系列文章
第2章 多机多卡nccl-tests 对比分析
目录
- 系列文章
- 前言
- 一、本地环境
- 1. 网卡接口
- 2. RDMA
- 3. TOPO信息
- pcie信息
- nvidia-smi topo -m
- 二、nccl-test对比分析
- 1. 相关环境变量
- 2. 不同情况的对比
- 3. 总结与分析
前言
NCCL(NVIDIA Collective Communications Library)是NVIDIA提供的一套用于GPU加速的通信库,主要用于在多个GPU之间进行数据传输和通信。它被设计为在异构计算环境中(包括NVIDIA GPU和CPU)高效地执行数据并行和模型并行。
NCCL是深度学习训练中的一个关键组件,因为它能够有效地在多个GPU之间传输数据,这对于加速神经网络的训练非常重要。在现代的深度学习框架中,如TensorFlow、PyTorch和Keras,NCCL通常作为后端通信库,与框架的API紧密集成,为用户提供一个简单易用的编程接口。
这里通过使用不同的网络配置,在双机进行了nccl-test测试,获得了不同的结果,并尝试进行简单分析。
一、本地环境
有2台机器,配置完全相同
1. 网卡接口
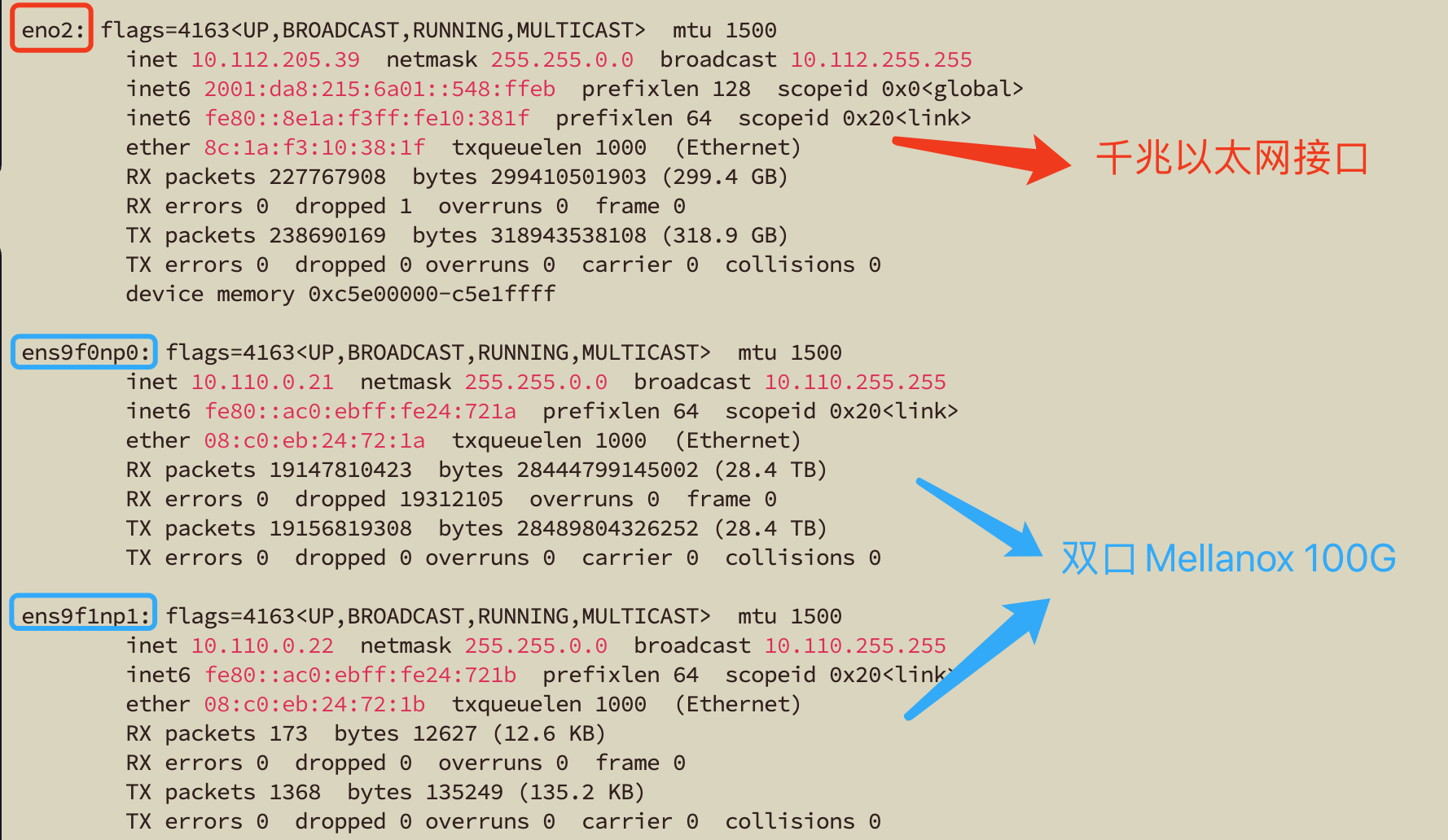
ifconfig的结果:
- eno2为普通千兆以太网接口,最大带宽1Gbps;
- ens9f0np0 和ens9f1np1为Mellanox 100G网卡的两个接口
2. RDMA
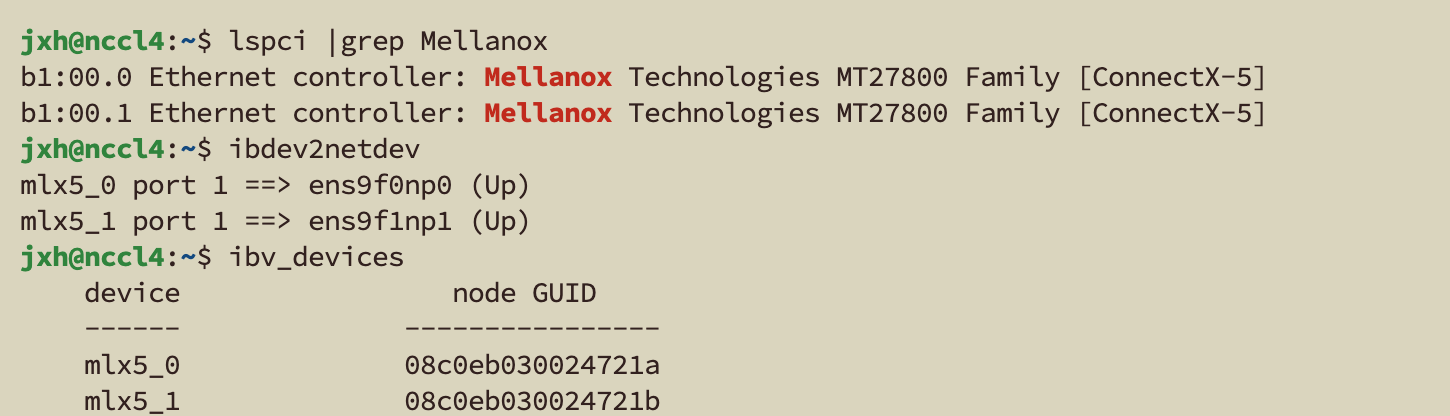
jxh@nccl4:~$ lspci |grep Mellanox //查看服务器中 mellaox 网卡信息
