看这篇文章前的知识储备
链接: 二叉树的性质和分类
链接: 二叉检索树的概念 、insert方法的图解、实现、时间代价分析
链接: 二叉检索树的search、remove方法的图解、实现、时间代价分析
1、中序遍历及中序遍历写进文件的区别
两者思路一致,将二叉树分为三部分:左子树,根结点,右子树。对左子树,右子树递归遍历。
(1)写入数组:
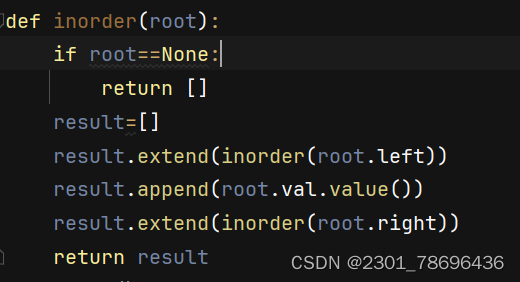
(2)写入文件
需要借助两个函数,目的:在传参时不需要手动重复传入二叉树根结点
第一个函数只需要传入输出文件名称即可(打开关闭文件,写入文件)
第二个函数具体实现写入文件
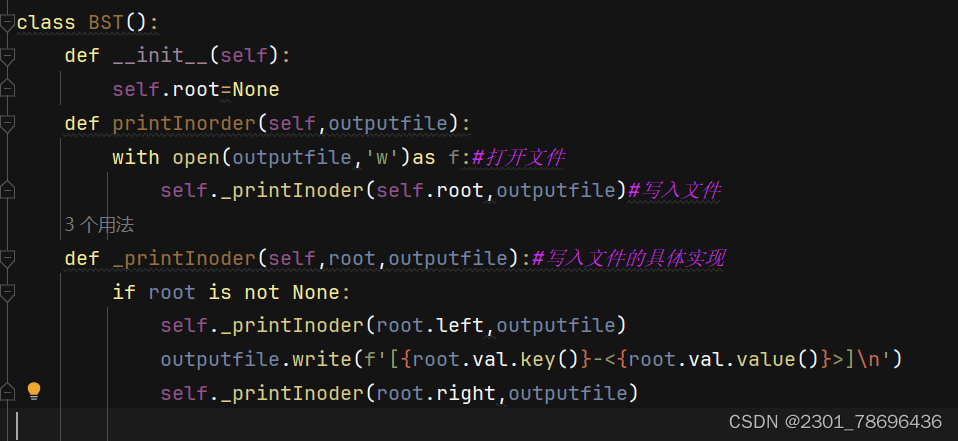

2、处理命令
为方便用户进行增删改查
将增删改查的命令符号分别定义为 + - = ?
具体实现如下

3、utf-8 和 gbk 编码的区别
UTF-8和GBK是两种不同的字符编码方式,它们之间存在一些显著的差异:
- 字符集范围
GBK编码主要用于支持中文字符和日韩字符,而UTF-8编码则支持全球范围内的字符。这意味着,如果需要处理多种语言字符,UTF-8将是一个更好的选择。 - 编码方式
GBK编码采用双字节编码,即不论中、英文字符均使用双字节来表示。而UTF-8编码则采用变长编码,一个字符的编码长度可为1~4个字节,甚至更长。这种变长编码方式使得UTF-8编码能够根据字符的实际长度来分配存储空间,因此在存储中占用的空间相对较小。 - 兼容性
GBK编码在国内应用广泛,但在国际化应用上可能受到限制。而UTF-8编码则具有更好的国际化兼容性,可以在各国各种支持UTF-8字符集的浏览器上显示,无需额外下载语言支持包。 - 存储空间大小
由于GBK编码每个字符固定占用2个字节,因此在存储中占用的空间相对较大。而UTF-8编码采用变长编码,可以根据需要分配存储空间,因此在存储中占用的空间相对较小。
综上所述,UTF-8和GBK在字符集范围、编码方式、兼容性和存储空间大小等方面存在显著差异。选择哪种编码方式取决于具体的应用场景和需求。在处理多种语言字符或需要国际化应用的场合,UTF-8编码通常更为合适;而在主要处理中文字符的场合,GBK编码可能更为常用。
(1)注意
在读取写入文件时,最好表明编码方式,防止出现UnicodeDecodeError错误
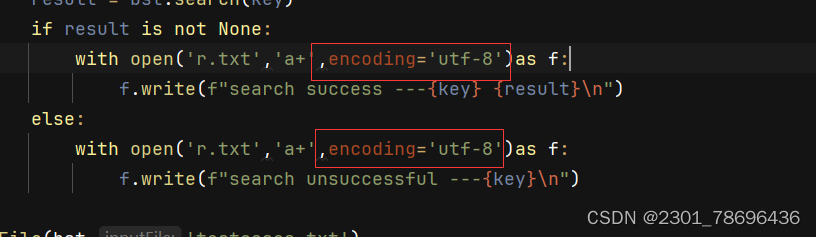
(2)判断文件的编码类型
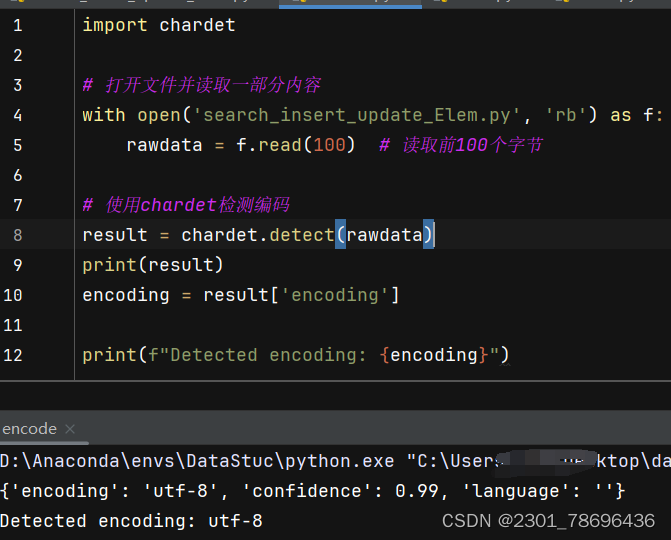
import chardet
# 打开文件并读取一部分内容
with open('name of your file', 'rb') as f:
rawdata = f.read(100) # 读取前100个字节
# 使用chardet检测编码
result = chardet.detect(rawdata)
print(result)
encoding = result['encoding']
