NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections(野外的 NERF: 用于无约束照片采集的神经辐射场)
Abstract
我们提出了一种基于学习的方法来合成新的视图的复杂场景使用只有非结构化的收集野生照片。我们建立在神经辐射场(neRF)的基础上,它使用多层感知机的权重来模拟场景的密度和颜色作为三维坐标的函数。虽然 NERF 能够很好地处理在受控环境下捕捉到的静态图像,但是它无法在不受控的图像中建模许多普遍存在的、真实的现象,例如可变光照或瞬态遮挡。我们引入了一系列的扩展,以解决这些问题,从而能够从互联网上采集的非结构化图像进行精确的重建。我们应用我们的系统,称为 NeRF-W,互联网照片收集的著名地标,并证明了时间一致的新颖视图渲染显着更接近于照片现实主义比先前的先进技术来说。
4. NeRF in the Wild
现在,我们介绍一个从野外照片集中重建3D 场景的系统 NeRF-W。我们建立在 NeRF的基础上,并引入了两个明确设计用于处理无约束图像的挑战的增强。
类似于 NeRF,我们从已知相机参数的非结构化照片集合
中学习体积密度表示 Fθ。NERF 在其输入视图中假定了一致性: 在三维空间中,从同一位置和两幅不同图像的观察方向观察到的一个点具有相同的亮度。但是由于两种截然不同的现象,互联网照片(如图2所示)违背了这一假设:
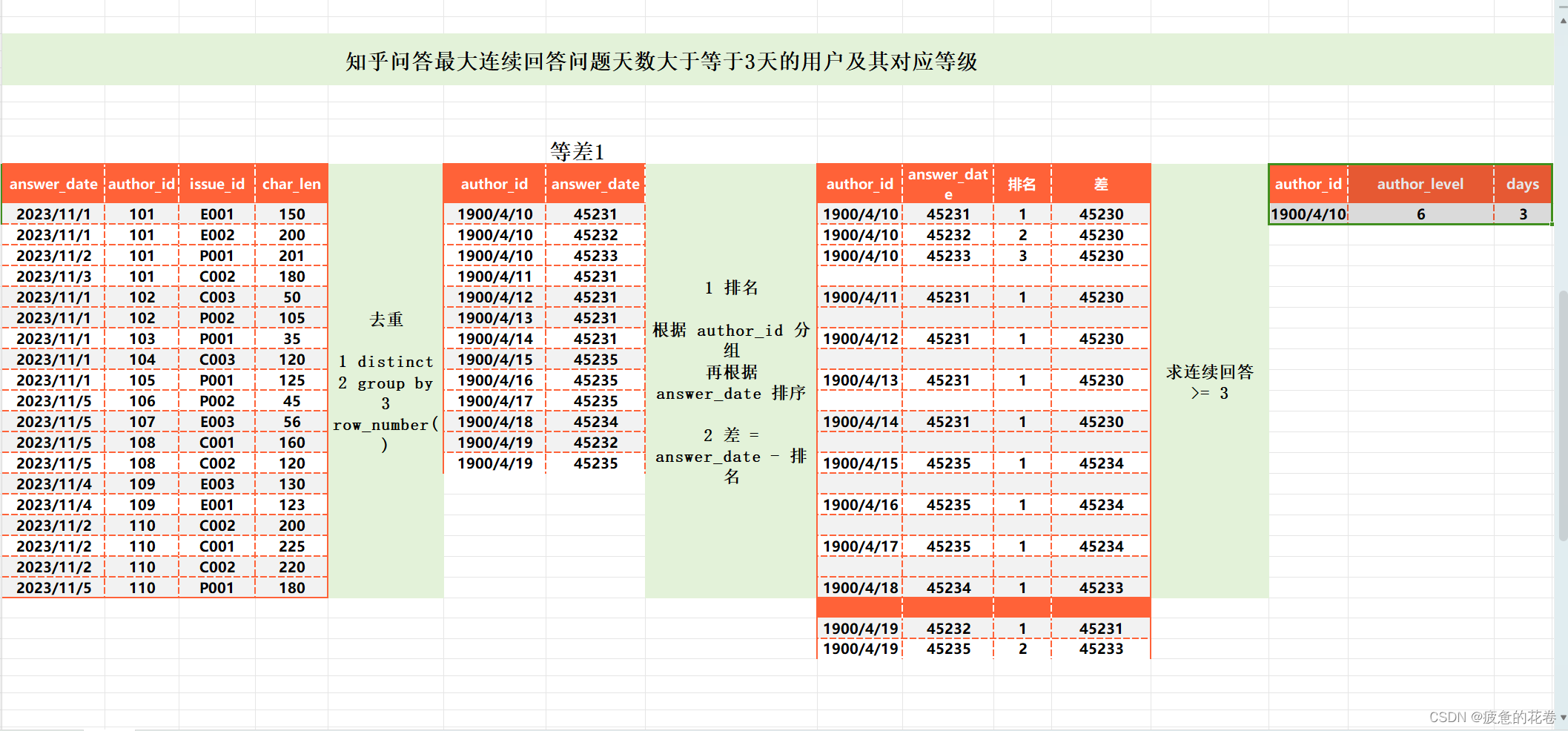
图2:用于训练 NeRF-W 的来自摄影旅游数据集的野外照片示例[13]。由于可变光照和后期处理(顶部) ,同一物体的颜色可能会因图像而异。野外拍摄的照片也可能包含暂时闭塞的主题(底部)。
1) Photometric variation:
在户外摄影中,一天的时间和大气条件直接影响场景中物体的照度(因此,辐射)。由于自动曝光设置、白平衡和跨照片色调映射的变化可能导致额外的光度不一致,因此摄影成像管道加剧了这个问题
