目录
- 一、多表关系
- 1.1 一对多
- 1.2 外键约束
- 1.3 一对一
- 1.4 多对多
- 二、多表查询
- 2.1 测试数据准备
- 2.2 笛卡尔积
- 2.3 内连接
- 2.4 外连接
- 2.5 子查询
- 1.标量子查询
- 2.列子查询
- 3.行子查询
- 4.表子查询
- 三、事务
- 3.1 问题场景引入
- 3.2 概念
- 3.3 事务操作
- 3.4 事务的四大特性ACID
- 四、索引
- 4.1 概念
- 4.2 优缺点
- 4.3 MySQL的索引结构-B+树
- 4.4 索引操作
一、多表关系
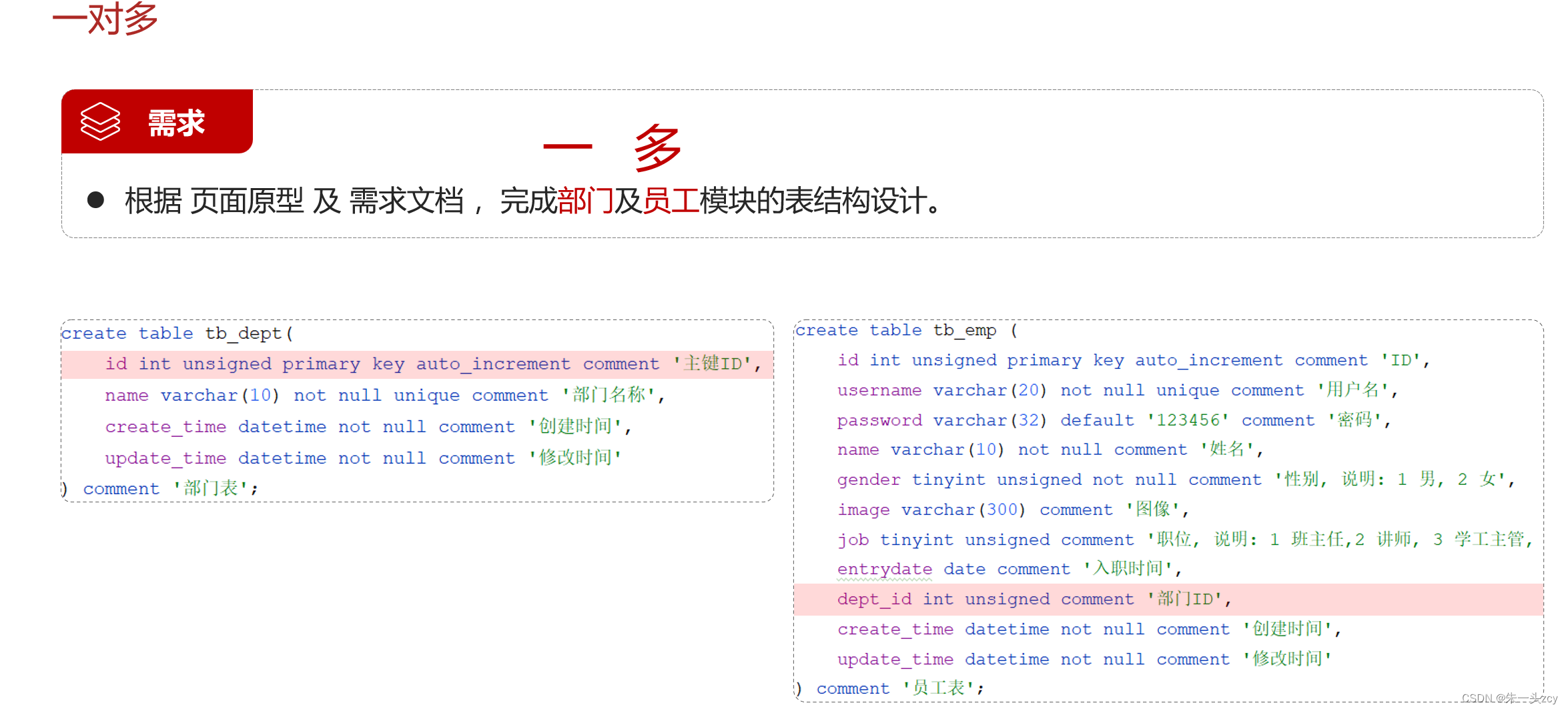
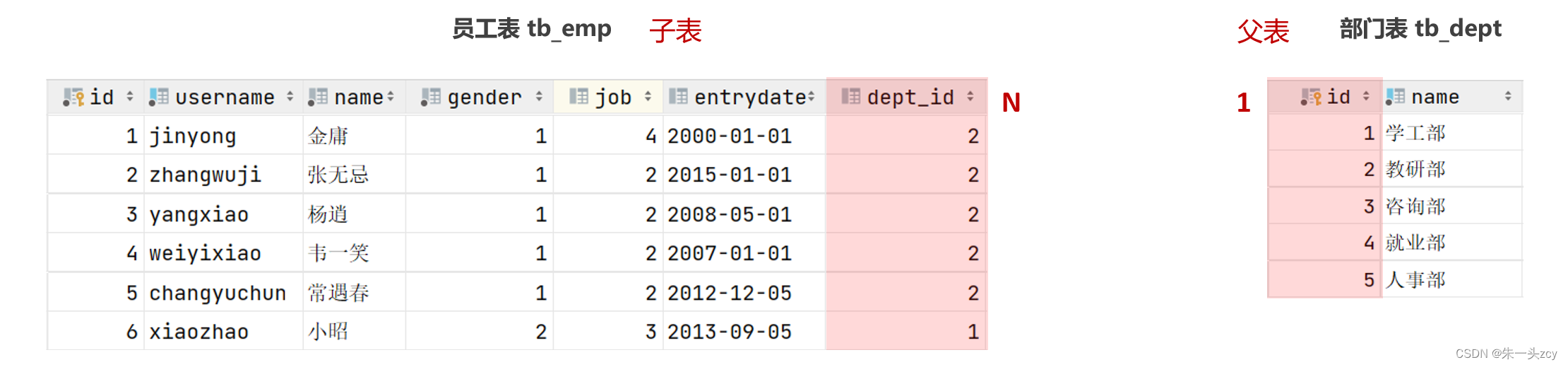
1.1 一对多
-
一个部门,对应多个员工; 一个员工,只能归属一个部门
-

