采用 C++TensorRT来部署深度学习模型有以下几个优点:
高性能推理:TensorRT是一个高性能的深度学习推理(Inference)优化器,专门为NVIDIA GPU硬件平台设计,能够提供低延迟、高吞吐量的模型推理性能。这意味着在执行模型推理时,TensorRT能够显著提高运算速度,适用于对实时性要求较高的应用场景。
多种框架支持:TensorRT支持从多种流行的深度学习框架(如TensorFlow、Caffe、MxNet、PyTorch等)转换而来的模型,这使得开发者可以灵活选择训练框架,并将训练好的模型转换为TensorRT格式以便进行优化推理。
优化技术集成:TensorRT集成了多种模型优化技术,包括模型量化、动态内存优化、层融合等,这些技术可以极大提高模型的推断速度和效率。
多平台兼容性:TensorRT可以在不同的NVIDIA GPU硬件上运行,无论是超大规模的数据中心还是嵌入式平台,甚至是自动驾驶平台,都可以利用TensorRT进行推理加速。
易于部署:TensorRT提供了C++ API和Python API,使得开发者可以根据自己的需求和熟悉程度选择适合的语言进行开发。C++通常用于需要更高性能和更低级别控制的场景。
提升执行速度:基于TensorRT的应用在推理期间,相比仅使用CPU平台的执行速度快达40倍,这对于需要快速响应的应用场景来说是非常重要的。
主流工具的优势:由于许多企业使用的是NVIDIA生产的计算设备,在这些设备上,NVIDIA推出的TensorRT在性能上相比其他工具(如TVM、TensorComprehensions)会有一定的优势。
一、下载tensorRT
1、登录NVIDA网站,没有账号的需要注册一个。
2、勾选选项框,弹出版本内容。

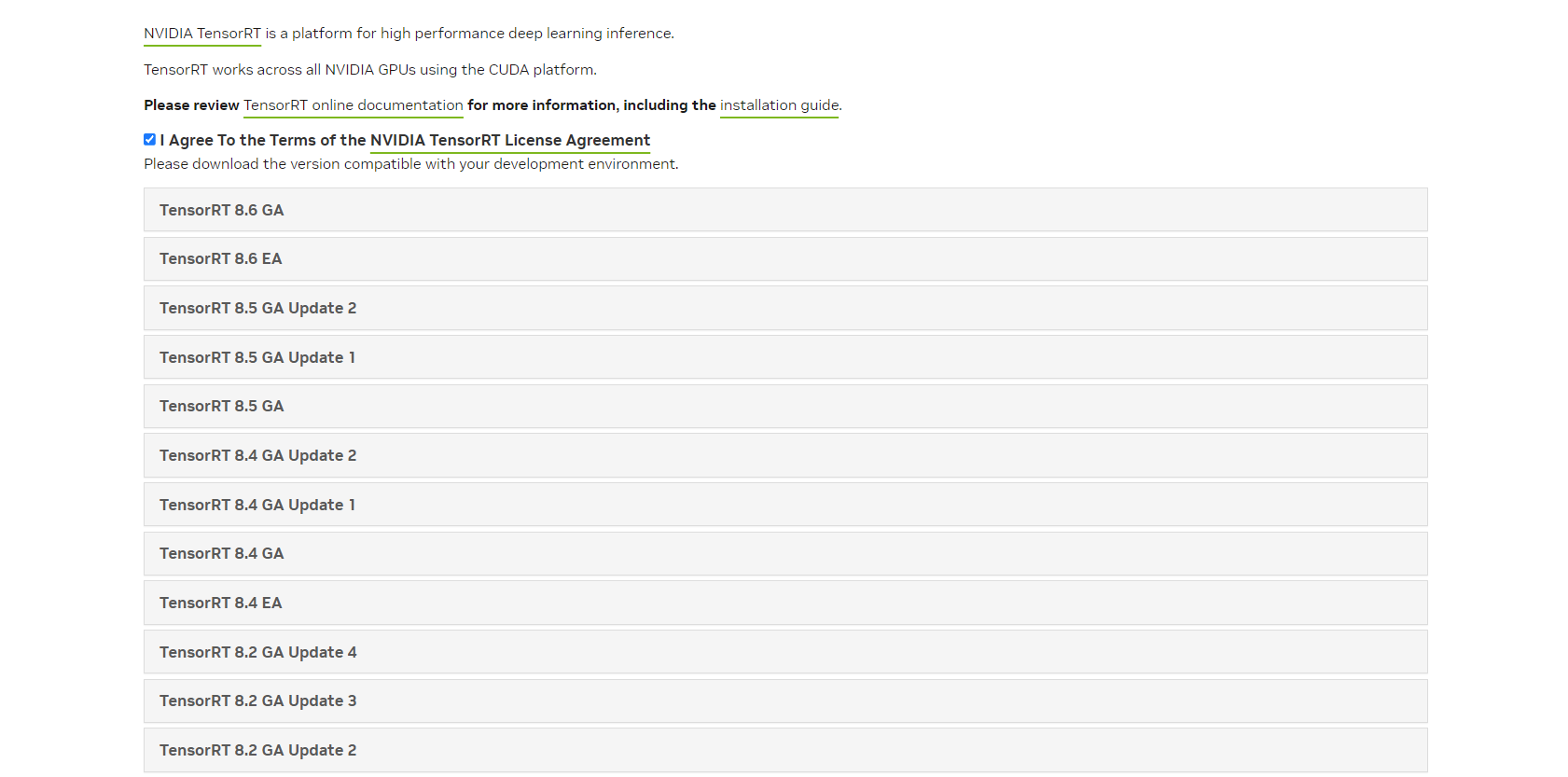
3、选择TensorRT 8.5 GA(GA版本是通用版、稳定版;EA版本是抢先版),点击下载windows版本,下载完毕解压压缩包。
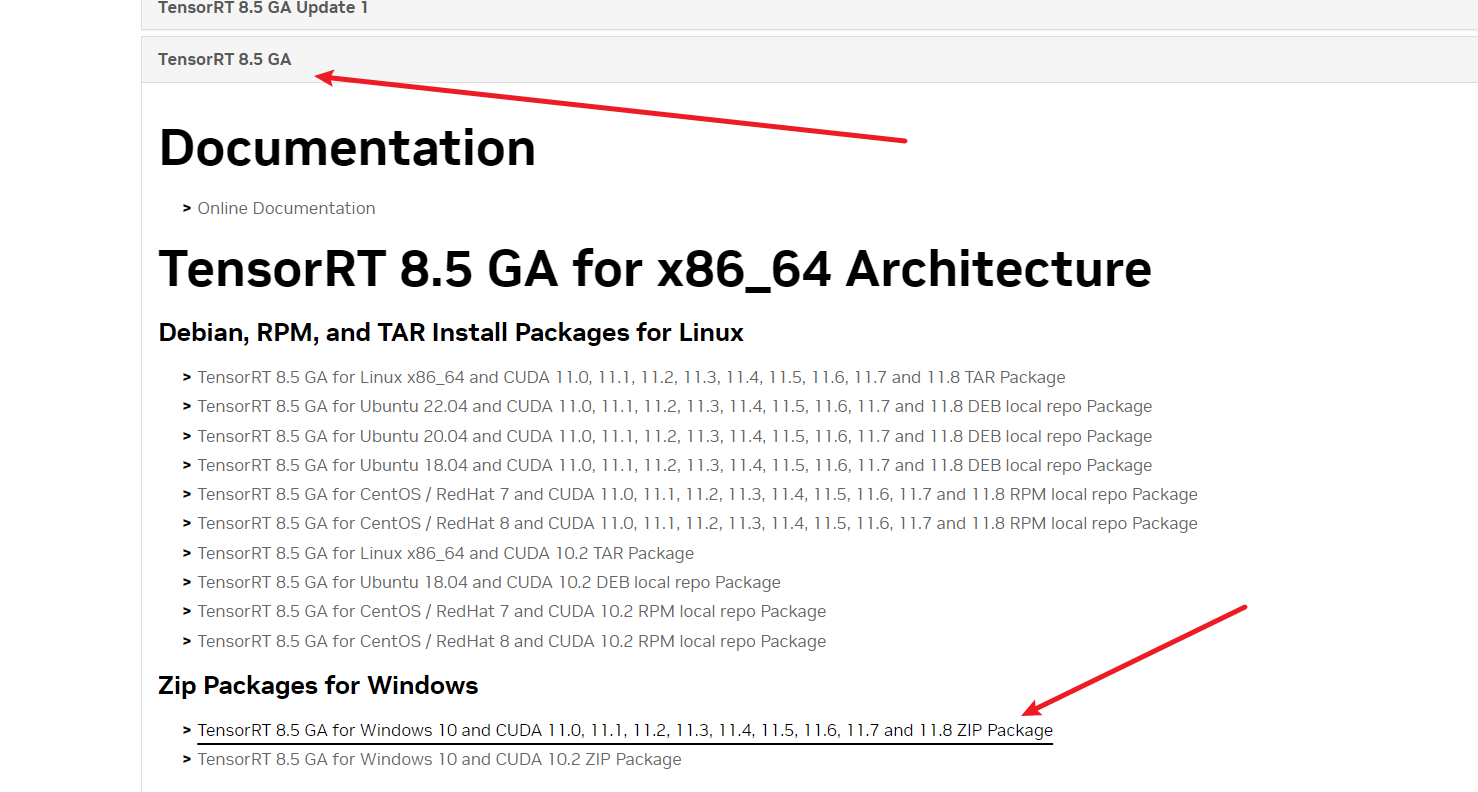
4、打开文件夹,位置1 include是c++需要调用的头文件,位置2 lib为c++调用的库文件;位置3为tensorRT自带的示例程序,有C++、python版本。
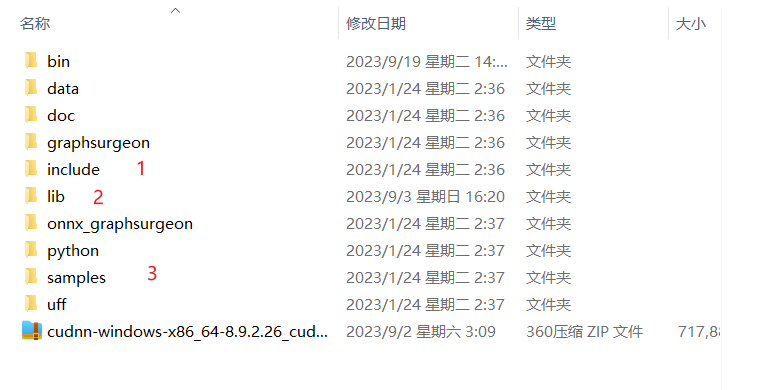
二、vs创建工程
1、打开vs,创建动态链接库工程。
