1. Yolov5
YOLOv5是是YOLO系列的一个延伸,其网络结构共分为:input、backbone、neck和head四个模块,yolov5对yolov4网络的四个部分都进行了修改,并取得了较大的提升,在input端使用了Mosaic数据增强、自适应锚框计算、自适应图片缩放; 在backbone端使用了Focus结构与CSP结构;在neck端添加了FPN+PAN结构;在head端改进了训练时的损失函数,使用GIOU_Loss,以及预测框筛选的DIOU_nms。
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
- input:Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- backbone:Focus结构与CSP结构;
- neck:添加了FPN+PAN结构;
- head:改进了训练时的损失函数,使用GIOU_Loss,以及预测框筛选的DIOU_nms。
1.1 网络结构
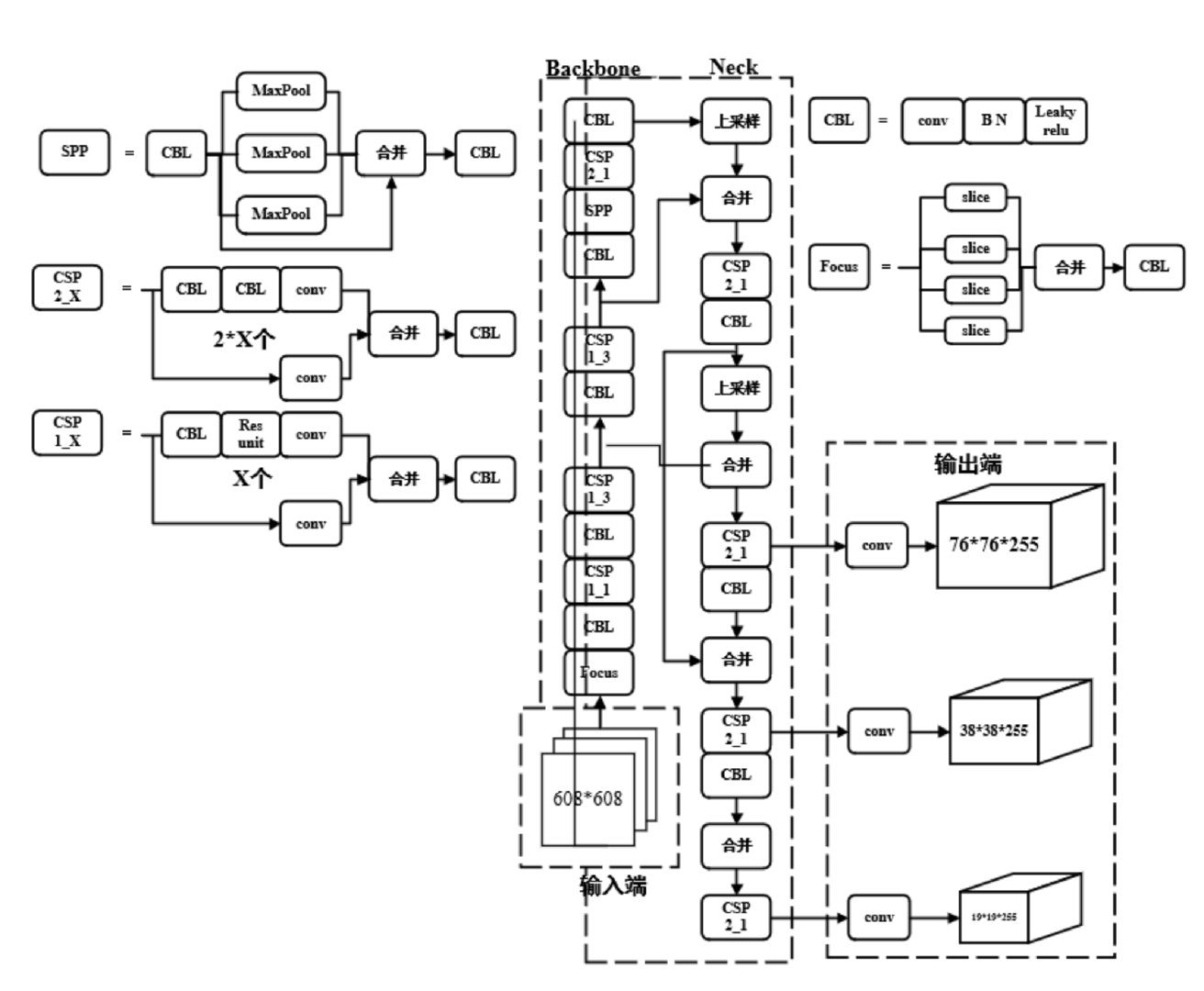 yolov5的网络结构如上图所示,yolo系列的算法基本可以分为四个模块,input、neck和head。下面对着4个模块依次进行分析。
yolov5的网络结构如上图所示,yolo系列的算法基本可以分为四个模块,input、neck和head。下面对着4个模块依次进行分析。
1.2 input
输入端主要对输入的图片进行预处理。该网络的输入图像大小为608×608,预处理主要是将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
Mosaic数据增强:Mosaic数据增强方法采用了4张图片,按照随机缩放、随机裁剪和随机排布的方式进行拼接而成,这种增强方法可以将几张图片组合成一张,这样不仅可以丰富数据集的同时极大的提升网络的训练速度,而且可以降低模型的内存需求。
自适应锚框计算:在YOLO系列算法中,针对不同的数据集,都需要设定特定长宽的Anchor。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与真实框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环。YOLOv5模型在每次训练时,根据数据集的名称自适应的计算出最佳的锚点框。
自适应图片缩放:传统的缩放方式都是按原始比例缩放图像并用黑色填充至目标大小,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLOv5算法的推理速度,该算法提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。具体的实现步骤如下所述:
- 根据原始图片大小与输入到网络图片大小计算缩放比例;
- 根据原始图片大小与缩放比例计算缩放后的图片大小;
- 计算黑边填充数值,该黑边数值不要求一定使图像缩放至指定大小,而是自适应模型中卷积和池化的大小。
1.3 backbone
主干网络部分主要引入了focus结构和CSP结构。
focus结构
Focus重要的是切片操作,如下图所示,4x4x3的图像切片后变成2x2x12的特征图。
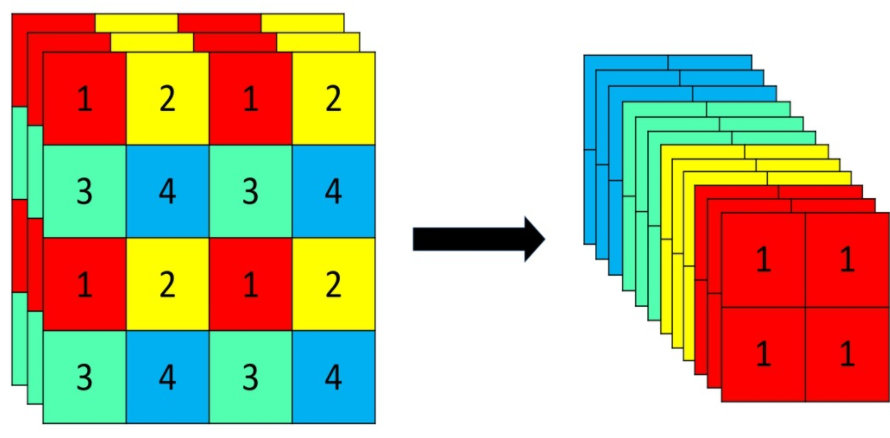
