前言
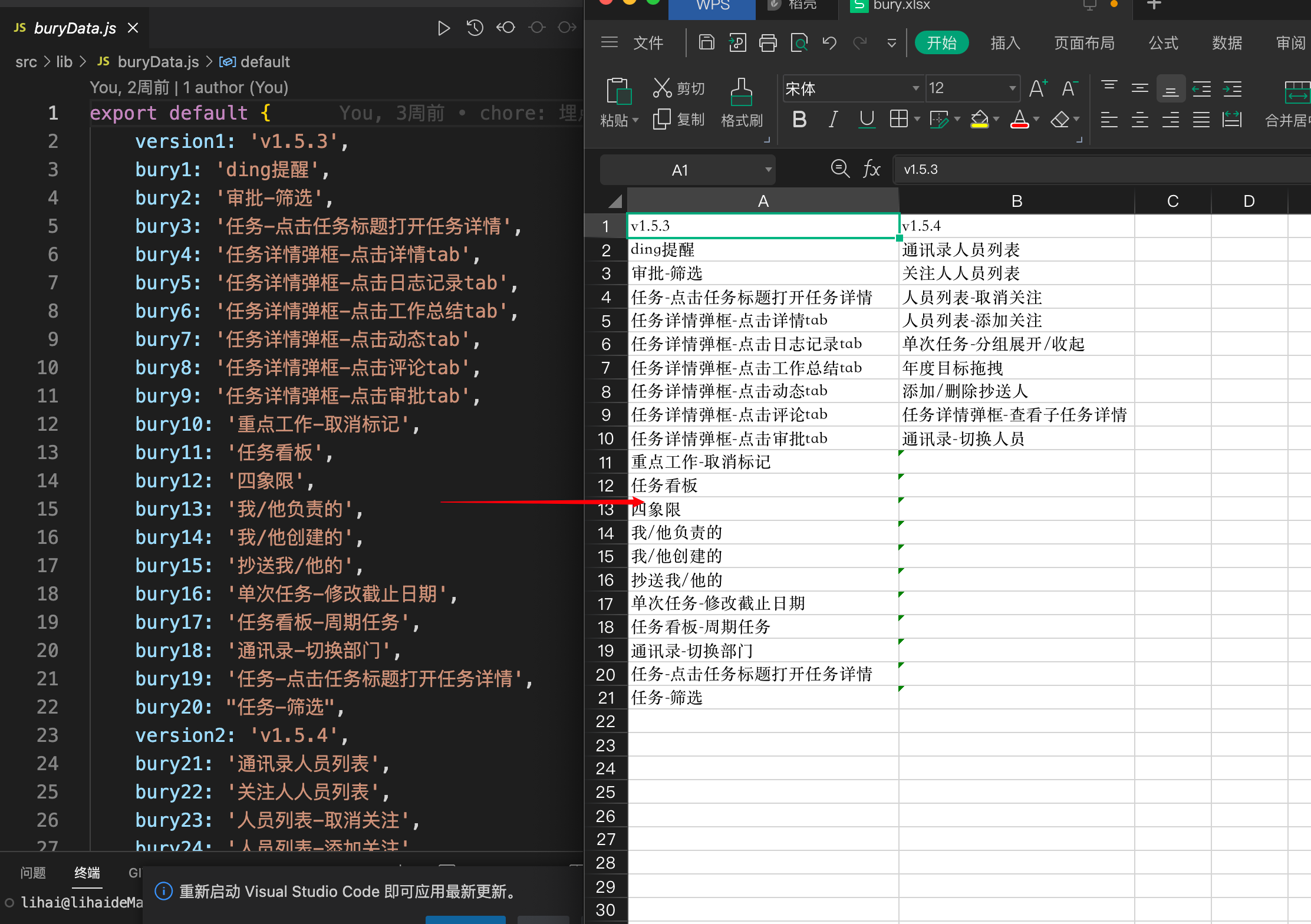
企业项目进行数据埋点后,埋点事件名需要整理成Excel表格便于统计,目标是将下图左侧数据转化成下图右侧的Excel表格:
考虑到左侧埋点数据是随项目迭代增加的,埋点数据每增加一次我就要把数据一条一条的Ctrl+C/V复制粘贴至Excel表格内。
懒,不想这样玩,于是我写了一个自动帮我整理成表格的脚本。
脚本实现
实现流程
- Node.js生成Excel表格工具库技术选型
- 单独复制一份埋点数据出来,保证它的变动不会影响业务相关埋点逻辑
- 整理埋点数据成我们需要的数据结构
分成三步走
技术选型
Node.js操作Excel表格工具库有:
- exceljs
- excellentexport
- node-xlsx
- xlsx-template
仅罗列以上四个。
选择的角度有以下几点:
- 学习成本低,文档API简单易用,仅生成表格即可,其他功能并不需要,所以API越简单越好
- 生成Excel表格需要提供的数据结构简单,便于实现
- 能导出xlsx表格,满足最基本要求
node-xlsx最贴近以上要求,首选使用它。
node-xlsx官方生成Excel表格给出的代码块:
import xlsx from 'node-xlsx';
// Or var xlsx = require('node-xlsx').default;
const data = [
[1, 2, 3],
[true, false, null, 'sheetjs'],
['foo', 'bar', new Date('2014-02-19T14:30Z'), '0.3'],
['baz', null, 'qux'],
];
var buffer = xlsx.build([{name: 'mySheetName', data: data}]); // Returns a buffer
生成表格数据data是二维数组,对应表格的行列。data.length 为表格行数,data[0].length 为表格的列数;data[0][0]对应至表格的第一行第一列的值,data[0][1]对应至表格的第一行第二列的值。
所以将埋点数据整理为一个二维数组即可,二维数组数据结构整理容易实现。
复制埋点数据
埋点数据统一放置在buryData.js 文件,但不能随意改动它,所以将该文件单独再复制一份出来。
buryData.js
export default {
version1: 'v1.5.3',
bury1: 'ding提醒',
bury2: '审批-筛选',
bury3: '任务-点击任务标题打开任务详情',
