一、DataStream API
1、概述
1)Flink程序剖析
1.Flink程序组成
a)Flink程序基本组成
- 获取一个
执行环境(execution environment); - 加载/创建初始数据;
- 指定数据相关的转换;
- 指定计算结果的存储位置;
- 触发程序执行。
b)创建执行环境
getExecutionEnvironment();
createLocalEnvironment();
createRemoteEnvironment(String host, int port, String... jarFiles);
通常,只使用 getExecutionEnvironment() 即可,该方法会根据上下文做正确的处理:
- 如果在 IDE 中执行程序或将其作为一般的 Java 程序执行,那么它将创建一个本地环境,该环境将在本地机器上执行程序。
- 如果基于程序创建了一个 JAR 文件,并通过命令行运行它,Flink 集群管理器将执行程序的 main 方法,同时 getExecutionEnvironment() 方法会返回一个执行环境以在集群上执行程序。
c)指定数据源
执行环境提供了一些方法,支持使用各种方法从文件中读取数据:可以直接逐行读取数据,像读 CSV 文件一样,或使用任何第三方提供的 source,将一个文本文件作为一个行的序列来读取:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("file:///path/to/file");
d)应用转换
指定 data sources 将生成一个 DataStream,可以在上面应用转换(transformation)来创建新的派生 DataStream,可以调用 DataStream 上具有转换功能的方法来应用转换,使用 map 的转换:
DataStream<String> input = ...;
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
e)指定数据汇
通过创建 sink 把包含最终结果的 DataStream 写到外部系统。
writeAsText(String path);
print();
f)触发程序执行
需要调用 StreamExecutionEnvironment 的 execute() 方法来触发程序执行,根据 ExecutionEnvironment 的类型,执行会在本地机器上触发,或将程序提交到某个集群上执行。
execute()方法将等待作业完成,然后返回一个JobExecutionResult,其中包含执行时间和累加器结果。
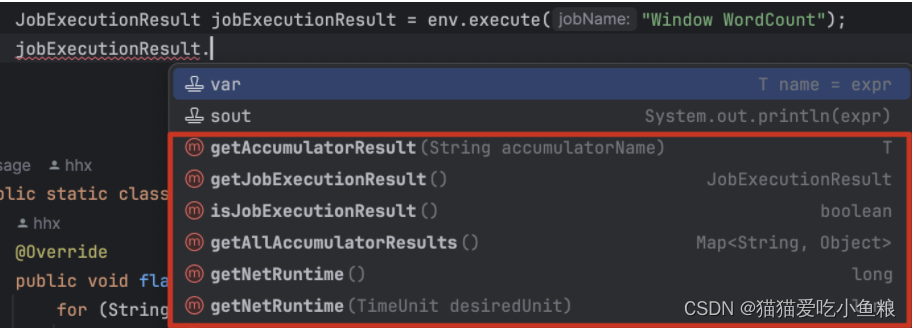
- 如果不想等待作业完成,可以通过调用
StreamExecutionEnvironment的executeAsync()方法来触发作业异步执行,它会返回一个JobClient,可以通过它与刚刚提交的作业进行通信。
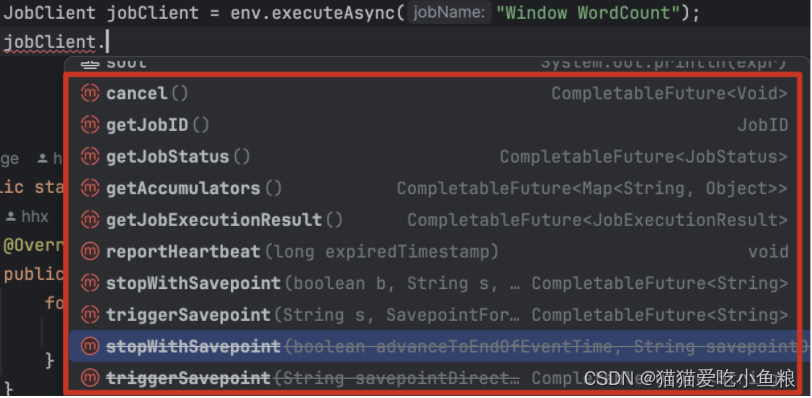
如下是使用 executeAsync() 实现 execute() 语义的示例。
final JobClient jobClient = env.executeAsync();
final JobExecutionResult jobExecutionResult = jobClient.getJobExecutionResult().get();
g)注意
所有 Flink 程序都是延迟执行的:
- 当程序的 main 方法被执行时,数据加载和转换不会直接发生,而是每个算子都被创建并添加到 dataflow 形成的有向图中;
- 当被执行环境的
execute()方法显示地触发时,这些算子才会真正执行。
2.Data Sources
Source 用于程序获取数据,可以用 StreamExecutionEnvironment.addSource(sourceFunction) 将一个 source 关联到程序中。
Flink 自带了许多预先实现的 source functions,也可以实现 SourceFunction 接口编写自定义的非并行 source,也可以实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 类编写自定义的并行 sources。
通过 StreamExecutionEnvironment 可以访问预定义的 stream source:
基于文件:
-
readTextFile(path)- 读取文本文件,例如遵守 TextInputFormat 规范的文件,逐行读取并将它们作为字符串返回。 -
readFile(fileInputFormat, path)- 按照指定的文件输入格式读取(一次)文件。 -
