“团结就是力量”,面对复杂多变的现实环境,multi-agent应运而生。相较于单打独斗的single-agent,multi-agent集结了多个功能各异的LLM,共同攻克难关。然而,这种协同作战的方式也带来了沉重的推理负担,限制了multi-agent在开放世界中的发展潜力。
特别是在多模态环境下,视觉、音频、文本交织在一起,如何动态调整多模态语言模型(MLMs),以适应视觉世界的纷繁复杂,成为摆在我们面前的一大挑战。
GPT-3.5研究测试: https://hujiaoai.cn
GPT-4研究测试: https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4): https://hiclaude3.com
浙大团队结合额外专家模块,提出了一种多模态multi-agent训练的层次知识蒸馏方法。multi-agent在一个自组织的层次系统中协作,实现精细的思维链和高效的部署。这里的agent通过教师模型进行分层次训练,模拟动态并调整任务,也就是说仅使用一个多模态语言模型(MLM)就能实现有效合作。经过蒸馏后,STEVE-2可以在无需专家指导的情况下,通过单一模型发展出高效的体感Agent,完成精细的开放任务。
论文标题:
Do We Really Need a Complex Agent System? Distill Embodied Agent into a Single Model
论文链接:
https://arxiv.org/pdf/2404.04619.pdf
方法
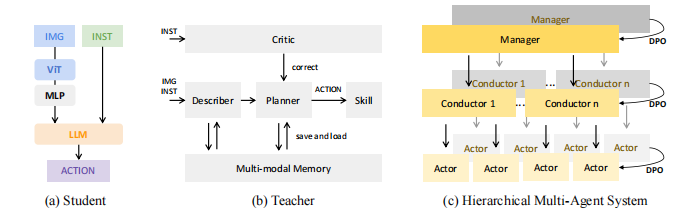
整体框架如上图所示, 图(a)中STEVE-2接受文本任务描述和图像作为每一步的输入状态,STEVE-2 可以被模块化为三个组成部分:
-
ViT作为视觉编码器,将图像编码为嵌入。
-
多层感知器(Multi-Layer Perceptron,MLP)层将ViT产生的嵌入与语言空间对齐。
-
LLM作为语言解码器,它接受指令token的拼接和线性投影层的输出作为输入,生成文本动作。然后,这个文本动作被用来检索代码动作。
STEVE-2生成从图(b)教师agent(一个多功能MLM的组合)提炼出的行动序列,两者在Multi-Agent系统中以分层组织结构的形式并行工作。它利用多模态语言模型的认知和协作能力,在开放式环境中处理视觉()、音频()和物体()目标,管理并执行复杂的多agent任务:
![]()
其中表示第个conductor agent的视觉、音频和其他属性的状态列表,是初始任务。接着为conductor agent获得动作,是agent的总数。
图(c)中层次架构主要包括两个部分:高层的集中式规划manager agent表示为和低层的分布式执行conductor agent表示为,这两个agent都由一个多模态语言模型实现,conductor agent的动作由以下方式获取:
![]()
Actor agents 通过实现:,是可选的附加行动。
在分层多agent系统中,每个教师agent通过不同的提示分别执行这三个不同的MLM。然后通过DPO损失的层次知识蒸馏,STEVE-2 学习了这三个agents的性能:。
多模态教师模型
多模态教师模型MLM包含三种关键agent:manager、conductor和actor。每个agent均配备规划器(Planner)、描述器(Describer)、批评者(Critic)和技能模块(Skill)。
它们共同协作,制定任务计划,处理多模态数据,通过反馈优化策略,并有效分配子任务。随后,它们将策略转化为具体动作,协调团队形成,确保任务分配与中央指令一致。同时,通过课程学习,模型能持续学习和适应复杂任务。此外,模型还维护一个多模态记忆,用于存储描述器生成的长期描述及规划器修正后的轨迹,以支持更高效的决策和执行。
基于MLM的自适应规划