2、将tensorRT的include文件和lib文件拷贝到tennsorRT该目录下,在工程中加入头文件和库目录。
3、下载cuda,我用的是cuda11.3,将头文件和lib库放在cuda文件夹中,工程中添加需要的库。

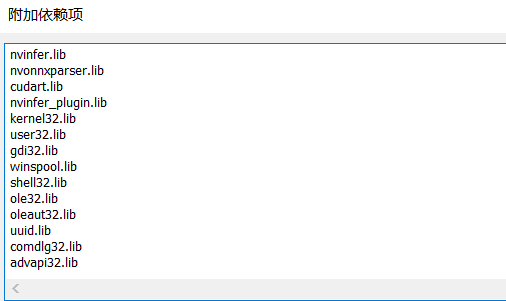
nvinfer.lib
nvonnxparser.lib
cudart.lib
nvinfer_plugin.lib
kernel32.lib
user32.lib
gdi32.lib
winspool.lib
shell32.lib
ole32.lib
oleaut32.lib
uuid.lib
comdlg32.lib
advapi32.lib
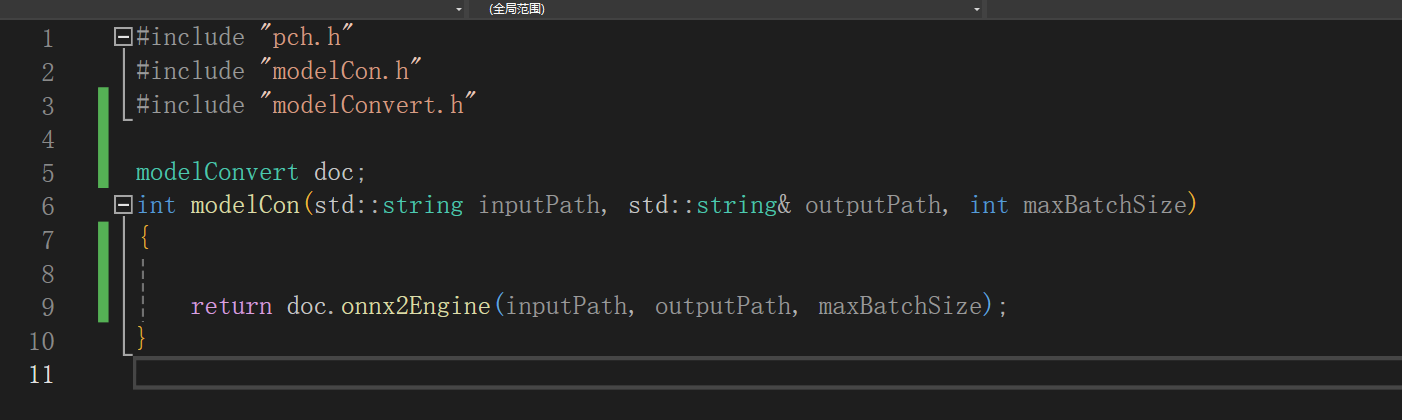
4、在工程中新建库文件,定义转换接口,需要设置的有输入路径,输出路径,batch。接口如下:
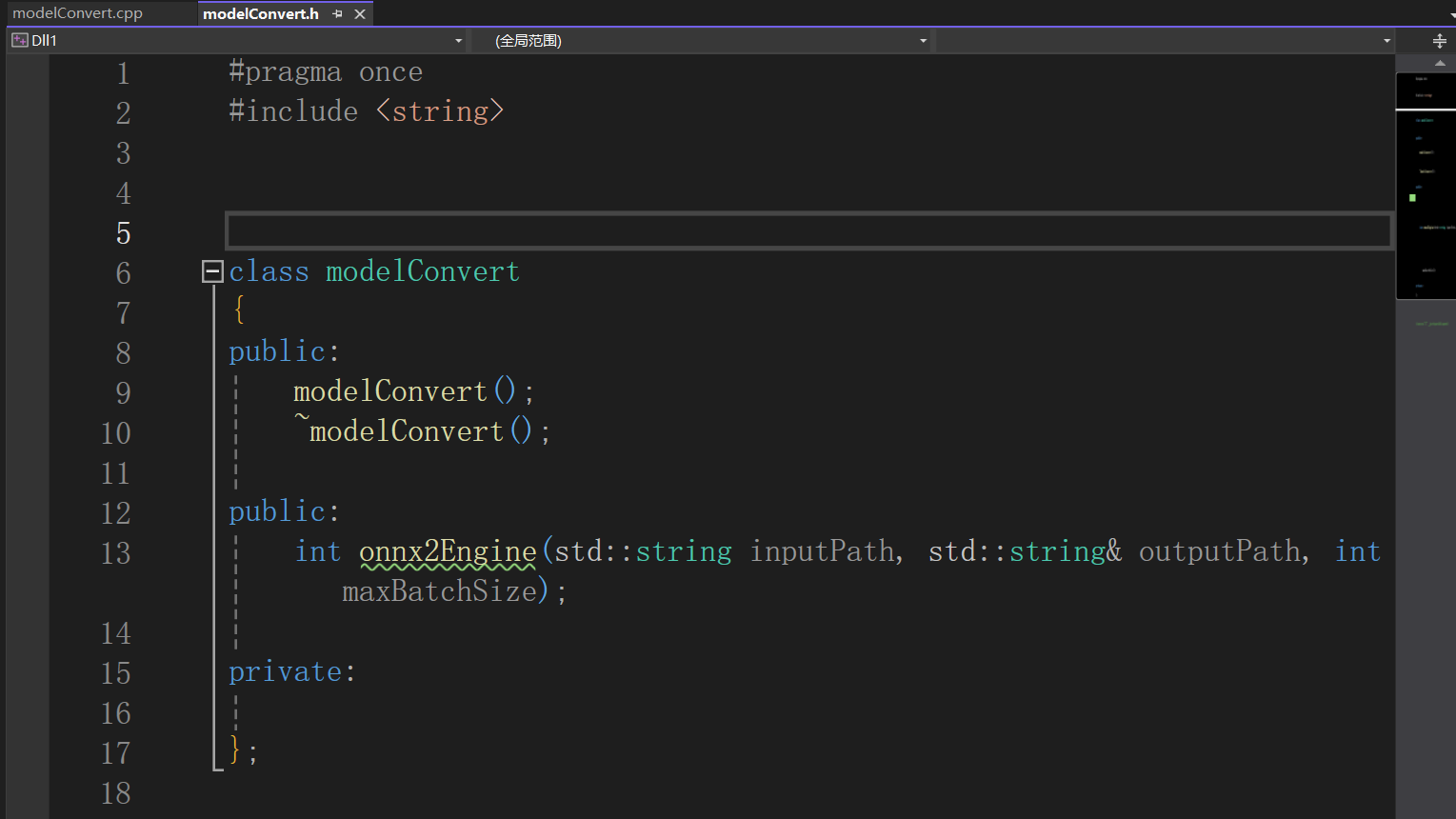
5、在cpp文件中包含头文件;

6、onnx转engine实现过程:
在cpp文件的函数接口内写入:
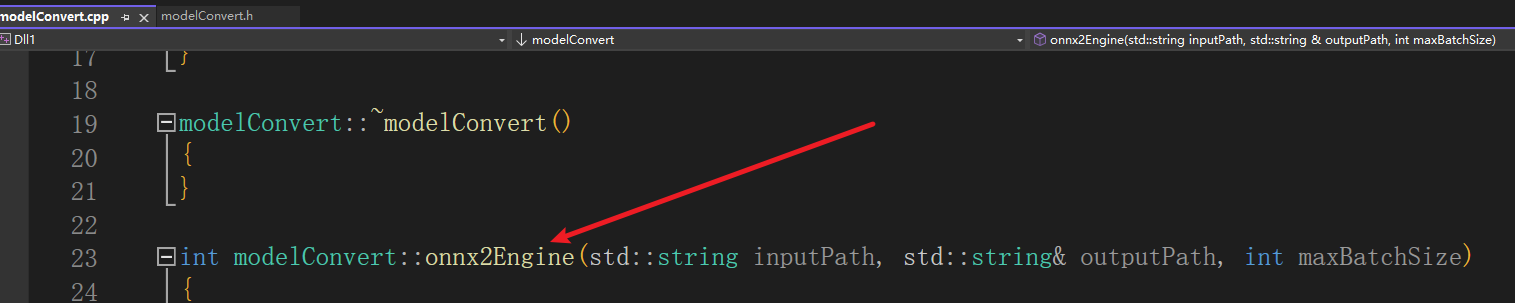