print(f"Detected encoding: {encoding}")
4、全部代码理解
(1)前期准备——Elem()、BinNode()

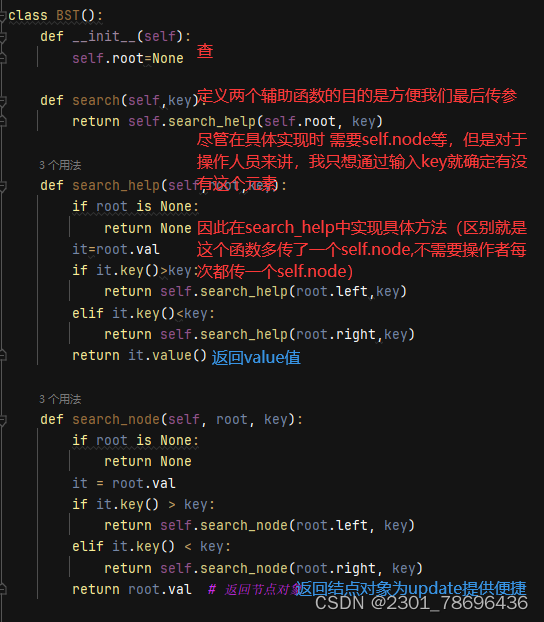
(2)查——search
(3)改——update

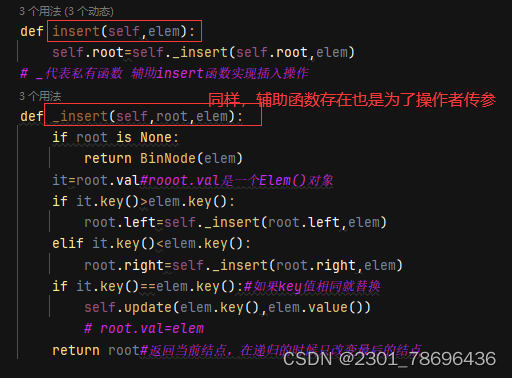
(4)增——insert
(5)删——remove

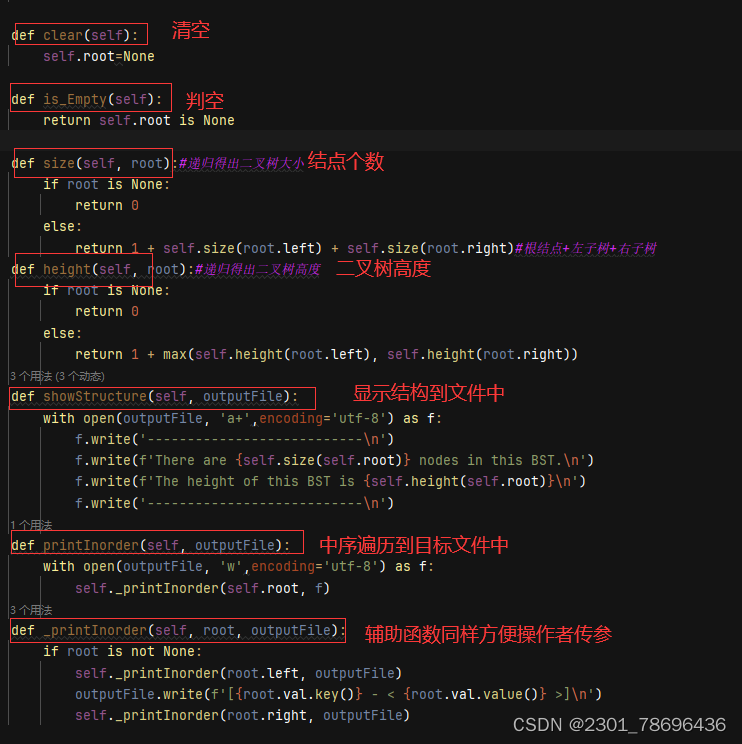
(6)其他方法
(7)读取命令

(8)具体命令处理
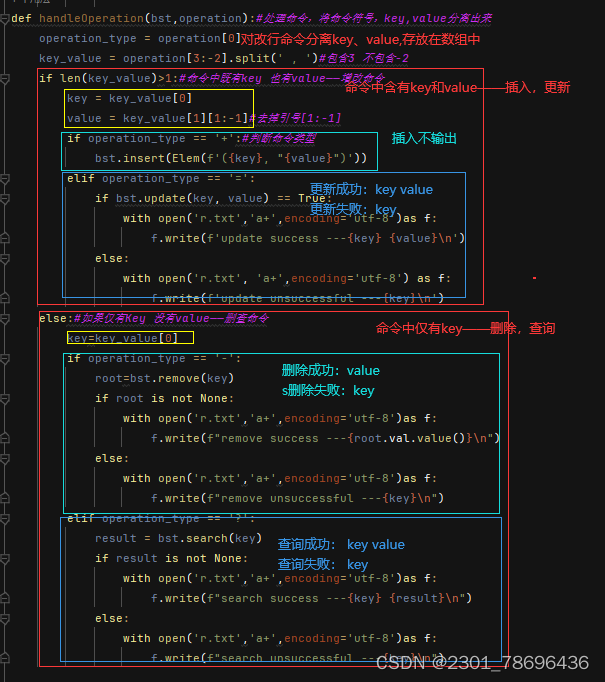
(8)实例

(9)结果
命令文件(部分)
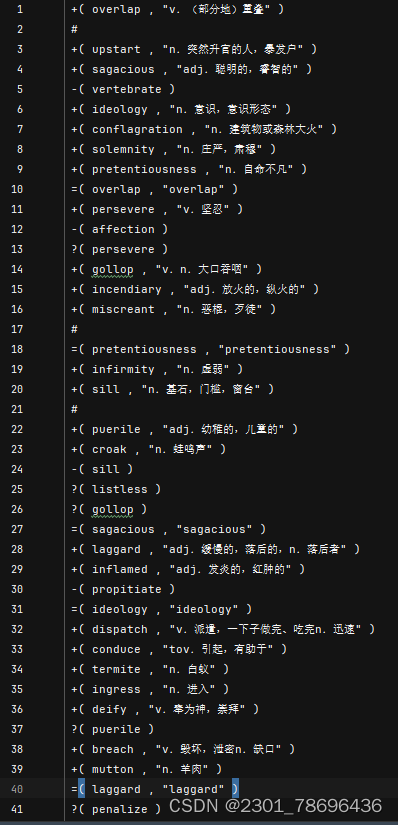
运行结果(部分)
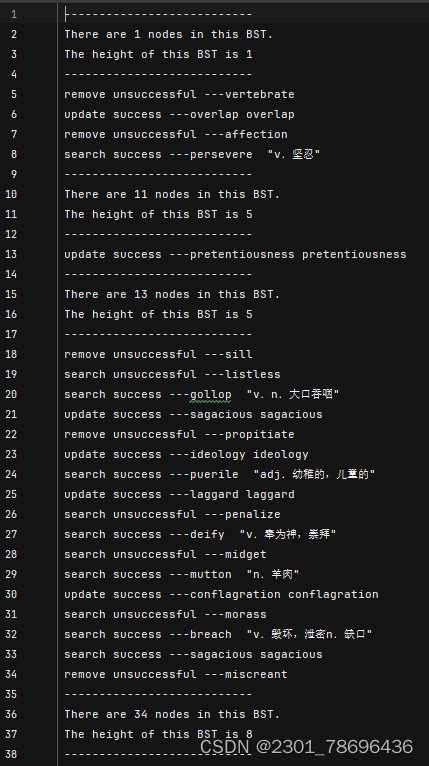
5、全部代码
class Elem():
def __init__(self,val):
if val is not None:#把要插入的元素提取出来
self._key = val[1:-1].strip().split(',')[0]
self._value= val[1:-1].strip().split(',')[1]
else:
self._key=None
def key(self):#获取key()
return self._key
def value(self):
return self._value
def set_key(self, key):
self._key = key
def set_value(self, value):
self._value = value
class BinNode:
def __init__(self, val):
self.left = None
self.right = None
self.val = val
class BST():
def __init__(self):
self.root=None
def search(self,key):
return self.search_help(self.root, key)
def search_help(self,root,key):
if root is None:
return None
it=root.val
if it.key()>key:
return self.search_help(root.left,key)
elif it.key()<key:
return self.search_help(root.right,key)
return it.value()
def search_node(self, root, key):
if root is None:
return None
it = root.val
if it.key() > key:
return self.search_node(root.left, key)