2) Transient objects:
真实世界的地标很少被孤立地捕捉没有移动的物体或遮挡物围绕着它们。地标性建筑的旅游照片尤其具有挑战性,因为它们通常包含人物和其他行人的造型。
我们提出了两个模型组件来解决这些问题。在第4.1节中,我们扩展了 NeRF,允许图像相关的外观和照度变化,如图像之间的光度差异可以明确建模。在第4.2节中,我们进一步扩展了这个模型,允许对瞬态对象进行联合估计,并从三维世界的静态表示中解脱出来。图3显示了所提议的模型体系结构的概述。
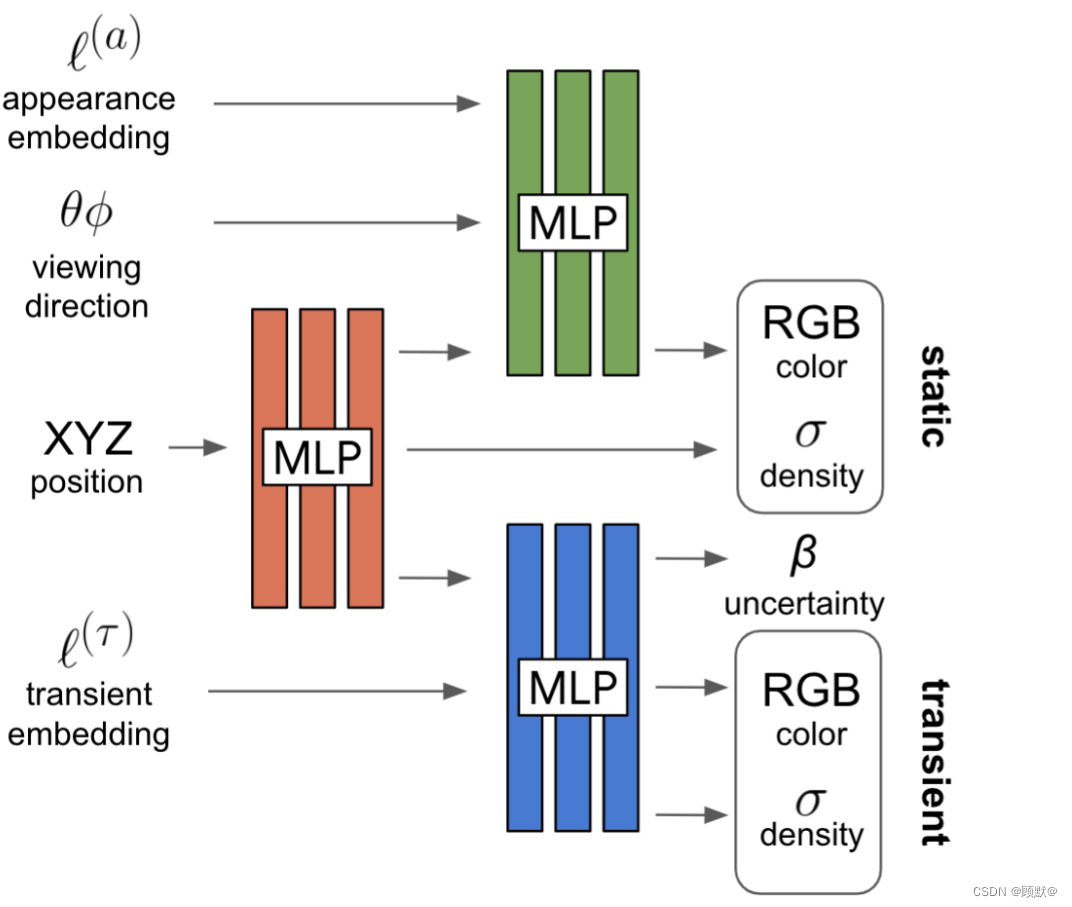
图3: NeRF-W 模型架构。给定一个3D 位置,观察方向,学习外观和瞬态嵌入,NeRF-W 产生静态和瞬态颜色和密度以及测量不确定性。请注意,静态不透明度是在模型以外观嵌入为条件之前生成的,以确保所有图像共享静态几何图形。
4.1. Latent Appearance Modeling(潜在外观建模)
为了适应 NERF 对可变光照和光度后处理的要求,我们采用了生成潜在优化(Generative Latent Optimization (GLO))的方法,给每个图像 Ii赋予一个相应的长度为 n ^(a)的实值外观嵌入向量 Li ^(a) 。我们将方程(1)中与图像无关的辐射度 c (t)替换为与图像有关的辐射度 ci (t) ,这也将对图像索引 i 的依赖性引入到近似像素颜色 ci帽:
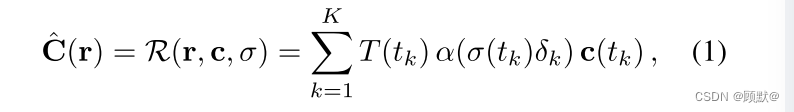
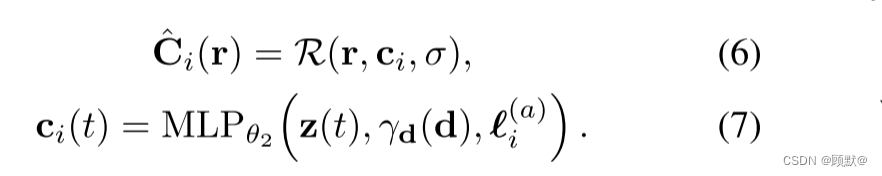

使用这些外观嵌入作为输入到只发射颜色的网络分支,在一个特定的图像中给我们的模型自由改变场景发射辐射,同时仍然保证3D 几何(由 MLPθ1早期预测)是静态的和共享的所有图像。通过将 n ^(a)设置为一个小值,我们鼓励优化来确定一个连续的空间,其中可以嵌入照明条件,从而使条件之间的平滑插值,如图8所示。
