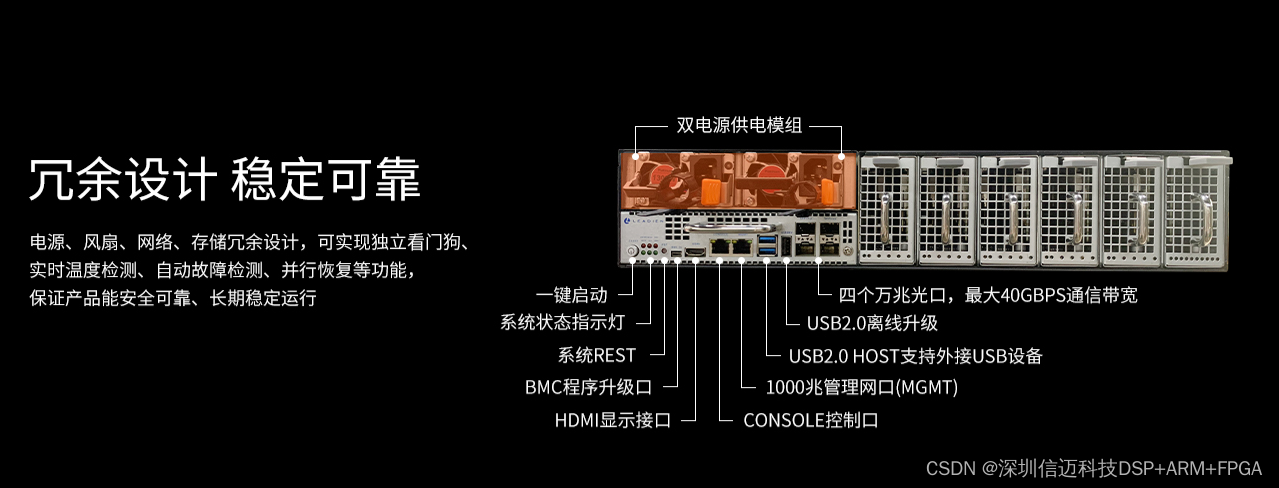
1. 主流程分析
从inference.py函数进入,主要流程包括:
1) 使用cv2获取视频中所有帧的列表,如下:

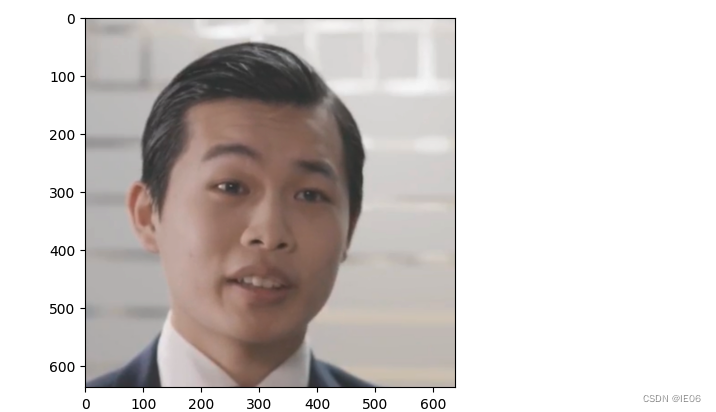
2)定义Croper。核心代码为69行:full_frames_RGB, crop, quad = croper.crop(full_frames_RGB)。其中crop是头肩位置,quad是人脸位置,得到的新的full_frames_RGB为人脸区域的截图。(此函数在ffhq_preprocess.py中),此时图像如下:
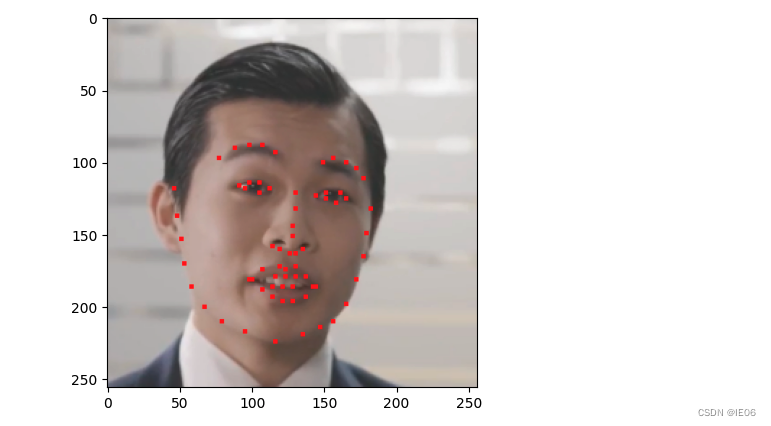
- 将头肩区域full_frames_RGB重新resize到(256,256)得到frames_pil,然后使用KeypointExtractor(face3d库,调用的是face_alignment包)获取关键点lm。lm在frames_pil上的图如下:
- 加载3d人脸重建模型(这里是一个resnet50模型),并用face3d库的lm3d函数加载BFM模型,生成人脸模型参数semantic_npy,并加载表情expression.mat,得到img_stablized。这里使用中性表情,处理后的结果如下:

5)进行图像增强,使用的是GPEN-BFR-512模型,图片变高清了:

6)接下来加载wav语音文件,并拆成块
7)进行lipSync,如下图

8) 将lipsync的结果贴到原图上,然后找嘴部的mask
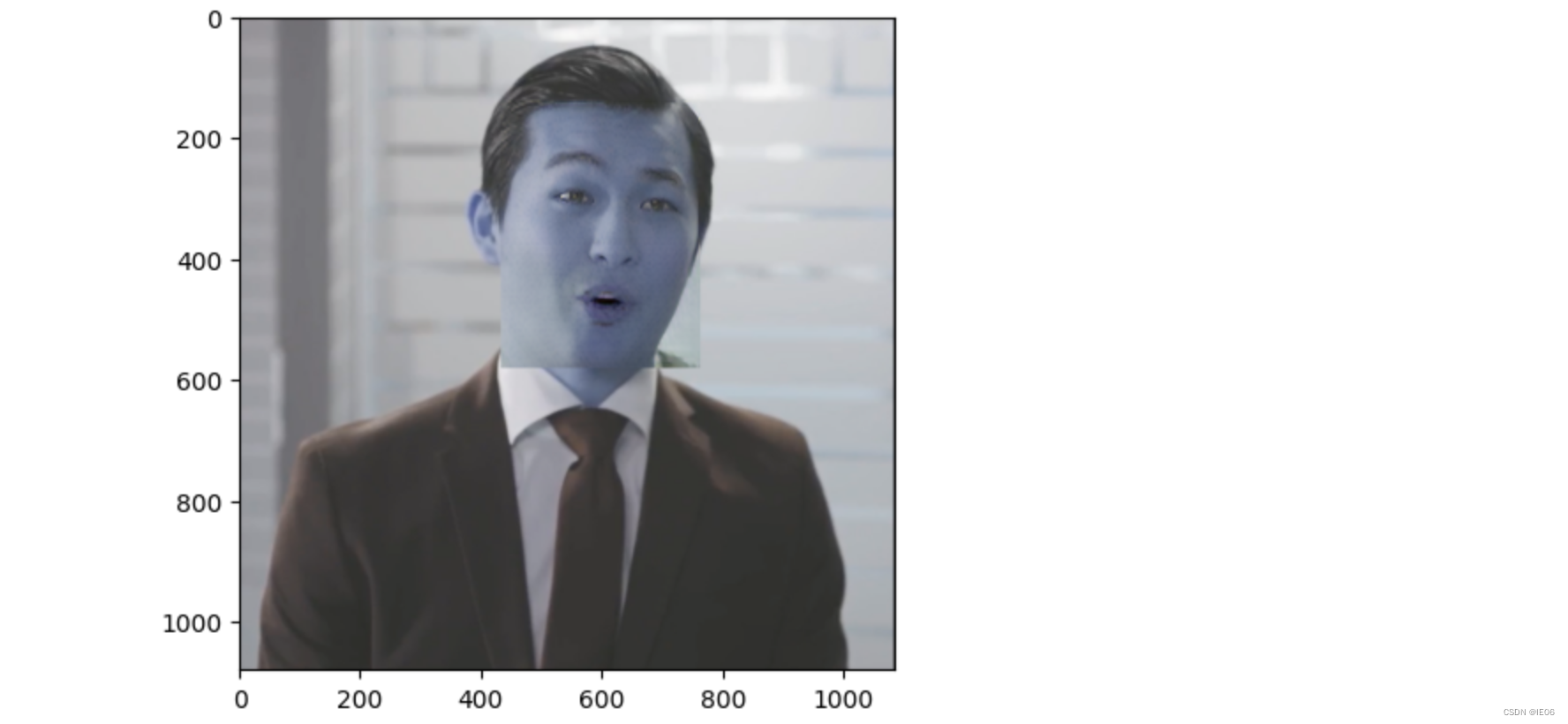
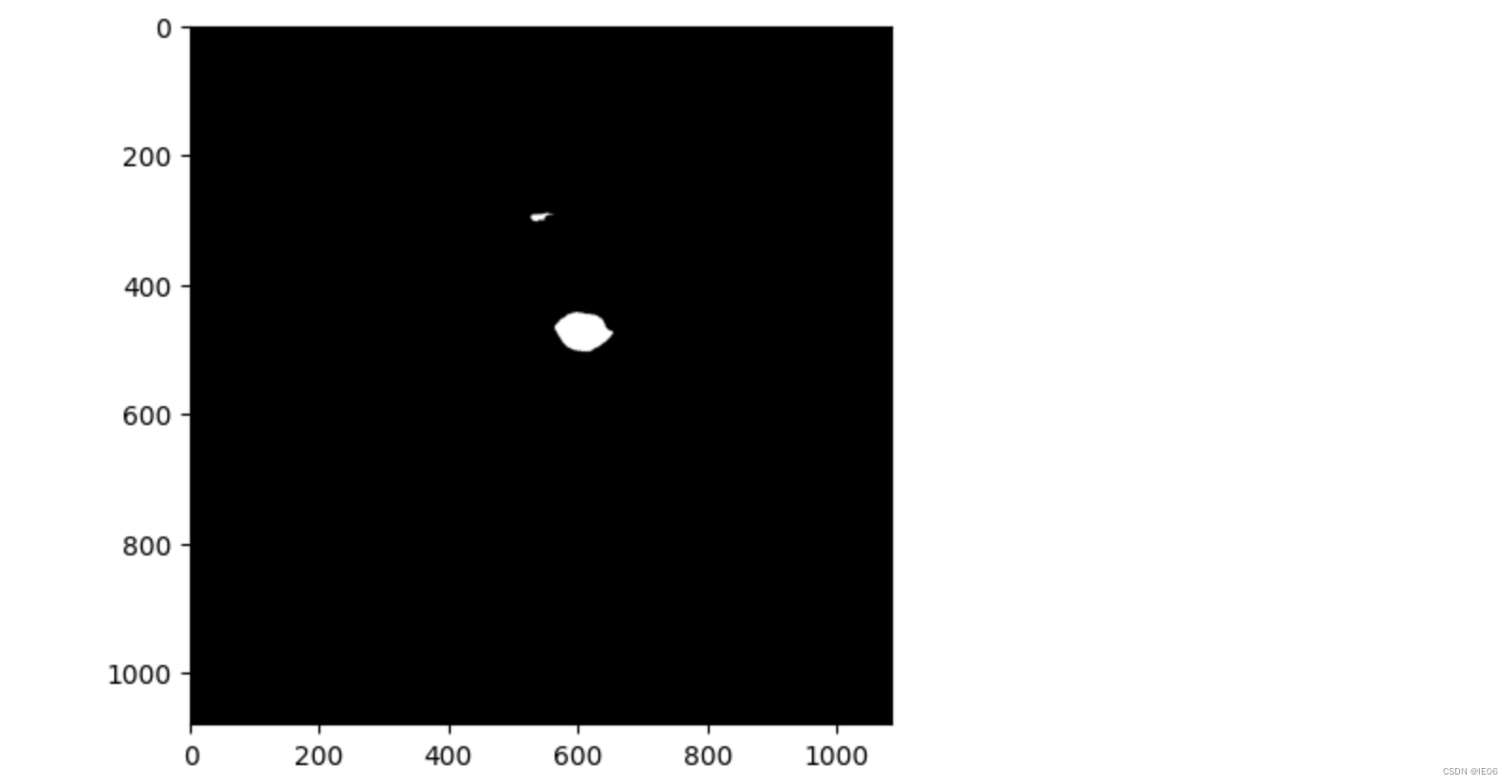
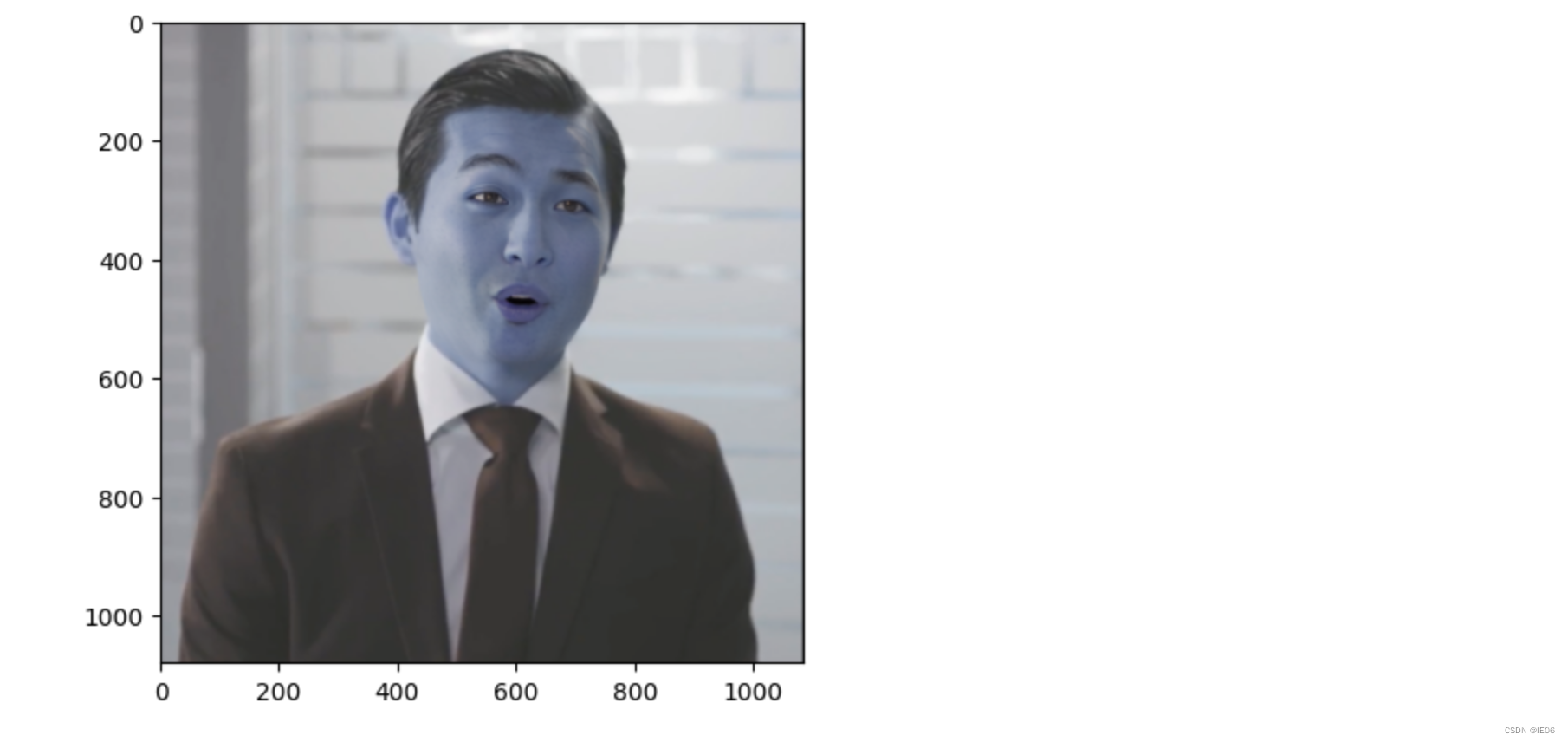
9) 使用mask,将新图和原图进行poisson blending即可:
2. dlib做人脸和关键点检测
参见http://dlib.net/face_landmark_detection.py.html
使用模型为:http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
做人脸检测部分:detector = dlib.get_frontal_face_detector()
关键点检测部分predictor = dlib.shape_predictor(‘checkpoints/shape_predictor_68_face_landmarks.dat’)