1.2 外键约束
- 1.1 只是在逻辑上知道员工和部门多对一的关系,但是数据库层面并没有进行关联
- 插入测试数据,假如把部门表ID为1的记录直接删除,员工表不会受到任何影响,但此时员工表已经出现数据不一致不完整的问题了,还有部分员工仍归属于被删掉的部门下
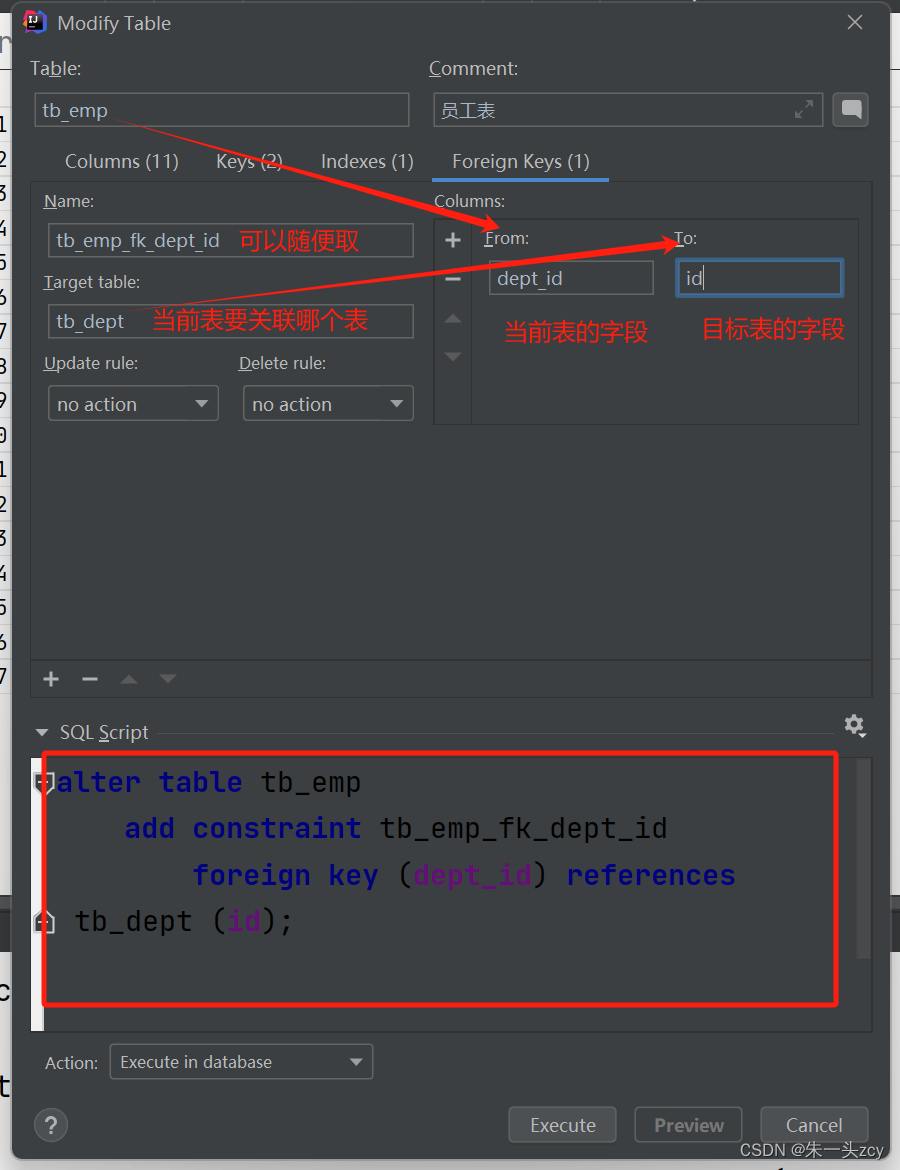
- 外键约束用于解决多表之间数据的一致性和完整性问题
- 设置外键关联之后,1部门就删不了了,5部门还是能删,因为没有员工属于5部门

alter table tb_emp
add constraint tb_emp_fk_dept_id
foreign key (dept_id) references tb_dept (id);
删除外键:
alter table tb_emp drop foreign key tb_emp_fk_dept_id;
物理外键与逻辑外键:

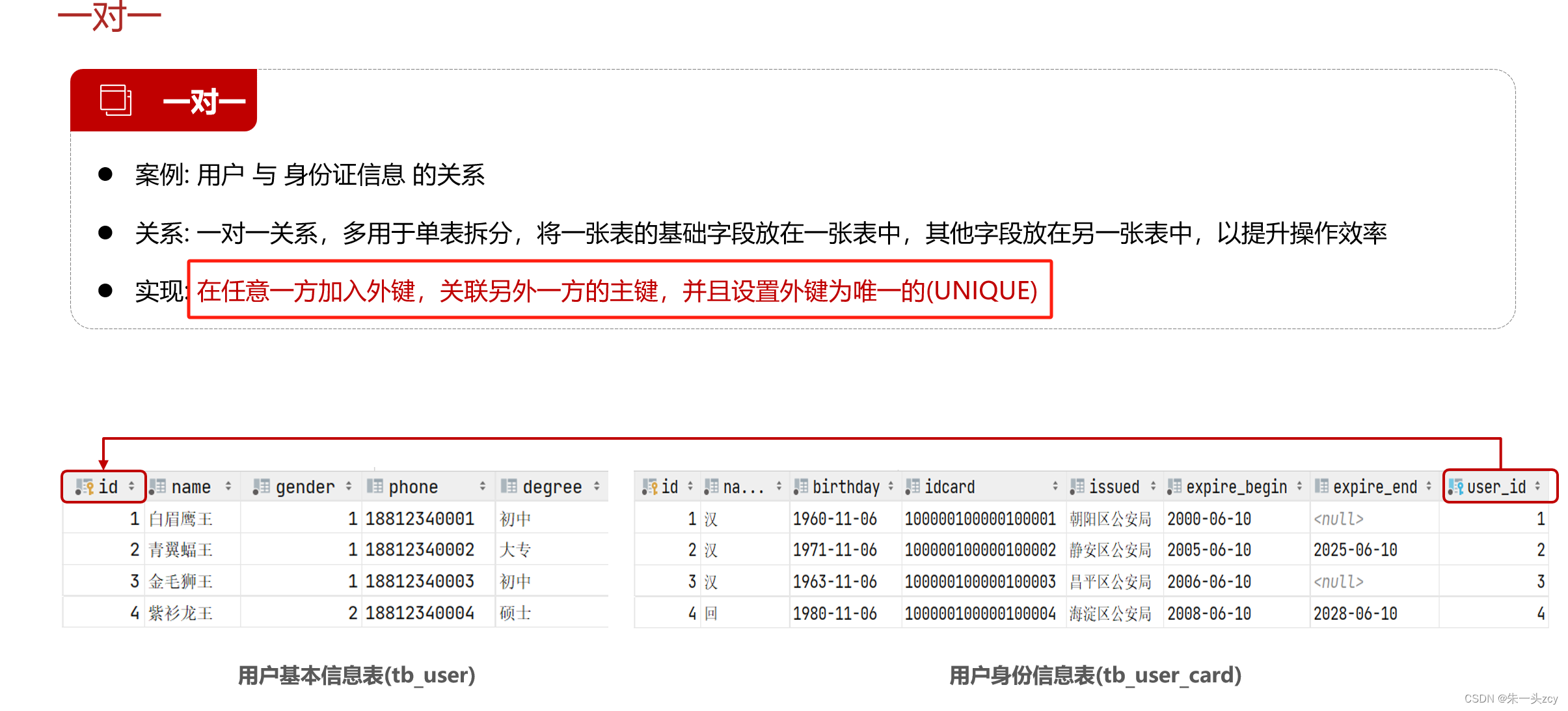
1.3 一对一

1.4 多对多
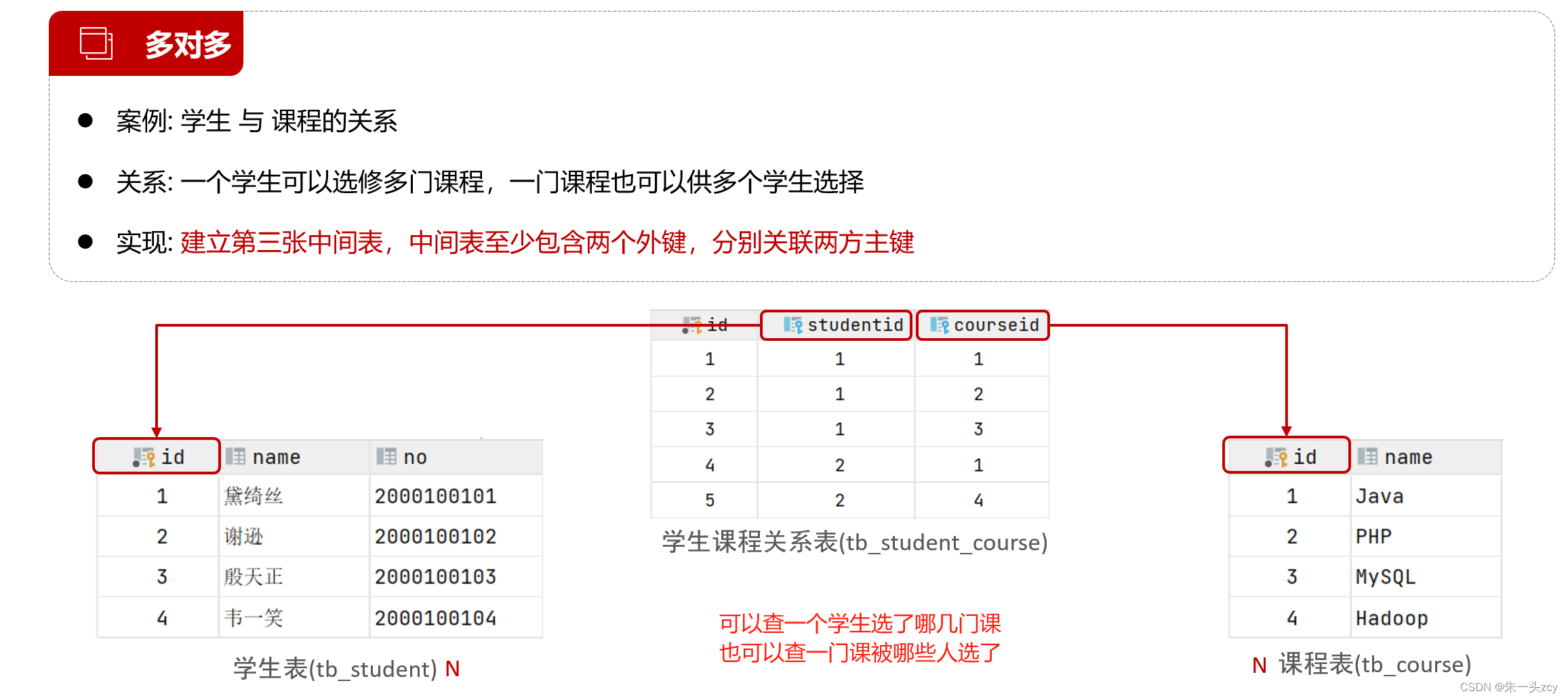
二、多表查询
2.1 测试数据准备
-- 多表查询: 数据准备
-- 部门管理
create table tb_dept
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(10) not null unique comment '部门名称',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
insert into tb_dept (id, name, create_time, update_time)
values (1, '学工部', now(), now()),
(2, '教研部', now(), now()),
(3, '咨询部', now(), now()),
(4, '就业部', now(), now()),
(5, '人事部', now(), now());
-- 员工管理
create table tb_emp
(
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师',
entrydate date comment '入职时间',
dept_id int unsigned comment '部门ID',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
INSERT INTO tb_emp
(id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time)
VALUES (1, 'jinyong', '123456', '金庸', 1, '1.jpg', 4, '2000-01-01', 2, now(), now()),
(2, 'zhangwuji', '123456', '张无忌', 1, '2.jpg', 2, '2015-01-01', 2, now(), now()),
(3, 'yangxiao', '123456', '杨逍', 1, '3.jpg', 2, '2008-05-01', 2, now(), now()),
(4, 'weiyixiao', '123456', '韦一笑', 1, '4.jpg', 2, '2007-01-01', 2, now(), now()),
(5, 'changyuchun', '123456', '常遇春', 1, '5.jpg', 2, '2012-12-05', 2, now(), now()),
(6, 'xiaozhao', '123456', '小昭', 2, '6.jpg', 3, '2013-09-05', 1, now(), now()),
(7, 'jixiaofu', '123456', '纪晓芙', 2, '7.jpg', 1, '2005-08-01', 1, now(), now()),
(8, 'zhouzhiruo', '123456', '周芷若', 2, '8.jpg', 1, '2014-11-09', 1, now(), now()),
