1、安装influxdb
本文采用Influxdb2,版本为influxdb:2.7.6。安装方式为docker。
执行安装命令
docker pull influxdb:2.7.6
创建服务
docker run --name=influxdb2 -p 8086:8086 -v $PWD:/var/lib/influxdb -d influxdb:2.7.6
其中 $PWD 指定为当前目录。可以根据需求进行更换
2、访问 http://ip:8086/进入influxdb系统进行配置,需要配置org和bucket。
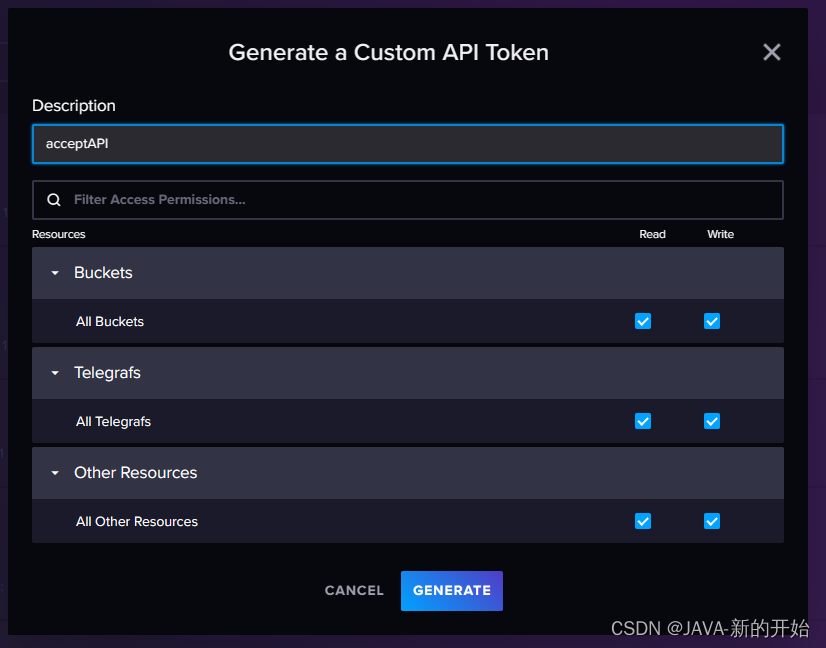
3、创建访问API。访问API创建成功后,一定要保存下来,否则,下次将无法查看。


4、开始编码,导入JAR包。需要导入 influxdb-client-java包
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
</dependency>
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>3.2.0</version>
</dependency>
</dependencies>5、创建连接并进行写入数据
InfluxDBClientOptions options = InfluxDBClientOptions.builder()
.url("http://192.168.10.123:8086")
.authenticateToken("KHRmELvLVlof-iJu-t6EdZmotertANGJlq6BpLFV5Ezi9dvKBeYWe2eU8JzFt3PwhYb2YvIcXBLiACIITZ5hZw==".toCharArray())
.org("szyk")
.bucket("szyk")
.build();
InfluxDBClient client = InfluxDBClientFactory.create(options);
OrganizationsApi organizationsApi = client.getOrganizationsApi();
System.out.println(organizationsApi.findOrganizations());
Instant now = Instant.now(); // 当前时间
Point dataPoint = Point.measurement("temperature")
.addTag("location", "New York")
.addField("value", "123")
.time(now.toEpochMilli(), WritePrecision.MS); // 使用毫秒精度
List<Bucket> list = client.getBucketsApi().findBuckets();
for (Bucket bucket : list) {
System.out.println(bucket.getName());
}
client.getWriteApiBlocking().writePoint(dataPoint);
System.out.println();
}6、注意事项
influxdb中measurement类似于关系形数据库中的表,tag为列,有索引,可以进行快速查询,field列没有索引不能进行快速查询,但field可以进行运算。
。以下是这三个概念的区别:
1. Measurement(测量)
定义: measurement是InfluxDB中存储时间序列数据的顶级容器。它代表了您想要收集和分析的某一类特定数据。每个measurement对应于关系型数据库中的一个表或消息队列中的一个主题。
作用: measurement将具有相同特性和目的的数据点集合在一起。它们定义了所存储数据的上下文,并作为查询InfluxDB中数据的主要入口点。
特点:
命名:measurement通过一个唯一的字符串名称来标识,通常反映其所代表的数据(如 cpu_usage、temperature、server_metrics)。
关系:多个measurement可以存在于同一个数据库(或InfluxDB 2.x中的“bucket”),但每个数据点只属于一个measurement。
无预定义结构:与关系型数据库中的表不同,measurement没有固定的模式。一个measurement关联的tag和field集可以在不同的数据点之间变化。
2. Tag(标签)
定义: tags是以键值对形式存在的,用于对measurement内数据点进行分类并提供上下文信息。它们用于查询时的数据过滤、分组和索引。
作用: tags使您能够基于元数据或分类信息高效地筛选和聚合数据。设计上,tag值被索引,使得基于tag条件的大规模数据查询变得快速。
特点:
键值对:每个tag由一个字符串键和一个字符串值组成(如 host="server-01" 或 region="us-west-2")。
不可变:一旦写入,tag值无法更新。要更改tag值,必须写入一个带有更新后tag的新数据点。
查询性能:tag值被索引,有利于快速查找和高效过滤查询结果。然而,过度使用tags可能会影响写入性能并因索引开销增加存储需求。
不参与数值计算:tag值不适合用于数学运算或聚合函数。它们主要用于过滤和分组结果。
3. Field(字段)
定义: fields存储了时间序列数据的实际数值或字符串值。它们代表了measurement内数据点可测量的量或属性。
作用: fields包含了您希望随时间记录和分析的定量或定性数据。它们是InfluxDB中聚合、统计计算和可视化的主要目标。
特点:
类型:fields可以具有数值类型(整数、浮点数、布尔型)或字符串类型。数值类型的fields适合进行数学运算。
非索引:与tags不同,field值未被索引。涉及field值的查询可能需要进行全扫描,这可能比基于tag的查询慢,特别是在大规模数据集上。
参与计算:field值用于数学表达式、聚合函数(如 mean、max、sum)和统计分析中。
可变:对于同一组合的measurement、tags和时间戳,field值可以随时间改变。InfluxDB将这些变化记录为单独的数据点。
总结:
Measurement 定义了所收集数据的上下文和类别,类似于关系型数据库中的一个表。
Tag 提供了用于高效过滤和分组数据的元数据和分类信息,充当索引键。
Field 存储了您打算测量、分析和可视化的实际定量或定性数据值。