查了很多资料,很多用python代码写的,只需要这个库那个库的,最后都没成功。
不如直接使用Yolov5里面的 export.py实现模型的转换。
一:安装依赖
因为yolov5里面的requirments.txt是将这些转换模型的都注释掉了
所以需要解除注释然后再安装

根据你需要导出模型的类型进行解除注释
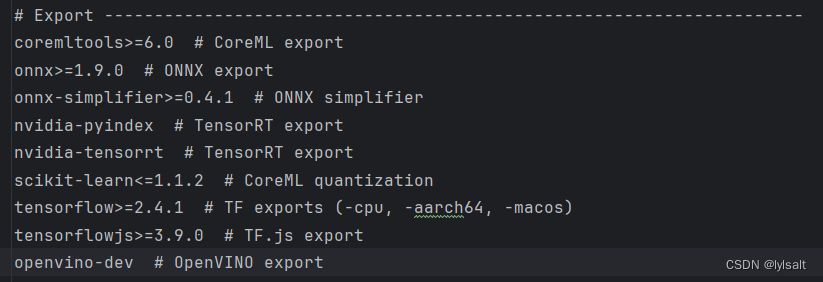
然后再安装依赖
pip install -r requirements.txt
二:导出模型
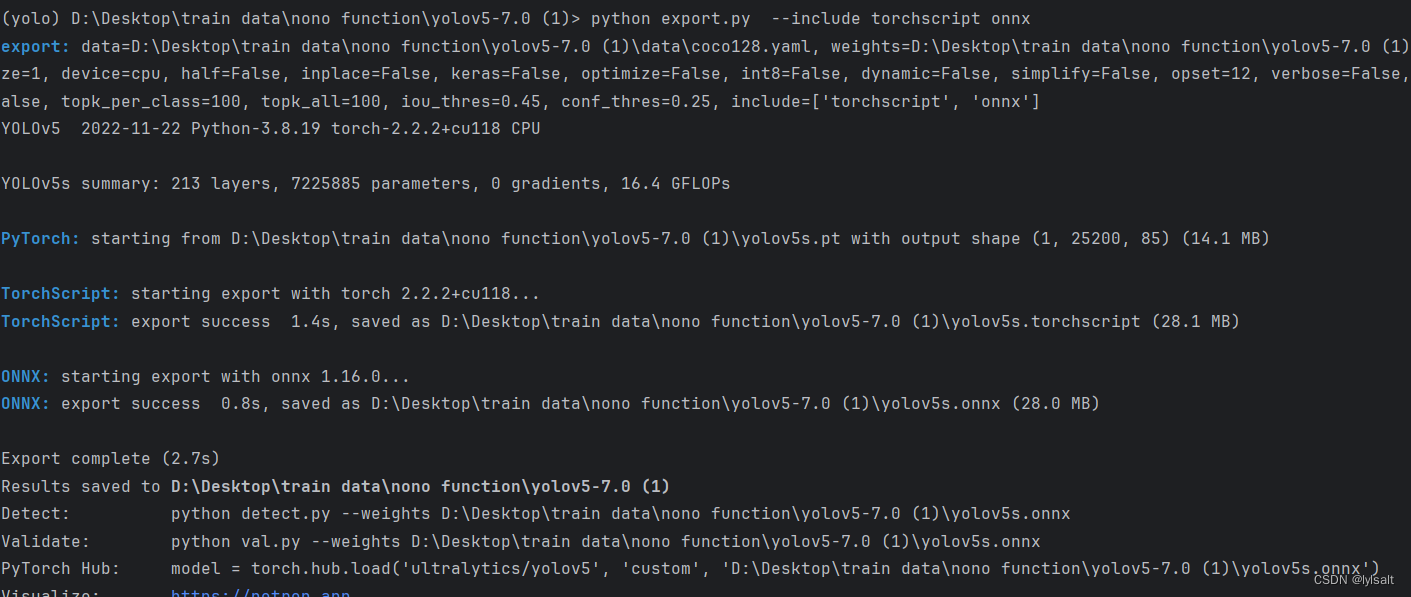
根据官方教程来说明如何导出模型,帮助如何将训练好的YOLOv5模型转换成ONNX格式或者TorchScipt格式。
在export.py里面设置模型和数据源的yaml