(9, 'dingminjun', '123456', '丁敏君', 2, '9.jpg', 1, '2011-03-11', 1, now(), now()),
(10, 'zhaomin', '123456', '赵敏', 2, '10.jpg', 1, '2013-09-05', 1, now(), now()),
(11, 'luzhangke', '123456', '鹿杖客', 1, '11.jpg', 5, '2007-02-01', 3, now(), now()),
(12, 'hebiweng', '123456', '鹤笔翁', 1, '12.jpg', 5, '2008-08-18', 3, now(), now()),
(13, 'fangdongbai', '123456', '方东白', 1, '13.jpg', 5, '2012-11-01', 3, now(), now()),
(14, 'zhangsanfeng', '123456', '张三丰', 1, '14.jpg', 2, '2002-08-01', 2, now(), now()),
(15, 'yulianzhou', '123456', '俞莲舟', 1, '15.jpg', 2, '2011-05-01', 2, now(), now()),
(16, 'songyuanqiao', '123456', '宋远桥', 1, '16.jpg', 2, '2007-01-01', 2, now(), now()),
(17, 'chenyouliang', '123456', '陈友谅', 1, '17.jpg', NULL, '2015-03-21', NULL, now(), now());
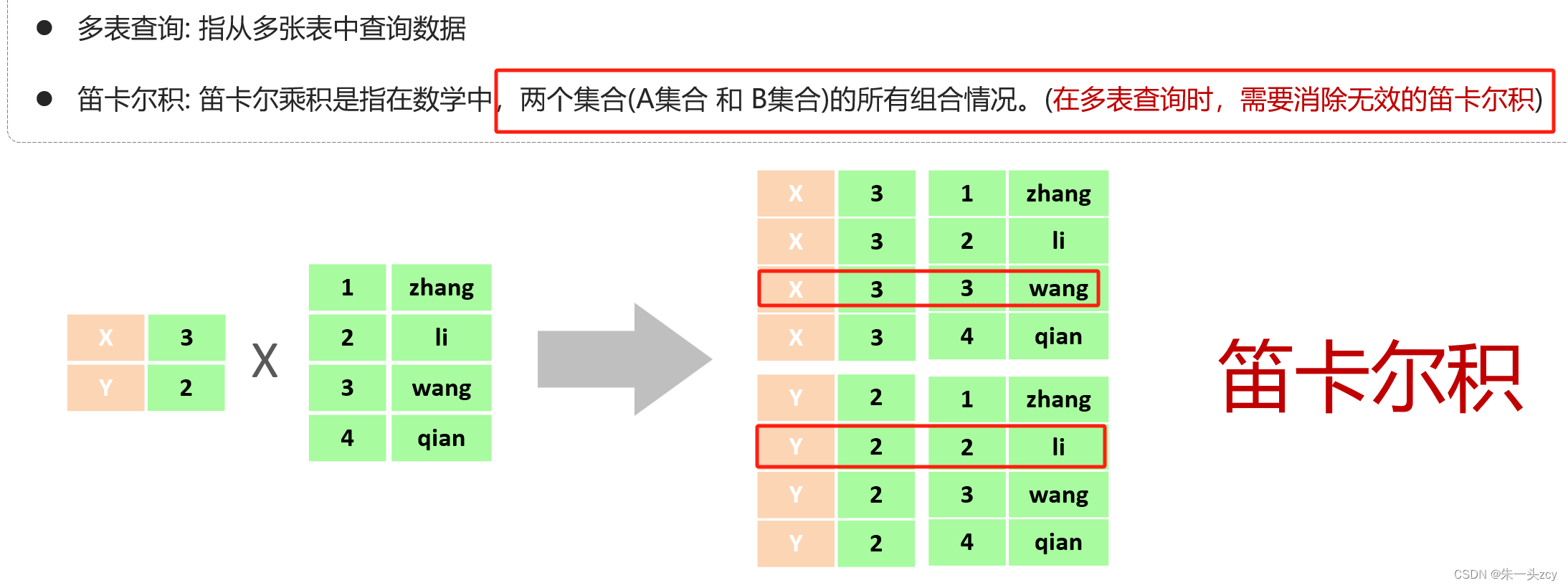
2.2 笛卡尔积
select * from tb_emp,tb_dept; -- 这是笛卡尔积 会有5*17条记录 每五条里面只有一条是有效的数据
select * from tb_emp,tb_dept where tb_emp.dept_id = tb_dept.id;
2.3 内连接
- 第十七个员工 内连接就查不出来(不属于交集) 要用外连接

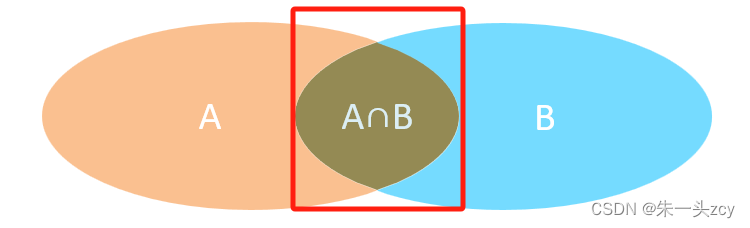
案例:
-- 内连接求的其实就是笛卡尔积 要用where或者on消除无效的数据
-- A. 查询员工的姓名 , 及所属的部门名称 (隐式内连接实现)
-- 这里第十七个员工的所属部门ID是NULL 所以他和部门表 就相当于是没有关系的 不属于交集部分 查不出来
select tb_emp.name as '姓名', tb_dept.name as '所属部门'
from tb_emp,tb_dept
where tb_emp.dept_id = tb_dept.id;
-- 起别名
select e.name, d.name
from tb_emp e,tb_dept d
where e.dept_id = d.id;
-- B. 查询员工的姓名 , 及所属的部门名称 (显式内连接实现)
select tb_emp.name, tb_dept.name
from tb_emp join tb_dept
on tb_emp.dept_id = tb_dept.id;
2.4 外连接