在yolov5网络模型中,原始608x608x3的图像输入Focus结构,采用切片操作,先变成304x304x12的特征图,再经过一次32个卷积核的卷积操作,最终变成304x304x32的特征图。
CSP结构
yolov4网络结构中,借鉴了CSPNet的设计思路,仅仅在主干网络中设计了CSP结构。而yolov5中设计了两种CSP结构,CSP1_X结构应用于主干网络中,另一种CSP2_X结构则应用于Neck网络中。
neck
yolov5的Neck网络仍然使用了FPN+PAN结构,但是在它的基础上做了一些改进操作,yolov4的Neck结构中,采用的都是普通的卷积操作。而YOLOv5的Neck网络中,采用借鉴CSPnet设计的CSP2结构,从而加强网络特征融合能力。
head
在head部分,yolov5改进了损失函数,采用GIoU_Lossounding box的损失函数并添加了预测框筛选的DIOU_nms,这两个点并不是yolov5的原创内容,如果想深入了解可以参考相关论文,这里不再赘述。
而v7.0版本最重要的更新是增加了对实例分割的支持,主要的更新了实例分割的代码,提高了分割的精度与速度。这个版本也许是Yolov5的最后一次更新了,就目前的消息,YOLOv5团队已经转向了YOLOv8的更新,因此,7.0版本大概率是YOLOv5的最终稳定版。
整个代码与数据下载地址:https://download.csdn.net/download/matt45m/89215063
2.环境安装
2.1 创建虚拟环境
我这里使用Anaconda创建虚拟环境,conda可以从清华源下载。下载自己想要的版本,这里是我用的版本:
安装完成之后创建环境:
conda create --name yolov5 python==3.10
activate yolov5
这里建议单独安装pytorch,torch要对应自己电脑的cuda版本进行安装,我这里使用的cuda是11.7,cudnn 8.5,单独安装torch的命令可以在torch官网可以获取:

conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
2.2 下载源码
在激活的环境下把源码拉取,如果拉取不了,可以直接下载源码包:
git clone https://github.com/ultralytics/yolov5.git
然后更改yolov5源码里面的requirements.txt文件,把这两行注掉:
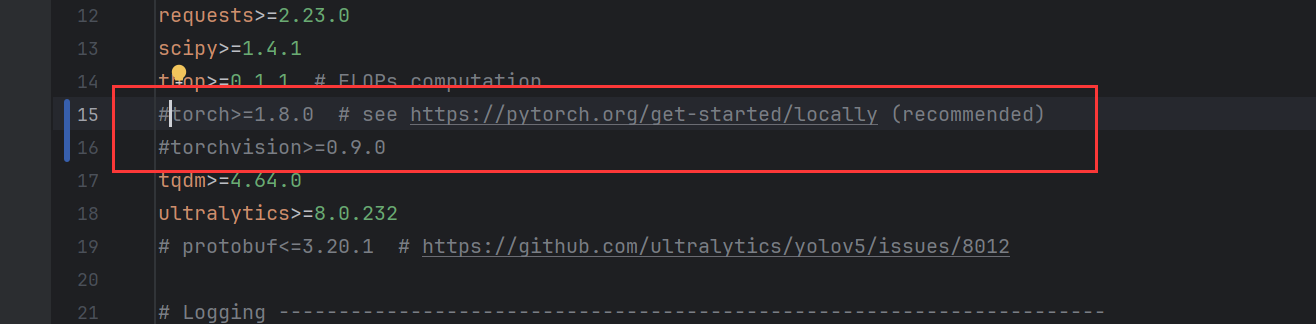
安装所需的依赖:
cd yolov5
pip install -r requirements.txt
哪里安装过程中出错,就查看安装错误库,单独安装或者使用源码安装。
3.数据集处理
这里使用的数据是河道水面的漂浮物,数据总共有5000多张,使用的标注工具是Labelme。

3.1数据标注
标注的格式可以选voc或者是yolo格式,如果选择voc的格式,则要转换,这里使用的voc数据格式,标注如下:


3.2 数据转换
数据如果是xml格式,则要把数据转换成txt格式,在yolov5目录下,创建一个dataset目录,然后把标注好的数据集的数像和xml标签文件在这个目录下:
然后在yolov5目录下创建一个xml_txt.py文件,脚本代码如下:
import os
import glob
import argparse
import random
import xml.etree.ElementTree as ET