bury4: '任务详情弹框-点击详情tab',
bury5: '任务详情弹框-点击日志记录tab',
bury6: '任务详情弹框-点击工作总结tab',
bury7: '任务详情弹框-点击动态tab',
//...
}
buryData.js复制出来文件命名为bury.js,还有一个问题:bury.js需要执行它,拿到它导出的数据对象,导出数据是使用ES6模块化语法,这边需要将ES6模块化转化成CommonJs模块化,将export default {} 替换成module.exports ={}即可做到。
Node.js fs模块+正则替换是可以达成以上目的,但为了更快捷,我选择使用工具库magic-string
magic-string它是操作字符串库,它可以帮我去掉写正则替换字符串的步骤。
const path = require('path');
const magicString = require('magic-string')
const fs = require('fs');
//buryData.js 文件路径
const buryFile = path.join(__dirname, '../src/lib/buryData.js')
const getBuryContent = (filePath) => {
const content = fs.readFileSync(filePath, 'utf8')
//将export default 替换成module.exports =
const s = new magicString(content)
s.replace('export default', 'module.exports = ')
return s.toString()
}
(async () => {
const str = getBuryContent(buryFile)
//将替换后的内容写入至bury.js文件
const copyFilePath = path.join(__dirname, '/bury.js')
fs.writeFileSync(copyFilePath, str)
//动态导入bury.js 获取埋点数据
const { default: data } = await import(copyFilePath)
})()
生成二维数组
上文已提及,node-xlsx生成表格需要先将数据整理成二维数组。
export default {
version1: 'v1.5.3',
bury1: 'ding提醒',
/...
version2: 'v1.5.4',
bury21: '通讯录人员列表',
//..
