文章目录
- MyBatis
- 其他查询操作
- 多表查询
- #{} 和 ${}
- 排序功能
- like 查询
- #{} 和 ${} 的区别
- 数据库连接池
MyBatis
其他查询操作
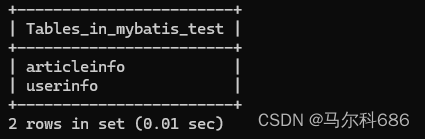
创建表:
-- 创建⽂章表
DROP TABLE IF EXISTS articleinfo;
CREATE TABLE articleinfo (
id INT PRIMARY KEY auto_increment,
title VARCHAR ( 100 ) NOT NULL,
content TEXT NOT NULL,
uid INT NOT NULL,
delete_flag TINYINT ( 4 ) DEFAULT 0 COMMENT '0-正常, 1-删除',
create_time DATETIME DEFAULT now(),
update_time DATETIME DEFAULT now()
) DEFAULT charset 'utf8mb4';
-- 插⼊测试数据
INSERT INTO articleinfo ( title, content, uid ) VALUES ( 'Java', 'Java正⽂', 1
);

多表查询
对应model:
SQL中直接查询多个表,把查询的结果放在一个对象即可。
package com.example.demo.model;
import lombok.Data;
import java.util.Date;
@Data
public class ArticleInfo {
private Integer id;
private String title;
private String content;
private Integer uid;
private Integer deleteFlag;
private Date createTime;
private Date updateTime;
//用户相关信息
private String username;
private Integer age;
}
SQL
select ta.*, tb.username,tb.age from articleinfo ta
left join userinfo tb on ta.uid = tb.id
where ta.id = 1
这是一个拼接的SQL查询语句,用于从两个数据表articleinfo和userinfo中检索数据。下面是对这个查询语句的逐步解释:
- 选择字段:
select ta.*, tb.username, tb.age
这部分表示选择articleinfo表中的所有字段(ta.*),以及userinfo表中的username和age字段。ta和tb是这两个表的别名,用于简化后续的查询。
- 连接表:
from articleinfo ta
left join userinfo tb on ta.uid = tb.id
这里使用左连接(left join)将articleinfo表(别名为ta)和userinfo表(别名为tb)连接在一起。连接的条件是articleinfo表中的uid字段等于userinfo表中的id字段。左连接意味着即使userinfo表中没有与articleinfo表匹配的记录,articleinfo表中的记录仍然会被选择出来,但userinfo表的字段将为NULL。
- 筛选条件:
where ta.id = 1
这部分是查询的筛选条件,它指定只选择那些articleinfo表中id字段等于1的记录。
所以,整个查询的意思是:从articleinfo表中选择id为1的记录,并左连接userinfo表,获取与articleinfo表中uid字段相匹配的userinfo表中的username和age字段。如果没有匹配的userinfo记录,这些字段将为NULL。
注意:在拼接SQL语句时,应该小心处理字符串的连接,以避免SQL注入等安全问题。在实际应用中,推荐使用预编译的SQL语句来确保安全。此外,SQL语句的拼接最好使用空格或其他适当的分隔符,以确保生成的SQL语法正确。在这个例子中,虽然拼接看起来是连续的,但在实际编程中,可能需要确保字符串连接后没有多余的空格或缺少必要的空格。
/**
* 多表查询
* @param articleId
* @return
*/
@Select("select ta.*, tb.username,tb.age from articleinfo ta" +
" left join userinfo tb on ta.uid = tb.id" +
" where ta.id = 1")
ArticleInfo selectArticleAndUserById(Integer articleId);
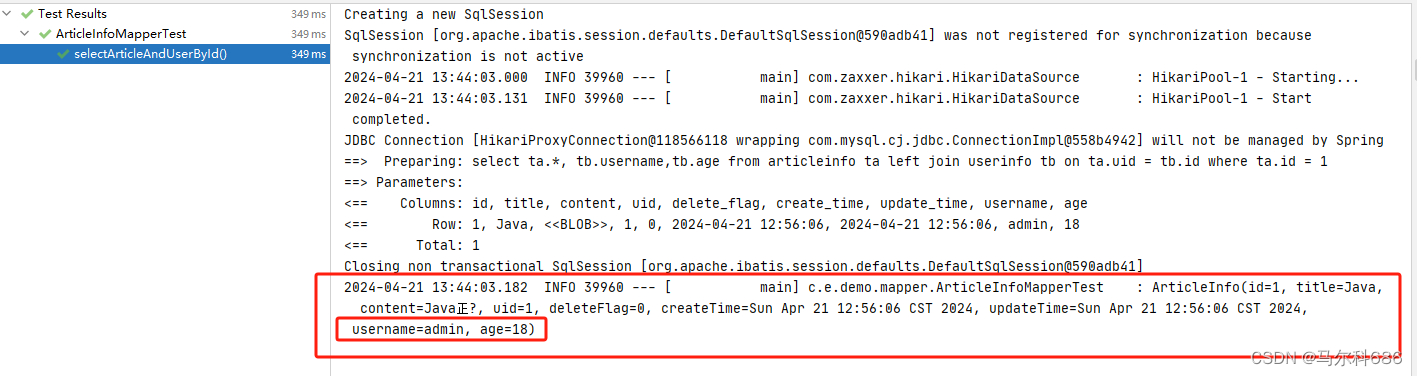
测试用例:
@Test
void selectArticleAndUserById() {
ArticleInfo articleInfo = articleInfoMapper.selectArticleAndUserById(1);
log.info(articleInfo.toString());
}
#{} 和 ${}
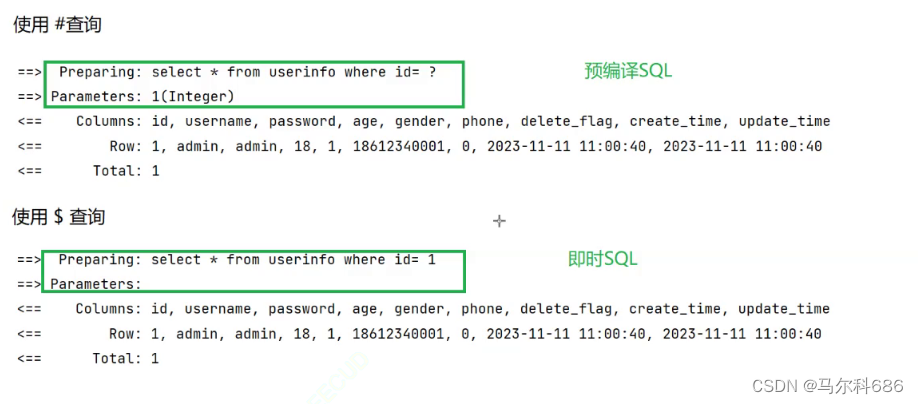
使用#{}查询:
@ResultMap(value = "BaseMap")
@Select("select * from userinfo where id= #{id}")
UserInfo selectOne(Integer id);