elif it.key() < key:
return self.search_node(root.right, key)
return root.val # 返回节点对象
def update(self, key, value):
node = self.search_node(self.root, key)
if node is not None:
node.set_value(value)
return True
else:
return False
def insert(self,elem):
self.root=self._insert(self.root,elem)
# _代表私有函数 辅助insert函数实现插入操作
def _insert(self,root,elem):
if root is None:
return BinNode(elem)
it=root.val#rooot.val是一个Elem()对象
if it.key()>elem.key():
root.left=self._insert(root.left,elem)
elif it.key()<elem.key():
root.right=self._insert(root.right,elem)
if it.key()==elem.key():#如果key值相同就替换
self.update(elem.key(),elem.value())
# root.val=elem
return root#返回当前结点,在递归的时候只改变最后的结点
def getmin(self,root):
if root.left is None:
return root.val
else:
return self.getmin(root.left)
def del_min(self,root):
if root.left is None:
root=root.right
else:
root.left=self.del_min(root.left)
return root
def remove(self,key):
self.remove_help(self.root,key)
def remove_help(self,root,key):
if root is None:
return None
it=root.val
#先找到要删除的元素,思想类似于del_min(),路径中结点不会改变子结点指针值
if it.key()>key:
root.left=self.remove_help(root.left,key)
elif it.key()<key:#要规范代码写法
root.right=self.remove_help(root.right,key)
#找到该元素,判断该结点类型(叶子、一分支、(叶子的判断可以包含在一分支判断中)二分支)
else:
if root.left is None:
root=root.right
elif root.right is None:
root=root.left
else:#两个分支
temp=self.getmin(root)#获取最小元素
root.val=temp#替换
self.del_min(root.right)#删除最小元素(del_min返回root)
return root
def clear(self):
self.root=None
def is_Empty(self):
return self.root is None
def size(self, root):#递归得出二叉树大小
if root is None:
return 0
else:
return 1 + self.size(root.left) + self.size(root.right)#根结点+左子树+右子树
def height(self, root):#递归得出二叉树高度
if root is None:
return 0
else:
return 1 + max(self.height(root.left), self.height(root.right))
def showStructure(self, outputFile):
with open(outputFile, 'a+',encoding='utf-8') as f:
f.write('---------------------------\n')
f.write(f'There are {self.size(self.root)} nodes in this BST.\n')
f.write(f'The height of this BST is {self.height(self.root)}\n')
f.write('---------------------------\n')
def printInorder(self, outputFile):
with open(outputFile, 'w',encoding='utf-8') as f:
self._printInorder(self.root, f)
def _printInorder(self, root, outputFile):
if root is not None:
self._printInorder(root.left, outputFile)
outputFile.write(f'[{root.val.key()} - < {root.val.value()} >]\n')
self._printInorder(root.right, outputFile)
bst=BST()
def readInputFile(bst,inputFile):#把命令文件读进来并将相应命令结果输出到文件中
with open(inputFile, 'r',encoding='utf-8') as f:
for line in f:
if line.startswith('+( ') or line.startswith('=( ') or line.startswith('-( ') or line.startswith('?( ') :