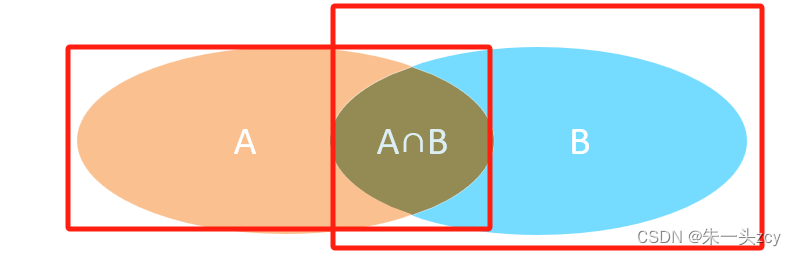
案例:
-- =============================== 外连接 ============================
-- A. 查询员工表 所有 员工的姓名, 和对应的部门名称 (左外连接)
-- 能查到17条记录 16(交集部分数据)+1(员工表交集外的一条数据)
select e.name, d.name
from tb_emp e left join tb_dept d
on e.dept_id = d.id;
-- B. 查询部门表 所有 部门的名称, 和对应的员工名称 (右外连接)
-- 能查到18条记录() 16(交集部分数据)+2(部门表交集外的两条数据)
select d.name '部门名称',e.name '员工名称'
from tb_emp e right join tb_dept d
on e.dept_id = d.id;
-- 换换位置就是左右连接了
select e.name, d.name
from tb_dept d left join tb_emp e
on e.dept_id = d.id;
2.5 子查询

子查询分类:

1.标量子查询

案例:
-- 标量子查询
-- 查询 "教研部" 的所有员工信息
-- a. 查询 教研部 的部门ID - tb_dept
select id from tb_dept where name = '教研部'; -- 结果是2
-- b. 再查询该部门ID下的员工信息 - tb_emp
select * from tb_emp where dept_id = 2; -- 拿到上面的结果2
-- 一条SQL搞定
select * from tb_emp
where
dept_id = (select id from tb_dept where name = '教研部');
-- 查询在 "方东白" 入职之后的员工信息
-- a. 查询 方东白 的入职时间
select entrydate from tb_emp where name = '方东白';
-- b. 再查询在 "方东白" 入职之后的员工信息
select * from tb_emp
where
entrydate > (select entrydate from tb_emp where name = '方东白');
2.列子查询

案例:
-- 列子查询
-- 查询 "教研部" 和 "咨询部" 的所有员工信息
-- a. 查询 "教研部" 和 "咨询部" 的部门ID - tb_dept
select id from tb_dept where name in ('教研部','咨询部');
select id from tb_dept where name = '教研部' or name = '咨询部';
-- b. 根据部门ID, 查询该部门下的员工信息 - tb_emp
select * from tb_emp where dept_id in (3,2);
select * from tb_emp where dept_id in (select id from tb_dept where name in ('教研部','咨询部'));
3.行子查询

案例:
-- 行子查询
-- 查询与 "韦一笑" 的入职日期 及 职位都相同的员工信息 ;
-- a. 查询 "韦一笑" 的入职日期 及 职位
select entrydate,job from tb_emp where name = '韦一笑';
-- b. 查询与其入职日期 及 职位都相同的员工信息 ;
-- 方式一
select * from tb_emp where entrydate = '2007-01-01' and job = 2;
select * from tb_emp where entrydate = (select entrydate from tb_emp where name = '韦一笑')
and job = (select job from tb_emp where name = '韦一笑');
-- 方式二
-- 优化 减少子查询的次数
select * from tb_emp where (entrydate,job) = ('2007-01-01', 2);
select * from tb_emp where (entrydate,job) = (select entrydate,job from tb_emp where name = '韦一笑');
4.表子查询

案例:
-- 表子查询
-- 查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门名称
-- a. 查询入职日期是 "2006-01-01" 之后的员工信息
select * from tb_emp where entrydate > '2006-01-01';
-- b. 查询这部分员工信息及其部门名称 - tb_dept
-- e作为临时表 和d表做笛卡尔积 然后筛选出有效数据
select e.*,d.name
from (select * from tb_emp where entrydate > '2006-01-01') e,tb_dept d
where e.dept_id = d.id;
三、事务
3.1 问题场景引入
有可能是SQL代码写错了或各种原因,导致该部门的员工没有被删除.
模拟这个场景.