使用${}查询:
@ResultMap(value = "BaseMap")
@Select("select * from userinfo where id= ${id}")
UserInfo selectOne(Integer id);

看下面的例子:
使用#{}查询(通过username):
@ResultMap(value = "BaseMap")
@Select("select * from userinfo where username= #{username}")
UserInfo selectByName(String username);
查询:
@Test
void selectByName() {
log.info(userInfoMapper.selectByName("admin").toString());
}

使用${}查询(通过username):
@ResultMap(value = "BaseMap")
@Select("select * from userinfo where username= ${username}")
UserInfo selectByName(String username);
查询:
@Test
void selectByName() {
log.info(userInfoMapper.selectByName("admin").toString());
}

程序直接报错了,若想要正确运行,需要给${username}处加单引号。
@ResultMap(value = "BaseMap")
@Select("select * from userinfo where username= '${username}'")
UserInfo selectByName(String username);

此时就可以运行成功了。

使用#{}时,如果参数为String,会自动加上'',而 ${}不会,${}符号是直接拼接,如果是字符串类型,需要加上''
SQL注⼊:是通过操作输⼊的数据来修改事先定义好的SQL语句,以达到执行代码对服务器进⾏攻击的⽅法。
正常的sql:
select * from userinfo where username= 'admin'
sql 注⼊代码: ' or 1='1
select * from userinfo where username ='' or 1='1';

select * from userinfo where username ='' or 1='1'; 这条SQL查询语句存在严重的安全风险,是一个典型的SQL注入示例。这条语句试图从userinfo表中选择所有记录,无论username字段的值是什么。
解释如下:
-
select * from userinfo:这部分表示从userinfo表中选择所有字段。 -
where username ='':这部分是查询的条件,原本意图是选择username字段为空字符串的记录。 -
or 1='1':这部分是问题的关键。or表示逻辑或,1='1'是一个恒真的条件(因为1永远等于1)。因此,不论username字段的值是什么,只要or 1='1'这一部分存在,整个查询都会返回userinfo表中的所有记录。
SQL注入的例子:
@ResultMap(value = "BaseMap")
@Select("select * from userinfo where username= '${username}'")
List<UserInfo> selectByName(String username);
测试:
@Test
void selectByName() {
log.info(userInfoMapper.selectByName("' or 1='1").toString());
}

我们发现数据居然查询出来了,这就验证了sql注入的问题。

使用#{}查询:
@ResultMap(value = "BaseMap")
@Select("select * from userinfo where username= #{username}")
List<UserInfo> selectByName(String username);
测试;
@Test
void selectByName() {
log.info(userInfoMapper.selectByName("' or 1='1").toString());
}
查出来结果是0

排序功能
进行一个升序查询:
/**
*
* @param sort
* @return
*/
@Select("select * from userinfo order by id #{sort}")
List<UserInfo> selectUserSort(String sort);
@Test
void selectUserSort() {
log.info(userInfoMapper.selectUserSort("asc").toString());
}

#{sort}在MyBatis中是用来绑定参数值的,而不是直接拼接到SQL语句中的。如果这样写,MyBatis会尝试将sort作为一个参数的值去绑定,而不是将其当作SQL语句的一部分。
正确的做法是使用${}来直接插入变量到SQL语句中。
/**
*
* @param sort
* @return
*/
@Select("select * from userinfo order by id ${sort}")
List<UserInfo> selectUserSort(String sort);
注意,这样做会有SQL注入的风险,因为${}中的内容是直接拼接到SQL语句中的,不会经过MyBatis的预编译处理。如果sort变量来自不可信的来源,那么这可能会引发安全问题。
如果信任sort变量的来源(例如,它只来自一个固定的枚举或已知的安全值集合),可以这样写:
@Select("select * from userinfo order by id ${sort}")
List<UserInfo> selectUserSort(@Param("sort") String sort);
在上面的代码中,@Param("sort")注解用来指定传递给SQL的参数名称,这样MyBatis就知道sort变量是对应到SQL语句中的${sort}部分的。
like 查询
like 使⽤ #{} 报错
@Select("select id, username, age, gender, phone, delete_flag, create_time, update_time " +
"from userinfo where username like '%#{key}%' ")
List<UserInfo> queryAllUserByLike(String key);
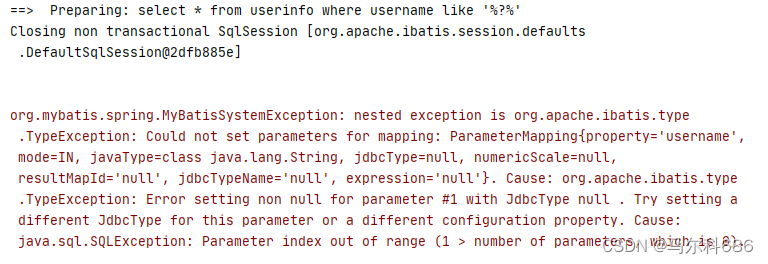
把 #{} 改成 ${} 可以正确查出来,
@Select("select * from userinfo where username like '%${username}%'")
List<UserInfo> selectUserByLike(String username);

