1.Series的索引
Series是Pandas库中的一种一维数据结构对象,与常规的一维数组相比,其最显著的特点在于拥有显式的索引结构。这种显式索引使得Series在数据处理和分析中更具灵活性和便利性。
显式索引指的是Series中每个元素除了值之外,还关联着一个明确的标识,即索引标签。这些标签可以是任意类型的数据,如整数、字符串等,为数据提供了额外的描述信息。通过显式索引,用户可以方便地根据特定标签访问、筛选或操作Series中的元素。
相对而言,隐式索引则是指那些没有显式定义索引的结构中,元素所隐含的顺序位置信息。在常规的一维数组或列表中,元素的索引通常是隐式的,通过整数来表示其在数组中的位置。
Series通过结合显式索引和值,为数据处理提供了一种更为强大和灵活的工具。无论是在数据分析、机器学习还是其他数据处理场景中,Series的显式索引都能大大提高工作效率和准确性。
2.显式索引
-
使用 index 中的元素作为索引值
-
使用 .loc[](推荐)
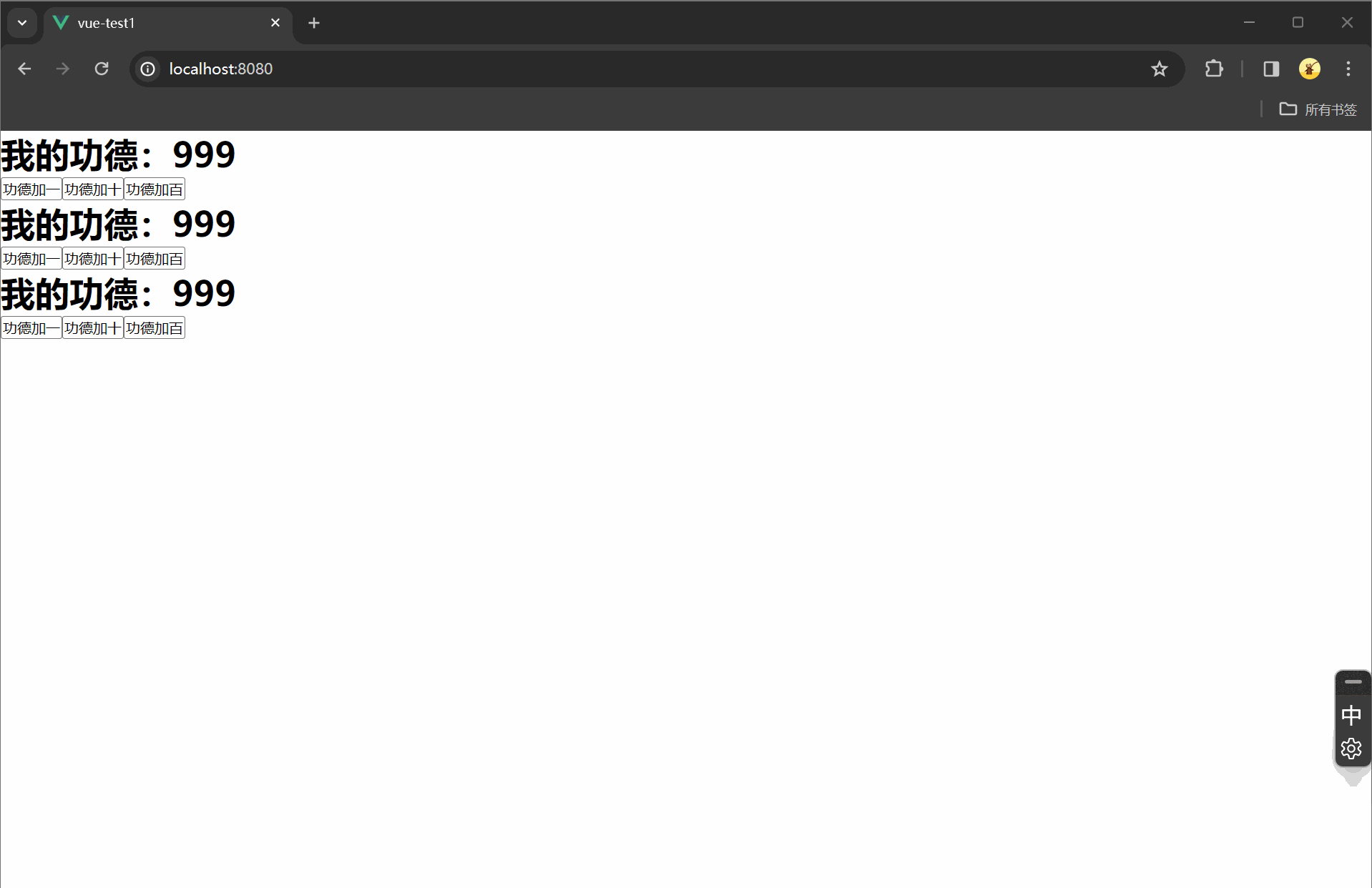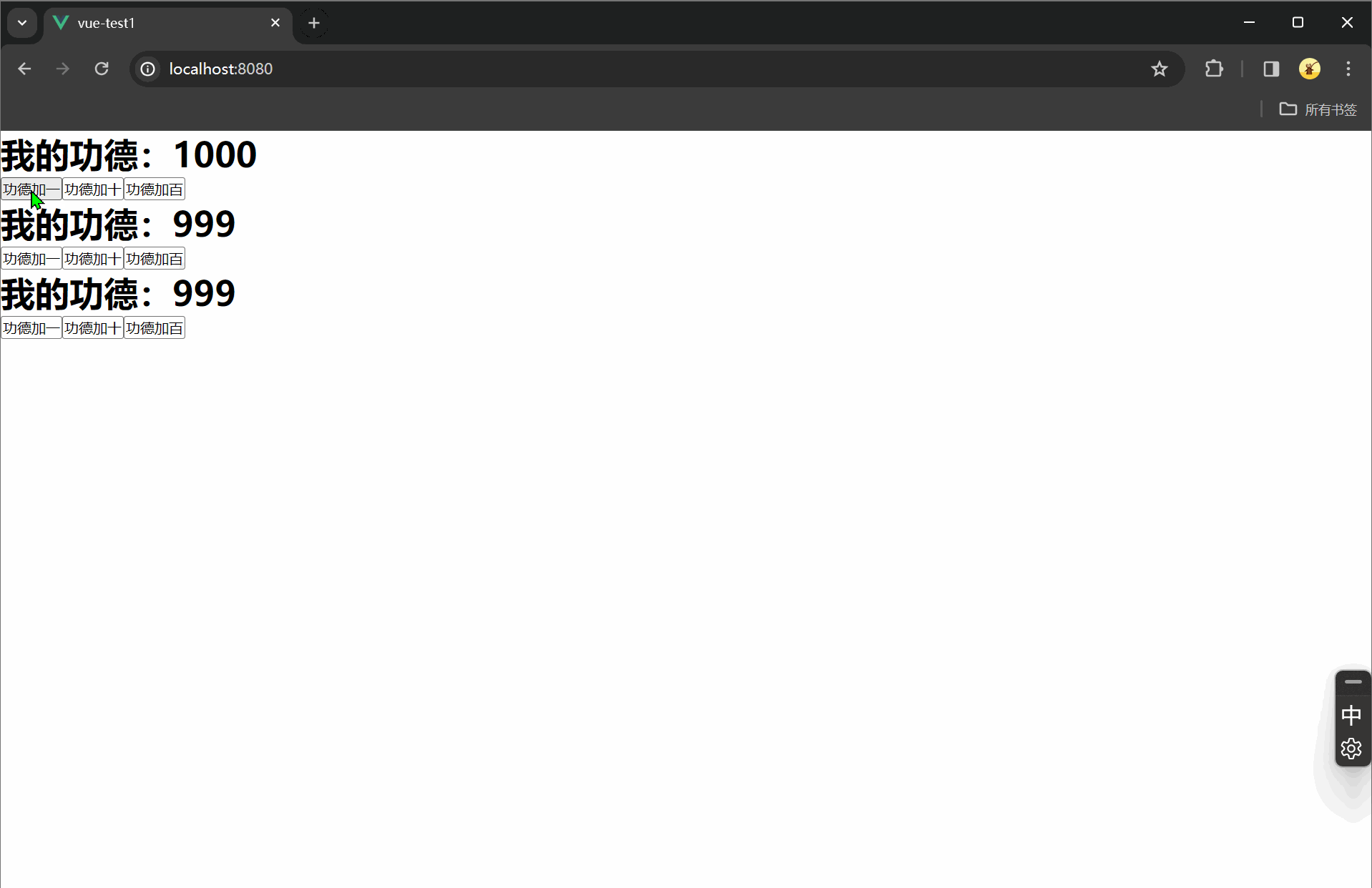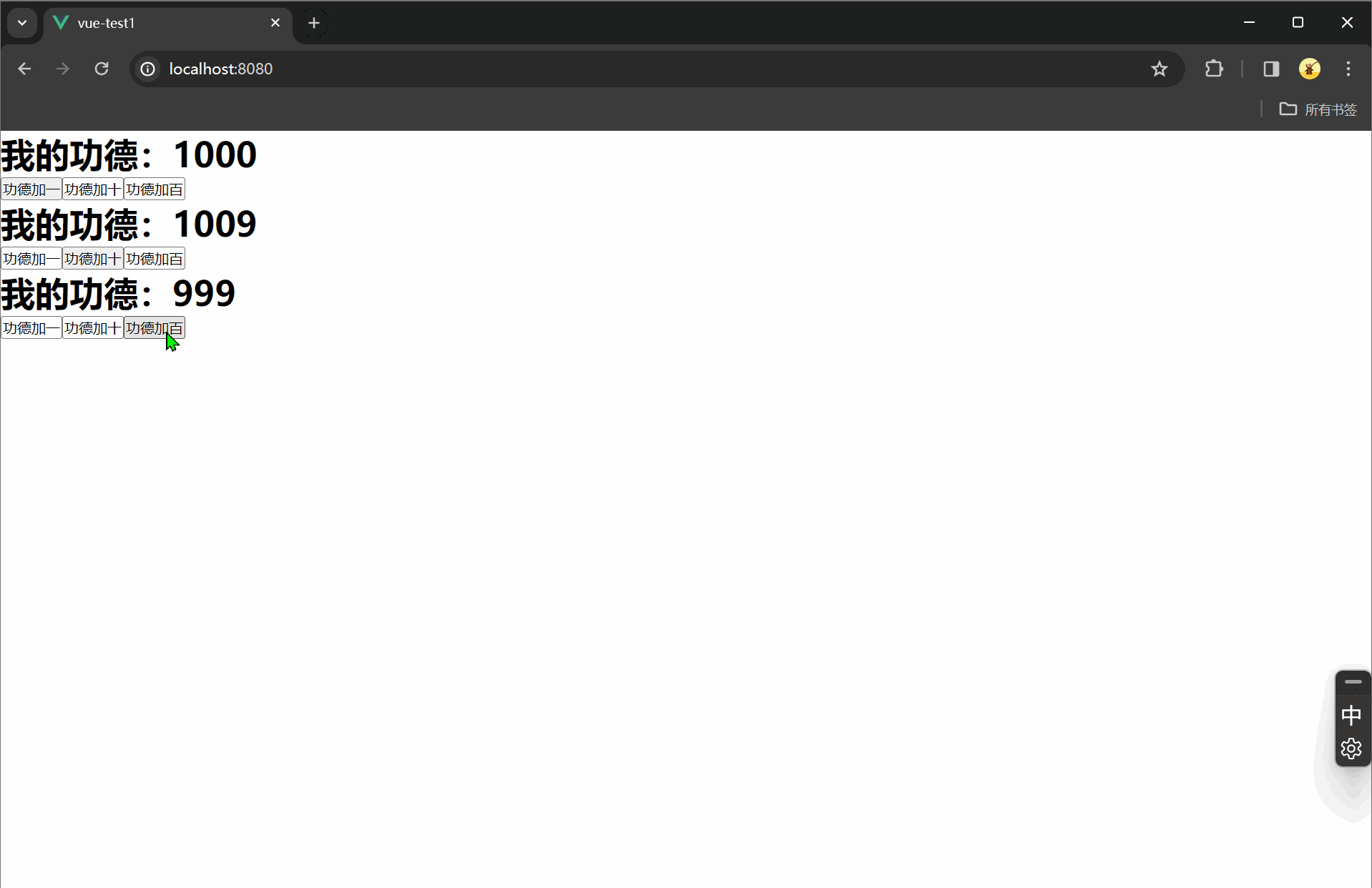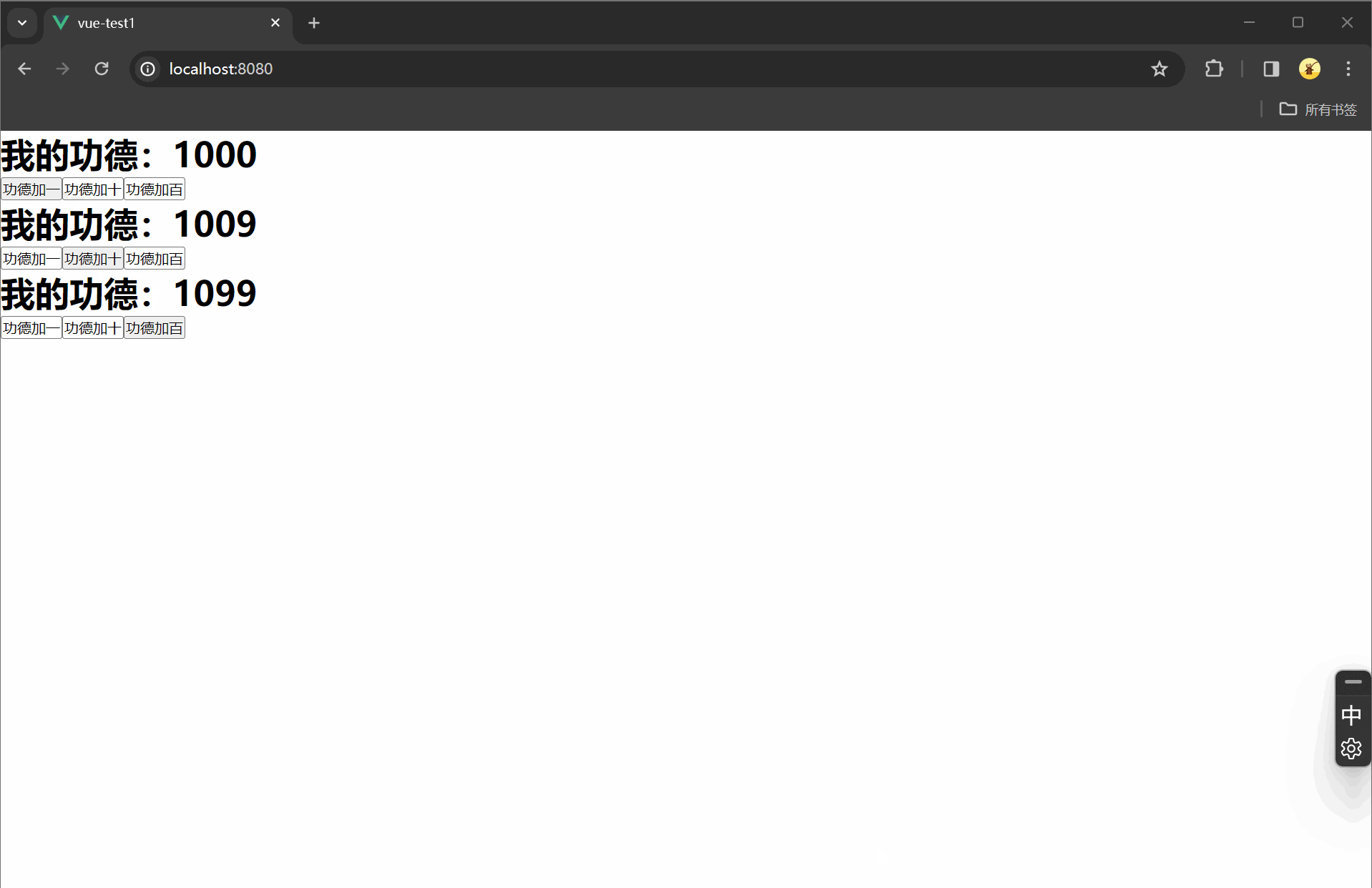
s = pd.Series({"Python":150,"NumPy":100,"Pandas":130})
s
# 执行结果
Python 150
NumPy 100
Pandas 130
dtype: int64
# 显示索引:使用索引名,取单个元素得到的是值
s["Python"]
# 执行结果
150
# 使用2个中括号得到的类型式 Series,一次取多个元素
s[["Python","NumPy"]]
# 执行结果
Python 150
NumPy 100
dtype: int64
# 使用 loc[]
s.loc["Python"]
s.loc[["Python","NumPy"]]
# 执行结果
Python 150
NumPy 100
dtype: int643.隐式索引
-
使用整数作为索引值
-
使用 .iloc[](推荐)
# 隐式索引:使用数字下标
s[0]
# 执行结果
150
s[[0,2]]
# 执行结果
Python 150
Pandas 130
dtype: int64
s[[0]]
# 执行结果
Python 150
dtype: int64
# 使用 iloc[]
s.iloc[0]
# 执行结果
150
s.iloc[[0,2]]
# 执行结果
Python 150
Pandas 130
dtype: int64