3.2 概念


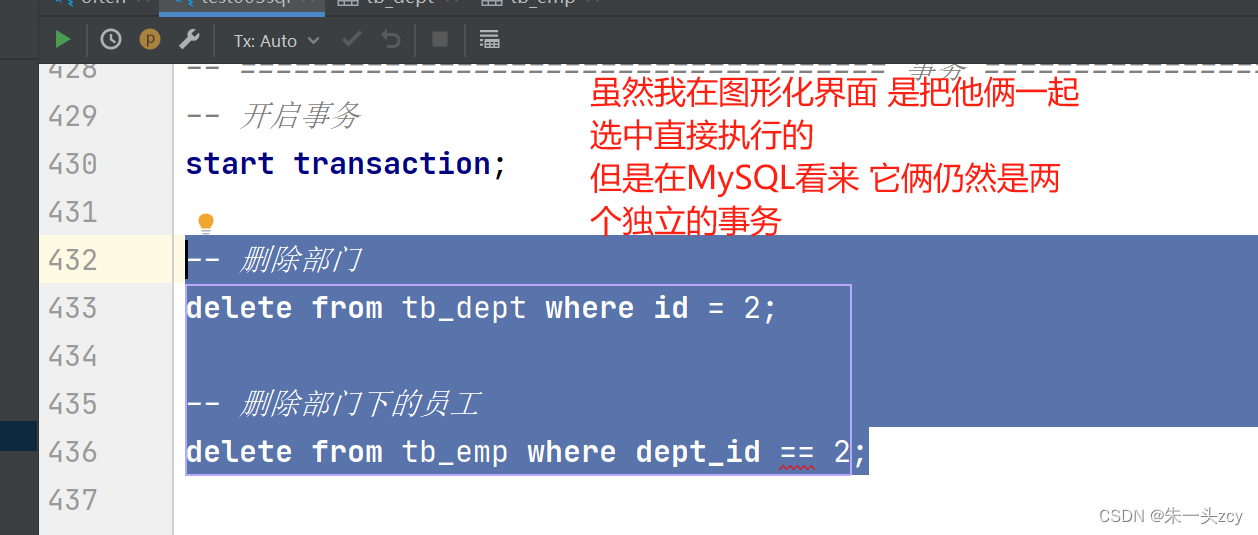
3.3 事务操作

正常情况:执行完没错,提交事务
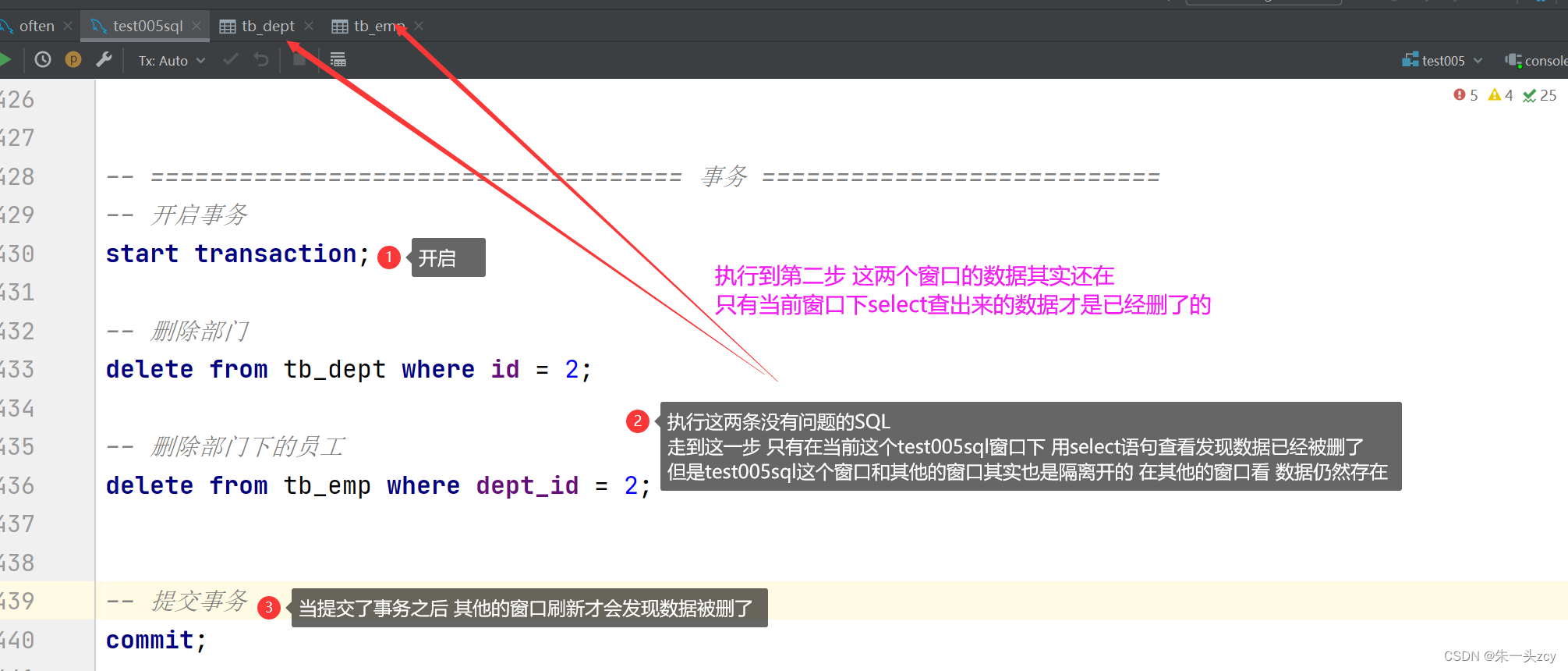
异常情况:执行出错,回滚事务.可以把删除掉的数据恢复,保证了操作前后数据的一致性