b1:00.0 Ethernet controller: Mellanox Technologies MT27800 Family [ConnectX-5]
b1:00.1 Ethernet controller: Mellanox Technologies MT27800 Family [ConnectX-5]
jxh@nccl4:~$ ibdev2netdev //查看以太网设备与IB设备关联信息
mlx5_0 port 1 ==> ens9f0np0 (Up)
mlx5_1 port 1 ==> ens9f1np1 (Up)
jxh@nccl4:~$ ibv_devices //查看RDMA设备
device node GUID
------ ----------------
mlx5_0 08c0eb030024721a
mlx5_1 08c0eb030024721b
3. TOPO信息
pcie信息
可以通过nccl传入环境变量NCCL_TOPO_DUMP_FILE=./dump-topo.xml \来转储nccl搜索到的本机topo
设置NCCL_IB_DISABLE=1时本机信息如下:
<system version="1">
<cpu numaid="1" affinity="ffff,fffff000,000000ff,fffffff0,00000000" arch="x86_64" vendor="GenuineIntel" familyid="6" modelid="106">
<pci busid="0000:ca:00.0" class="0x060400" vendor="0x11f8" device="0x4000" subsystem_vendor="0x11f8" subsystem_device="0xbeef" link_speed="16.0 GT/s PCIe" link_width="16">
