参考快速入门LLM
参考究竟什么是神经网络
1 深度学习
1.1 神经网络和深度学习
神经网络是一种模拟人脑神经元工作方式的机器学习算法,也是深度学习算法的基本构成块。神经网络由多个相互连接的节点(也称为神经元或人工神经元)组成,这些节点被组织成层次结构。通过训练,神经网络可以学习从输入数据(例如图像、文本或声音)中提取有用的特征,并根据这些特征进行分类、预测或其他任务。
神经网络是一种机器学习算法,但它与传统机器学习在几个关键方面有所不同。其中一个重要的区别是神经网络能够自我学习和改进,不需要人为干预。通过训练,神经网络可以 自动从数据中提取有用的特征,这使得它在处理大规模数据集时具有优势。相比之下,传统机器学习算法通常需要手动选择和提供特征。
深度学习的一个关键优势是它处理大数据的能力,随着数据量的增加,传统机器学习技术在性能和准确性方面可能会变得效率低下。而深度学习算法,由于其强大的表示能力和对数据的强大处理能力,仍然能够保持良好的性能和准确性。这使得深度学习成为数据密集型应用的理想选择,尤其适用于处理大规模数据集。
深入理解深度学习的底层结构可以帮助我们更好地设计和改进模型,以及更好地解释和调试模型的结果。虽然使用计算机自动生成输出可以提供一些初步的结果,但对深度学习结构的理解可以帮助我们更好地理解模型的工作原理,发现潜在的问题,以及进行更有针对性的改进。
(1)通过分析神经网络的结构,我们可以找到优化它的方法,来获得更好的性能。例如,我们可以调整层数或节点数,或者调整网络处理输入数据的方式,来改进网络的预测或分类准确率。
(2)此外,通过了解神经网络的结构和运作原理,可以开发出更适合特定任务的神经网络。例如,可以利用神经网络分析医学图像,以辅助疾病诊断或提高医学影像分析的准确性。在股市预测方面,神经网络也可以用于分析大量的历史数据和市场动态,以预测未来的股票价格走势。
1.2 神经网络的工作原理
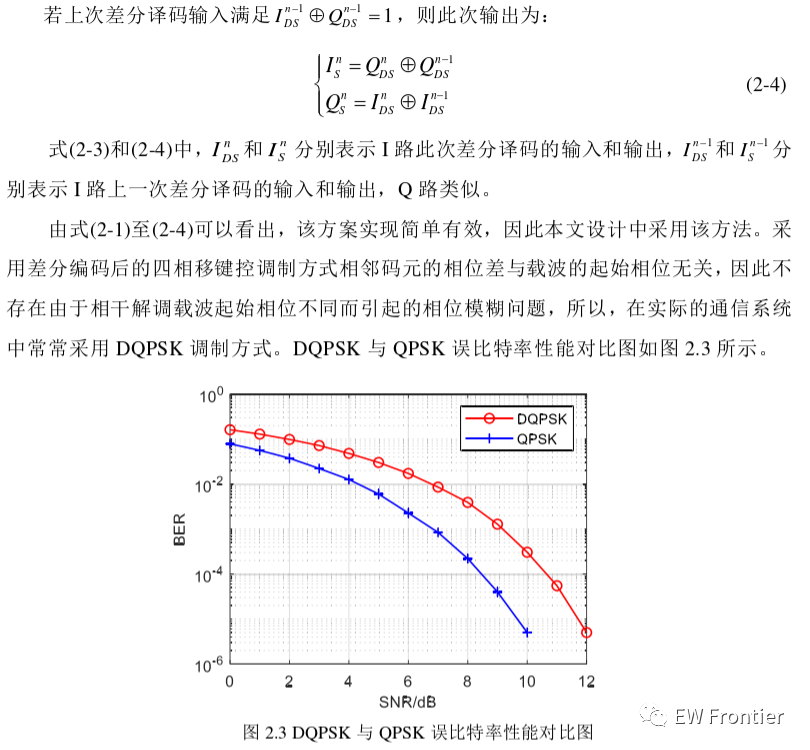
