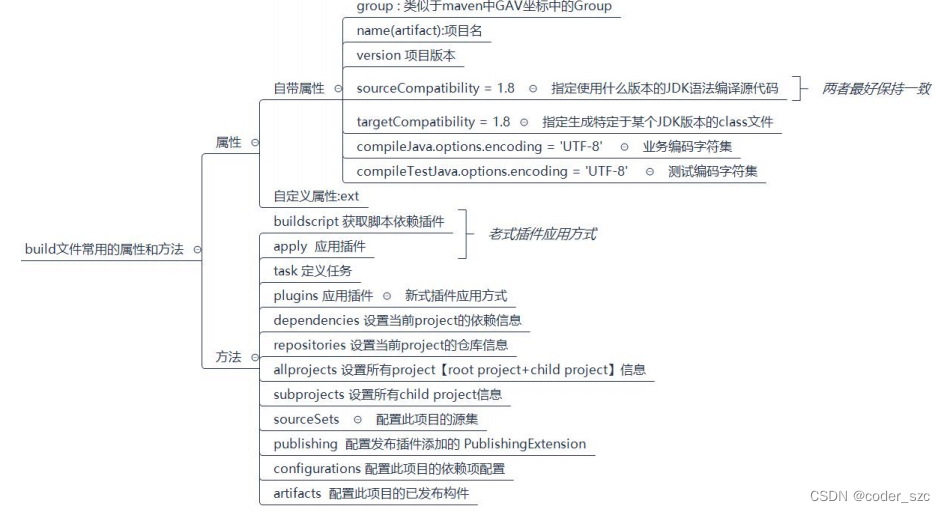
1、原理
Layer Normalization是针对自然语言处理领域提出的,例如像RNN循环神经网络。在RNN这类时序网络中,时序的长度并不是一个定值(网络深度不一定相同),比如每句话的长短都不一定相同,所有很难去使用BN,所以作者提出了Layer Normalization。
注意:在图像处理领域中BN比LN是更有效的,但现在很多人将自然语言领域的模型用来处理图像,比如Vision Transformer,此时还是会涉及到LN。
如下所示,是Pytorch官方给的关于LayerNorm的简单介绍,只看公式的话感觉和BN没什么区别,都是减均值,除以标准差,其中 ϵ 是一个非常小的量(默认10−5),是为了防止分母为零;
同样也有两个参数 β , γ。不同的是,BN是对一个batch数据的每个channel进行标准化处理,但LN是对单个数据的指定维度进行标准化处理,与batch无关。而且BN在训练时是需要累计moving_mean和moving_var两个变量(BN中有4个参数moving_mean, moving_var, β , γ),但LN不需要累计,只有 β , γ两个参数。

2、Pytorch实验
在Pytorch的LayerNorm类中有个normalized_shape参数,可以指定你要标准化的维度。
注意,函数说明中the last certain number of dimensions,指定的维度必须是从最后一维开始。
比如数据的shape是[4, 2, 3],那么normalized_shape可以是[3](最后一维上进行Norm处理),也可以是[2, 3](Norm最后两个维度),也可以是[4, 2, 3](对整个维度进行Norm),但不能是[2]或者[4, 2],否则会报以下错误(以normalized_shape=[2]为例):
RuntimeError:
Given normalized_shape=[2],
expected input with shape [*, 2],
but got input of size[4, 2, 3]
提示我们传入的normalized_shape=[2],接着系统根据我们传入的normalized_shape推理出希望输入的数据shape应该为[*, 2],即最后的一个维度大小应该是2,但实际传入的数据shape是[4, 2, 3]所以会报错。
下面是测试代码,验证使用官方的LN方法和自己实现的LN方法是否一致:
import torch
import torch.nn as nn
def layer_norm_process(feature: torch.Tensor, beta=0., gamma=1., eps=1e-5):
var_mean = torch.var_mean(feature, dim=-1, unbiased=False)
# 均值
mean = var_mean[1]
# 方差
var = var_mean[0]
# layer norm process
feature = (feature - mean[..., None]) / torch.sqrt(var[..., None] + eps)
feature = feature * gamma + beta
return feature
def main():
t = torch.rand(4, 2, 3)
print(t)
# 仅在最后一个维度上做norm处理
norm = nn.LayerNorm(normalized_shape=t.shape[-1], eps=1e-5)
# 官方layer norm处理
t1 = norm(t)
# 自己实现的layer norm处理
t2 = layer_norm_process(t, eps=1e-5)
print("t1:\n", t1)
print("t2:\n", t2)
if __name__ == '__main__':
main()
结果一致: