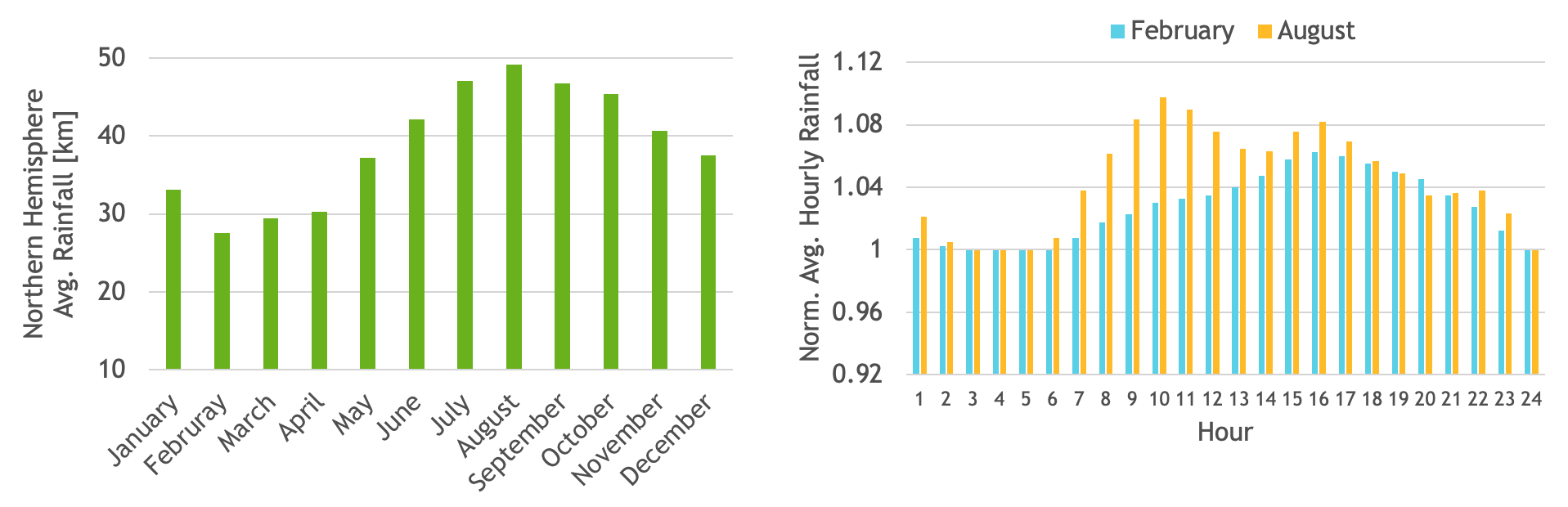
📝个人主页:哈__
期待您的关注

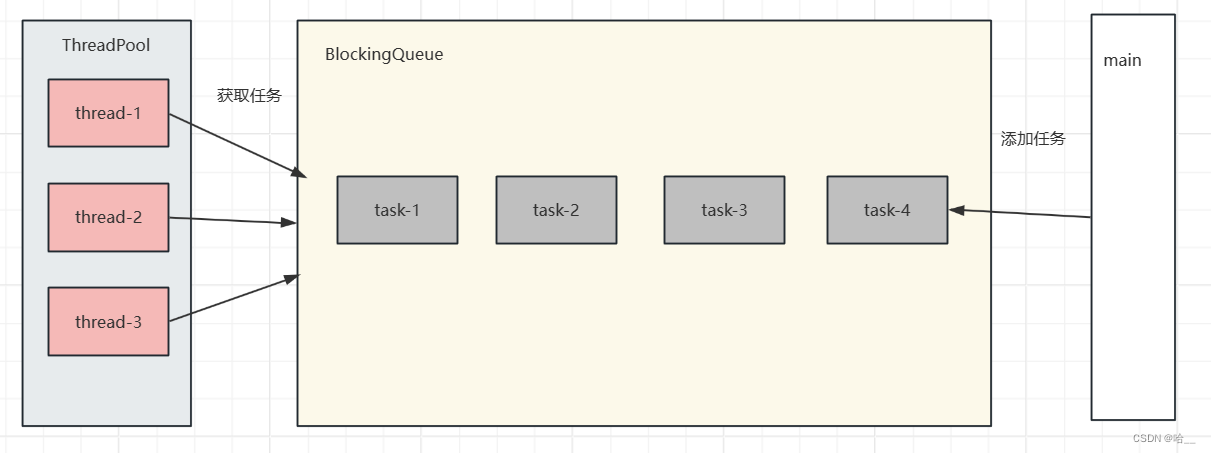
一、线程池的模式
线程池顾名思义就是管理线程的一个池子,我们把创建线程的过程交给线程池来处理,而这个线程池当中的线程都会从阻塞队列当中取获取任务执行。
我们不在直接把任务的创建过程写到我们初始化的线程对象中,而是通过调用线程池的execute()方法,同时把我们的具体任务交作为参数传给线程池,之后线程池就会把任务添加到阻塞队列当中,而线程池当中的线程会从阻塞队列当中获取任务并执行。
二、线程池的一些参数
- corePoolSize:线程池核心线程大小,即最小线程数(初始化线程数)。线程池会维护当前数量的线程在线程池中,即使这些线程一直处于闲置状态,也不会被销毁,除非设置了allowCoreThreadTimeOut。
- maximumPoolSize:线程池最大线程数量。当任务提交到线程池后,如果当前线程数小于核心线程数,则会创建新线程来处理任务;如果当前线程数大于或等于核心线程数,但小于最大线程数,并且任务队列已满,则会创建新线程来处理任务。
- keepAliveTime:空闲线程的存活时间。当线程池中的线程数量大于核心线程数且线程处于空闲状态时,在指定时间后,这个空闲线程将会被销毁,从而逐渐恢复到稳定的核心线程数数量。
- unit:keepAliveTime的存活时间的计量单位,通常使用TimeUnit枚举类中的方法,如TimeUnit.SECONDS表示秒级。
- workQueue:任务队列。用于存放等待执行的任务,常见的实现类有LinkedBlockingQueue、ArrayBlockingQueue等。
- threadFactory:线程工厂。用于创建新的线程,可以自定义线程的名称、优先级等。
- handler:拒绝策略。当任务无法执行(如线程池已满)时,可以选择的策略有:AbortPolicy(抛出异常)、CallerRunsPolicy(调用者运行)、DiscardOldestPolicy(丢弃最老的任务)、DiscardPolicy(无声丢弃)。
三、代码实现
因为我们只是简单的实现,所以有一些情况和实际不太相似。
1.BlockingQueue
先来看看我们阻塞队列当中的一些参数,为了在多线程环境下防止并发问题,我使用了ReentrantLock,使用它的目的是为了创建多个不同的阻塞条件。
在我们调用一个对象的await()方法后,我们的当前线程就会加入到一个特定的队列当中去等待,直到有调用了这个对象的notify()方法后才会从这个队列中抽取一个线程唤醒。
举个例子,我们去医院的时候,一个医生同一时间只能看一个病人,剩下的人都只能等待,如果只有一个大厅的话,看不同病的病人都只能等待在一个候诊室中。使用ReentrentLock的意思就是为了创建多个不同的候诊室,将不同医生的病人分开在不同的候诊室当中。
//1.阻塞队列
private Deque<T> deque = new ArrayDeque<>();
//2.实现阻塞的锁
private ReentrantLock lock = new ReentrantLock();
//3. 生产者等待条件
private Condition fullWaitSet = lock.newCondition();
//4.消费者等待条件
private Condition emptyWaitSet = lock.newCondition();
//5.阻塞队列的大小
private int CAPACITY;在自定义的阻塞队列中,我使用了一个双向队列来存储任务,并且设置了一个队列大小的属性,在我们创建这个队列的时候我们可以进行初始化。
先来看看阻塞队列任务的添加过程。这个逻辑并不难,我们在代码的上方上锁,在finally中解锁。如果这时我们的队列是满的,就无法在继续添加任务了,这个时候我们就把当前线程挂起(注意我们的挂起条件)。如果队列不是满的话那我们就加入到队尾,同时把另一类挂起的线程唤醒(这类线程在队列为空的时候挂起,等待任务的添加)。
// 生产者放入数据
public void put(T t) {
lock.lock();
try {
while (deque.size() == CAPACITY) {
fullWaitSet.await();
}
deque.addLast(t);
emptyWaitSet.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}在看看我们取任务的过程。同样加锁,当我们的队列为空的时候,线程挂起,等待任务的添加之后线程唤醒,如果队列不为空的话,我们从队列头部取出一个任务,并且唤起一类线程(这类线程在任务已经满了的时候无法在添加任务了,进行挂起,等待队列不为满)。
// 消费者从线程池当中获取任务
public T take(){
T t = null;
lock.lock();
try {
while(deque.size() == 0){
emptyWaitSet.await();
}
t = deque.removeFirst();