每个神经元代表一个计算单元,它接收一组输入,执行一组计算,并产生一个输出,该输出被传递到下一层。就像我们大脑中的神经元一样,神经网络中的每个节点都会接收输入,对其进行处理,并将输出传递给下一个节点。

随着数据在网络中移动,节点之间的连接会根据数据中的模式而增强或减弱。这使得网络能够从数据中学习,并根据所学内容进行预测或决策。
(1)网格的行被排列成水平的一维阵列,然后被转换为垂直阵列,形成第一层神经元。就像这样;
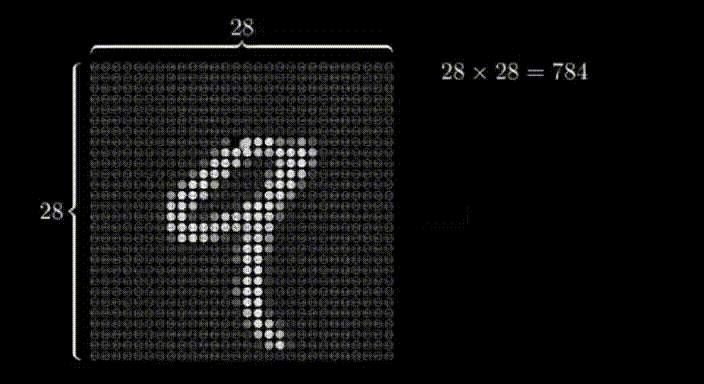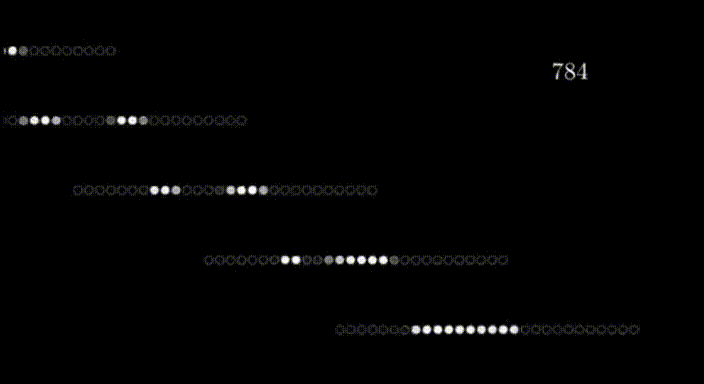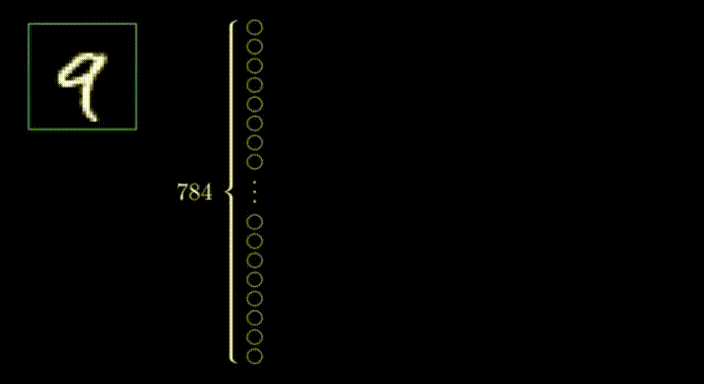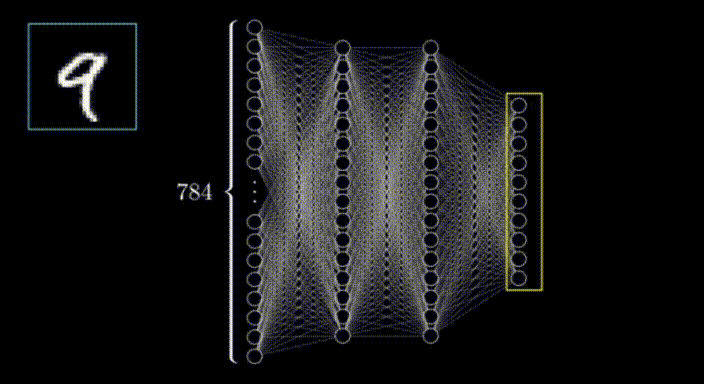
(2)输入层
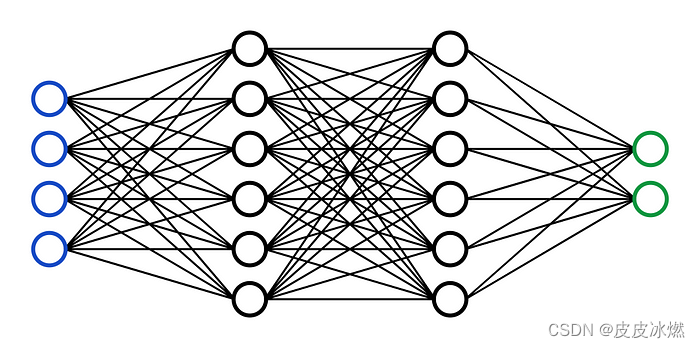
