文章目录
- 遇到慢查询怎么办?—— 创建索引
- 联合索引的底层的数据存储结构长什么样?
mysql脑图
阿里开发手册

遇到慢查询怎么办?—— 创建索引
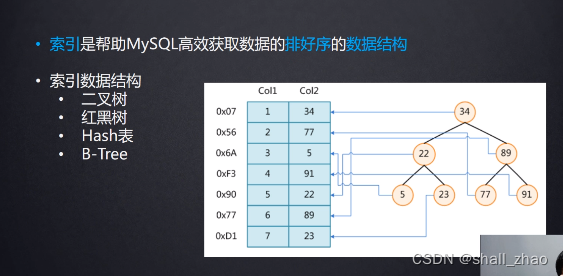
不用索引的话一个一个找太慢了,用索引就快的多。
假如使用树这样的结构建立索引,这样找一个数据,就可以减少查询磁盘的次数(IO性能很低),提高查询效率。
- mysql为什么没有采用二叉树存储数据?
假如是col1的数据,存进二叉树就是单支树,退化成链表了,索引白建了,对于自增列不支持高效查询。 - mysql为什么没有采用红黑树存储数据?
数据量大的话,树太高。 - 能不能对红黑树做优化,当数据量大的时候,树的高度依旧可控
扩大每个节点的存储数据,当存的数据多的时候,高度依旧可控——B树
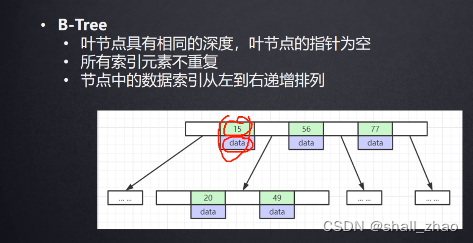
mysql也不是原封不动用B树,而是做了优化——B+树
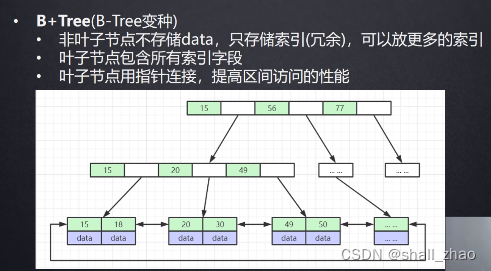
B+树的非叶子节点放到内存,叶子节点放在磁盘,节点内可以使用折半查找,这样查找效率非常高,只需要去磁盘找一次。
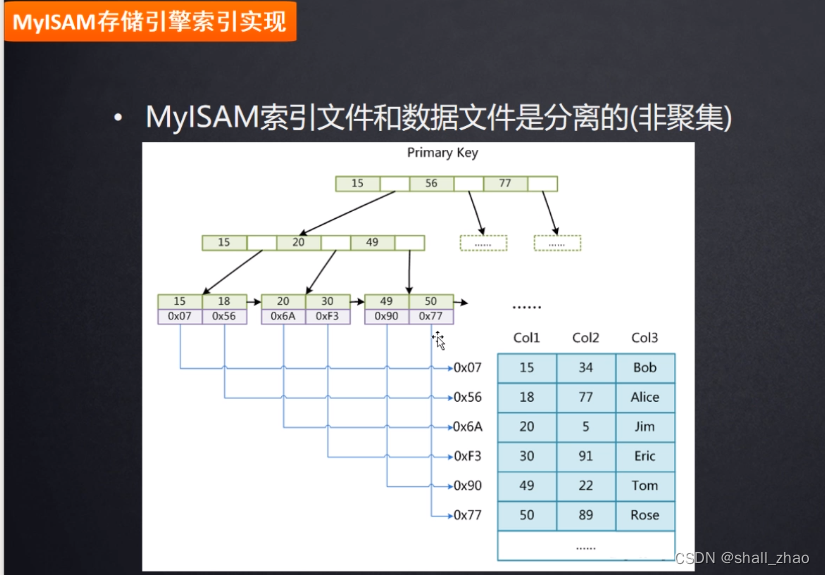
工作中很少使用myIASM,不支持事物,锁等等,我们使用Innodb
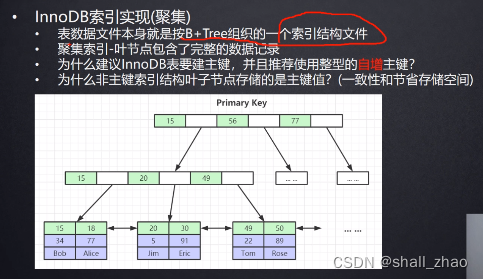
- 为什么建议InnoDB表要键主键,并且推荐使用整形的自增主键
- 为什么非主键索引结构叶子节点存储的是主键值?
因为建了主键,使用主键索引维护这个索引结构,如果没有主键,那就找第一个唯一索引,使用这个唯一索引维护索引结构,假如没有唯一索引怎么办?他就在后台维护一个隐藏字段rowId,从而维护好索引的结构,所以建立主键索引,我们可以直接用,查找效率高哎。同时,整型比大小效率高(UUID是字符串哦),占用空间小,为什么自增呢?
因为用了自增的节点,B+树永远都是往后面维护节点,可以避免节点的分裂,很少影响性能。所以自增可以提升数据插入的效率
在看这个
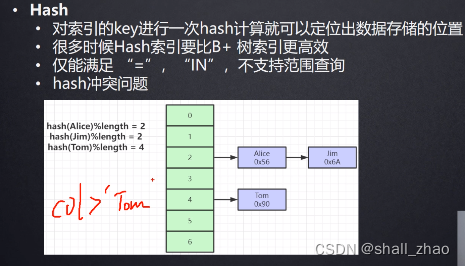
hash索引不支持范围查询,所以也不用这个索引结构。
联合索引的底层的数据存储结构长什么样?

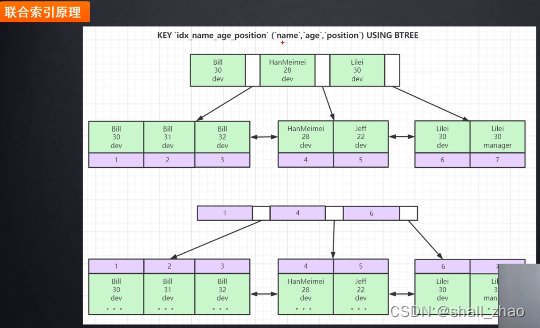

最左前最先原则,只有第一条会走联合索引。
最左前最先原则?为什么会有这个呢?要先排name,才能确定你排的age是唯一的。
后面的内容,额,公开课其实就是卖课的,后面都是主要为了卖课,不讲东西啦。