fullWaitSet.signal();
}catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
return t;
}我们上边的代码展示的队列的存取的过程都是死等状态,什么是死等状态?就是任务添加不进去或者取不出来的时候,线程会被一直挂起。真实并不是如此,这里只是简单的展示。
阻塞队列需要的就是这两个存取的过程。
2.ThreadPool
先看看线程池当中的属性。把刚才创建的任务队列加进去,因为线程池要时常和任务队列沟通。然后创建了一个HashSet结构用于存储我们的线程。下边的都是我们线程池需要的一些参数了,拒绝策略在这里没有写。
// 任务队列
private BlockedQueue<Runnable> taskQueue;
// 线程集合
private HashSet<Worker> workers = new HashSet<>();
//核心线程数
private int coreSize;
// 超时时间
private int timeout;
// 超时单位
private TimeUnit timeUnit;
来看看我们的线程池是如何工作的吧,可以看到我们线程池保存的是Worker对象,我们来看看这个Worker对象是干啥的。这个Worker对象实现了Runnable接口,我们可以把这个类当作线程类,这个类中有一个task属性,因为我们线程池当中的线程是要获取任务执行的,这个任务就用这个task属性代表。
这个Worker类一直在干一件事情,就是不断地从我们的任务队列当中获取任务(Worker类是ThreadPool的内部类),如果获取的任务不为空的话就执行任务,一旦没有任务可以执行那么就把当前的线程从线程池当中移除。
class Worker implements Runnable{
private Runnable task;
public Worker(Runnable task){
this.task = task;
}
@Override
public void run() {
while(task!=null || (task = taskQueue.take())!=null){
System.out.println("取出的任务是"+task);
try {
task.run();
}catch (Exception e){
e.printStackTrace();
}finally {
task = null;
}
synchronized (workers){
workers.remove(this);
}
}
}
}那什么时候用到这个Worker类呢?当我们调用ThreadPool中的execute()方法时,线程池中的线程会就调用这个run()方法。
来看我们的execute()方法。当我们的线程数小于我们的核心线程数的时候,我们可以直接创建一个新的线程,并且把我们的任务直接交给这个核心线程。反之我们不能创建,而是把任务添加到我们的任务队列当中,等待核心线程去执行这个任务。
// 任务执行
public void execute(Runnable task){
synchronized (workers){
if(workers.size() < coreSize){
// 创建核心线程
Worker worker = new Worker(task);
workers.add(worker);
Thread thread = new Thread(worker);
thread.start();
}else {
taskQueue.put(task);
}
}
}写完了上边的代码我们测试一下。
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(2,10,TimeUnit.MILLISECONDS,10);
for(int i = 0;i<12;i++){
int j = i;
threadPool.execute(()->{
System.out.println("当前线程"+Thread.currentThread().getName()+"task "+j+" is running");
try {
Thread.currentThread().sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
方法运行了之后,即使任务全部执行,线程也不会结束。这是因为我们的worker类中的run方法调用了任务队列的take()方法,而take方法是会一直挂起的。
我们现在换一种带超时获取,在规定时间内获取不到任务就自动结束任务。这时候就用到我们传入的时间参数了,我们不再调用await()方法了,而是调用awaitNanos()方法,方法可以接收一个时间参数,这个方法可以消耗我们的nanos时间,在这个时间内如果获取不到的话线程就不在挂起了,这时还会进入到我们的while循环当中,判断我们的nanos是不是被消耗完了,如果被消耗完了就说明在规定时间内获取不到任务,直接return结束线程。
// 带超时获取
public T poll(int timeout,TimeUnit timeUnit){
T t = null;
