2024/4/22
上个星期我们已经完成了Hadoop的安装及配置文件的修改 下面 我们将namenode进行一下初始化
hdfs namenode -format
(创建文件存储目录:账本目录namenode datanode的目录)

我们在配置时 这就是用来设置账本目录的
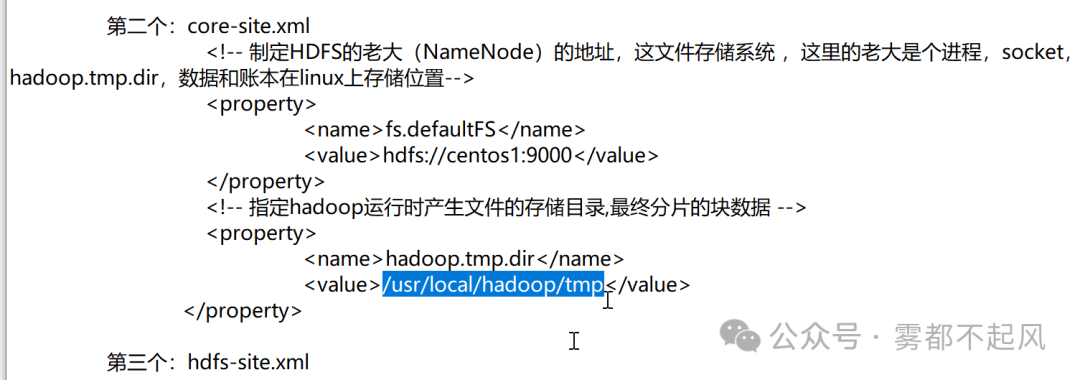
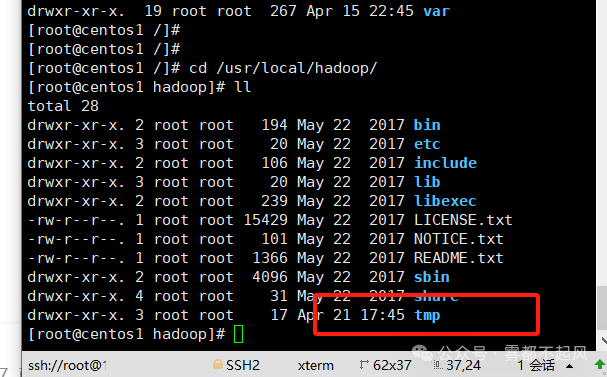
我们做完格式化后 tmp目录就出现了
9.Hadoop原理
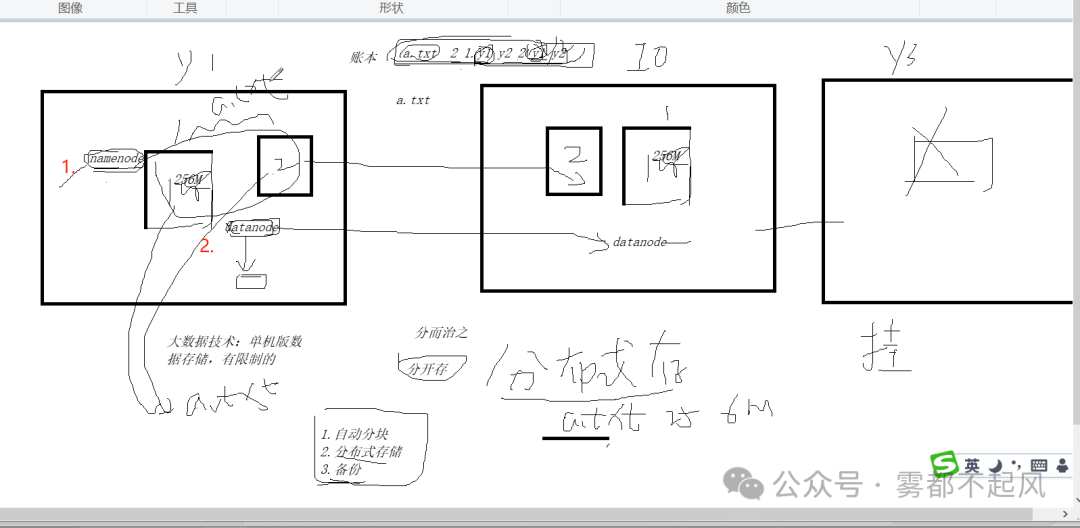
1)datanode(程序):负责存储
文件被分成block存储在磁盘上 为保证数据安全 文件会有多个副本