<pci busid="0000:cd:00.0" class="0x030000" vendor="0x10de" device="0x2684" subsystem_vendor="0x7377" subsystem_device="0x0000" link_speed="16.0 GT/s PCIe" link_width="16">
<gpu dev="0" sm="89" rank="0" gdr="0"/>
</pci>
<pci busid="0000:cf:00.0" class="0x030000" vendor="0x10de" device="0x2684" subsystem_vendor="0x7377" subsystem_device="0x0000" link_speed="16.0 GT/s PCIe" link_width="16">
<gpu dev="1" sm="89" rank="1" gdr="0"/>
</pci>
</pci>
<pci busid="0000:b1:00.0" class="0x020000" vendor="0x15b3" device="0x1017" subsystem_vendor="0x15b3" subsystem_device="0x0007" link_speed="8.0 GT/s PCIe" link_width="8">
<nic>
<net name="ens9f0np0" dev="1" speed="100000" port="0" latency="0.000000" guid="0x1" maxconn="65536" gdr="0"/>
</nic>
</pci>
<pci busid="0000:b1:00.1" class="0x020000" vendor="0x15b3" device="0x1017" subsystem_vendor="0x15b3" subsystem_device="0x0007" link_speed="8.0 GT/s PCIe" link_width="8">
<nic>
<net name="ens9f1np1" dev="2" speed="100000" port="0" latency="0.000000" guid="0x2" maxconn="65536" gdr="0"/>
</nic>
</pci>
</cpu>
<cpu numaid="0" affinity="0000,00000fff,ffffff00,0000000f,ffffffff" arch="x86_64" vendor="GenuineIntel" familyid="6" modelid="106">
<pci busid="0000:65:00.1" class="0x020000" vendor="0x8086" device="0x1521" subsystem_vendor="0xffff" subsystem_device="0x0000" link_speed="5.0 GT/s PCIe" link_width="4">
<nic>
<net name="eno2" dev="0" speed="1000" port="0" latency="0.000000" guid="0x0" maxconn="65536" gdr="0"/>
</nic>
</pci>
</cpu>
</system>
正如以上topo显示:
- 有两张4090,均为Pcie 4.0 *16
- 一个100G网卡上的两个接口 均为 Pcie3.0 * 8
不设置NCCL_IB_DISABLE=1时本机信息如下:
<system version="1">
<cpu numaid="1" affinity="ffff,fffff000,000000ff,fffffff0,00000000" arch="x86_64" vendor="GenuineIntel" familyid="6" modelid="106">
<pci busid="0000:ca:00.0" class="0x060400" vendor="0x11f8" device="0x4000" subsystem_vendor="0x11f8" subsystem_device="0xbeef" link_speed="16.0 GT/s PCIe" link_width="16">
<pci busid="0000:cd:00.0" class="0x030000" vendor="0x10de" device="0x2684" subsystem_vendor="0x7377" subsystem_device="0x0000" link_speed="16.0 GT/s PCIe" link_width="16">
<gpu dev="0" sm="89" rank="0" gdr="0"/>
</pci>
<pci busid="0000:cf:00.0" class="0x030000" vendor="0x10de" device="0x2684" subsystem_vendor="0x7377" subsystem_device="0x0000" link_speed="16.0 GT/s PCIe" link_width="16">
<gpu dev="1" sm="89" rank="1" gdr="0"/>
</pci>
</pci>
<pci busid="0000:b1:00.0" class="0x020000" vendor="0x15b3" device="0x1017" subsystem_vendor="0x15b3" subsystem_device="0x0007" link_speed="8.0 GT/s PCIe" link_width="8">
<nic>
<net name="mlx5_0" dev="0" speed="100000" port="1" latency="0.000000" guid="0x1a72240003ebc008" maxconn="131072" gdr="0"/>
</nic>
</pci>
</cpu>
</system>
对比之前的topo 删除了eno2,enf9f0np0等,取而代之的是mlx5_0,这是因为nccl会自动使用速度快的。
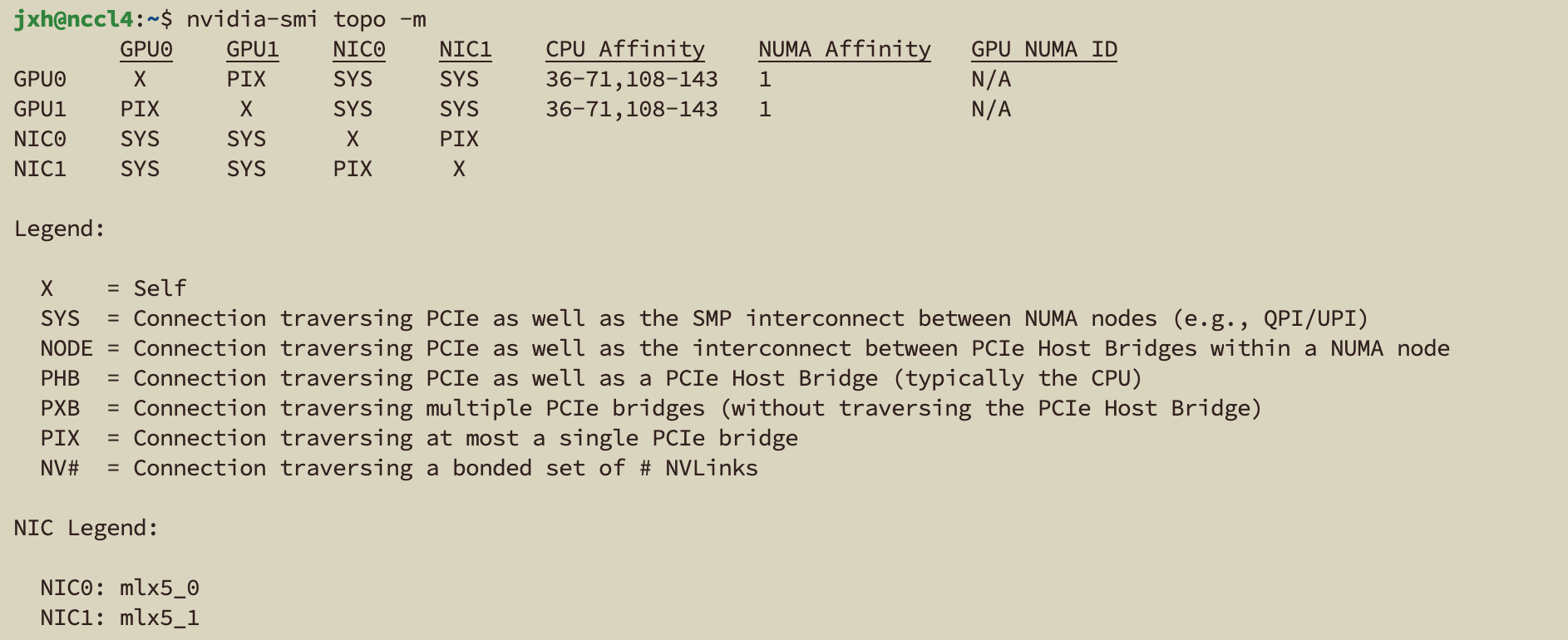
nvidia-smi topo -m
二、nccl-test对比分析
1. 相关环境变量
以下为nccl用户手册的介绍:
- NCCL_SOCKET_IFNAME
- NCCL_IB_DISABLE
NCCL_SOCKET_IFNAME 变量指定用于通信的IP接口。
NCCL_IB_DISABLE 变量禁用NCCL使用的IB/RoCE传输。相反,NCCL将回退到使用IP套接字,默认值为0。
以下就是对这两个环境变量进行控制来做的对比分析
2. 不同情况的对比
- IB disable=1,指定eno2——>实际使用eno2进行socket通信。