}
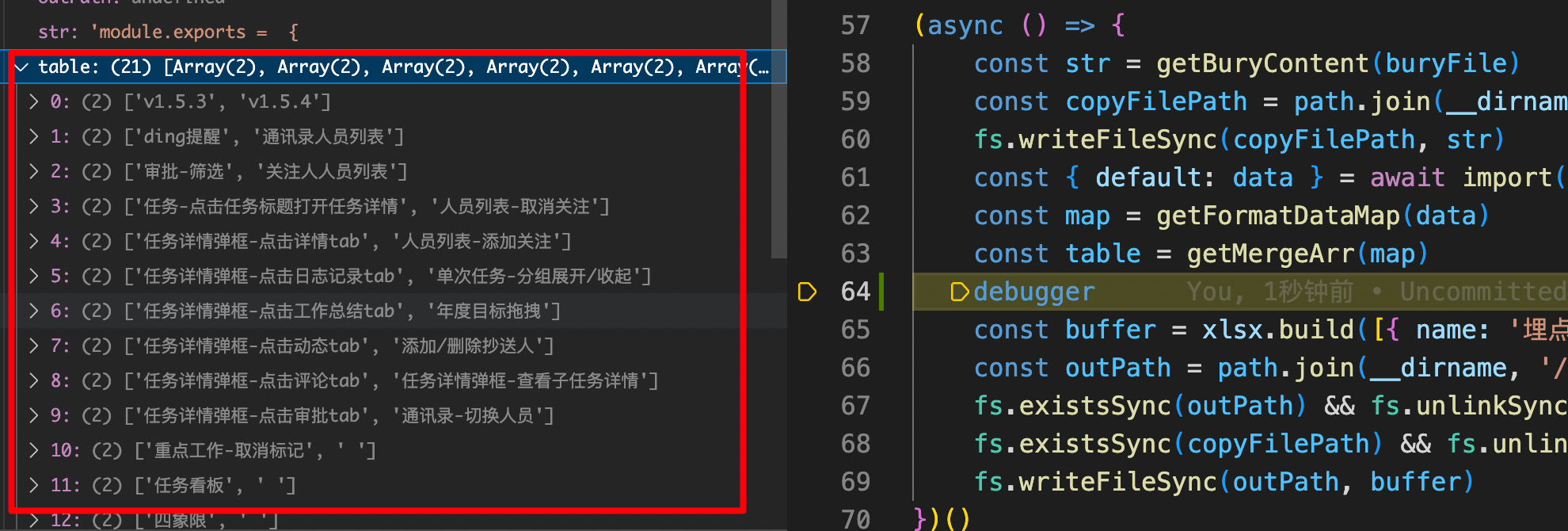
以上数据整理成:
[
['v1.5.3','v1.5.4'],
['ding提醒','通讯录人员列表'],
//...
]
首先,将数据全部存放至一个Map对象中。因为埋点数据是一个对象,其中version1、version2 表示版本号,随项目迭代版本号会增多version3、version4……以version进行划分Map 值。
const _ = require('lodash');
//...
const getFormatDataMap = (data) => {
let version
const map = new Map();
_.forIn(data, (value, key) => {
if (key.includes('version')) {
version = value
!map.has(version) && map.set(version, [value])
return
}
const mapValue = map.get(version)
mapValue.push(value)
})
return map
}
(async () => {
const str = getBuryContent(buryFile)
const copyFilePath = path.join(__dirname, '/bury.js')
fs.writeFileSync(copyFilePath, str)
const { default: data } = await import(copyFilePath)
//新增
const map = getFormatDataMap(data)
})()
getFormatDataMap 函数执行后,返回的数据是:
{
'v1.5.3'=>['v1.5.3','ding提醒' //...]
'v1.5.4'=>['v1.5.4','通讯录人员列表' //...]
}

然后,需要知道表格最大行数,表格列数即为map.size(),最大行数通过获取Map.values()获取所有的值values,遍历values获取values内存放的每一个数组的长度,长度统一用另一个数组lens临时记录,遍历结束后比较lens中的数值得到最大的值,
MAX_LEN 即为表格最大的行数,也是values存放的所有数组中长度最大的值。
const _ = require('lodash');
//...