lock.lock();
try {
long nanos = timeUnit.toNanos(timeout);
while(deque.size() == 0){
if(nanos <= 0){
return null;
}
nanos = emptyWaitSet.awaitNanos(nanos);
}
t = deque.removeFirst();
fullWaitSet.signal();
}catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
return t;
}修改Worker类。
class Worker implements Runnable{
private Runnable task;
public Worker(Runnable task){
this.task = task;
}
@Override
public void run() {
while(task!=null || (task = taskQueue.poll(timeout,timeUnit))!=null){
System.out.println("取出的任务是"+task);
try {
task.run();
}catch (Exception e){
e.printStackTrace();
}finally {
task = null;
}
synchronized (workers){
workers.remove(this);
}
}
}
}
现在就可以正常结束了。
四、拒绝策略
全部代码如下。要使用拒绝策略,我们定义一个函数式接口,同时写一个参数传给线程池,参数的具体内容就是拒绝策略的拒绝方法,是我们自己定义的。
同时我们的execute()方法不在使用put来添加任务了,而是使用tryPut,如果大家对这一块感兴趣的话,可以在bilibili上观看黑马程序员的课程学习一下。
/**
* 自定义线程池
*/
public class TestPool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(2,10,TimeUnit.SECONDS,10,((queue, task) -> {queue.put(task);}));
for(int i = 0;i<12;i++){
int j = i;
threadPool.execute(()->{
System.out.println("当前线程"+Thread.currentThread().getName()+"task "+j+" is running");
try {
Thread.currentThread().sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
}
/**
* 拒绝策略
*/
@FunctionalInterface
interface RejectPolicy<T>{
void reject(BlockedQueue<T> queue,T task);
}
/**
* 阻塞队列
*/
class BlockedQueue <T>{
//1.阻塞队列
private Deque<T> deque = new ArrayDeque<>();
//2.实现阻塞的锁
private ReentrantLock lock = new ReentrantLock();
//3. 生产者等待条件
private Condition fullWaitSet = lock.newCondition();
//4.消费者等待条件
private Condition emptyWaitSet = lock.newCondition();
//5.阻塞队列的大小
private int CAPACITY;
public BlockedQueue(int queueCapacity) {
this.CAPACITY = queueCapacity;
}
// 生产者放入数据
public void put(T t) {
lock.lock();
try {
while (deque.size() == CAPACITY) {
fullWaitSet.await();
}
deque.addLast(t);
emptyWaitSet.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
// 带超时添加
public boolean offer(T t,int timeout,TimeUnit timeUnit) {
lock.lock();
long nanos = timeUnit.toNanos(timeout);
try {
while (deque.size() == CAPACITY) {
if(nanos <= 0){
return false;
}
nanos = fullWaitSet.awaitNanos(nanos);
}
deque.addLast(t);
emptyWaitSet.signal();
return true;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
