import os
import requests
from openpyxl import Workbook
from openpyxl. drawing. image import Image
from concurrent. futures import ThreadPoolExecutor
image_urls = [
"https://uploads/file/20230205/f85Lpcv8PXrLAdmNUDE1Hh6xqkp0NHi2gSXeqyOb.png" ,
"https://uploads/file/20230205/geG4FOpthrsUX0LkmWvDH2veFtw6yj8JLDMYBaQ1.png" ,
"https://uploads/file/20230205/mjVAx4jsbke6uj0e2Qz66f8KDceL1P5tanKQkNoy.png"
]
output_dir = "C:/Users/win-10/Desktop/发票图片/"
save_folder = "C:/Users/win-10/Desktop/发票图片/downloaded_images/"
excel_filename = "images_with_links.xlsx"
max_download_attempts = 3
def download_image ( url, filename, attempts= 0 ) :
"""
下载图片到指定文件名
:param url: 图片的URL链接
:param filename: 保存图片的本地文件名
:param attempts: 当前下载尝试次数,默认为0
:return: 成功保存的文件名,下载失败返回None
"""
try :
response = requests. get( url, stream= True )
if response. status_code == 200 :
with open ( filename, 'wb' ) as f:
for chunk in response. iter_content( 1024 ) :
f. write( chunk)
return url, filename
else :
raise Exception( f"HTTP错误码: { response. status_code} " )
except Exception as e:
if attempts < max_download_attempts - 1 :
print ( f"下载尝试失败: { e} ,重试..." )
return download_image( url, filename, attempts + 1 )
else :
print ( f"下载失败: { url} , { e} " )
return url, None
def create_excel_file ( image_data, output_dir, excel_filename) :
"""
创建Excel文件并添加图片信息
:param image_data: 包含图片URL和本地路径的元组列表
:param output_dir: 目标Excel文件的输出目录
:param excel_filename: Excel文件名(不含目录路径)
"""
global cm_to_px_ratio
workbook = Workbook( )
sheet = workbook. active
for idx, ( img_url, img_path) in enumerate ( image_data, start= 1 ) :
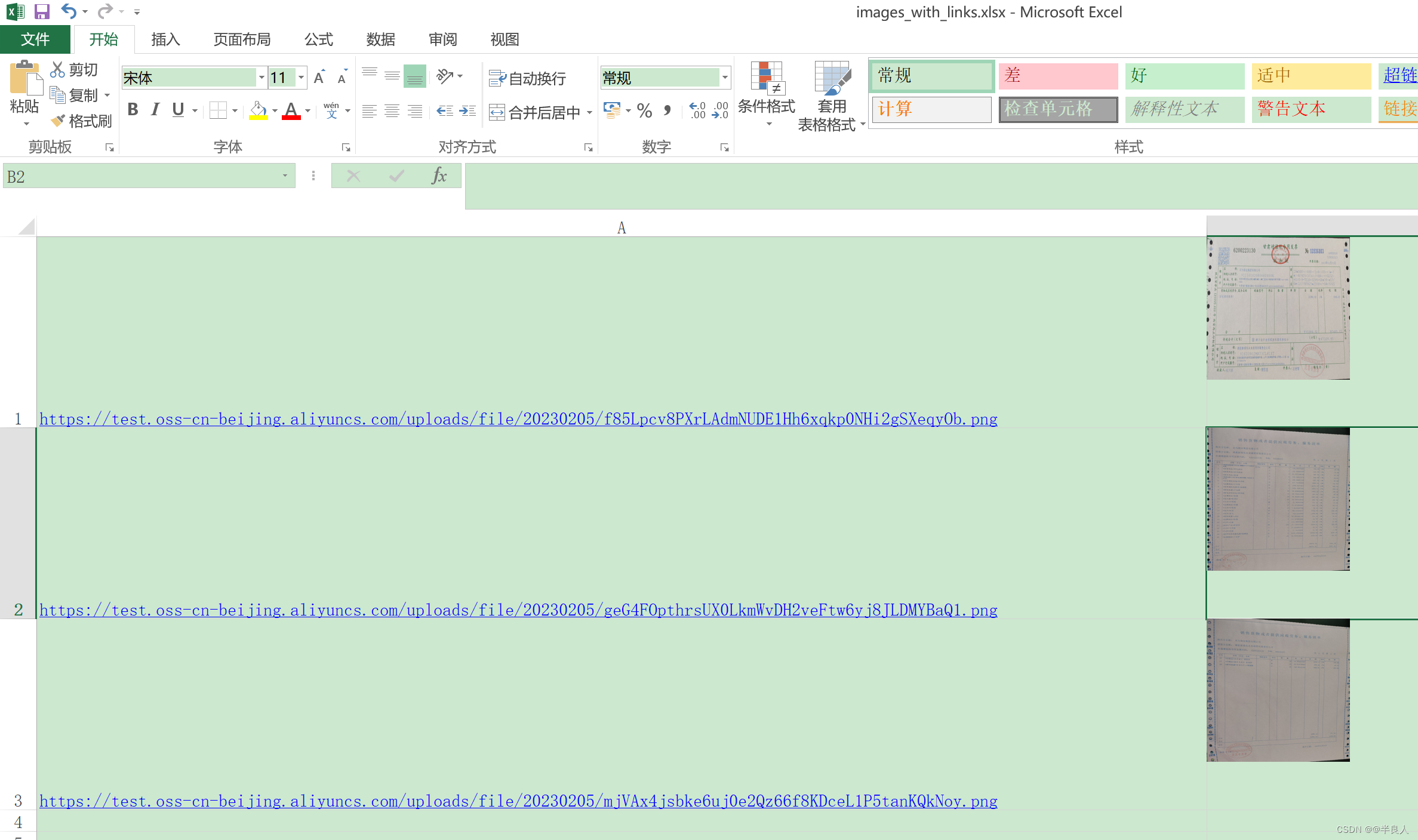
sheet[ f"A { idx} " ] = img_url
img = Image( img_path[ 1 ] )
cm_to_px_ratio = 20
img. width = 6 * cm_to_px_ratio
img. height = 6 * cm_to_px_ratio
img. anchor = f"B { idx} " . left = idx
img. top = idx
sheet. add_image( img)
sheet. column_dimensions[ 'A' ] . width = 6 * cm_to_px_ratio
sheet. column_dimensions[ 'B' ] . width = 6 * cm_to_px_ratio
sheet. row_dimensions[ idx] . height = 6 * cm_to_px_ratio
excel_full_path = os. path. join( output_dir, excel_filename)
workbook. save( excel_full_path)
print ( f"图片及其链接已保存至Excel文件: { excel_full_path} " )
if __name__ == "__main__" :
if not image_urls:
print ( "图片链接列表为空,程序退出。" )
exit( 1 )
if not os. path. exists( save_folder) :
os. makedirs( save_folder)
with ThreadPoolExecutor( max_workers= 5 ) as executor:
image_futures = [
executor. submit( download_image, url, os. path. join( save_folder, f"image { idx} . { url. split( '.' ) [ - 1 ] } " ) ) for
idx, url in enumerate ( image_urls, start= 1 ) ]
image_data = [ ( url, future. result( ) ) for idx, ( url, future) in
enumerate ( zip ( image_urls, image_futures) , start= 1 ) ]
create_excel_file( image_data, output_dir, excel_filename)







![[lesson58]类模板的概念和意义](https://img-blog.csdnimg.cn/direct/4b9d9730362a4e27b7d841b646e76381.png#pic_center)