在第一层的情况下,每个神经元对应于输入图像中的一个像素,每个神经元内的值表示该像素的激活或强度。神经网络的输入层负责接收原始数据(在本例中为图像),并将其转换为可以由网络其余部分处理的格式。在这种情况下,我们有28x28个输入像素,在输入层中总共给我们784个神经元。每个神经元的激活值是0或1,取决于输入图像中相应的像素分别是黑色还是白色。
(3)输出层
在这种情况下,神经网络的输出层由10个神经元组成,每个神经元代表一个可能的输出类(在这种情况下,数字0到9)。输出层中每个神经元的输出表示输入图像属于该特定类的概率。最高概率值决定了该输入图像的预测类。
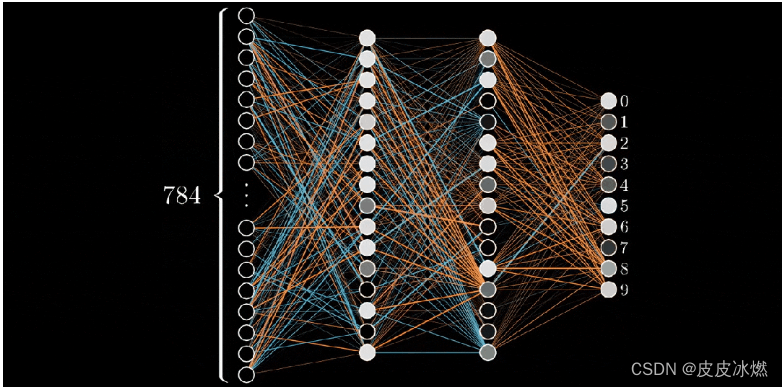
(4)隐藏层
在输入层和输出层之间,我们有一个或多个隐藏层,对输入数据执行一系列非线性变换。这些隐藏层的目的是从输入数据中提取更高层次的特征,这些特征对于手头的任务更有意义。
你想在你的网络中添加多少个隐藏层取决于你。
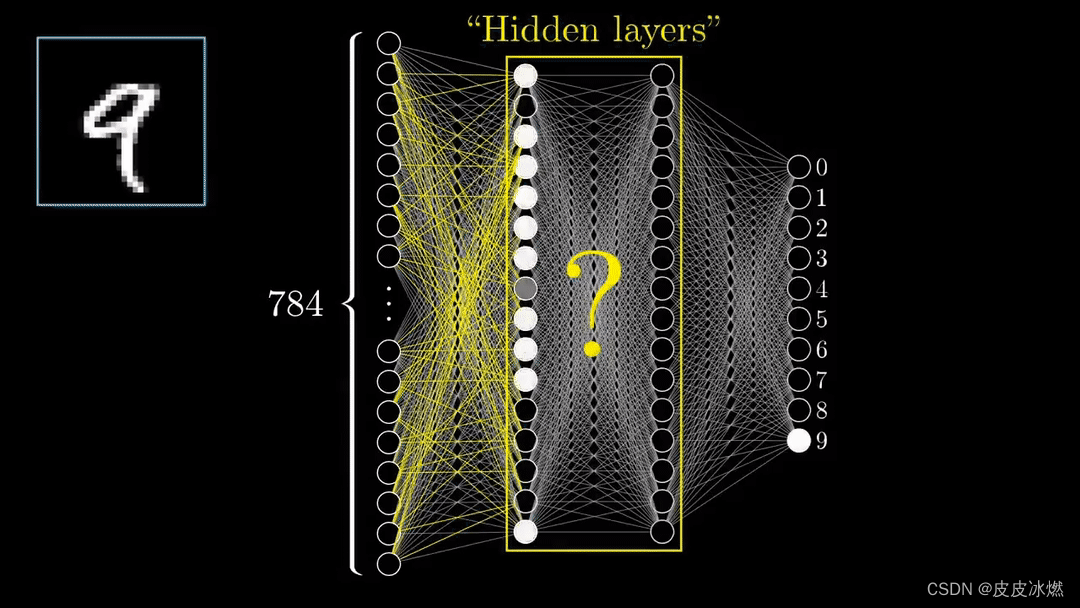
