1不相交的线
在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数。
现在,可以绘制一些连接两个数字 nums1[i] 和 nums2[j] 的直线,这些直线需要同时满足:
-
nums1[i] == nums2[j] - 且绘制的直线不与任何其他连线(非水平线)相交。
请注意,连线即使在端点也不能相交:每个数字只能属于一条连线。
以这种方法绘制线条,并返回可以绘制的最大连线数。
示例 1:
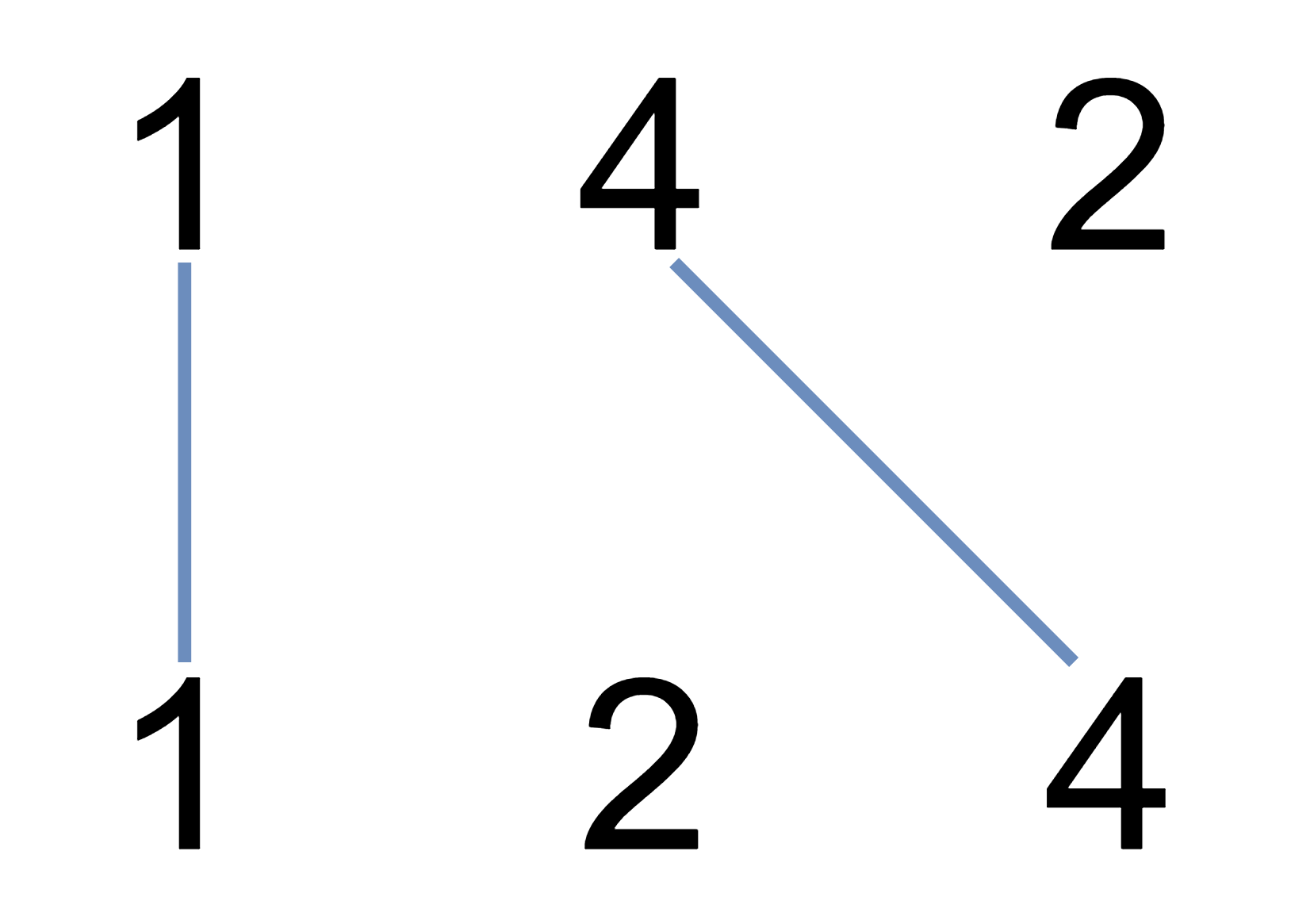
输入:nums1 = [1,4,2], nums2 = [1,2,4] 输出:2 解释:可以画出两条不交叉的线,如上图所示。 但无法画出第三条不相交的直线,因为从 nums1[1]=4 到 nums2[2]=4 的直线将与从 nums1[2]=2 到 nums2[1]=2 的直线相交。
示例 2:
输入:nums1 = [2,5,1,2,5], nums2 = [10,5,2,1,5,2] 输出:3
示例 3:
输入:nums1 = [1,3,7,1,7,5], nums2 = [1,9,2,5,1] 输出:2
提示:
1 <= nums1.length, nums2.length <= 5001 <= nums1[i], nums2[j] <= 2000
思路:
绘制一些连接两个数字 A[i] 和 B[j] 的直线,只要 A[i] == B[j],且直线不能相交!