@Test
void selectUserByLike() {
log.info(userInfoMapper.selectUserByLike("java").toString());
}
但是${}存在SQL注⼊的问题, 所以不能直接使⽤${}.
解决办法: 使⽤ mysql 的内置函数 concat() 来处理:
@Select("select id, username, age, gender, phone, delete_flag, create_time, update_time " +
"from userinfo where username like concat('%',#{key},'%')")
List<UserInfo> queryAllUserByLike(String key);
#{} 和 ${} 的区别
#{} 和 ${} 的区别就是预编译SQL和即时SQL 的区别.
1. 预编译SQL#{} 性能更高。
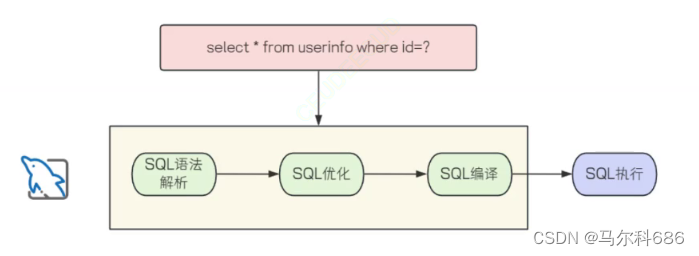
大多数情况下, 某⼀条 SQL 语句可能会被反复调用执行, 或者每次执⾏的时候只有个别的值不同(比如select 的 where⼦句值不同, update 的 set 子句值不同, insert 的 values 值不同). 如果每次都需要经过上⾯的语法解析, SQL优化、SQL编译等,则效率就明显不行了
预编译SQL,编译⼀次之后会将编译后的SQL语句缓存起来,后⾯再次执⾏这条语句时,不会再次编译(只是输⼊的参数不同), 省去了解析优化等过程, 以此来提高效率。
2. 预编译SQL${}不存在SQL注入的问题。
3. 排序时不能使用#{},表名,字段名等作为参数时,也不能使用#{}
4. 模糊查询时,如果使用#{},需要搭配mysql的内置函数concat,而不能直接使用。
数据库连接池
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用⼀个现有的数据库连接,而不是再重新建立⼀个.
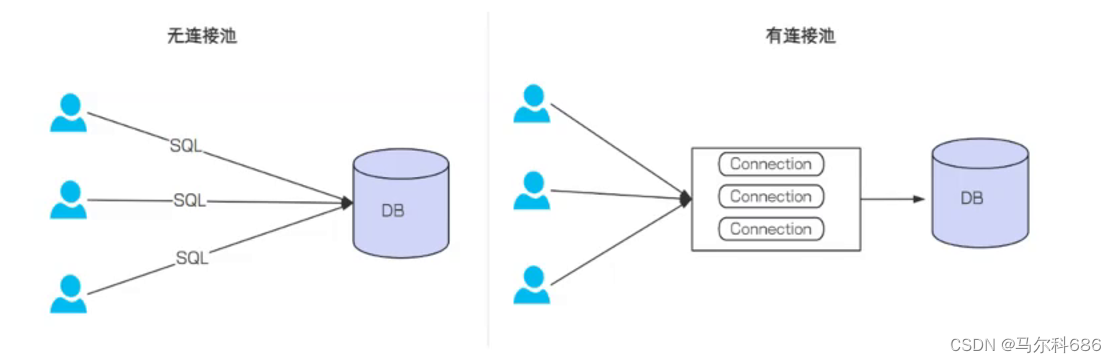
没有使⽤数据库连接池的情况: 每次执行SQL语句, 要先创建⼀个新的连接对象, 然后执⾏SQL语句, SQL语句执行完, 再关闭连接对象释放资源. 这种重复的创建连接, 销毁连接比较消耗资源。
使用数据库连接池的情况: 程序启动时, 会在数据库连接池中创建⼀定数量的Connection对象, 当客户请求数据库连接池, 会从数据库连接池中获取Connection对象, 然后执行SQL, SQL语句执⾏完, 再把Connection归还给连接池。
常见的数据库连接池:
C3P0DBCPDruidHikari
目前比较流⾏的是 Hikari, Druid
- Hikari
SpringBoot默认使⽤的数据库连接池就是Hikari

- Druid
切换为Druid数据库连接池, 只需要引⼊相关依赖即可
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.17</version>
</dependency>