kafka部分partition的leader=-1修复方案整理
- 1. 背景说明
- 2. 修复测试
- 2.1 创建正常的topic并验证生产和消费
- 2.2 停止kafka模拟leader=-1
- 2.3 修复parition
- 2.4 修复完成验证生产消费是否恢复
- 3. 疑问和思考
- 3.1 kafka在进行数据消费时,如果有partition的leader=-1,进行数据生产和消费时,kafka是否会自动剔除对应的parition?
- 4. 参考文档
1. 背景说明
部分环境发现,支撑kafka部分topic的被设置成单副本。当出现单机故障时,部分topic-partition出现leader=-1,对应的partition无法正常读写数据。特别是kafka内置的topic __consumer_offsets,__consumer_offsets 是记录topic的消费组数据消费的相关信息,如果出现了该问题,就会导致部分topic的消费组无法正常进行数据消费。
本文记录在工作中遇到的一次修复经历,并进行整理
2. 修复测试
2.1 创建正常的topic并验证生产和消费
- 获取kafka的配置zk链接信息,以及leader=-1的topic-partition、和每个kafka的id
# 获取kafka的id
cd /usr/local/services/kafka_2.11-1.1.1
cat config/server.properties |grep broker.id

# 获取kafka的zk地址
cd /usr/local/services/kafka_2.11-1.1.1
cat config/server.properties |grep zookeeper

- 创建一个单parition,4副本的topic,便于后续测试
# 创建topic
./bin/kafka-topics.sh --create --zookeeper $zk --topic test5 --replication-factor 4 --partitions 1

- 验证topic的读写情况
# 控制台1,创建数据消费者
./bin/kafka-console-consumer.sh --topic test5 --group test5 --bootstrap-server localhost:9092 --from-beginning
# 控制台2,创建数据生产者
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test5

2.2 停止kafka模拟leader=-1
- 停止部分kafka节点,使得__consumer_offsets的partition:41为-1(正好记录test5的数据消费信息)
# 停止相关kafka节点的计划任务
crontab -e
# 停止相关kafka进程
ps -ef|grep kafka
kill -9
# 获取zk信息
# 检查集群的topic信息
cd /usr/local/services/kafka_2.11-1.1.1
zk=xx.xx.xx.xx:2181/kafka
bin/kafka-topics.sh --zookeeper $zk --describe|grep __consumer_offsets
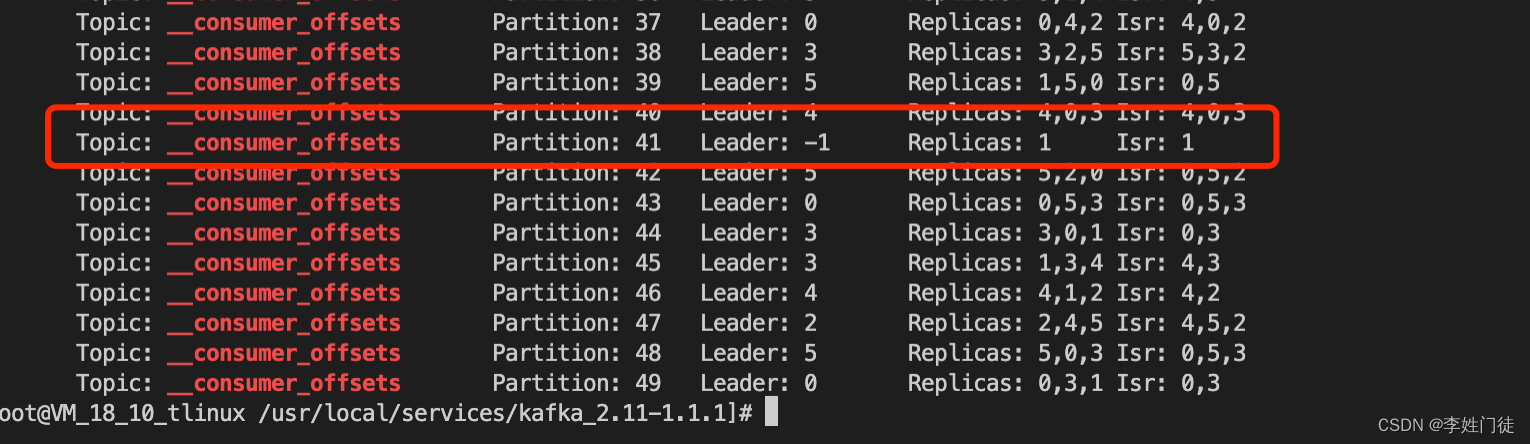
- 继续测试test5的数据生产和消费,此时test5无法消费数据

