Farewell to Mutual Information: Variational Distillation for Cross-Modal Person Re-Identification
摘要:
信息瓶颈 (IB) 通过在最小化冗余的同时保留与预测标签相关的所有信息,为表示学习提供了信息论原理。尽管 IB 原理已应用于广泛的应用,但它的优化仍然是一个具有挑战性的问题,严重依赖于互信息的准确估计。在本文中,我们提出了一种新的策略,变分自蒸馏 (VSD),它提供了一种可扩展、灵活和解析解,以基本上拟合互信息,但没有显式估计它。在严格的理论保证下,VSD 使 IB 能够掌握表示和标签之间的内在相关性以进行监督训练。此外,通过将VSD扩展到多视图学习,我们引入了另外两种策略,变分交叉蒸馏(VCD)和变分互学习(VML),通过消除特定于视图和与任务无关的信息,显著提高了表示对视图变化的鲁棒性。为了验证我们理论基础的策略,我们将我们的方法应用于跨模态人 Re-ID,并进行了广泛的实验,其中展示了与最先进的方法相比的优越性能。我们有趣的发现强调了重新思考估计互信息的方法的必要性。
1.引言
信息瓶颈(IB)[35]在计算机视觉[6]、语音处理[21]、神经科学[30]和自然语言处理[18]等现代机器感知系统的发展方面取得了显著进展。它本质上是一个信息论原理,将原始观察转换为通常低维的表示,该原理自然地扩展到表示学习或理解深度神经网络 (DNN) [31, 24, 9]。通过拟合互信息 (MI),IB 允许学习的表示在高维数据上保留复杂的内在相关结构,并包含与下游任务相关的信息 [35]。然而,尽管应用成功,但传统 IB 存在重大缺陷,阻碍了其进一步发展(即互信息的估计)
在本文中,我们提出了一种新的信息瓶颈策略,称为变分自蒸馏 (VSD),这使我们能够保留足够的与任务相关的信息,同时丢弃与任务无关的干扰物。我们在这里应该强调的是,我们的方法本质上拟合互信息,但没有明确估计它。为了实现这一点,我们使用变分推理来提供理论分析,该理论分析获得了 VSD 的解析解。与试图为互信息开发估计器的传统方法不同,我们的方法避免了所有复杂的设计并允许网络通过该方法保证掌握数据和标签之间的内在相关性。此外,通过将VSD扩展到多视图学习,我们提出了变分交叉蒸馏(VCD)和变分互学习(VML),这是一种提高信息瓶颈对视图变化的鲁棒性的策略。VCD 和 VML 消除了特定于视图和与任务无关的信息,而不依赖于任何强大的先验假设。更重要的是,我们以训练损失的形式实现VSD、VCD和VML,它们可以相互受益,提高了性能。因此,我们的方法保留了表示学习的两个关键特征(即充分性和一致性)。为了验证我们理论基础的策略,我们将我们的方法应用于跨模态人员再识别1,这是一种跨模态行人图像匹配任务。在广泛采用的基准数据集上进行的广泛实验表明,我们的方法对最先进的方法的有效性、鲁棒性和令人印象深刻的性能。我们的主要贡献总结如下:
• 我们为表示学习设计了一种新的信息瓶颈策略(VSD)。通过使用变分推理重建 IB 的目标,我们可以保留足够的标签信息,同时摆脱与任务无关的细节。
• 通过严格的理论分析提出了一种可扩展的、灵活和解析解来拟合互信息,从根本上解决了互信息估计的困难。
• 我们将我们的方法扩展到多视图表示学习,并通过消除特定于视图和与任务无关的信息显着提高了对视图变化的鲁棒性。
2.相关工作和预备知识
开创性的工作来自[35],它引入了IB原则。在此基础上,[1,6,27]要么重新制定训练目标,要么扩展IB原则,极大地促进了其应用。与上述所有内容相比,我们的工作是第一个提供解析解来拟合互信息而不估计它。所提出的 VSD 可以更好地保留与任务相关的信息,同时摆脱与任务无关的干扰。此外,我们将VSD扩展到多视图设置,并提出了VCD和VML,显著提高了对视图变化的鲁棒性。为了更好地说明,我们在监督学习的背景下简要回顾了 IB 原则 [35],数据观察 V 和标签 Y ,表示学习的目标是获得一个编码 Z,它对 Y 的信息量最大,由互信息衡量:(1)