顺便,这里的算法带宽algbw就是总的数据量除以时间。这里最大0.12GB/s=0.12*8=0.96Gbps≈1Gbps,已经非常接近千兆以太网支持的最大带宽了。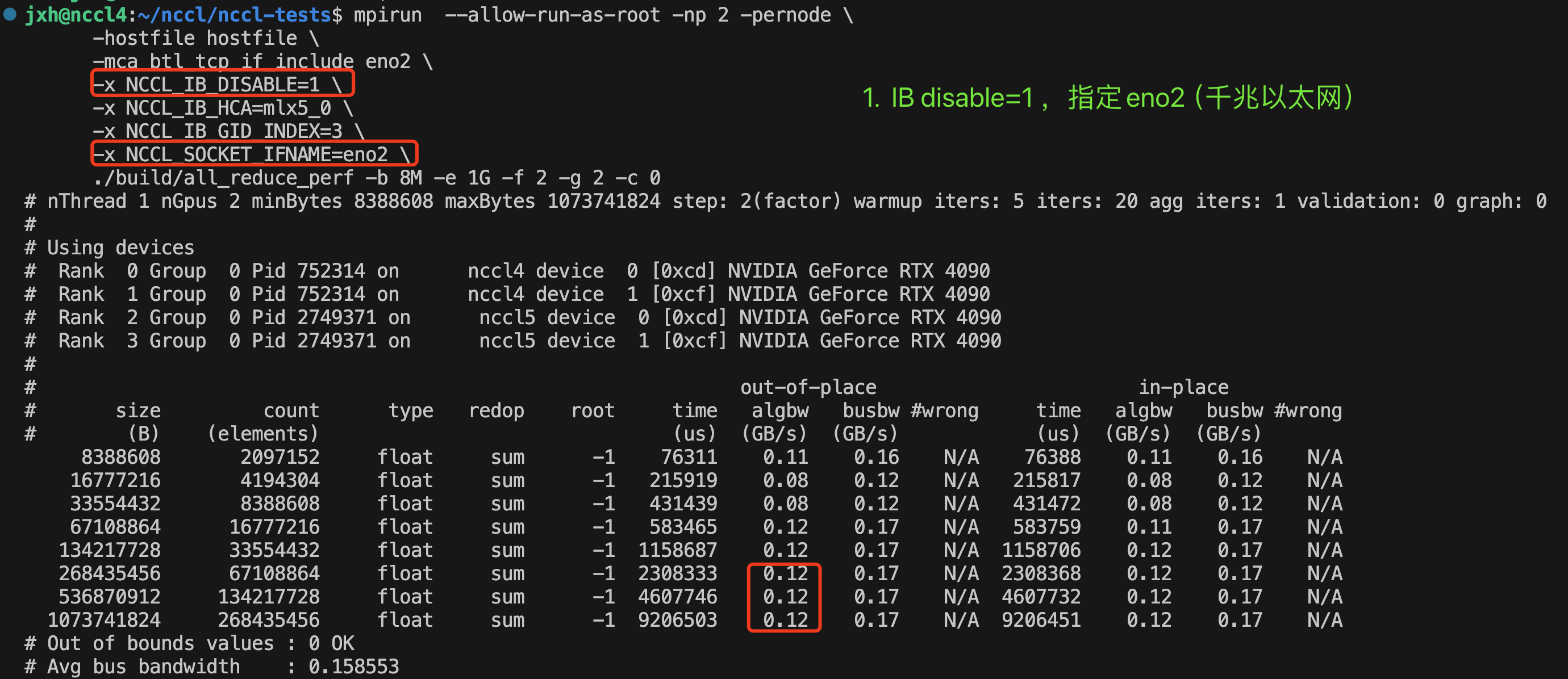
- IB disable=1,指定ens9f0np0——>实际使用ens9f0np0(100G网卡接口)进行socket通信。
这里最大算法带宽1.97GB/s=1.97*8=15.76Gbps<100Gbps,距离100G仍有差距。
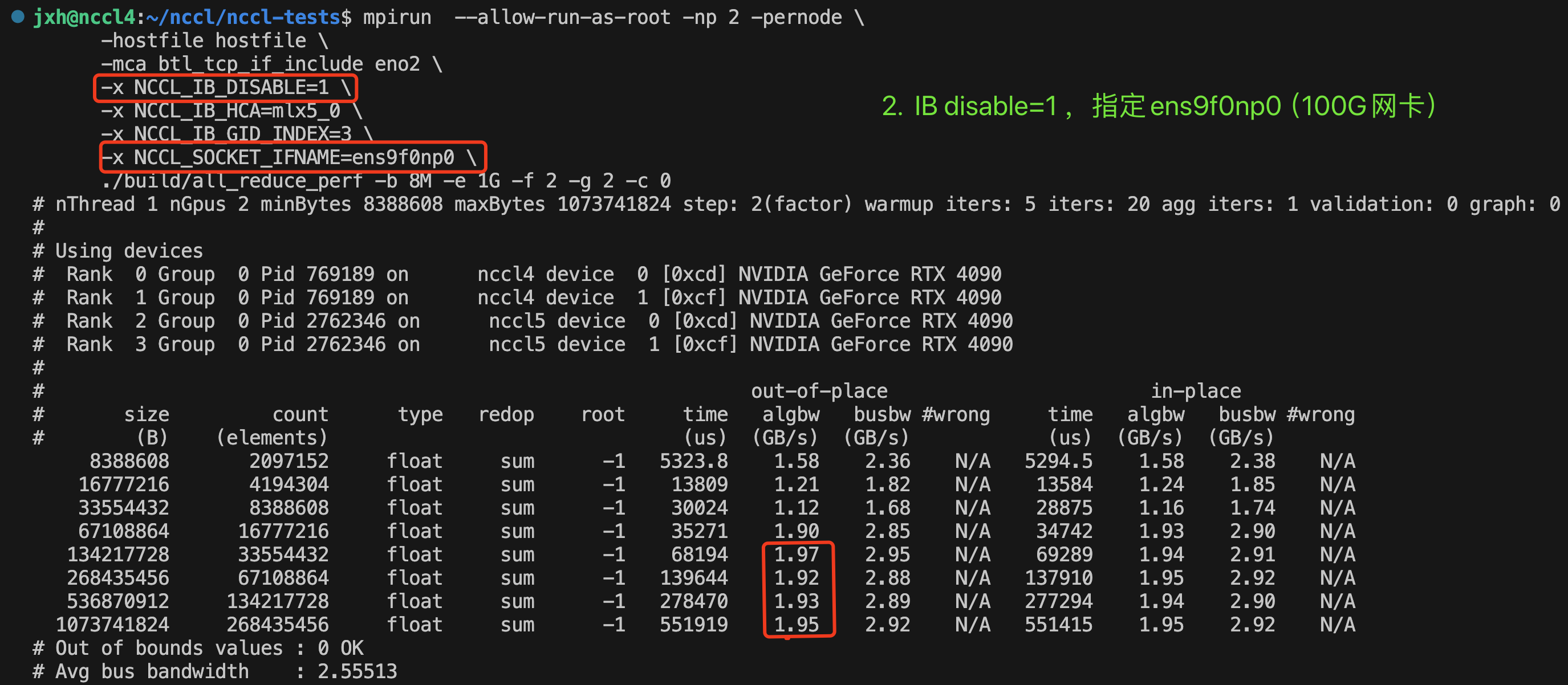
- IB disable=1,不指定网卡——>结果和情况2相同
- IB disable=1,指定eno2——>实际使用mlx5_0进行RoCE通信。
这里最大算法带宽5.81GB/s=5.81*8=46.48Gbps,已经接近100G的一半。
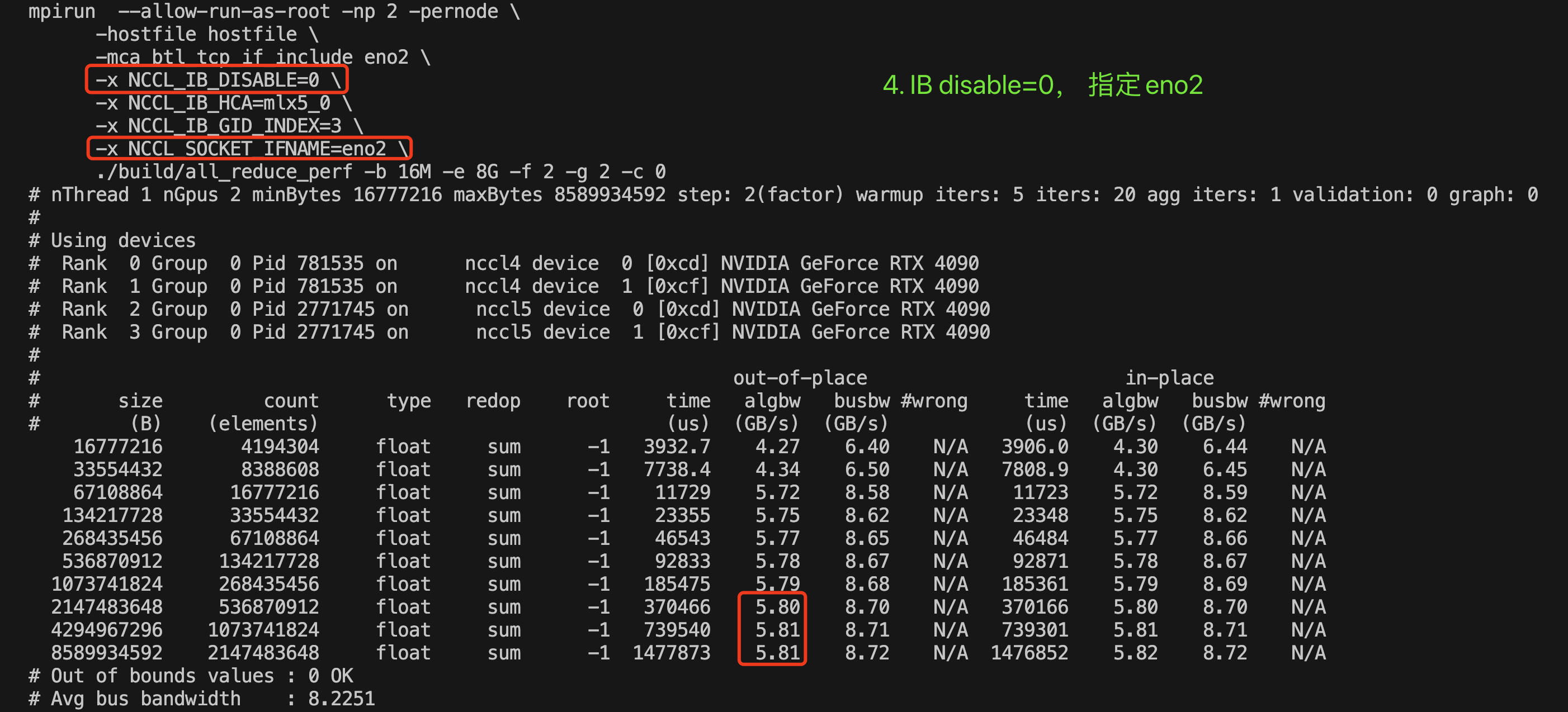
- IB disable=1,指定ens9f0np0——>结果和情况4相同
- 不设置IB disable,不指定用于socket通信的网卡——>结果和情况4相同,使用mlx5_0 RoCE,最大算法带宽5.81GB/s=5.81*8=46.48Gbps,即默认情况下nccl会选择最优的情况,
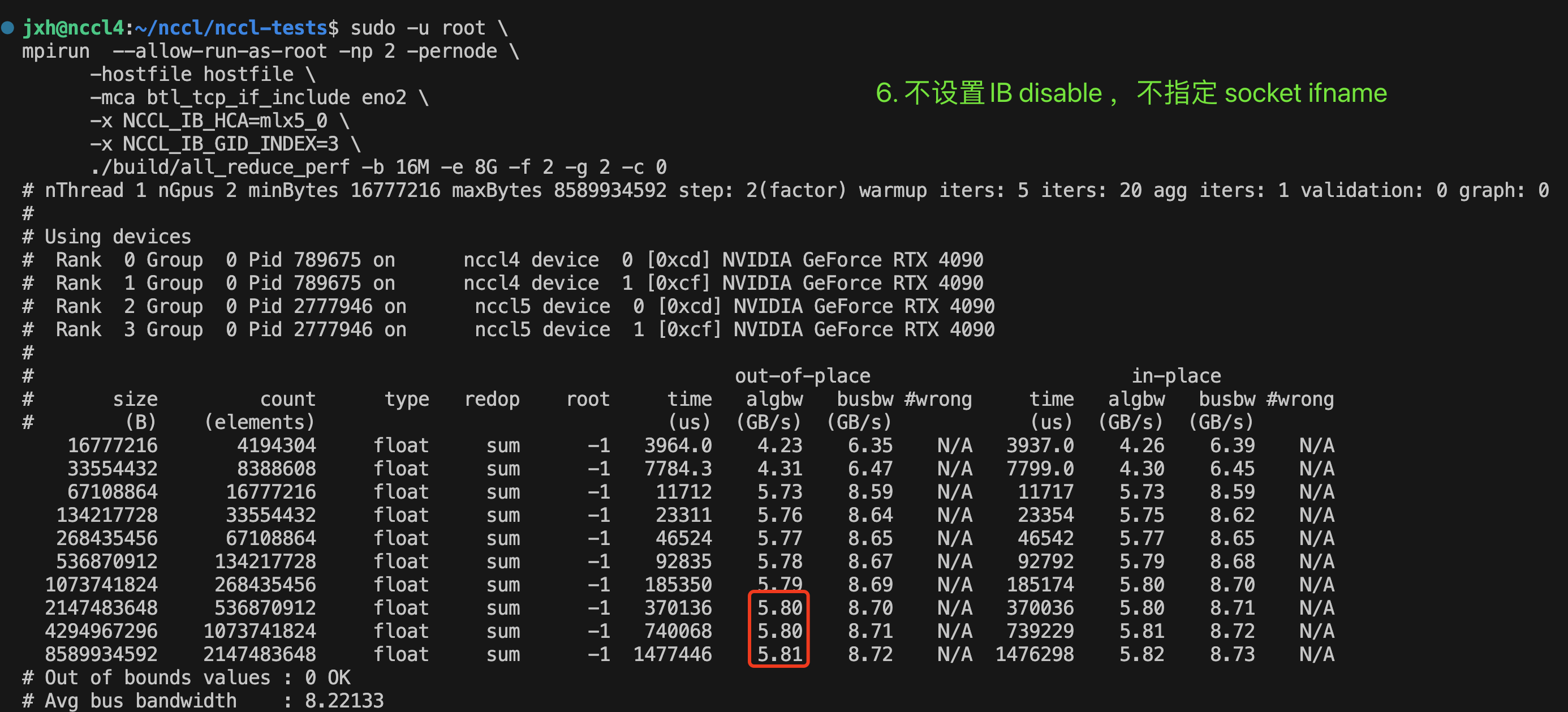
这里有一个疑问,因为这台机子的mellanox网卡连接的是Pcie 3.0 *8 ,根据这个issue
Why { “16 GT/s”,120 } paired in kvDictPciGen?#1206
nccl中的带宽最大应该为6GB/s,而5.81已经比较接近,那这里限制带宽的因素是pcie嘛?