2.3 修复parition
- 由于__consumer_offsets的partition:41(test5的消费记录保存在该paritition中)单副本,并且对应的节点已经宕机,因此不能通过调整副本的方式进行修复。需要调整zk中的元数据,重新给__consumer_offsets的partition:41配置isr和leader,让它恢复正常
# 获取zk信息
cd /usr/local/services/kafka_2.11-1.1.1
zk=xx.xx.xx.xx:2181/kafka
# 登录zk节点,并进入zk
cd /data/zookeeper-3.4.14/bin
./zkCli.sh
# 获取__consumer_offsets的partition:41的配置信息
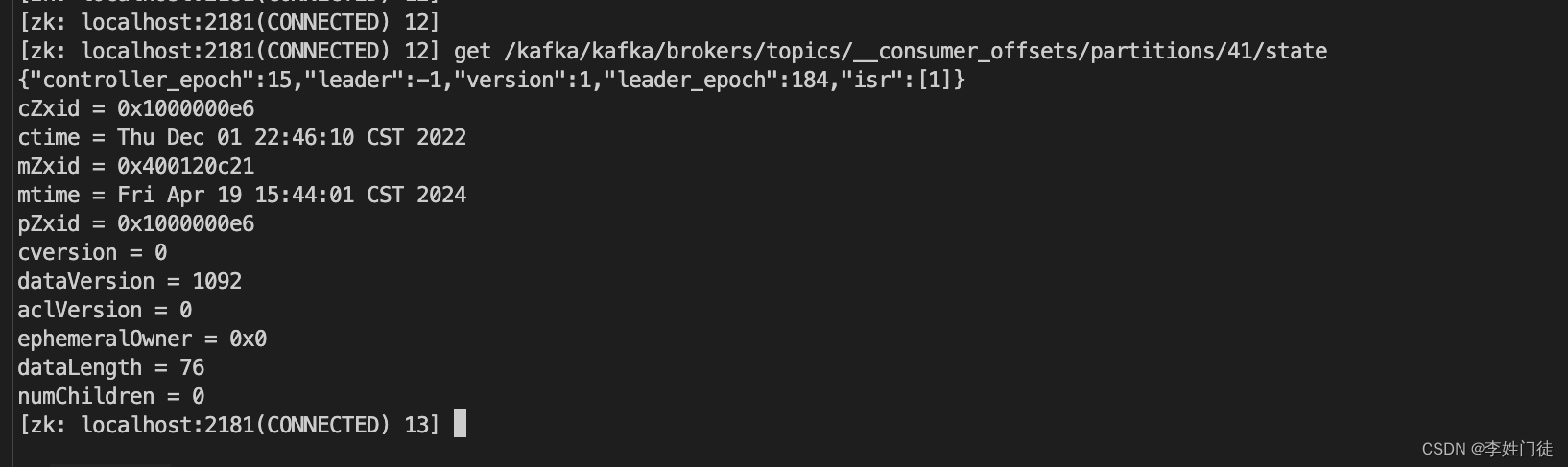
get /kafka/brokers/topics/__consumer_offsets/partitions/41/state
# 调整__consumer_offsets的partition:41的配置信息,选择0作为leader
set /kafka/brokers/topics/__consumer_offsets/partitions/41/state {"controller_epoch":15,"leader":0,"version":1,"leader_epoch":177,"isr":[0]}
get /kafka/brokers/topics/__consumer_offsets/partitions/41/state
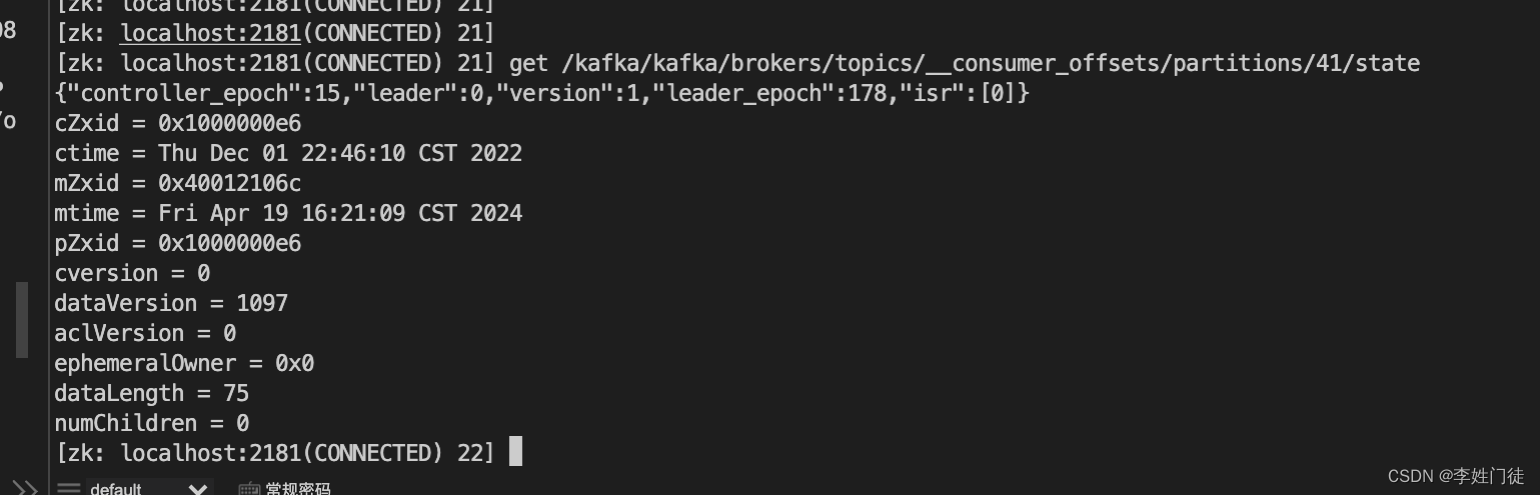
# 登录0号kafka节点,进一步调整replica信息,调整为0
cd /usr/local/services/kafka_2.11-1.1.1
vim replication-factor.json
{"version":1,"partitions":[{"topic":"__consumer_offsets","partition":41,"replicas":[0],"log_dirs":["any"]}]}
# 执行调整命令
./bin/kafka-reassign-partitions.sh --zookeeper $zk --reassignment-json-file replication-factor.json --execute
# 查看调整进度
./bin/kafka-reassign-partitions.sh --zookeeper $zk --reassignment-json-file replication-factor.json --verify
说明调整完成,此时应该是leader:0 ,replica: [0], isr: [0]
# 获取zk信息
# 检查集群的topic信息
cd /usr/local/services/kafka_2.11-1.1.1
zk=xx.xx.xx.xx:2181/kafka
bin/kafka-topics.sh --zookeeper $zk --describe|grep __consumer_offsets
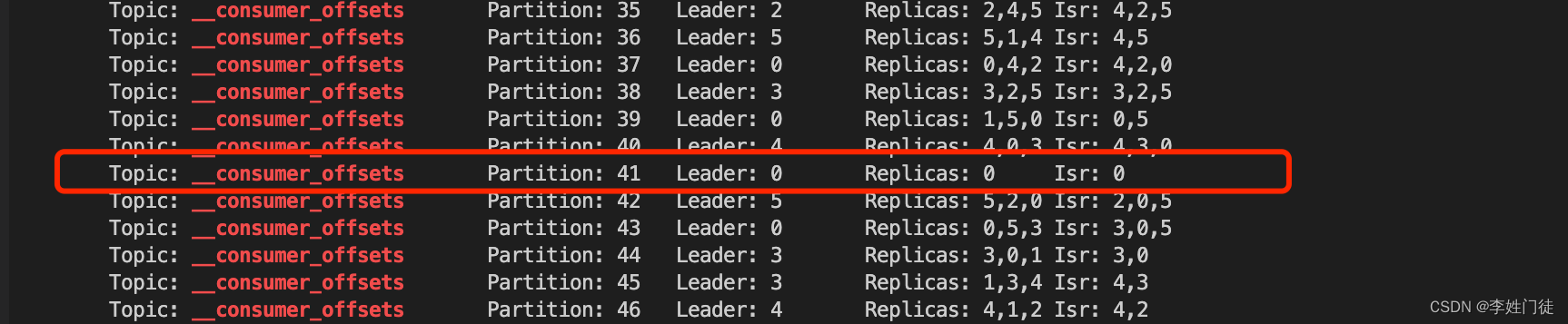
2.4 修复完成验证生产消费是否恢复
- 继续验证topic的生产和消费,已经恢复正常
# 控制台1,创建数据消费者
./bin/kafka-console-consumer.sh --topic test5 --group test5 --bootstrap-server localhost:9092 --from-beginning
# 控制台2,创建数据生产者
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test5

3. 疑问和思考
3.1 kafka在进行数据消费时,如果有partition的leader=-1,进行数据生产和消费时,kafka是否会自动剔除对应的parition?
不会。
在这里将kafka的topic-parition设置成2种类型。
- 业务topic,业务数据进行生产和消费
- 内置topic __consumer_offsets,记录业务topic的消费的offset信息
两者逻辑相同。
数据进行生产时,会通过的方式 hash(key) / partition数量(也可以指定partition)到对应的partition, 消费者跟对应的paritition对应才能保证数据在paritition内有序。
如果kakfa在进行hash时需要考虑partition的leader=-1的情况,对应的hash规则会发生调整,对应的数据消费端也需要进行调整,整体的影响较大,因此kafka没有进行这样的考虑。而是要求在创建topic时能够进行要求多副本,并且通过监控运维等手段及时发现leader=-1的partition,并及时修复。
4. 参考文档
暂无