直线不能相交,这就是说明在字符串A中 找到一个与字符串B相同的子序列,且这个子序列不能改变相对顺序,只要相对顺序不改变,链接相同数字的直线就不会相交。拿示例nums1 = [1,4,2], nums2 = [1,2,4]为例,相交情况如图: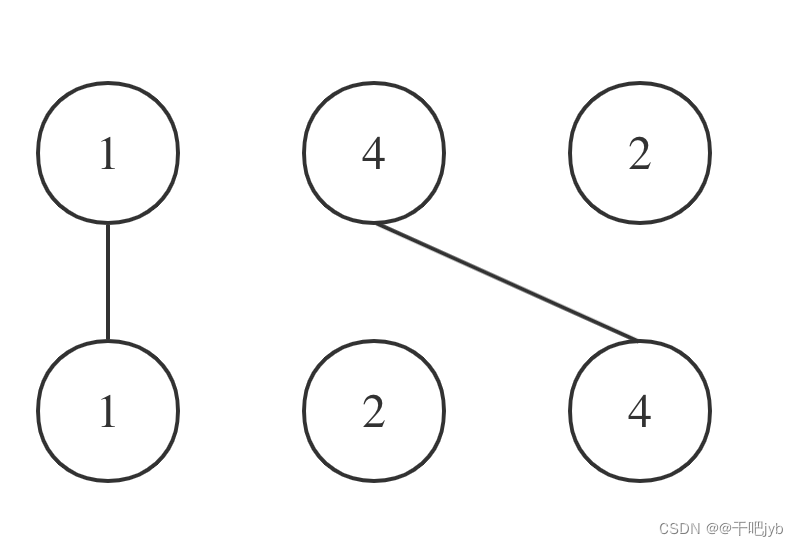
其实也就是说nums1和nums2的最长公共子序列是[1,4],长度为2。 这个公共子序列指的是相对顺序不变(即数字4在字符串A中数字1的后面,那么数字4也应该在字符串B数字1的后面)
这么分析完之后,大家可以发现:本题说是求绘制的最大连线数,其实就是求两个字符串的最长公共子序列的长度!
首先,我们可以定义一个二维数组 dp,其中 dp[i][j] 表示 nums1 的前 i 个数字和 nums2 的前 j 个数字所能组成的最大不相交连线数。
然后,我们可以考虑状态转移方程。当 nums1[i-1] == nums2[j-1] 时,说明 nums1 的第 i 个数字和 nums2 的第 j 个数字可以连线,此时最大连线数为 dp[i-1][j-1] + 1。否则,说明 nums1[i-1] 和 nums2[j-1] 不能连线,那么最大连线数为 max(dp[i-1][j], dp[i][j-1]),即不考虑当前这对数字时的最大连线数。
最后,我们遍历 nums1 和 nums2 的所有组合情况,计算得到 dp[nums1.size()][nums2.size()]即为所求的结果
代码:
class Solution {
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {
// 创建二维动态规划数组,大小为 nums1.size()+1 行,nums2.size()+1 列,初始化为0
vector<vector<int>> dp(nums1.size() + 1, vector<int>(nums2.size() + 1, 0));
// 遍历 nums1 和 nums2 的所有组合情况
for (int i = 1; i <= nums1.size(); i++) {
for (int j = 1; j <= nums2.size(); j++) {
if (nums1[i - 1] == nums2[j - 1]) {
// 当 nums1[i-1] 和 nums2[j-1] 相等时,更新 dp[i][j] 为左上角值加一
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// 否则,更新 dp[i][j] 为上方和左方值的较大者
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 返回最终结果,即 dp[nums1.size()][nums2.size()]
return dp[nums1.size()][nums2.size()];
}
};2 最大子数组和
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组
是数组中的一个连续部分。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4] 输出:6 解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
输入:nums = [1] 输出:1
示例 3:
输入:nums = [5,4,-1,7,8] 输出:23
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 104
思路:
首先,我们定义一个动态规划数组 dp,其中 dp[i] 表示以 nums[i] 结尾的子数组的最大和。
然后,我们考虑状态转移方程。对于数组中的第 i 个元素 nums[i],我们有两种选择:要么将其加入前面的子数组,形成一个新的子数组;要么将其作为新的起点,重新开始一个新的子数组。因此
1 dp[i]只有两个方向可以推出来:
- dp[i - 1] + nums[i],即:nums[i]加入当前连续子序列和
- nums[i],即:从头开始计算当前连续子序列和
一定是取最大的,所以dp[i] = max(dp[i - 1] + nums[i], nums[i]);
这个方程的含义是,要么当前元素加上前一个元素的子数组和构成了一个更大的子数组,要么当前元素本身构成了一个新的子数组。我们选择其中较大的那个作为 dp[i] 的值。
2 dp数组如何初始化
从递推公式可以看出来dp[i]是依赖于dp[i - 1]的状态,dp[0]就是递推公式的基础。
dp[0]应该是多少呢?