const getMergeArr = (map) => {
const values = _.toArray(map.values())
const lens = []
//获取长度,长度值统一存放至lens数组中
values.forEach((value) => { lens.push(value.length) })
//比较
const MAX_LEN = _.max(lens)
return getTargetItems({ mapValue: values, forNum: MAX_LEN })
}
(async () => {
const str = getBuryContent(buryFile)
const copyFilePath = path.join(__dirname, '/bury.js')
fs.writeFileSync(copyFilePath, str)
const { default: data } = await import(copyFilePath)
const map = getFormatDataMap(data)
//新增
const table = getMergeArr(map)
})()
最后,以values、MAX_LEN进行双循环。表格列数map.size()可获取,但为了方便直接mapValue.length,两者是相等的。
有了表格列数即可创建二维数组的第二层数组,new Array(len).fill(' ')第二层数组长度即为mapValue.length,创建时数组内的值先统一填充为' '。
const getTargetItems = ({ mapValue, forNum }) => {
const len = mapValue.length
const targetItems = []
mapValue.forEach((v, i) => {
for (let index = 0; index < forNum; index++) {
const element = v[index];
let targetItem = targetItems[index]
if (!targetItem) {
//创建数组,值先统一填充为' '
targetItem = new Array(len).fill(' ')
}
/**
如果当前index大于数组v的长度,这时获取值v[index]为undefined。
为undefined的话直接跳过,保持targetItem[i]为' '
*/
targetItem[i] = element ? element : ' '
targetItems[index] = targetItem
}
})
return targetItems
}
完成二维数组的转化,数据结构为下图:
生成表格
数据已完成,留下的就是写入数据生成表格,直接复制node-xlsx演示的代码下来。
//...
(async () => {
const str = getBuryContent(buryFile)
const copyFilePath = path.join(__dirname, '/bury.js')
fs.writeFileSync(copyFilePath, str)
const { default: data } = await import(copyFilePath)
const map = getFormatDataMap(data)
const table = getMergeArr(map)
//写入数据,生成表格,返回buffer数据
const buffer = xlsx.build([{ name: '埋点', data: table }])
const outPath = path.join(__dirname, '/bury.xlsx')
//bury.js文件可以删除,bury.xlsx如果已存在就先删了
fs.existsSync(outPath) && fs.unlinkSync(outPath)
fs.existsSync(copyFilePath) && fs.unlinkSync(copyFilePath)
//创建一个bury.xlsx文件,将得到的buffer写入
fs.writeFileSync(outPath, buffer)
})()
脚本完。
完整源码:
const path = require('path');
const fs = require('fs');
const xlsx = require('node-xlsx');
const magicString = require('magic-string')
const _ = require('lodash');
const buryFile = path.join(__dirname, '../src/lib/buryData.js')
const getBuryContent = (filePath) => {
const content = fs.readFileSync(filePath, 'utf8')
const s = new magicString(content)
s.replace('export default', 'module.exports = ')
return s.toString()
}
const getFormatDataMap = (data) => {
let version
const map = new Map();
_.forIn(data, (value, key) => {
if (key.includes('version')) {
version = value
!map.has(version) && map.set(version, [value])
return
}
const mapValue = map.get(version)
mapValue.push(value)
})
return map
}
const getTargetItems = ({ mapValue, forNum }) => {
const len = mapValue.length
const targetItems = []
mapValue.forEach((v, i) => {
for (let index = 0; index < forNum; index++) {
const element = v[index];
let targetItem = targetItems[index]
if (!targetItem) {
targetItem = new Array(len).fill(' ')
}
targetItem[i] = element ? element : ' '
targetItems[index] = targetItem
}
})
return targetItems
}
const getMergeArr = (map) => {
const values = _.toArray(map.values())
const lens = []
values.forEach((value) => { lens.push(value.length) })
const MAX_LEN = _.max(lens)
return getTargetItems({ mapValue: values, forNum: MAX_LEN })
}
(async () => {
const str = getBuryContent(buryFile)
const copyFilePath = path.join(__dirname, '/bury.js')
fs.writeFileSync(copyFilePath, str)
const { default: data } = await import(copyFilePath)
const map = getFormatDataMap(data)
const table = getMergeArr(map)
debugger
const buffer = xlsx.build([{ name: '埋点', data: table }])
const outPath = path.join(__dirname, '/bury.xlsx')
fs.existsSync(outPath) && fs.unlinkSync(outPath)
fs.existsSync(copyFilePath) && fs.unlinkSync(copyFilePath)
fs.writeFileSync(outPath, buffer)
})()
去掉空行,一百行以内。
总结
Node.js可使用的场景非赏多,不单单是用于服务器接口的开发,我们还能通过写脚本的形式解决生活中重复性的工作,凭藉js的语法简单及强大的生态,前端不必学习shell、python等,仅使用js就可以搞定爬虫、自动化脚本等场景。
如果我的文章对你有帮助,你的👍就是对我的最大支持_。