from PIL import Image
from tqdm import tqdm
def get_all_classes(xml_path):
xml_fns = glob.glob(os.path.join(xml_path, '*.xml'))
class_names = []
for xml_fn in xml_fns:
tree = ET.parse(xml_fn)
root = tree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
class_names.append(cls)
return sorted(list(set(class_names)))
def convert_annotation(img_path, xml_path, class_names, out_path):
output = []
im_fns = glob.glob(os.path.join(img_path, '*.jpg'))
for im_fn in tqdm(im_fns):
if os.path.getsize(im_fn) == 0:
continue
xml_fn = os.path.join(xml_path, os.path.splitext(os.path.basename(im_fn))[0] + '.xml')
if not os.path.exists(xml_fn):
continue
img = Image.open(im_fn)
height, width = img.height, img.width
tree = ET.parse(xml_fn)
root = tree.getroot()
anno = []
xml_height = int(root.find('size').find('height').text)
xml_width = int(root.find('size').find('width').text)
if height != xml_height or width != xml_width:
print((height, width), (xml_height, xml_width), im_fn)
continue
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in class_names:
continue
cls_id = class_names.index(cls)
# print(cls_id)
xmlbox = obj.find('bndbox')
xmin = int(xmlbox.find('xmin').text)
ymin = int(xmlbox.find('ymin').text)
xmax = int(xmlbox.find('xmax').text)
ymax = int(xmlbox.find('ymax').text)
cx = (xmax + xmin) / 2.0 / width
cy = (ymax + ymin) / 2.0 / height
bw = (xmax - xmin) * 1.0 / width
bh = (ymax - ymin) * 1.0 / height
anno.append('{} {} {} {} {}'.format(cls_id, cx, cy, bw, bh))