隐藏层中的每个神经元接收来自前一层所有神经元的输入,并在将这些输入传递给非线性激活函数之前,对它们应用一组权重和偏置。
这个过程在隐藏层中的所有神经元上重复,直到到达输出层。
1.3 神经网络的专业术语
一、前向传播
前向传播是通过神经网络传递输入数据以生成输出的过程。它涉及通过将权重和偏置应用于输入并将结果传递通过激活函数来计算网络每一层中每个神经元的输出。
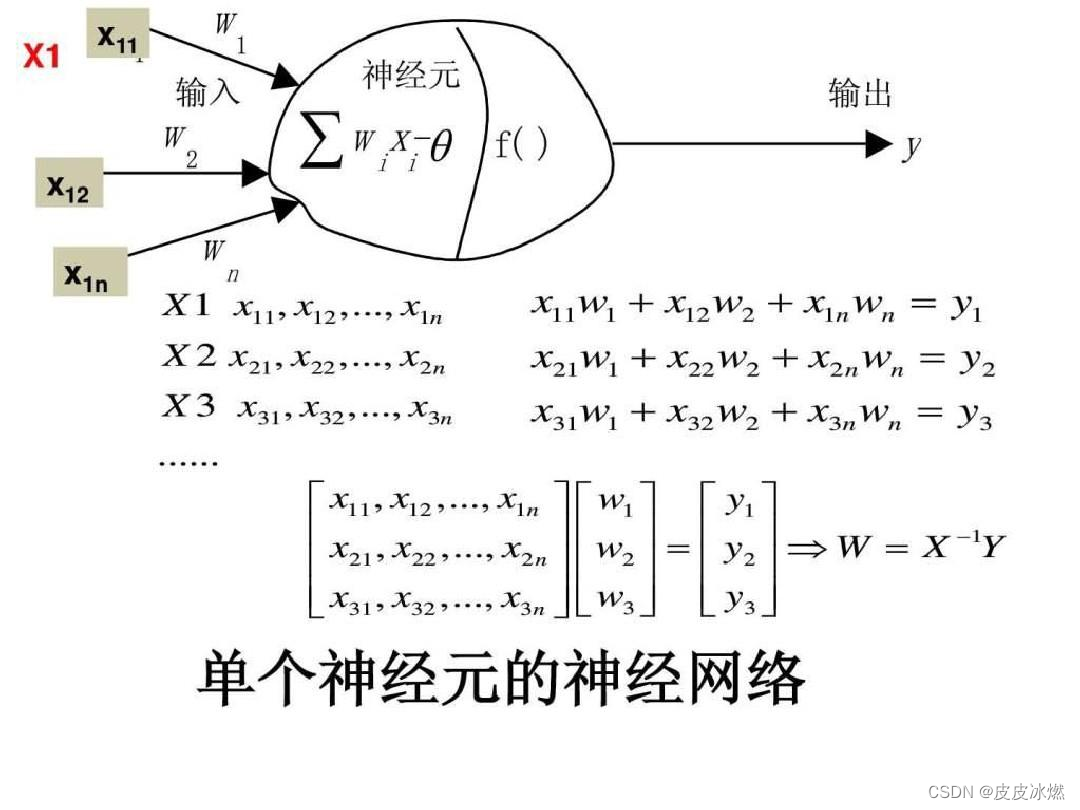
其中y是神经网络的输出,f是非线性激活函数。
二、反向传播
反向传播是一种在训练神经网络时常用的优化算法。
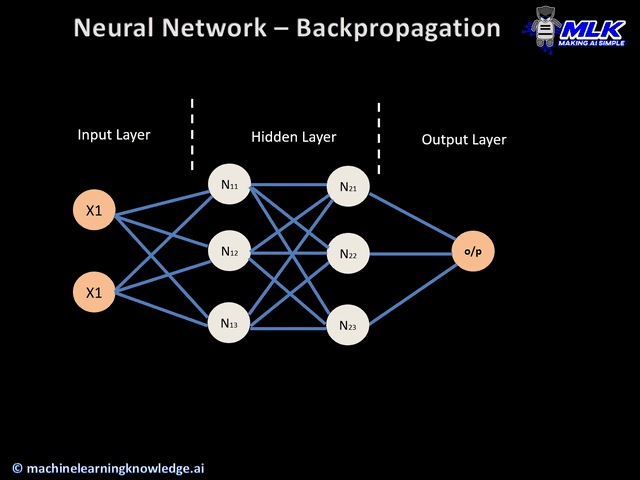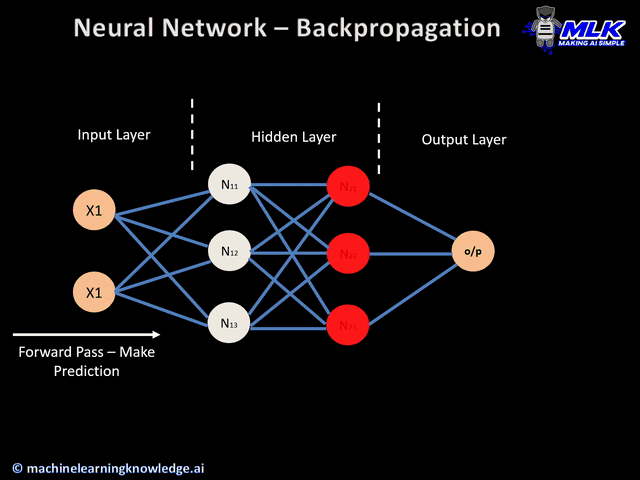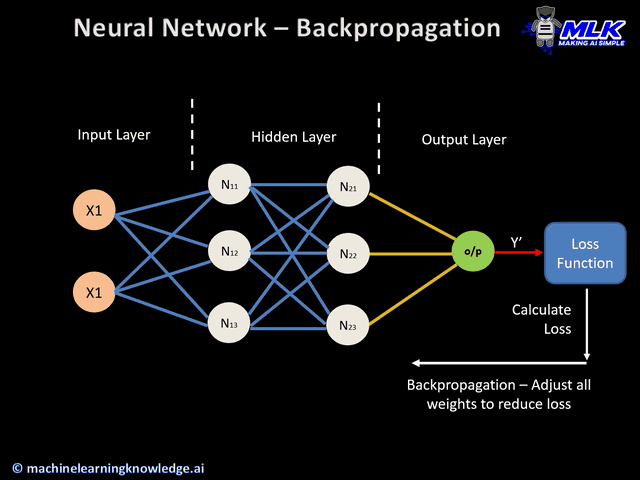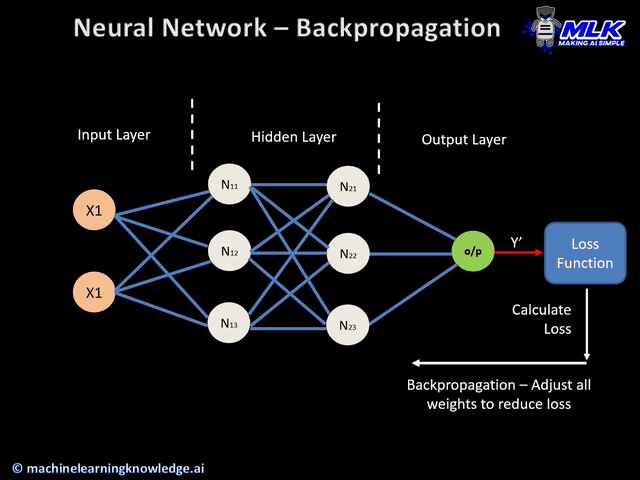