在写入数据的时候 自己写一份 顺便给集群中其他地方一份 达到了备份的效果 只是做到了分布式存储 但是并没有将每一块分开的数据进行区分
那么 这个时候 我们要做一个账本
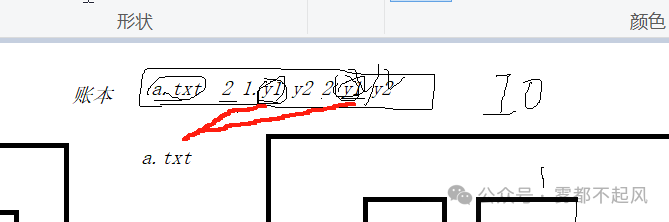
2)namenode(作账本):负责管理 管理文件(a.txt)与block之间的关系 block与datanode之间的关系
3)Secondarynamenode:账本很重要 所以账本需要备份 账本的备份
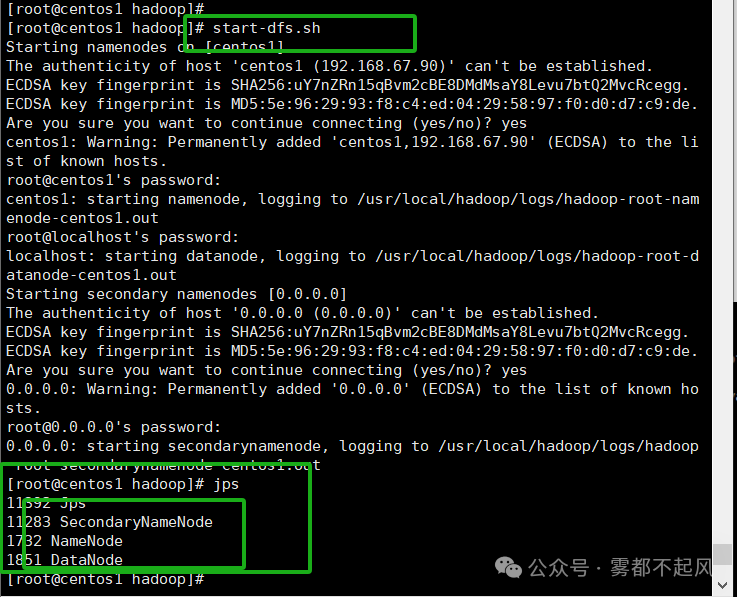
10.启动Hadoop
启动文件系统:start-dfs.sh stop-dfs.sh