if len(anno) > 0:
output.append(im_fn)
with open(im_fn.replace('.jpg', '.txt'), 'w') as f:
f.write('\n'.join(anno))
# random.shuffle(output)
# train_num = int(len(output) * 0.9)
# with open(os.path.join(out_path, 'train.txt'), 'w') as f:
# f.write('\n'.join(output[:train_num]))
# with open(os.path.join(out_path, 'val.txt'), 'w') as f:
# f.write('\n'.join(output[train_num:]))
def parse_args():
parser = argparse.ArgumentParser('generate annotation')
parser.add_argument('--img_path', default='dataset/Trash/images', type=str, help='input image directory')
parser.add_argument('--xml_path', default='dataset/Trash/xml',type=str, help='input xml directory')
parser.add_argument('--out_path',default='Trash/', type=str, help='output directory')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
class_names = get_all_classes(args.xml_path)
convert_annotation(args.img_path, args.xml_path, class_names, args.out_path)
运行完成之后,会在images目录下生成与图像同名的.txt文件:
4.数据处理
4.1 数据分割
训练之后要对数据集进行分割,一般都要分为训练集,验证集,测试集,一般按8:1:1的分法。在yolov5根目录下创建data_splitting.py脚本,脚本代码如下:
import os
import random
from shutil import move
# 指定原始目录
source_dir = 'dataset/Trash/images'
# 创建子目录:训练集、验证集和测试集
sub_dirs = ['train', 'val', 'test']
for sub_dir in sub_dirs:
os.makedirs(os.path.join(source_dir, sub_dir), exist_ok=True)
# 收集所有.jpg和对应的.txt文件
jpg_files = {f for f in os.listdir(source_dir) if f.lower().endswith('.jpg')}
txt_files = {f[:-4] + '.txt' for f in jpg_files} # 假设.txt文件名是去掉.jpg后缀的.jpg文件名