对应项目的utils.ffhq_preprocess.Croper。结果绘制如下:
for lmi in lm:
rr, cc=draw.ellipse(lmi[1],lmi[0],10,10)
draw.set_color(img,[rr,cc],[255,0,0])
rr, cc=draw.polygon_perimeter([y1,y1,y2,y2],[x1,x2,x2,x1])
draw.set_color(img,[rr,cc],[255,0,0])
plt.imshow(img,plt.cm.gray)

3. face3D库做人脸3dmm
定义的代码为88-89行:
net_recon = load_face3d_net(args.face3d_net_path, device)
lm3d_std = load_lm3d(‘checkpoints/BFM’)
其中加载模型结构load_face3d_net引用的是utils.inference_utils。
加载参数load_lm3d引用的是third_part.face3d.util.load_mats
计算获得coeff,并加载expression表情参数。
4. GPEN库做人脸增强
third_part.GPEN.gpen_face_enhancer import FaceEnhancement
接下来使用DNet进行人脸增强。DNet首先学习一个GAN来生成高质量人脸图像,然后把它嵌入到一个U型的DNN里面作为先验的decoder,然后再利用合成的低质量人脸图像微调这个’嵌入GAN先验的DNN’。
5. 使用ENet做lipsync
这段是核心部分,很费时间。加载包含LNet的ENet模型。
incomplete, reference = torch.split(img_batch, 3, dim=1)
pred, low_res = model(mel_batch, img_batch, reference)
6. 使用GFPGAN做人脸增强
代码入下:
cropped_faces, restored_faces, restored_img = restorer.enhance(
ff, has_aligned=False, only_center_face=True, paste_back=True)
# 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
mm = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 255, 255, 255, 0, 0, 0, 0, 0, 0]
mouse_mask = np.zeros_like(restored_img)
tmp_mask = enhancer.faceparser.process(restored_img[y1:y2, x1:x2], mm)[0]
mouse_mask[y1:y2, x1:x2]= cv2.resize(tmp_mask, (x2 - x1, y2 - y1))[:, :, np.newaxis] / 255.
height, width = ff.shape[:2]
restored_img, ff, full_mask = [cv2.resize(x, (512, 512)) for x in (restored_img, ff, np.float32(mouse_mask))]
img = Laplacian_Pyramid_Blending_with_mask(restored_img, ff, full_mask[:, :, 0], 10)
pp = np.uint8(cv2.resize(np.clip(img, 0 ,255), (width, height)))
pp, orig_faces, enhanced_faces = enhancer.process(pp, xf, bbox=c, face_enhance=False, possion_blending=True)
plt.imshow(pp)