为了鼓励编码过程关注标签信息,IB 通过最大化以下目标等式(2)来实现
将Ic作为从观测V到编码Z的信息流的上界。
等式 (2) 意味着压缩表示可以通过忽略原始输入中的不相关干扰项来提高泛化能力。通过使用拉格朗日目标,IB 允许编码 Z 最大程度地表达 Y,同时通过以下方式最大限度地压缩 X的表达:
![]()
其中 β 是拉格朗日乘数。然而,已经表明,由于高压缩和高互信息之间的权衡优化,不可能在等式中实现两个目标。 (3) 实际上 [6, 1]。更重要的是,在高维估计互信息给优化IB带来了额外的困难[26,2,29]。因此,它不可避免地引入了不相关的干扰因素,并在编码过程中丢弃了一些预测线索。接下来,我们展示了如何设计一种新的策略来处理这些问题,并将其扩展到多视图表示学习。
3.方法
令 v ∈ V 是从编码器 E(v|x) 中提取的输入数据 x ∈ X 的观察。优化信息瓶颈的挑战可以表述为找到一个额外的编码 E(z|v),它保留了 v 中包含的所有标签信息,同时丢弃了与任务无关的干扰项。为此,我们根据信息论展示了 z 的两个特征(即充分性和一致性)的关键作用,并设计了两个变分信息瓶颈来保持这两个特征。具体来说,我们提出了一种变分自蒸馏 (VSD) 方法,它允许信息瓶颈保持表示 z 的充分性,其中编码过程后标签信息的数量不变。在VSD的设计中,我们进一步发现它可以扩展到多视图任务,提出了基于表示一致性的变分交叉蒸馏(VCD)和变分互学习(VML)方法,这两种方法都能够消除视图变化的敏感性,提高泛化能力
更重要的是,所提出的 VSD、VCD 和 VML 可以相互受益,并且本质上拟合高维的互信息,而无需通过理论分析明确估计它。
3.1. 变分自蒸馏
信息瓶颈用于生成表示 z,以保持所有预测信息 w.r.t 标签 y,同时避免编码与任务无关的信息。它也被称为 z 对y 的充分性,定义为:
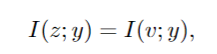 (4)
(4)
其中 v 是包含所有标签信息的观察。通过分解 v 和 z 之间的互信息,我们对公式进行分解
 (5)
(5)
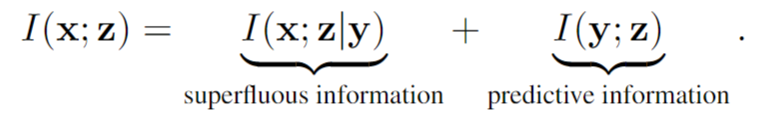
注:LEARNING ROBUST REPRESENTATIONS VIAMULTI-VIEW INFORMATION BOTTLENECK 论文中 定义1。充分性:当且仅当I(x;y|z) = 0时,x的表示z对于y就足够了。任何访问足够表示z的模型都必须能够至少准确地预测y,就好像它可以访问原始数据x一样。事实上,当且仅当有关任务的信息量因编码过程而改变时,z 对于 y 就足够了(参见附录中的命题 B.1):I(x; y|z) = 0 ⇐⇒ I(x; y) = I(y; z)。(1) 在足够的表示中,导致对未标记数据实例更好的泛化的表示特别吸引人。当 x 的信息内容高于 y 时,x 中的一些信息必须与预测任务无关。这可以通过使用互信息的链式法则将 I(x; z) 细分为两个组件来更好地理解(参见附录 A):
其中 I(z; y) 表示表示 z 中保留的标签信息量,I(v; z|y) 表示 z 中对给定任务 [6] 进行编码的不相关信息,即多余的信息。因此,z for y 的充分性被表述为最大化 I(z; y) 并同时最小化 I(v; z|y)。
等式右侧的第一项。 (6) 表明保持充分性经历了两个子过程:最大化 I(v; y) 和强制 I(z; y) 来近似 I(v; y)。在这种情况下,y 的 z 的充分性被重新制定为三个子优化:最大化 I(v; y),最小化 I(v; y)−I(z; y) 和最小化 I(v; z|y)。显然,最大化第一项 I(v; y) 与特定任务严格一致,最后两个项是等价的。因此优化简化为:
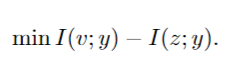
然而,在式(5)中很难进行最小-最大博弈,因为在高维估计互信息方面存在很大的困难,特别是在涉及潜在变量优化时。为了解决这个问题,我们引入了以下理论:
定理1。最小化Eq.(7)等价于最小化条件熵H(y|z)和H(y|v)的减法。
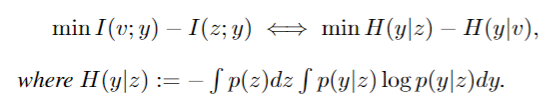
更具体地说,给定 y 的充分观察 v,我们有以下推论:
推论1。如果充分观测v的预测分布与表示z之间的kl散度等于0,那么z也足以满足y,