# 将.jpg和.txt文件映射成字典,以.jpg文件名为键
all_files = jpg_files.union(txt_files)
file_dict = {f: os.path.join(source_dir, f) for f in all_files}
# 随机打乱文件列表
random.shuffle(list(file_dict.keys()))
# 根据给定的比例分配文件到不同的目录
total_files = len(file_dict)
split1 = int(total_files * 0.8) # 训练集的文件数量
split2 = int(total_files * 0.9) # 验证集的文件数量
# 训练集
train_files = list(file_dict.keys())[:split1]
# 验证集
val_files = list(file_dict.keys())[split1:split2]
# 测试集
test_files = list(file_dict.keys())[split2:]
# 移动文件到相应的子目录
for files, sub_dir in ((train_files, 'train'), (val_files, 'val'), (test_files, 'test')):
for file in files:
source_path = file_dict[file]
dest_dir = os.path.join(source_dir, sub_dir)
dest_path = os.path.join(dest_dir, file)
# 确保目标子目录中包含对应的.jpg和.txt文件
if file.endswith('.jpg'):
move(source_path, dest_path) # 移动.jpg文件
txt_file = file[:-4] + '.txt'
if txt_file in file_dict:
txt_source_path = file_dict[txt_file]
move(txt_source_path, dest_dir) # 移动对应的.txt文件
print("文件分配完成。")
运行完成之后,会下images下生成三个目录:
目录里面有对应的图像与txt标签文件:
4.2 处理数据
在dataset/Trash目录下创建一个lables文件,然后把上面生成三个目录train, val, test复制一份到labels目录里面:
把images下的三个目录里面的.txt文件删掉,只保留.jpg文件。
然后再把labels下的三个目录里面的.jpg文件删除掉只保留.txt文件。
4.3 创建数据配置文件
在yolov5/data目录下创建一个trash_data.yaml
添加以下内容:
path: ./dataset/Trash # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: test
# Classes
names:
0: trash
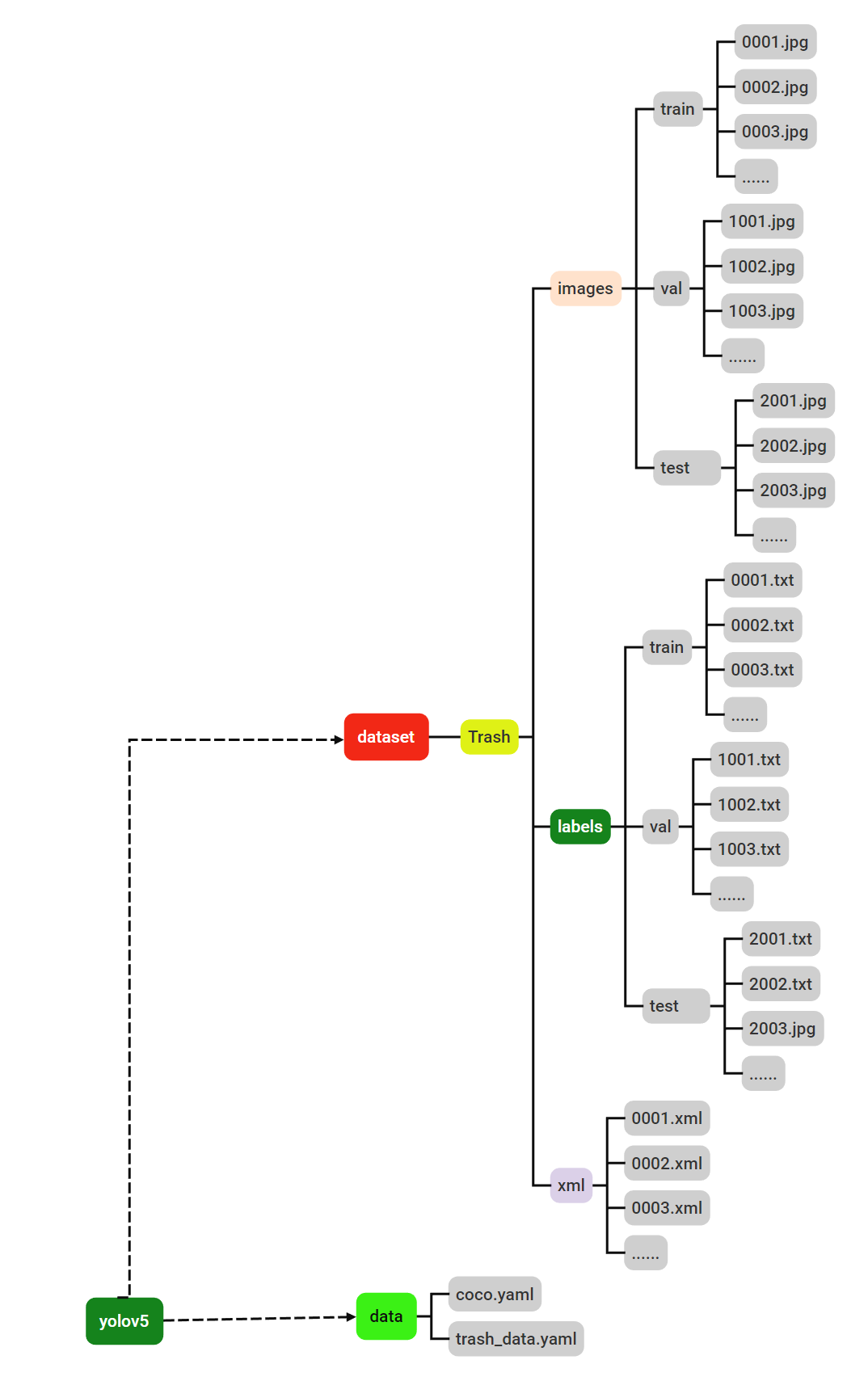
最终数据目录结构如下:
5.模型训练
5.1 模型训练
训练代码配置:
def parse_opt(known=False):
"""Parses command-line arguments for YOLOv5 training, validation, and testing."""