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)- 这是前两个方法内部调用的方法,它基于给定的fileInputFormat读取路径path上的文件,根据提供的watchType的不同,source 可以定期(每interval毫秒)监控路径上的新数据(watchType 为FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次当前路径中的数据然后退出(watchType 为FileProcessingMode.PROCESS_ONCE),使用pathFilter,可以过滤正在处理的文件。实现:
在底层,Flink 将文件读取过程拆分为两个子任务,即 目录监控 和 数据读取。
每个子任务都由一个单独的实体实现,监控由单个非并行(并行度 = 1)任务实现,而读取由多个并行运行的任务执行,读取任务的并行度和作业的并行度相等。
单个监控任务的作用是扫描目录(定期或仅扫描一次,取决于
watchType),找到要处理的文件,将它们划分为 分片,并将这些分片分配给下游 reader。Reader 是将实际获取数据的角色,每个分片只能被一个 reader 读取,而一个 reader 可以一个一个地读取多个分片。
重要提示:
- 如果
watchType设置为FileProcessingMode.PROCESS_CONTINUOUSLY,当一个文件被修改时,它的内容会被完全重新处理,这可能会打破 “精确一次” 的语义,因为在文件末尾追加数据将导致重新处理文件的所有内容。 - 如果
watchType设置为FileProcessingMode.PROCESS_ONCE,source 扫描一次路径然后退出,无需等待 reader 读完文件内容,reader 会继续读取数据,直到所有文件内容都读完,关闭 source 会导致在那之后不再有检查点,这可能会导致节点故障后恢复速度变慢,因为作业将从最后一个检查点恢复读取。
- 如果
基于套接字:
socketTextStream- 从套接字读取,元素可以由分隔符分隔。
基于集合:
fromCollection(Collection)- 从 Java Java.util.Collection 创建数据流,集合中的所有元素必须属于同一类型。fromCollection(Iterator, Class)- 从迭代器创建数据流,class 参数指定迭代器返回元素的数据类型。fromElements(T ...)- 从给定的对象序列中创建数据流,所有的对象必须属于同一类型。fromParallelCollection(SplittableIterator, Class)- 从迭代器并行创建数据流,class参数指定迭代器返回元素的数据类型。fromSequence(from, to)- 基于给定间隔内的数字序列并行生成数据流。
自定义:
addSource- 关联一个新的 source function,可以使用addSource(new FlinkKafkaConsumer<>(...))从 Apache Kafka 获取数据,更多参考 DataStream Connectors。
3.DataStream Transformations
参考算子。
4.Data Sinks
Data sinks 使用 DataStream 并将它们转发到文件、套接字、外部系统或打印它们。
Flink 自带了多种内置的输出格式,这些格式相关的实现封装在 DataStreams 的算子里:
writeAsText()/TextOutputFormat- 将元素按行写成字符串,通过调用每个元素的 toString() 方法获得字符串。writeAsCsv(...)/CsvOutputFormat- 将元组写成逗号分隔的文件,行和字段的分隔符是可配置的,每个字段的值来自对象的 toString() 方法。print()/printToErr()- 在标准输出/标准错误流上打印每个元素的 toString() 值,可以提供一个前缀(msg)附加到输出,有助于区分不同的 print 调用,如果并行度大于1,输出结果将附带输出任务标识符的前缀。writeUsingOutputFormat()/FileOutputFormat- 自定义文件输出的方法和基类,支持自定义 object 到 byte 的转换。writeToSocket- 根据SerializationSchema将元素写入套接字。addSink- 调用自定义 sink function,Flink 捆绑了连接到其它系统(例如 Apache Kafka)的连接器,这些连接器被实现为 sink functions。
注意:
DataStream 的 write*() 方法主要用于调试,不参与 Flink 的 checkpointing,通常这些函数具有至少有一次语义,刷新到目标系统的数据取决于 OutputFormat 的实现,并非所有发送到 OutputFormat 的元素都会立即显示在目标系统中;此外,在失败的情况下,这些记录可能会丢失。
为了将流可靠地、精准一次地传输到文件系统中,请使用 FileSink;通过 .addSink(...) 方法调用的自定义实现也可以参与 Flink 的 checkpointing,以实现精准一次的语义。
5.执行参数
StreamExecutionEnvironment 包含了 ExecutionConfig,它允许在运行时设置作业特定的配置值。
参数的说明可参考执行配置,这些参数特别适用于 DataStream API:
setAutoWatermarkInterval(long milliseconds):设置自动发送 watermark 的时间间隔,可以使用long getAutoWatermarkInterval()获取当前配置值。
a)容错
State & Checkpointing 描述了如何启用和配置 Flink 的 checkpointing 机制。
b)控制延迟
默认情况下,元素不会在网络上一一传输(这会导致不必要的网络传输),而是被缓冲。
缓冲区的大小(实际在机器之间传输)可以在 Flink 配置文件中设置,虽然此方法有利于优化吞吐量,但当输入流不够快时,它可能会导致延迟问题。
要控制吞吐量和延迟,可以调用执行环境(或单个算子)的 env.setBufferTimeout(timeoutMillis) 方法来设置缓冲区填满的最长等待时间,超过此时间后,即使缓冲区没有未满,也会被自动发送,超时时间的默认值为 100 毫秒。
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setBufferTimeout(timeoutMillis);
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
为了最大限度地提高吞吐量,设置 setBufferTimeout(-1) 来删除超时,这样缓冲区仅在已满时才会被刷新。
要最小化延迟,请将超时设置为接近 0 的值(例如 5 或 10 毫秒)应避免超时为 0 的缓冲区,因为它会导致严重的性能下降。
6.调试
a)本地执行环境
LocalStreamEnvironment 在创建它的同一个 JVM 进程中启动 Flink 系统,如果从 IDE 启动 LocalEnvironment,则可以在代码中设置断点并轻松调试程序。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
DataStream<String> lines = env.addSource(/* some source */);
// 构建你的程序
env.execute();
b)集合 Data Sources
Flink 提供了由 Java 集合支持的特殊 data sources 以简化测试。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 从元素列表创建一个 DataStream
DataStream<Integer> myInts = env.fromElements(1, 2, 3, 4, 5);
// 从任何 Java 集合创建一个 DataStream
List<Tuple2<String, Integer>> data = ...
DataStream<Tuple2<String, Integer>> myTuples = env.fromCollection(data);
// 从迭代器创建一个 DataStream
Iterator<Long> longIt = ...
DataStream<Long> myLongs = env.fromCollection(longIt, Long.class);
注意: 集合 data source 要求数据类型和迭代器实现 Serializable,且集合 data sources 不能并行执行(parallelism = 1)。
c)迭代器 Data Sink
Flink 还提供了一个 sink 来收集 DataStream 的结果。
DataStream<Tuple2<String, Integer>> myResult = ...
Iterator<Tuple2<String, Integer>> myOutput = myResult.collectAsync();
注意:在程序完成时或者CheckPoint触发时才会输出结果。
7.总结
1.DataStream 的 write*() 方法不参与 Flink 的 checkpointing,具有至少一次语义,可以通过 FileSink 或 .addSink(...) 方法调用的自定义实现,参与 Flink 的 checkpointing,具有精准一次语义,实现将流可靠地、精准一次地传输到文件系统中;
2.通过配置 BufferTimeout 控制缓冲区刷出的延迟,通过配置 ExecutionConfig 控制执行参数;
3.通过调用 env.executeAsync() 返回的 jobClient 实现对 Flink Job 的控制(可用于在 Java 中控制 Flink 任务);
4.readFile()方法,在底层 Flink 将文件读取过程拆分为两个子任务,即 目录监控 和 数据读取;监控由单个非并行(并行度 = 1)任务实现,而读取由多并行任务执行,读取任务的并行度和作业的并行度相等;单个监控任务的作用是扫描目录(定期或仅扫描一次,取决于watchType),找到要处理的文件,将它们划分为分片,并将这些分片分配给下游 reader;Reader 是将获取数据的角色,每个分片只能被一个 reader 读取,而一个 reader 可以一个一个地读取多个分片。