handleOperation(bst,line.strip())
if line.startswith('#'):
bst.showStructure('r.txt')
def handleOperation(bst,operation):#处理命令,将命令符号,key,value分离出来
operation_type = operation[0]
key_value = operation[3:-2].split(' , ')#包含3 不包含-2
if len(key_value)>1:#命令中既有key 也有value——增改命令
key = key_value[0]
value = key_value[1][1:-1]#去掉引号[1:-1]
if operation_type == '+':#判断命令类型
bst.insert(Elem(f'({key}, "{value}")'))
elif operation_type == '=':
if bst.update(key, value) == True:
with open('r.txt','a+',encoding='utf-8')as f:
f.write(f'update success ---{key} {value}\n')
else:
with open('r.txt', 'a+',encoding='utf-8') as f:
f.write(f'update unsuccessful ---{key}\n')
else:#如果仅有Key 没有value——删查命令
key=key_value[0]
if operation_type == '-':
root=bst.remove(key)
if root is not None:
with open('r.txt','a+',encoding='utf-8')as f:
f.write(f"remove success ---{root.val.value()}\n")
else:
with open('r.txt','a+',encoding='utf-8')as f:
f.write(f"remove unsuccessful ---{key}\n")
elif operation_type == '?':
result = bst.search(key)
if result is not None:
with open('r.txt','a+',encoding='utf-8')as f:
f.write(f"search success ---{key} {result}\n")
else:
with open('r.txt','a+',encoding='utf-8')as f:
f.write(f"search unsuccessful ---{key}\n")
readInputFile(bst,'testcases.txt')
bst.printInorder('bstInorder.txt')