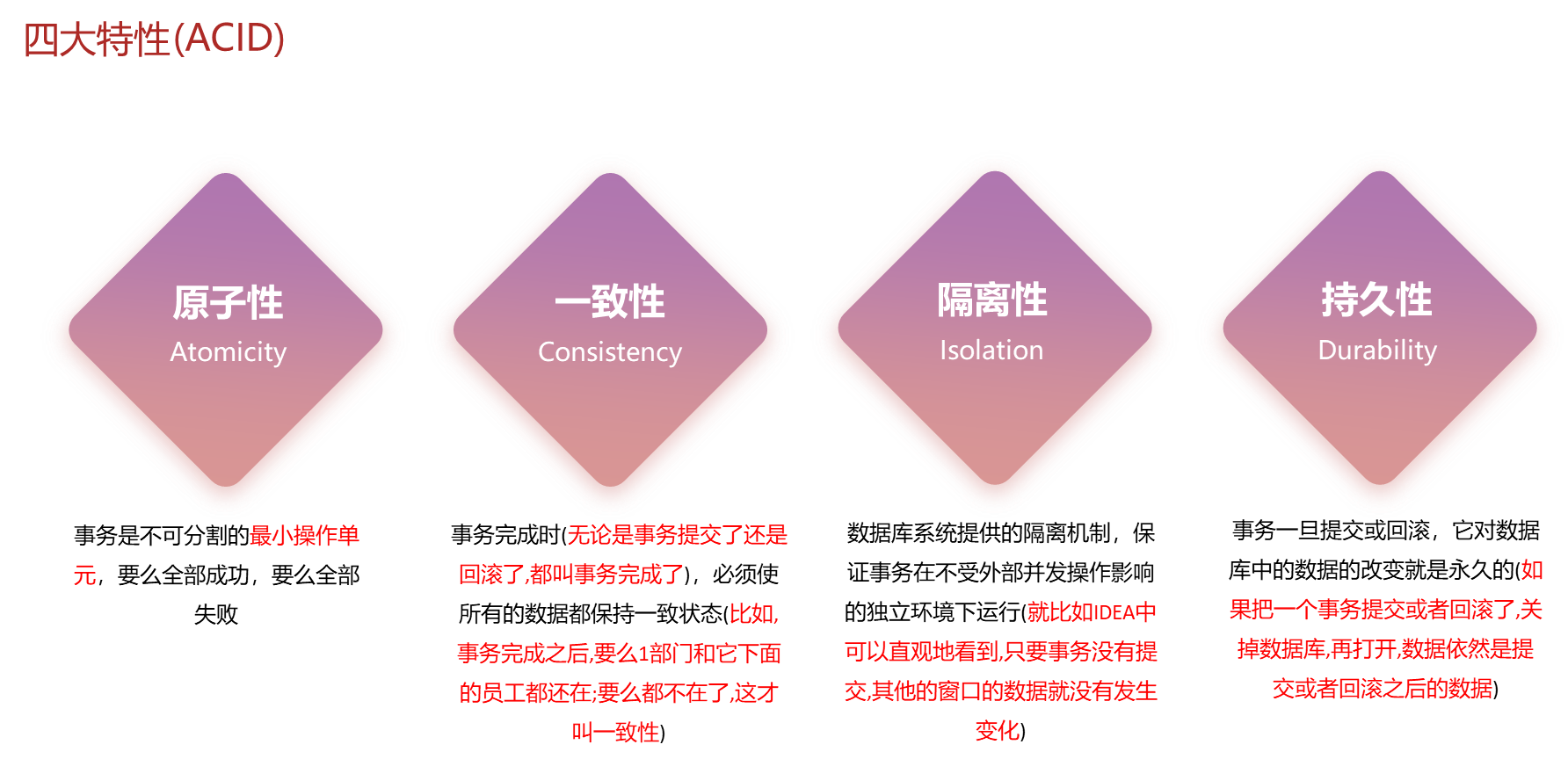
3.4 事务的四大特性ACID
四、索引
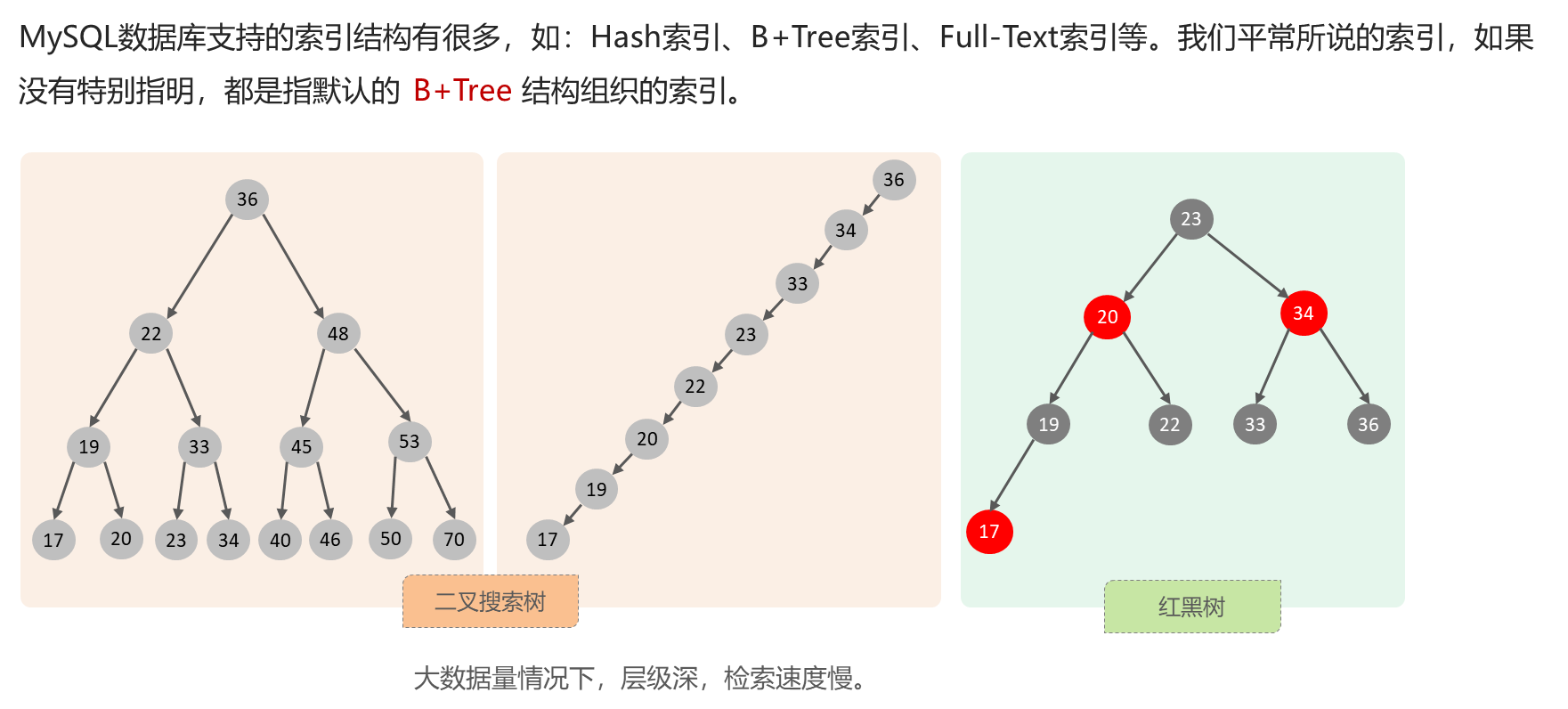
4.1 概念
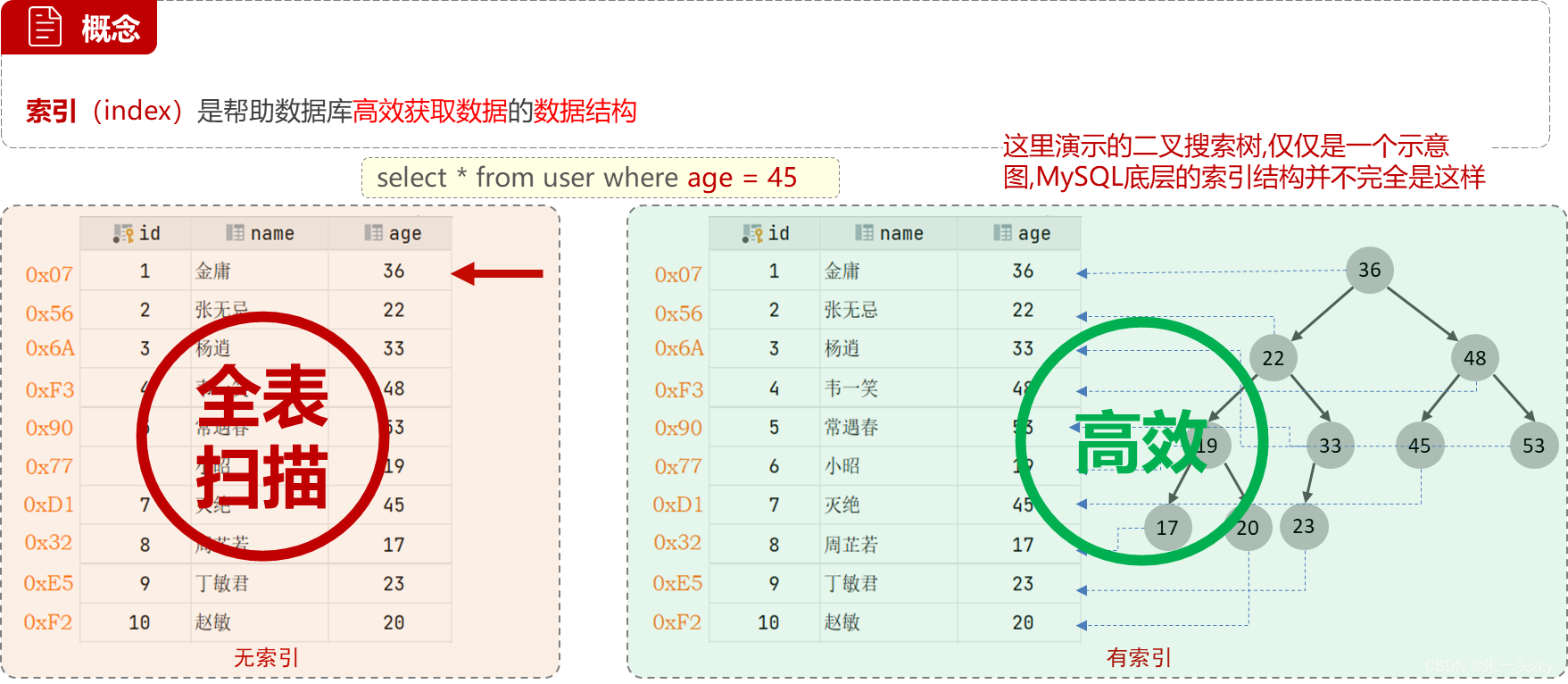
4.2 优缺点