官方文档写了具体可以导出的类型。

在 --include添加导出的类型。
python export.py --include torchscript onnx
三:测试和验证推理
python detect.py --weights yolov5s.onnx --dnn
python val.py --weights yolov5s.onnx --dnn
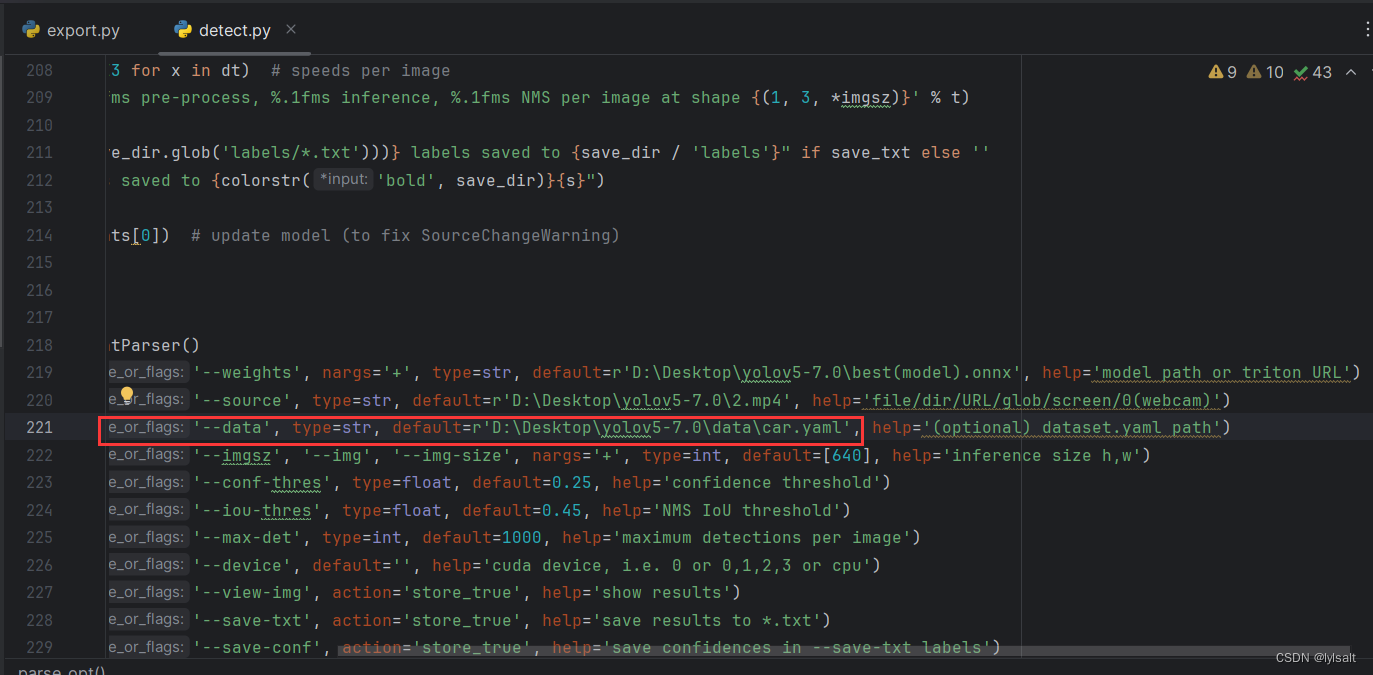
记住推理的时候,要修改detect.py里面的数据源yaml文件。不然会出现推理的时候标签不一致。
在模型的导出中,onnx不需要GPU进行推理,没有用GPU推理,导致推理的时候很慢,但是tensorRT需要GPU进行推理。
文件有些大,根据官方文档的提示
💡 ProTip: Add --half to export models at FP16 half precision for smaller file sizes
添加--half以FP16半精度导出模型,以缩小文件大小
原来的.pt模型是40.2MB.转成ONNX后模型大小是79.9MB
用完--half完,模型大小变为40.0MB,明显变小了
再次进行推理验证,时间少了43%左右,说明这个是有效果的,测试了一下,对精度影响不大。
相关参数解释:
def parse_opt():
"""
data: 数据集目录 默认=ROOT / 'data/coco128.yaml'
weights:权重文件目录 默认=ROOT / 'yolov5s.pt'
img-size: 输入模型的图片size=(height, width) 默认=[640, 640]
batch-size: batch大小 默认=1
device: 模型运行设备 cuda device, i.e. 0 or 0,1,2,3 or cpu 默认=cpu
include: 要将pt文件转为什么格式 可以为单个原始也可以为list 默认=['torchscript', 'onnx', 'coreml']
half: 是否使用半精度FP16export转换 默认=False
inplace: 是否设置 YOLOv5 Detect() inplace=True 默认=False
train: 是否开启model.train() mode 默认=True coreml转换必须为True
optimize: TorchScript转化参数 是否进行移动端优化 默认=False
int8: 支持CoreML/TF INT8 量化 不支持ONNX
dynamic: ONNX转换参数 dynamic_axes ONNX转换是否要进行批处理变量 默认=False
simplify: ONNX转换参数 是否简化onnx模型 默认=False
opset: ONNX转换参数 设置ONNX版本 默认=13
topk-per-class: TF.js每一类别都要保留 默认=100
topk-all: TF.js Topk为所有class保留
iou-thres: TF.js IoU threshold default=0.45
conf-thres: TF.js confidence threshold default=0.25
include: 需要导出的版本 default=['torchscript', 'onnx'],
"""
复制代码参考文章:
yolov5 pt 模型 导出 onnx_yolov5 export.py-CSDN博客
TFLite, ONNX, CoreML, TensorRT Export - Ultralytics YOLOv8 Docs
源码解析二 模型转换 export.py - ---dgw博客 - 博客园 (cnblogs.com)