return true;
}
// 带超时获取
public T poll(int timeout,TimeUnit timeUnit){
T t = null;
lock.lock();
try {
long nanos = timeUnit.toNanos(timeout);
while(deque.size() == 0){
if(nanos <= 0){
return null;
}
nanos = emptyWaitSet.awaitNanos(nanos);
}
t = deque.removeFirst();
fullWaitSet.signal();
}catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
return t;
}
// 消费者从线程池当中获取任务
public T take(){
T t = null;
lock.lock();
try {
while(deque.size() == 0){
emptyWaitSet.await();
}
t = deque.removeFirst();
fullWaitSet.signal();
}catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
return t;
}
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try {
if(deque.size()==CAPACITY){
rejectPolicy.reject(this,task);
}else{
deque.addLast(task);
emptyWaitSet.signal();
}
} finally {
lock.unlock();
}
}
}
/**
* 线程池
*/
class ThreadPool{
// 任务队列
private BlockedQueue<Runnable> taskQueue;
// 线程集合
private HashSet<Worker> workers = new HashSet<>();
//核心线程数
private int coreSize;
// 超时时间
private int timeout;
// 超时单位
private TimeUnit timeUnit;
//拒绝策略
private RejectPolicy<Runnable> rejectPolicy;
// 任务执行
public void execute(Runnable task){
synchronized (workers){
if(workers.size() < coreSize){
// 创建核心线程
Worker worker = new Worker(task);
workers.add(worker);
Thread thread = new Thread(worker);
thread.start();
}else {
// 任务队列
//taskQueue.offer(task,timeout,timeUnit);
taskQueue.tryPut(rejectPolicy,task);
//taskQueue.put(task);
}
}
}
public ThreadPool(int coreSize, int timeout, TimeUnit timeUnit,int queueCapacity,RejectPolicy<Runnable> rejectPolicy){
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockedQueue<>(queueCapacity);
this.rejectPolicy = rejectPolicy;
}
class Worker implements Runnable{
private Runnable task;
public Worker(Runnable task){
this.task = task;
}
@Override
public void run() {
while(task!=null || (task = taskQueue.poll(timeout,timeUnit))!=null){
System.out.println("取出的任务是"+task);
try {
task.run();
}catch (Exception e){
e.printStackTrace();
}finally {
task = null;
}
synchronized (workers){
workers.remove(this);
}
}
}
}
}这个代码我自己觉得是有些问题,因为如果我的任务队列大小有10的时候,我给出了13个任务,两个交给核心线程不占任务队列大小,另外10个任务正好占满,剩下一个放不进去,这时就会卡住不输出。---------未解决

![new[]与delete[]](https://img-blog.csdnimg.cn/direct/538e525a35a44247871b720b4983e301.png)