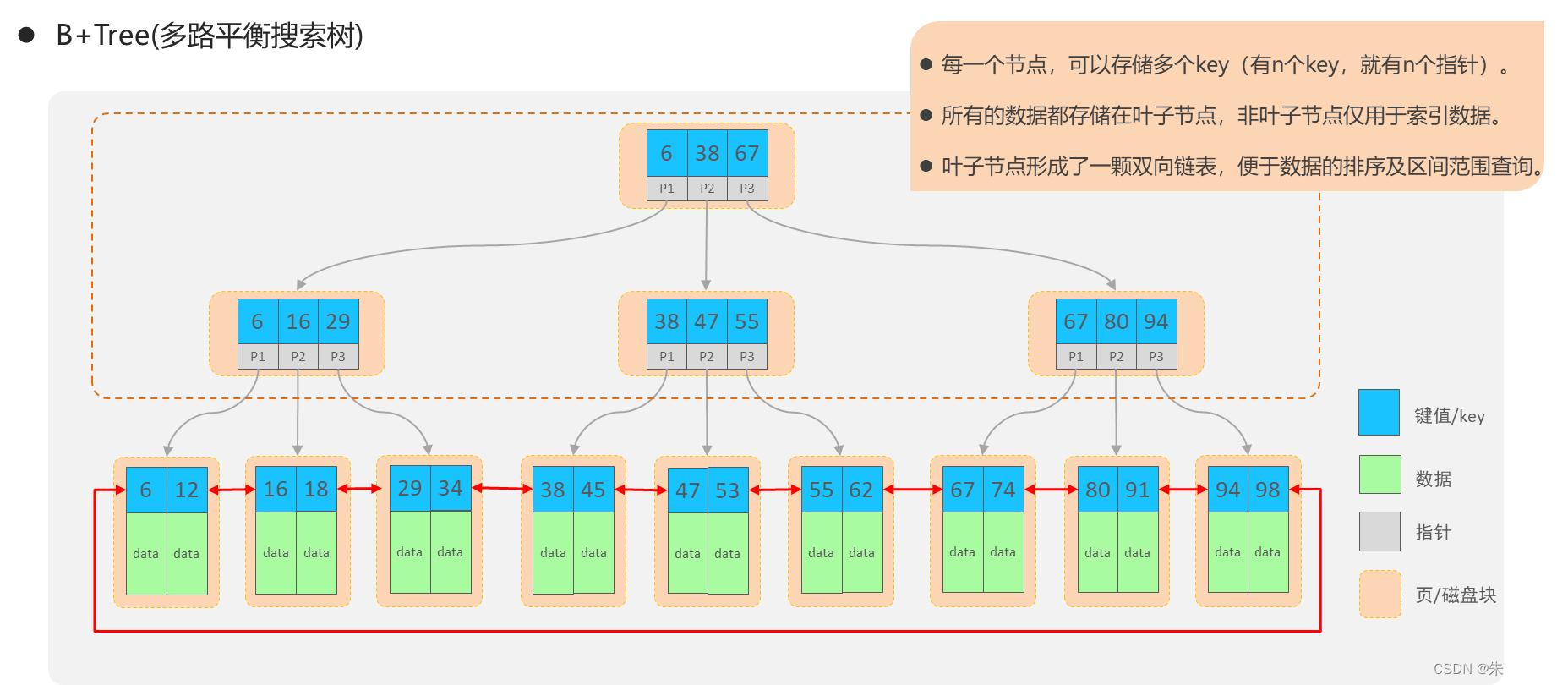
4.3 MySQL的索引结构-B+树
4.4 索引操作

案例:
-- ================================ 索引 =============================
select * from tb_sku where sn = '100000003145008'; -- 14s
create index idx_sku_sn on tb_sku (sn);
select * from tb_sku where sn = '100000003145008'; -- 速度贼快
-- 创建 : 为tb_emp表的name字段建立一个索引 .
create index idx_emp_name on tb_emp (name);
-- 查询 : 查询 tb_emp 表的索引信息 .
show index from tb_emp;
-- 删除: 删除 tb_emp 表中name字段的索引 .
drop index idx_emp_name on tb_emp;