合度较好,在峰值模拟时拟合度更好,能够保证水质突发事件的模拟精度。从图2可以看出,基于IGRA-ISSALSTM的pH预测在前期拟合度低于IGRA-SSALSTM,但在中后期有所提高,峰值时模拟效果更好,说明基于IGRA-ISSA-LSTM的pH预测整体性能较好。从图3可以看出,基于IGRA-ISSA-LSTM的KMnO 4预测对低峰值拟合度一般,但对高峰值拟合度较好,整体拟合效果较好。

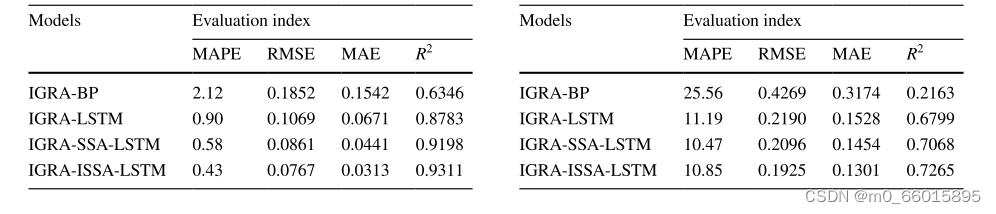
如表所示,与IGRA-BP、IGRA-LSTM和IGRA-SSA-LSTM相比,基于IGRA-ISSA-LSTM的DO预测使得MAPE、RMSE、MAE都得到了降低,并将R2的值提高了。因此可以说明IGRA-ISA-LSTM可以更准确地解释水质的动态过程
总结
基于IGRA、ISSA和LSTM的DO、pH和KMnO 4浓度混合预测模型(IGRA-ISSA-LSTM),通过IGRA确定水质指标之间的相关性,从而可以降低模型维度,解决LSTM维数灾难问题,而ISSA提高寻找最优LSTM超参数的能力,避免SSA陷入局部最优,增加了预测的精度。改方法提供了一个新的视角如何管理水污染在未来,未来可以发展的方向包括增加数据集的水质指标和使用额外的优化算法来增强LSTM参数。