parser = argparse.ArgumentParser()
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
parser.add_argument("--epochs", type=int, default=100, help="total training epochs")
parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)")
parser.add_argument("--rect", action="store_true", help="rectangular training")
parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training")
parser.add_argument("--nosave", action="store_true", help="only save final checkpoint")
parser.add_argument("--noval", action="store_true", help="only validate final epoch")
parser.add_argument("--noautoanchor", action="store_true", help="disable AutoAnchor")
parser.add_argument("--noplots", action="store_true", help="save no plot files")
parser.add_argument("--evolve", type=int, nargs="?", const=300, help="evolve hyperparameters for x generations")
parser.add_argument(
"--evolve_population", type=str, default=ROOT / "data/hyps", help="location for loading population"
)
parser.add_argument("--resume_evolve", type=str, default=None, help="resume evolve from last generation")
parser.add_argument("--bucket", type=str, default="", help="gsutil bucket")
parser.add_argument("--cache", type=str, nargs="?", const="ram", help="image --cache ram/disk")
parser.add_argument("--image-weights", action="store_true", help="use weighted image selection for training")
parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument("--multi-scale", action="store_true", help="vary img-size +/- 50%%")
parser.add_argument("--single-cls", action="store_true", help="train multi-class data as single-class")
parser.add_argument("--optimizer", type=str, choices=["SGD", "Adam", "AdamW"], default="SGD", help="optimizer")
parser.add_argument("--sync-bn", action="store_true", help="use SyncBatchNorm, only available in DDP mode")
parser.add_argument("--workers", type=int, default=8, help="max dataloader workers (per RANK in DDP mode)")