3. 总结与分析
将以上6种情况整理成表格:
| 序号 | IB_disable | SOCKET_IFNAME | 最大算法带宽 | 实际情况 |
|---|---|---|---|---|
| 1 | 1 | eno2 | 0.12 GB/s | use eno2(1G) |
| 2 | 1 | ens9f0np0 | 1.97 GB/s | use 100G网卡 |
| 3 | 1 | 不指定网卡 | 1.97 GB/s | use 100G网卡 |
| 4 | 0 | eno2 | 5.81 GB/s | use RoCE |
| 5 | 0 | ens9f0np0 | 5.81 GB/s | use RoCE |
| 6 | 不设置(默认为0) | 不指定网卡 | 5.81 GB/s | use RoCE |
- 根据表格1-3条,禁用ib的情况下,除非明确指定eno2(千兆以太网接口,最大1Gbps),否则会自动使用速度快的ens9f0np0(100G网卡接口),根据第一个xml文件,也可以看到两者有着100倍的差距。
<net name="eno2" dev="0" speed="1000"
<net name="ens9f0np0" dev="1" speed="100000"
- 根据表格4-6条,未明确禁用ib的情况下,无论指定哪一个socket ifname,结果都相同且是使用RoCE通信,这是因为nccl会自动使用带宽大的,即IB的优先级高于socket,在nccl info信息中也可以看到,nccl会先搜索ib设备,如果没找到或者用户显式禁用,才会回退到套接字,
- 对应以上情况就是
mlx_5(IB/RoCE) > ens9f0np0(socket) > eno2(socket)