本文综合了环境观察和任务指令,以根据当前情况规划行动。首先,将多模态观察转化为文本描述,避免了LLMs直接进行场景标注。从STEVE-21K数据集中提取物品关键词,并运用GPT-4V将这些观察结果编织成句子。
在规划阶段,大语言模型从文本观察中筛选出与任务相关的条件句子。通过预定义的模板,巧妙地将额外信息整合成文本,使计划更加全面。随后,结合任务指令和这些描述性文本,利用LLM的语言组件生成行动计划。
这种方法分层运用大语言模型的能力,生成更准确的情境描述和计划,相较于完全集成模型,显著降低了生成不切实际元素的风险。
自主错误修正与主动规划
STEVE-2 通过闭环反馈机制提升规划,通过分析反馈并利用自我解释能力自动纠正错误,无需人工干预或额外信息。它能提前识别并修正计划中的潜在问题,通过模拟和评估每个步骤来减少因计划失败导致的困难情况。这种主动方法使它能够预见资源不足等可能阻碍任务完成的问题。
带有额外专家信息的教师模型
现有开放型agent在面临不确定指令下的复杂任务时往往束手无策。特别是导航和创作这类高度开放的任务,由于语言指令可能信息不足且结果复杂多样,要求agent能够自主想象并补充指令中未明确指出的细节。
作者从从Creative Agents的研究中受到启发,通过引入生成模型作为输入先验,并借助想象力模块,使Agent能够模拟并想象任务细节,从而更有效地规划和执行任务。
具体来说,作者扩展了到额外的Expert,修改了VQ-VAE ,用于创作任务生成3D占用空间,以及使用多模态信号的动态地图 来处理导航任务。需要注意的是,仅将这部分与教师模型集成,以避免直接向STEVE-2部分提供提示信息,防止作弊。这种方法也确保了STEVE-2的轻量性。表示如下:
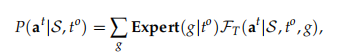
其中, 表示文本描述的多模态知识。状态由表示。Expert 将文本对象目标 转换为。这个过程为教师模型 提供了详尽的任务描述。这为Agent提供了更丰富的任务信息,降低了不确定性。
知识蒸馏
目标是构建一个层次化的多模态语言模型系统,每个学生模型θ被赋予特定的功能,能够学习和复制教师 的行为,同时利用额外的知识:θ 和 。
作者在训练 STEVE-2 系统中的manager, conductor and actor agents时,采用了类似的方法,使用层次化的MLM教师。通过最小化由θ 引发的状态分布的目标函数来实现这一目标:
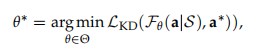
其中,损失函数 是知识蒸馏损失。作者在实验中采用了DPO损失,它使用响应对非首选响应的相对对数概率,并结合动态每样本权重来防止模型退化,经证明,这种方法在将语言模型与教师偏好对齐方面优于交叉熵:
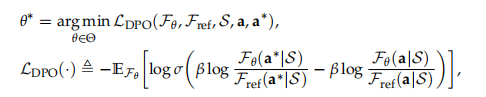
其中使用逻辑函数σ和超参数β来控制与参考agent 的偏差。参考agent是通过对基于规则的老师产生的数据集进行行为克隆得到的。
模型使用最大似然估计(MLE)进行训练,并增加一个正则化项,以防止agent 偏离老师的准确分布,保持生成的多样性,并避免过早收敛到简单任务。
为了稳定训练过程,MLM agent θ被初始化为。然而,由于无法计算的分布,使用DAgger来收敛到最优agent θ,以克服累积误差和分布偏移问题。
实验
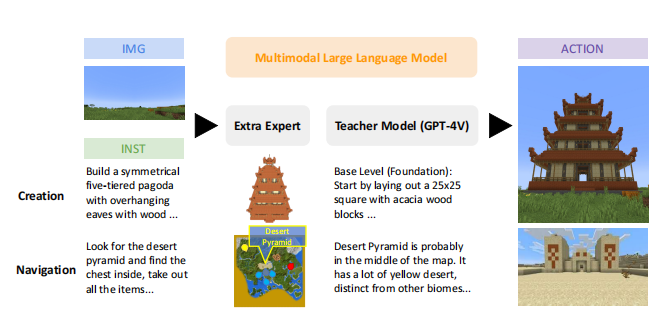
作者通过多模态创造与导航两个任务对多agent合作和执行复杂任务的效率进行了实验。多模态导航任务比如下图中的示例“寻找沙漠金字塔,找到里面的箱子,拿出所有的物品”,而多模态创造任务则类似“用木头建造对称的五层悬檐宝塔”的指令。
在本文中Extra Expert可以生成模型和动态地图,用于完成两项任务。生成模型生成三维占用空间,渲染成多视角图像,并输入给教师模型GPT-4V。
多模态导航任务
该任务包括多模态目标搜索、连续区块搜索和地图探索。实验结果见下表,