启动计算系统:start-yarn.sh
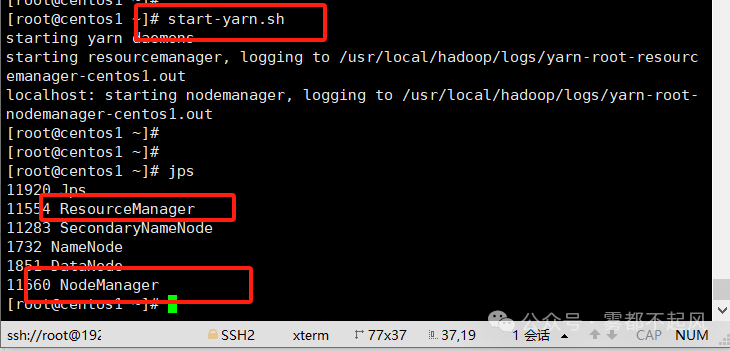
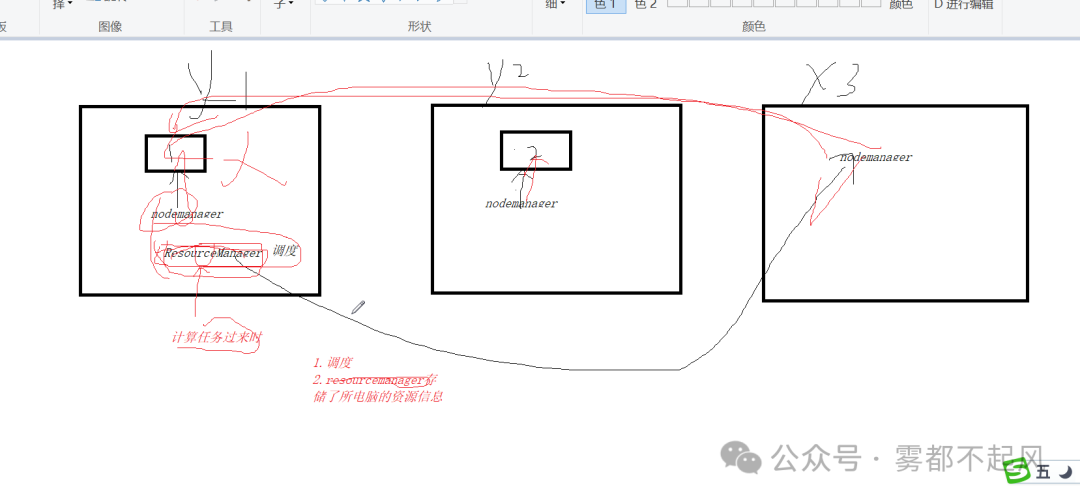
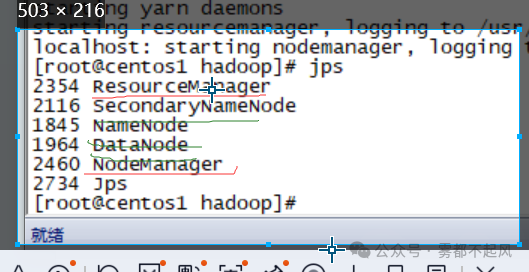
问题:hadoop中有多少个进程 分别是干嘛的
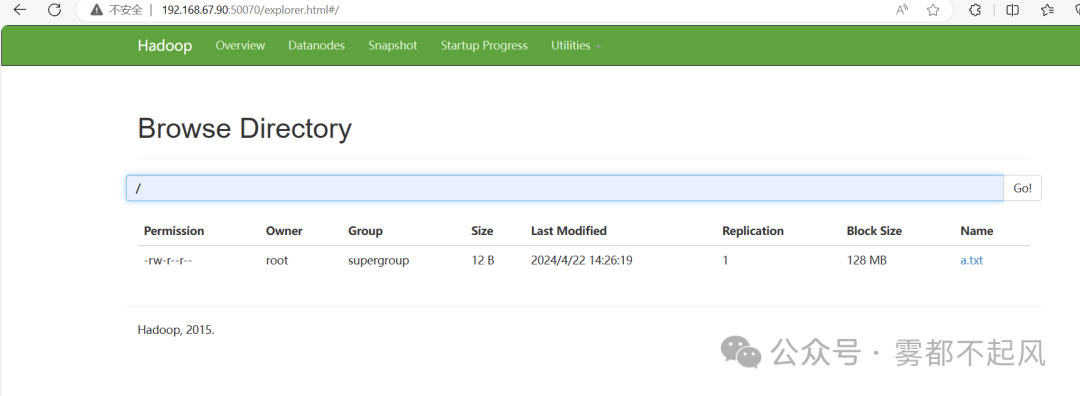
11.测试
上传数据:hadoop fs -put linux文件路径 hadoop文件路径
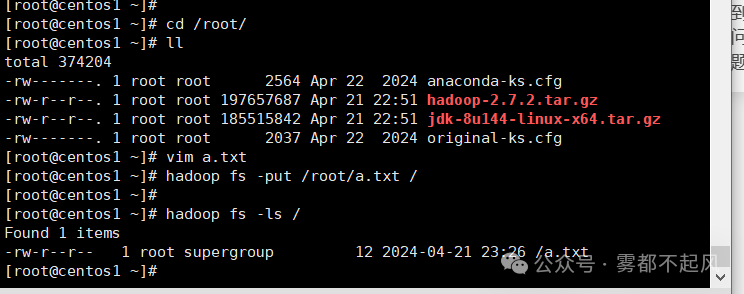
查看:hadoop fs -ls /

192.168.38.101:50070