根据dp[i]的定义,很明显dp[0]应为nums[0]即dp[0] = nums[0]。
3 确定遍历顺序
递推公式中dp[i]依赖于dp[i - 1]的状态,需要从前向后遍历。
代码:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
// 如果数组为空,则直接返回0
if (nums.size() == 0) return 0;
// 创建动态规划数组,大小为 nums.size(),用于存储最大子数组和
vector<int> dp(nums.size());
dp[0] = nums[0]; // 初始化动态规划数组的第一个元素为数组的第一个元素
int result = dp[0]; // 用于存储最大子数组和的变量,初始化为数组的第一个元素
// 遍历数组,计算最大子数组和
for (int i = 1; i < nums.size(); i++) {
// 状态转移公式:当前元素加上前一个元素的动态规划值,或者当前元素本身,取两者中的较大值
dp[i] = max(dp[i - 1] + nums[i], nums[i]);
// 更新最大子数组和的值
if (dp[i] > result) result = dp[i];
}
// 返回最终的最大子数组和
return result;
}
};3 判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, ... , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
致谢:
特别感谢 @pbrother 添加此问题并且创建所有测试用例。
示例 1:
输入:s = "abc", t = "ahbgdc" 输出:true
示例 2:
输入:s = "axc", t = "ahbgdc" 输出:false
双指针思路:
- 定义两个指针
i和j,分别用于遍历两个序列nums1和nums2。 - 初始时,
i和j都指向两个序列的起始位置。 - 在遍历过程中,比较
nums1[i]和nums2[j]是否相等。 - 如果相等,则将
j移动到nums2的下一个位置。 - 无论是否相等,都将
i移动到nums1的下一个位置。 - 当遍历完
nums1或者nums2中的任意一个时,停止遍历。 - 如果
j已经达到nums2的末尾,则说明nums2是nums1的子序列,返回true。 - 如果遍历完
nums1后,j还没有到达nums2的末尾,则说明nums2不是nums1的子序列,返回false。
代码:
#include <vector>
class Solution {
public:
bool isSubsequence(std::vector<int>& nums1, std::vector<int>& nums2) {
int i = 0, j = 0;
int n = nums1.size();
int m = nums2.size();
// 遍历 nums1
while (i < n && j < m) {
// 如果 nums1[i] 与 nums2[j] 相等
if (nums1[i] == nums2[j]) {
// 移动 nums2 的指针
j++;
}
// 无论是否匹配,nums1 的指针都移动到下一个位置
i++;
}
// 如果 nums2 的指针到达末尾,则 nums2 是 nums1 的子序列
return j == m;
}
};动态规划思路:
确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
注意这里是判断s是否为t的子序列。即t的长度是大于等于s的。
然后,我们初始化动态规划数组 dp 的大小为 (s.size() + 1) * (t.size() + 1),并将所有元素初始化为 0。接着,我们遍历字符串 s 和 t 的所有字符,外层循环遍历 s 的每个字符,内层循环遍历 t 的每个字符。
在遍历过程中,如果 s 的第 i 个字符等于 t 的第 j 个字符,则说明找到了一个相同的字符,此时 dp[i][j] 的值为 dp[i - 1][j - 1] + 1,表示将该字符加入子序列中。如果 s 的第 i 个字符不等于 t 的第 j 个字符,则说明当前字符不能加入子序列,此时 dp[i][j] 的值为 dp[i][j - 1],表示不将该字符加入子序列中。
具体推出递推公式思路如下:
- if (s[i - 1] == t[j - 1])
- t中找到了一个字符在s中也出现了
- if (s[i - 1] != t[j - 1])
- 相当于t要删除元素,继续匹配
- if (s[i - 1] == t[j - 1]),那么dp[i][j] = dp[i - 1][j - 1] + 1;,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1
- if (s[i - 1] != t[j - 1]),此时相当于t要删除元素,t如果把当前元素t[j - 1]删除,那么dp[i][j] 的数值就是 看s[i - 1]与 t[j - 2]的比较结果了,即:dp[i][j] = dp[i][j - 1];
遍历完成后,如果 dp[s.size()][t.size()] 的值等于 s 的长度,则说明 s 是 t 的子序列,返回 true;否则返回 false。
代码:
#include <vector>
#include <string>
class Solution {
public:
// 判断字符串 s 是否是字符串 t 的子序列