(1)创建onnx转trt解析器
static Logger gLogger;
//创建builder
IBuilder* builder = createInferBuilder(gLogger);
//创建network
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
//创建onnx模型解析器
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
(2)读取onnx模型文件
//读取onnx模型文件
const char* onnx_filename = inputPath.c_str();
//将onnx模型导入trt网络,解析模型
parser->parseFromFile(onnx_filename, static_cast<int>(Logger::Severity::kWARNING));
for (int i = 0; i < parser->getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
std::cout << "successfully load the onnx model" << std::endl;
(3)创建引擎
//使用builder对象构建engine
IBuilderConfig* config = builder->createBuilderConfig();
//设置batch
builder->setMaxBatchSize(maxBatchSize);
//设置最大工作空间
config->setMaxWorkspaceSize(1 << 20);
//config->setMaxWorkspaceSize(128 * (1 << 20)); // 16MB
//设置精度计算
config->setFlag(BuilderFlag::kFP16);
//创建engine
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
(4)序列化引擎并写入文件
IHostMemory* gieModelStream = engine->serialize();
std::ofstream p(outputPath.c_str(), std::ios::binary);
if (!p)
{
std::cerr << "could not open plan output file" << std::endl;
return -1;
}
//写入
p.write(reinterpret_cast<const char*>(gieModelStream->data()), gieModelStream->size());
//摧毁
gieModelStream->destroy();
engine->destroy();
parser->destroy();
network->destroy();
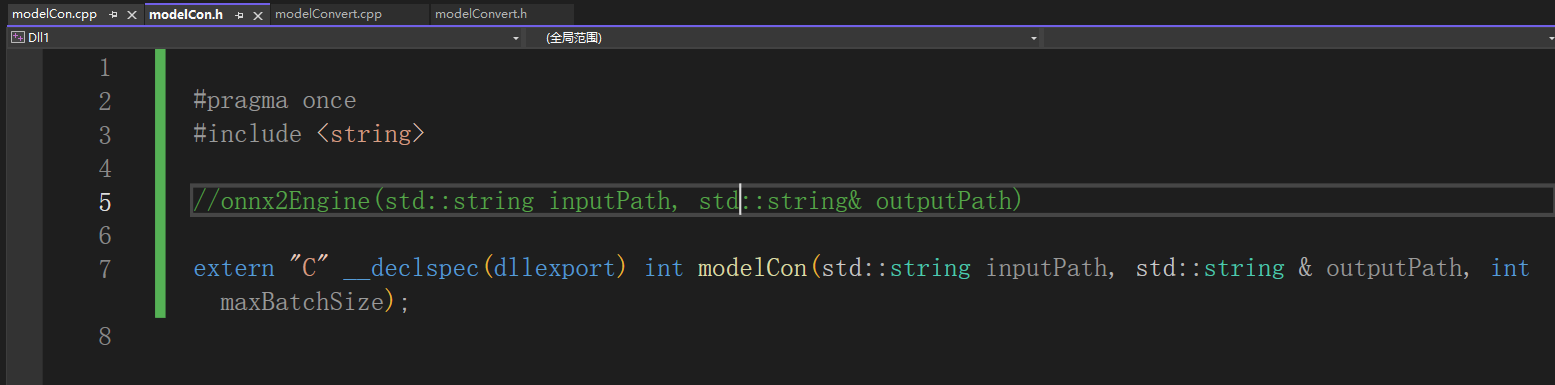
7、添加新建文件,导出调用函数
三、接口测试
编写调用程序:
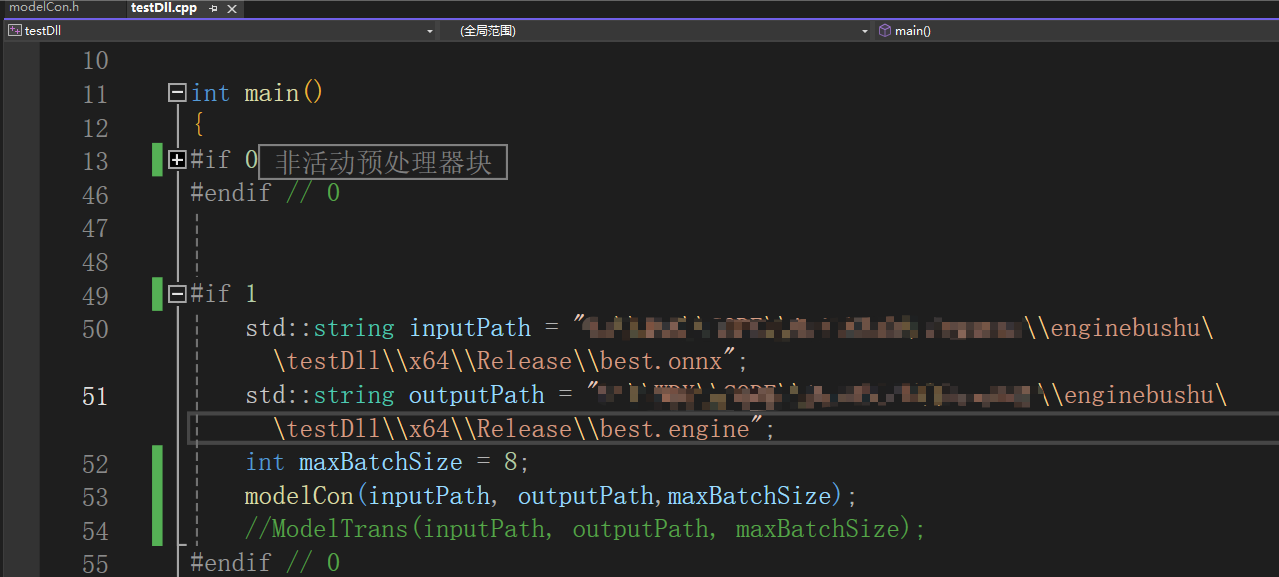
1、新建控制台程序,包含头文件和库目录。
2、在main函数中调用接口,运行,结果显示如下,即为调用成功。然后等待转换成功,在输出目录中即可找到对应的engine文件。

源码链接:
【超级会员】通过百度网盘分享的文件:onnx转trt
链接:https://pan.baidu.com/s/1_Jkq9GjFBzp7j-V34cDQkg?pwd=7785
提取码:7785
复制这段内容打开「百度网盘APP 即可获取」