图8: 两个训练图像(左,右)的外观嵌入 l ^(a)之间的插值,导致渲染(中) ,其中颜色和照明被插值,但几何是固定的。注意,训练图像包含渲染中没有出现的人(左)和灯(右)。
4.2. Transient Objects
我们使用两个不同的设计决策来处理瞬态现象: 首先,我们指定在 NeRF 中使用的color-emitting MLP (方程(4))作为我们模型的“静态”头,
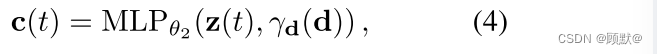
并且我们添加一个额外的“瞬态”头,发射自己的颜色和密度,其中密度允许在不同的训练图像中变化。这使得 NeRF-W 能够重建包含遮挡物的图像,而无需在静态场景表示中引入伪影。其次,我们不假设所有观察到的像素颜色都是同样可靠的,而是允许我们的瞬态头部发射一个不确定场(很像我们现有的颜色和密度场) ,这使得我们的模型能够适应其重建损失,以忽略可能包含遮挡物的不可靠的像素和3D 位置。我们将每个像素的颜色建模为一个各向同性的正态分布,我们将最大化这种正态分布的可能性,并使用与 NeRF 相同的立体渲染方法“渲染”这种分布的方差。这两个模型组件允许 NeRF-W 在没有显式监督的情况下分离静态和瞬态现象。
为了构造我们的瞬态头部,我们在方程(6)的立体渲染公式的基础上,用瞬态对应物 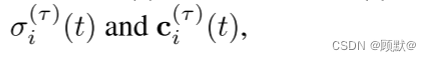
增加静态密度 σ (t)和辐射率 ci (t) ,
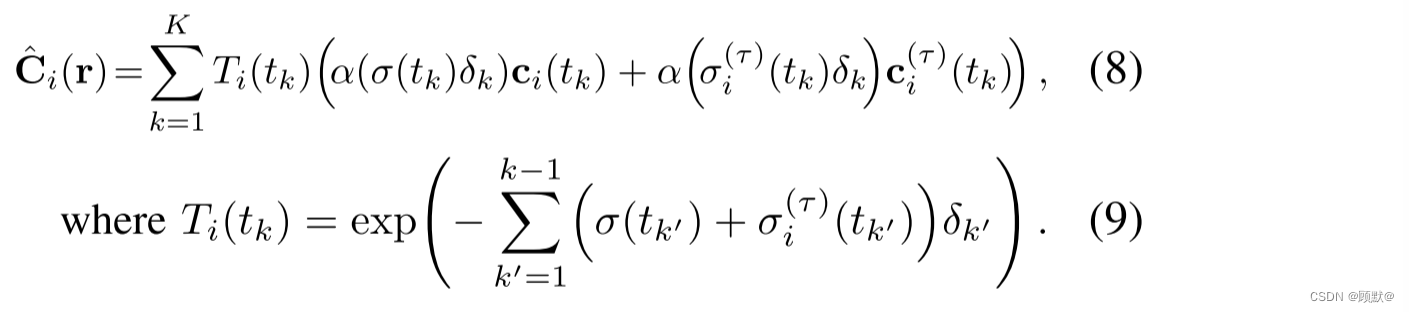
然后,r (t)的预期颜色成为静态和瞬态分量的 alpha 组合。
我们使用Kendall等人的贝叶斯学习框架来模拟观察到的颜色的不确定性。我们假设观测到的像素强度是固有的噪声(任意的) ,并且进一步假设这种噪声是与输入相关的(异方差的)。