parser.add_argument("--project", default=ROOT / "runs/train", help="save to project/name")
parser.add_argument("--name", default="exp", help="save to project/name")
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")
parser.add_argument("--quad", action="store_true", help="quad dataloader")
parser.add_argument("--cos-lr", action="store_true", help="cosine LR scheduler")
parser.add_argument("--label-smoothing", type=float, default=0.0, help="Label smoothing epsilon")
parser.add_argument("--patience", type=int, default=100, help="EarlyStopping patience (epochs without improvement)")
parser.add_argument("--freeze", nargs="+", type=int, default=[0], help="Freeze layers: backbone=10, first3=0 1 2")
parser.add_argument("--save-period", type=int, default=-1, help="Save checkpoint every x epochs (disabled if < 1)")
parser.add_argument("--seed", type=int, default=0, help="Global training seed")
parser.add_argument("--local_rank", type=int, default=-1, help="Automatic DDP Multi-GPU argument, do not modify")
# Logger arguments
parser.add_argument("--entity", default=None, help="Entity")
parser.add_argument("--upload_dataset", nargs="?", const=True, default=False, help='Upload data, "val" option')
parser.add_argument("--bbox_interval", type=int, default=-1, help="Set bounding-box image logging interval")
parser.add_argument("--artifact_alias", type=str, default="latest", help="Version of dataset artifact to use")
# NDJSON logging
parser.add_argument("--ndjson-console", action="store_true", help="Log ndjson to console")
parser.add_argument("--ndjson-file", action="store_true", help="Log ndjson to file")
return parser.parse_known_args()[0] if known else parser.parse_args()
更改yolov5/models/yolov5s.yaml文件,把nc类别改成自己数据类别数目,这里只有一个类别,所以是1:
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
运行命令:
python train.py --img 640 --batch 8 --epochs 150 --data ./data/trash_data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt
- –img 640 #训练图像大小
- –batch 8 #批次大小,如果GPU够大,可以改成更大,这里2的倍数,如果报显存报错,则改小
- –epochs 150 #迭代次数
- –data ./data/trash_data.yaml #数据配置文件
- –cfg ./models/yolov5s.yaml #模型配置文件
- –weights yolov5s.pt #第一次运动会下载这个权重文件,如果下载其间报错,可以手动下载放到指定目录,然后指定模型路径
手动模型下载地址

开始训练:
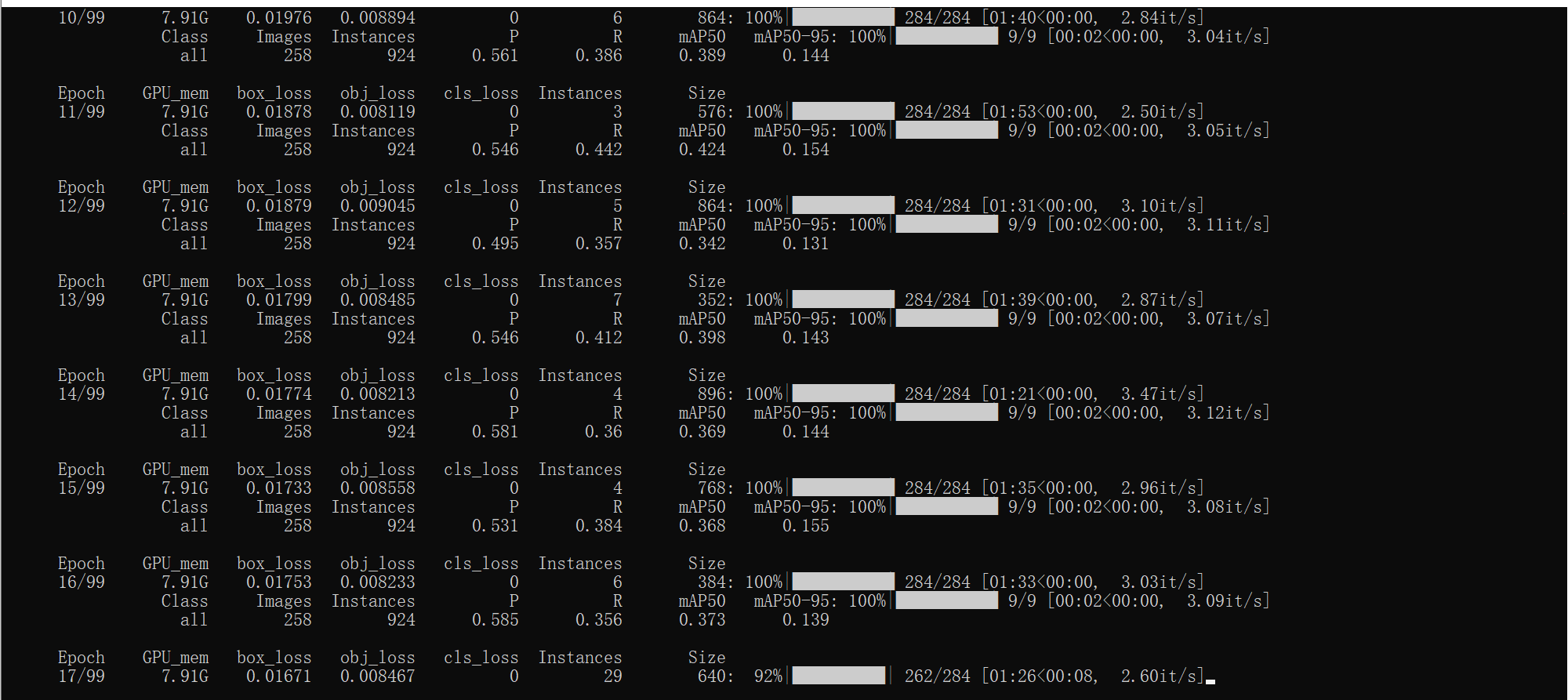
5.2 训练结果
训练完成之后,会在yolov5/run目录下看找到训练的结果:
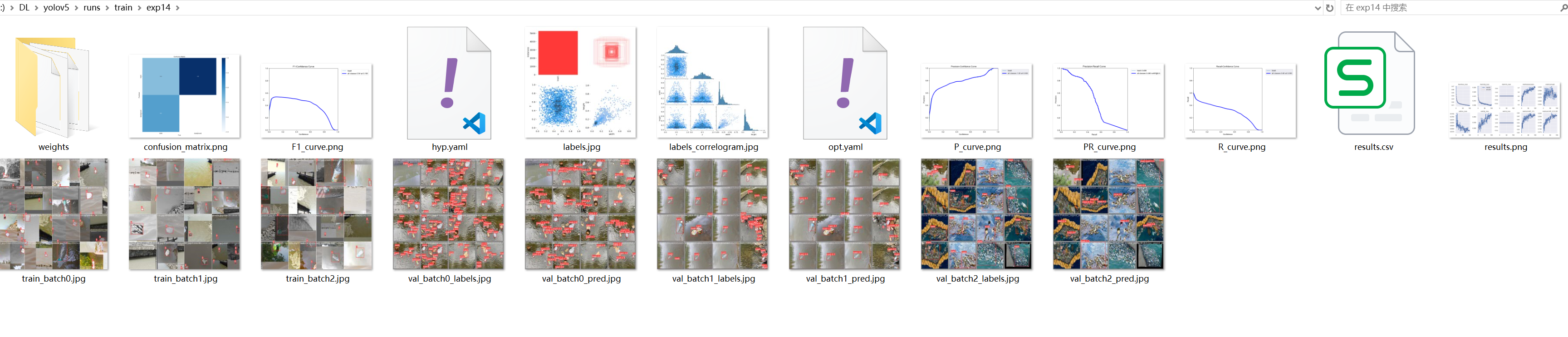
可以看到验证结果:

7.常见错误解决
7.1 解决错误:RuntimeError: result type Float can‘t be cast to the desired output type __int64
原因:
原因是新版本的torch无法自动执行转换,旧版本torch可以。
解决方法:
将utils/loss.py中gain = torch.ones(7, device=targets.device)改为gain = torch.ones(7, device=targets.device).long()即可。
7.2 AttributeError: module ‘numpy‘ has no attribute ‘float‘
原因:
这是numpy版本过高的原因,降低numpy版本就可以
解决方法:
pip uninstall numpy
pip install numpy==1.23.5
7.3 AssertionError:Label class 1 exceeds nc=1 in yolo/dataset.ymal Possible class labels are 0-0
原因:
这是因为训练类型只有一个的原因。
解决方法:
找到train.py文件中这一行代码,注释掉。
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
注释后:
#assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
assert nf > 0 or not augment, f’{prefix}No labels found in {cache_path}, can not start training. {HELP_URL}’
AssertionError: train: No labels found in
7.4 No labels found in (Done) 或者 Exception: Dataset not found
原因:
这是数据目录没有对上的原因。就是代码无法找到lables目录里面的文件。
解决方法:
数据集详细参考4.3节的格式。
7.5 Could not run ‘torchvision::nms’ with arguments from the ‘CUDA’ backend (Done)
原因:
因为CUDA与torch版本不匹配造成的,当前版本:
| 环境、工具 | 版本 |
|---|---|
| CUDA | 11.3 |
| torch | 1.13.1+cu116 |
| torchvision | 0.14.1 |
解决方法:
降低torch版本解决。
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.douban.com/simple
更换版本后的各个环境工具版本:
| 环境、工具 | 版本 |
|---|---|
| CUDA | 11.3 |
| torch | 1.9.0+cu111 |
| torchvision | 0.10.0+cu111 |



![[lesson58]类模板的概念和意义](https://img-blog.csdnimg.cn/direct/4b9d9730362a4e27b7d841b646e76381.png#pic_center)