z for y 的充分性可以通过以下目标来实现:
![]() (8)
(8)
其中 θ, φ 分别代表编码器和信息瓶颈的参数。另一方面,基于Eq.(6)和Eq.(5),I(v;y)−I(z;y)的最小化等价于减少I(v;z|y),表明Eq.(8)也使IB能够消除不相关的干扰因素。从这个角度来看,我们的方法本质上是一种自我蒸馏方法,它净化与任务相关的知识。更重要的是,通过使用变分推理,我们重新制定了 IB 的目标,并提供了理论分析,该理论分析获得了高维互信息拟合解析解。因此,我们将策略命名为变分自蒸馏,即 VSD。讨论。与其他自蒸馏方法(如 [46])相比,我们方法的一个主要优势是 VSD 能够检索那些有用但可能丢弃的信息,同时避免了理论上保证下与任务无关的信息。与显式减少 I(v; z) 不同,我们迭代地执行 VSD 以使表示足以完成任务。理想情况下,当我们有 I(v; y) = I(z; y) 时,我们可以用最小化多余信息来实现足够的表示,即最优表示
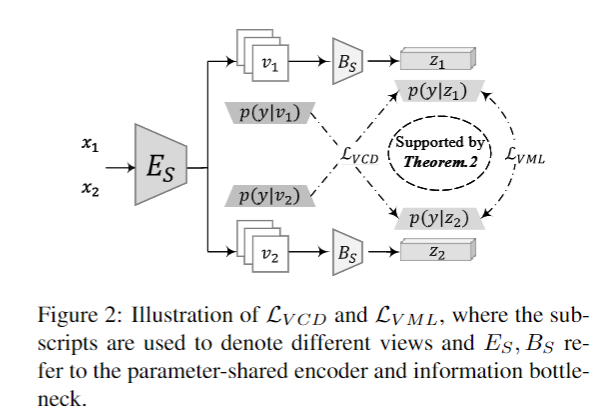
3.2.变分交叉蒸馏和变分互学习
越来越多的真实世界数据是从不同的来源收集的,或者从不同的特征提取器中获得,多视图表示学习越来越受到关注。在本节中,我们展示了 VSD 可以灵活地扩展到多视图学习。
将 v1 和 v2 视为来自不同视点的 x 的两个观察。假设 v1 和 v2 都足以标记 y,因此任何包含两个视图访问的所有信息的表示 z 也将包含必要的标签信息。更重要的是,如果 zonly 捕获从 v1 和 v2 访问的线索,它将消除特定于视图的细节,并且对视图更改具有鲁棒性 [6]。受此启发,我们将从信息瓶颈中获得的一致性 w.r.t z1, z2 定义为:

当且仅当 I(z1; y) = I(v1v2; y) = I(z2; y) z1 and z2 are view-consistent
直观地说,只有当 z1 和 z2 具有相同数量的预测信息时,它们才是视图一致的。类似于方程式。 (5),我们首先分解观察 v1 和表示 z1 之间的互信息,以清楚地揭示一致性的本质:

I(v1;z1|v2)表示z1中包含的信息对v1是唯一的,通过观察v2(即视图特定信息)无法预测(特有信息),I(z1;v2)表示z1和v2共享的信息,称为视图一致信息。为了以最小的视图特定细节获得视图一致的表示,我们需要联合最小化 I(v1; z1|v2) 并最大化 I(z1; v2)。一方面,为了减少特定于视图的信息并注意 y 是恒定的,我们可以使用以下等式来近似 I(v1; z1|v2) 的上限(证明可以在补充材料中找到)。

另一方面,通过使用链式法则将I(z1;v2)细分为两个分量[6],我们有:
等式。 (14) 意味着视图一致的信息还包括多余的信息。因此,基于上述分析,我们给出了以下定理来净化视图一致性:
定理2。给定输入x的两个不同的充分观测v1, v2,当满足以下条件时,对应的表示z1和z2是视图一致的:

其中 Pz1 = p(y|z1) 和 Pv2 = p(y|v2) 表示预测分布。基于定理 1 和推论 1,等式。 (15) 使表示 z1 能够保留预测线索,同时消除 I(z1; v2) 中包含的多余信息(z2 和 I(z2;v1) 反之亦然),称为变分交叉蒸馏。
讨论。请注意,MIB [6] 也是一种多视图信息瓶颈方法。但是,在我们的和MIB之间有三个不同
1)我们的策略本质上适合互信息,而无需通过变分推理对其进行估计。2)我们的方法不依赖于[6]中提出的强假设,即每个视图提供相同的与任务相关的信息。相反,我们探索了多个视图的互补性和一致性来进行表示学习。3) MIB 本质上是一种无监督方法,由于缺乏标签监督,它在不同视图中保持所有一致的信息。然而,通过预测信息,我们的方法能够丢弃一致表示中包含的多余信息,从而提高鲁棒性。
3.3.多模态人员Re-ID
在本节中,我们将展示如何将VSD、VCD和VML应用于多模态学习(即多模态人员ReID)。在这种情况下,来自不同模态的图像有两种(即红外图像 xI 和可见图像 xV)。多模态人员Re-ID的基本目标是匹配来自另一个模态的图像的图库中的目标人。特别是,我们使用两个配备VSD的并行模态特定分支来处理来自特定模态的图像。此外,如图3所示,部署了使用VCD和VML训练的模态共享分支来生成模态一致的表示。为了便于 Re-ID 学习,我们还在 Re-ID 社区中采用了一些常用的策略。因此总损失为:Ltrain = LReID + β · (LV SD + LV CD + LV M L)。(16) 更具体地说,LReID可以进一步划分为以下项,LReID = Lcls + Lmetric + α·LDM L,(17)其中Lcls, Lmetric, LDM L表示标签平滑[34]、度量约束[39]和深度相互学习损失[47]的分类损失。

多模态Re-ID的网络架构。EI/S/V 和 BI/S/V 分别表示编码器(ResNet-50)和信息瓶颈(多层感知器)。v 和 z 分别表示来自编码器和信息瓶颈的观察和表示