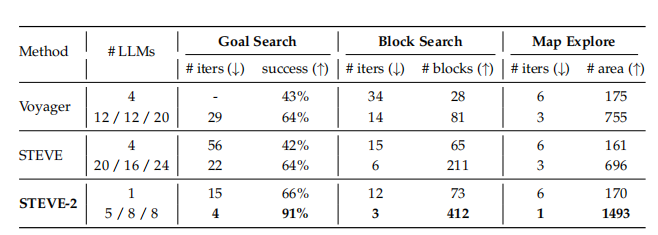
STEVE-2表现出最佳性能,这表明在不同操作模式的多个导航任务中,多agent合作的高效性。当使用更少的LLMs时,处理效率和模块减少显著提升。
-
多模态目标搜索。 多模态目标搜索技术能精准识别图像、对象和音频目标。在游戏中,对象标签帮助识别物品,图像标签助力物体定位,而音频标签则能捕捉玩家范围外的声音。STEVE-2通过分解任务层次,其性能相较于目前最先进的LLM方法提升了5.5倍,同时成功率保持不变。
-
连续区块搜索。 连续区块搜索是对agent探索能力和定位钻石区块熟练度的全面评估。在此过程中,agent的目标是以最少的迭代次数找到尽可能多的区块。通过动态地图和分层结构的辅助,能更有效地发现和部署更多区块,从而提升搜索效率。
-
地图探索。 地图探索旨在让agent尽可能多地更新地图信息。在相同的环境感知条件下,对于未到达的区域,系统会通过文本形式提供状态信息。此外,每步移动的最大距离限制在50块以内。在此限制下,STEVE-2展现出卓越性能,相较于最先进的LLM方法,性能提升了1.9倍,同时效率也提高了3倍。
多模态创造任务
为了评估创造任务的完成情况,将其分为收集材料和建造两部分,实验结果如下表所示:

-
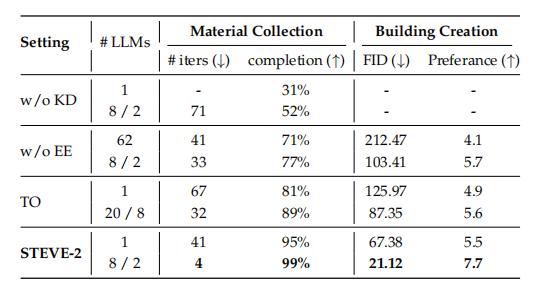
材料收集。本文为agent提供了一份详尽的材料清单及其所需数量,以助力其高效完成收集任务。实验结果表明,STEVE-2在保证收集准确性的同时,将效率提升了惊人的19倍,展现出了卓越的性能。
-
建筑生成。 由于建筑生成的复杂性和独特性,agent需要具备想象能力,以填补指令中未明确说明的细节。为此,作者利用微调后的VQ-VAE作为3D占用空间生成工具,帮助agent进行想象。同时采用多视角的占用状态作为教师模型的输入,训练模型执行相应动作。为了进一步简化架构并提升性能还采用知识蒸馏方法,仅使用一个agent和一个大语言模型。这种简化不仅显著提高了输出质量,甚至在某些方面超越了更复杂的结构,展现出强大的潜力和效率。
下图是本方法的代表性输出结果,并与GT (Ground Truth)进行比较:

本文的方法相较于Creative Agents方法,展现了对建筑结构保留的深入理解,生成结果与描述文本高度一致。
由于抽象文本的创建方式多样,综合使用FID指数及人工统计偏好来判断生成结果是否贴合描述。STEVE-2在FID得分上实现了3.2倍的提升,且在GPT-4V和人类的主观偏好评分中均名列前茅,确保了高准确性的同时,也展现了卓越的性能。
消融实验
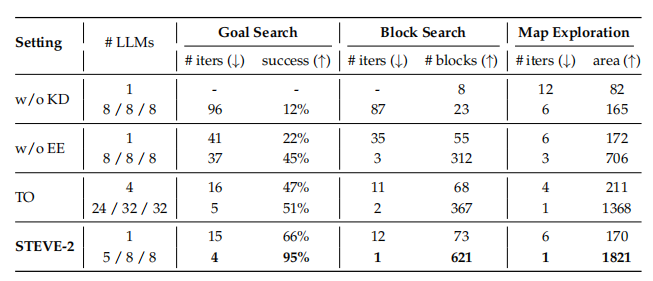
作者针对多模态目标搜索、连续区块搜索和地图探索进行了研究。w/o KD 表示没有知识蒸馏,w/o EE 表示没有额外专家,TO 是仅有的教师模型,用于预热阶段提供额外知识。结果如下表所示
下表是对材料收集和建筑创建的消融实验。
作者还比较了不同语言模型的效率,如下表所示, # time 指的是每次迭代的运行时间,用于计算一个agent的所有语言模型的推理时间。VRAM 大约是 GPU 内存使用量。基于 GPT-4 的方法是通过 API调用,没有计算部分。
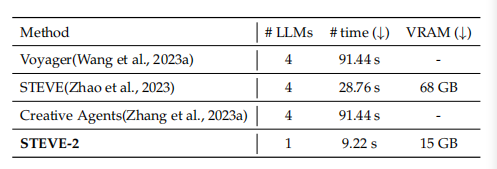
从以上实验结果可以看出,STEVE-2 模型在系统性能上显著优于教师模型 GPT-4V,导航效率提高了 1.8 倍,创作质量提升了 4 倍。
知识蒸馏进一步提升了模型,使其导航效率提高了 24 倍,还能从头开始生成高质量的建筑。
结论
STEVE-2通过采用分层结构实现精细任务划分,结合镜像蒸馏方法充分利用并行的模拟数据,以及引入想象模型为模拟注入额外上下文知识,有效弥合了任务理解和执行之间的鸿沟,并展现出对开放环境的动态适应能力。在复杂且现实的应用场景中,STEVE-2可以展现出更高的复杂性、灵活性和效率,为人工智能和具身智能领域的发展注入了新的活力。