bool isSubsequence(string s, string t) {
// 创建二维动态规划数组,dp[i][j] 表示 s 的前 i 个字符是否是 t 的前 j 个字符的子序列
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
// 遍历 s 和 t 的所有字符
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
// 如果 s 的第 i 个字符等于 t 的第 j 个字符
if (s[i - 1] == t[j - 1]) {
// 则 s 的前 i 个字符作为 t 的前 j 个字符的子序列的长度加一
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// 否则,s 的前 i 个字符作为 t 的前 j 个字符的子序列的长度与之前的相同
dp[i][j] = dp[i][j - 1];
}
}
}
// 如果 s 的所有字符都是 t 的子序列,则返回 true,否则返回 false
if (dp[s.size()][t.size()] == s.size()) {
return true;
}
return false;
}
};4不同的子序列
给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数,结果需要对 109 + 7 取模。
示例 1:
输入:s = "rabbbit", t = "rabbit"输出:3解释: 如下所示, 有 3 种可以从 s 中得到"rabbit" 的方案。rabbbitrabbbitrabbbit
示例 2:
输入:s = "babgbag", t = "bag"输出:5解释: 如下所示, 有 5 种可以从 s 中得到"bag" 的方案。babgbagbabgbagbabgbagbabgbagbabgbag
提示:
1 <= s.length, t.length <= 1000s和t由英文字母组成
动态规划思路:
-
定义
dp[i][j]为以s的第i-1个字符结尾的子序列中出现以t的第j-1个字符结尾的子序列的个数。 -
初始状态:
- 当
t为空字符串时,s的任何子串都可以与之匹配,因此dp[i][0] = 1。 - 当
s为空字符串时,无论t如何都无法匹配,因此dp[0][j] = 0。这一步其实在代码中被默认初始化为 0,因此省略了这一步的实际操作。
- 当
-
状态转移方程:
- 当
s[i - 1] == t[j - 1]时,即s的第i-1个字符与t的第j-1个字符相等,此时dp[i][j]可以由两部分得到:- 不考虑
s[i-1]和t[j-1]的情况,即dp[i-1][j]。 - 考虑
s[i-1]和t[j-1]的情况,即dp[i-1][j-1]。因为此时s的第i-1个字符与t的第j-1个字符匹配,所以这种情况下dp[i][j]的数量应该加上以s的第i-2个字符结尾的子序列中以t的第j-2个字符结尾的子序列的数量。 -
还要考虑 不用s[i - 1]来匹配,都相同了指定要匹配啊。
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
- 不考虑
- 当
s[i - 1] != t[j - 1]时,即s的第i-1个字符与t的第j-1个字符不相等,此时dp[i][j]只能由dp[i-1][j]得到。当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i - 1][j]
所以递推公式为:dp[i][j] = dp[i - 1][j];
- 当
-
最后返回
dp[s.size()][t.size()],即s和t的完全匹配的子序列数量。
代码:
class Solution {
public:
int numDistinct(string s, string t) {
// 创建一个二维向量 dp,用于存储状态
vector<vector<uint64_t>> dp(s.size() + 1, vector<uint64_t>(t.size() + 1));
// 初始化 dp,当 t 为空字符串时,s 的子串都可以与 t 匹配,所以为 1
for (int i = 0; i < s.size(); i++) dp[i][0] = 1;
// 当 s 为空字符串时,无论 t 如何都不能匹配,所以为 0(默认初始化时已为 0,此处可省略)
for (int j = 1; j < t.size(); j++) dp[0][j] = 0;
// 动态规划计算
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
// 如果 s 的第 i 个字符等于 t 的第 j 个字符
if (s[i - 1] == t[j - 1]) {
// 当前状态可以由前一个状态和前一个状态减去 s 的第 i 个字符 的状态得到
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
// 当前状态可以由前一个状态得到
dp[i][j] = dp[i - 1][j];
}
}
}
// 返回 s 和 t 的匹配数
return dp[s.size()][t.size()];
}
};




![OpenHarmony其他工具类—libharu [GN编译]](https://img-blog.csdnimg.cn/img_convert/48b1e7eff01309fe163e3e6dcf6fba55.webp?x-oss-process=image/format,png)