注:各向同性正向分布(isotropic normal distribution)
为了允许场景的瞬态分量在图像之间变化,我们给每个训练图像 Ii 分配一个第二次嵌入的 li ^(τ) ∈ R ^n ^(τ)作为瞬态 MLP 的输入,
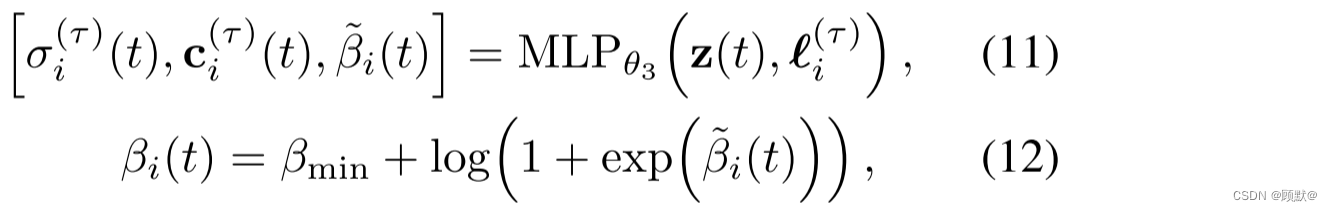
对于 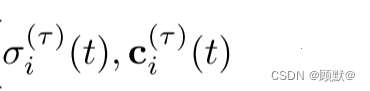
使用 ReLU 和sigmoid,并且使用软加作为 βi (t)的激活(通过 βmin > 0移位,确保将最小重要性分配给每条射线的超参数)。有关我们完整的模型体系结构的说明,请参见图3。真彩色Ci®在图像 i 中的光线r损失为: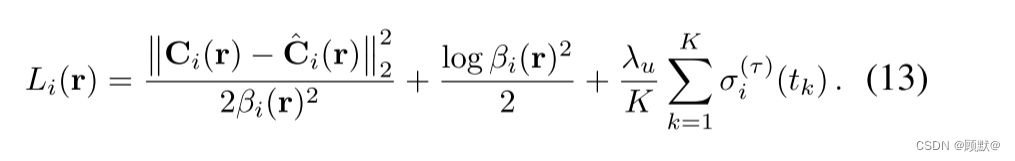
前两项是基于正态分布的(位移)对数亏损概率,其均值为® ,方差为 βi ®2。较大的 βi ®值减弱了分配给像素的重要性,假设它属于某个瞬态对象。第一项被第二项平衡,它对应于正态分布的对数配分函数,排除了 βi ® = ∞的平凡极小值。第三项是 L1正则化子,其乘子 λu 在(非负)瞬态密度 σ (τ) i (t)上,这阻碍了模型用瞬态密度来解释静态现象。
在测试时,我们省略了瞬态和不确定度场,只渲染 σ (t)和 c (t)。有关静态、瞬态和不确定性组件的说明,请参见图4
图4: NeRF-W 分别呈现场景的静态(a)和瞬态(b)元素,然后组合它们©。训练最小化合成图像和真实图像(d)之间的差异,不确定性(e)加权,这是同时优化识别和折扣异常图像区域。
6. Conclusion
我们提出了 NeRF-W,一种基于 NeRF 的非结构化互联网照片集的复杂环境三维场景重建的新方法。我们学习每个图像的潜在嵌入捕获光度外观变化通常存在于野外数据,我们分解场景到图像依赖和共享组件,使我们的模型从静态场景分离瞬态元素。对真实世界(和合成)数据的实验评估表明,与以前的最先进的方法相比,定性和定量方面都有显著的改进。