反向传播算法的工作原理就是将输出层的误差反向传播回网络各层,并利用微积分中的链式法则计算损失函数相对于每个权重的梯度。
它的核心思想是计算损失函数对网络中每个权重的梯度,然后根据这些梯度来更新权重,以最小化损失函数。通过不断地迭代这个过程,神经网络的权重可以得到调整和优化,从而提高网络的预测准确性和泛化能力。
反向传播算法在深度学习领域中非常重要,它是许多现代神经网络模型训练的基础。
三、神经网络的训练:基于输入数据和期望输出调整神经网络权值的过程,以提高网络预测的准确性。
四、权重:权重是指训练过程中学习的参数,它们决定了神经元之间连接的强度。神经元之间的每个连接都被赋予一个权重,该权重乘以神经元的输入值以确定其输出。
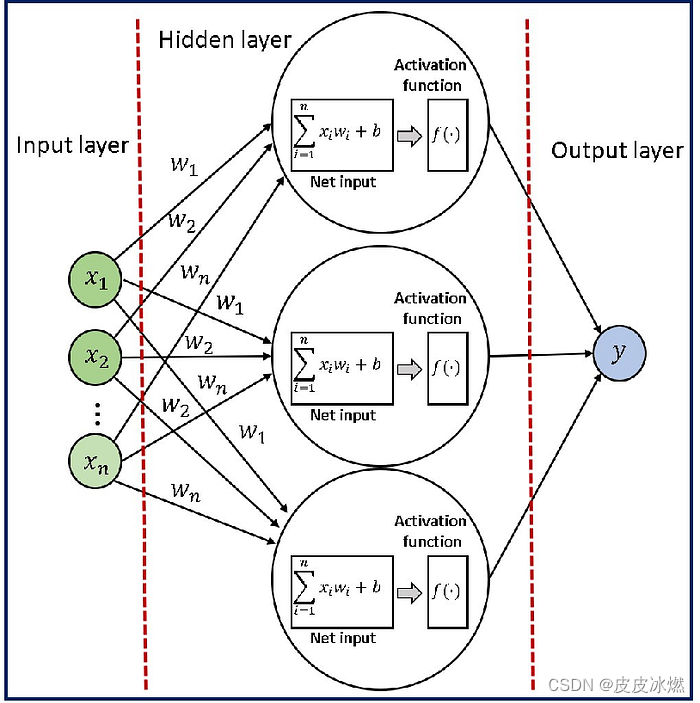
五、偏差:偏差是另一个学习参数,它被添加到给定层中神经元的输入加权和中。它是神经元的额外输入,有助于调整激活函数的输出。
六、非线性激活函数:非线性激活函数应用于神经元的输出,以将非线性引入网络。非线性很重要