数据对齐是一种安排数据分配方式以加速 CPU 访问内存的方法。 不了解这个概念会导致额外的内存消耗甚至性能下降。
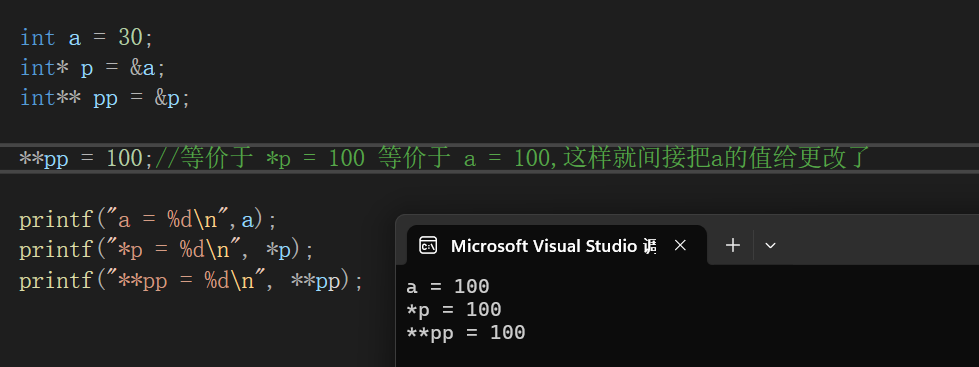
要了解数据对齐的工作原理,让我们首先讨论没有它会发生什么。假设我们分配两个变量,一个 int32 类型的 (32 B) 和一个 int64类型的(64 B):
var i int32
var j int64在没有数据对齐的情况下,在 64 位架构上,这两个变量的分配方式如下图所示,j 变量可以被分配在两个字上。 如果 CPU 想要读取 j,它需要两次内存访问而不是一次。

为了防止发生这种情况,变量的内存地址应该是其自身大小的倍数,这就是数据对齐的概念。在 Go 中,对齐可保证如下事项:
- byte, uint8, int8: 占用 1 B
- uint16, int16: 占用 2 B
- uint32, int32, float32: 占用 4 B
- uint64, int64, float64, complex64: 占用 8 B
- complex128: 占用 16 B
所有这些类型都保证对齐的方式: 它们的地址是它们大小的倍数。例如,任何 int32 类型的变量的地址都是 4 的倍数。
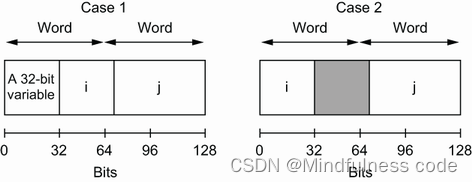
让我们回到现实世界。下图显示了 i 和 j 在内存中分配的两种不同情况。
在第一种情况下,在 i 之前分配了一个 32 位的变量。因此, i 和 j 是连续分配的。在第二种情况下, 32 位的变量在 i 之前没有被分配 (比如是 64 位的变量); 所以,i 被分配在一个字的开头。为了遵循从数据对齐 (地址是 64 的倍数),j 不能与 i 一起被分配,而是被分配给下一个 64 的倍数。 灰色框表示 32 位的填充。
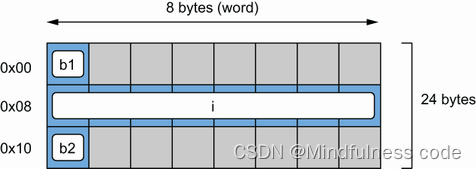
接下来,让我们看看填充何时会成为问题。我们将考虑以下包含三个字段的结构:
type Foo struct {
b1 byte
i int64
b2 byte
}我们有一个字节类型(1 B)、一个 int64 (8 B)类型和另一个字节类型 (1 B)。在64位架构上,结构体在内存中的分配如下图所示。b1 首先被分配。因为 i 是一个 int64 类型的,它的地址必须是 8 的倍数。因此,不可能将它与 b1 一起分配在 0x01 。 8的倍数的下一个地址是什么?0x08。b2 被分配给下一个可用地址,它是 1 的倍数:0x10。


![[阅读笔记16][Orca-2]Teaching Small Language Models How to Reason](https://img-blog.csdnimg.cn/direct/3162f310f55a47a08334d07cac3f2f8a.png)