1. 从github下载目录文件
https://github.com/meta-llama/llama3
使用git下载或者直接从github项目地址下载压缩包文件
git clone https://github.com/meta-llama/llama3.git
2.申请模型下载链接
到Meta Llama website填写表格申请,国家貌似得填写外国,组织随便填写即可

3.安装依赖
在Llama3最高级目录执行以下命令(建议在安装了python的conda环境下执行)
pip install -e .
4.下载模型
执行以下命令
bash download.sh
根据提示输出邮件里的链接,选择想要的模型,我这里选的是8B-instruct,注意要确保自己的显存足够模型推理
 开始下载之后要等待一段时间才能下载完成
开始下载之后要等待一段时间才能下载完成
5. 运行示例脚本
执行以下命令:
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir Meta-Llama-3-8B-Instruct/ \
--tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model \
--max_seq_len 512 --max_batch_size 6
有以下一些对话的示例输出
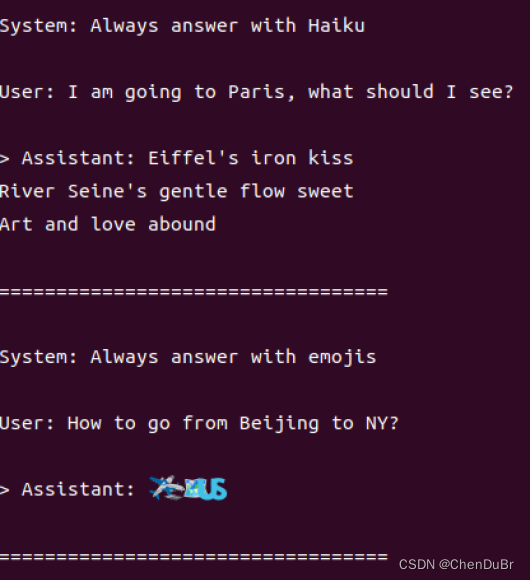
运行自己的对话脚本
在主目录下创建以下chat.py脚本
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed in accordance with the terms of the Llama 3 Community License Agreement.
from typing import List, Optional
import fire
from llama import Dialog, Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 512,
max_batch_size: int = 4,
max_gen_len: Optional[int] = None,
):
"""
Examples to run with the models finetuned for chat. Prompts correspond of chat
turns between the user and assistant with the final one always being the user.
An optional system prompt at the beginning to control how the model should respond
is also supported.
The context window of llama3 models is 8192 tokens, so `max_seq_len` needs to be <= 8192.
`max_gen_len` is optional because finetuned models are able to stop generations naturally.
"""
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
# Modify the dialogs list to only include user inputs
dialogs: List[Dialog] = [
[{"role": "user", "content": ""}], # Initialize with an empty user input
]
# Start the conversation loop
while True:
# Get user input
user_input = input("You: ")
# Exit loop if user inputs 'exit'
if user_input.lower() == 'exit':
break
# Append user input to the dialogs list
dialogs[0][0]["content"] = user_input
# Use the generator to get model response
result = generator.chat_completion(
dialogs,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)[0]
# Print model response
print(f"Model: {result['generation']['content']}")
if __name__ == "__main__":
fire.Fire(main)
运行以下命令就可以开始对话辣:
torchrun --nproc_per_node 1 chat.py --ckpt_dir Meta-Llama-3-8B-Instruct/ --tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model --max_seq_len 512 --max_batch_size 6
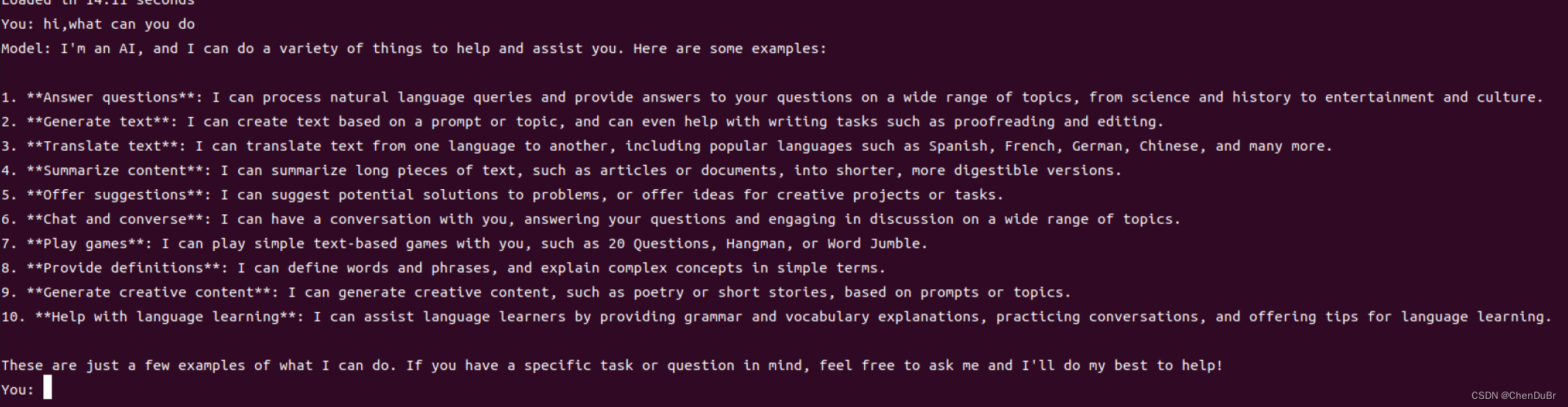
实现多轮对话
Mchat.py脚本如下:
from typing import List, Optional
import fire
from llama import Dialog, Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 512,
max_batch_size: int = 4,
max_gen_len: Optional[int] = None,
):
"""
Run chat models finetuned for multi-turn conversation. Prompts should include all previous turns,
with the last one always being the user's.
The context window of llama3 models is 8192 tokens, so `max_seq_len` needs to be <= 8192.
`max_gen_len` is optional because finetuned models are able to stop generations naturally.
"""
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
dialogs: List[Dialog] = [[]] # Start with an empty dialog
while True:
user_input = input("You: ")
if user_input.lower() == 'exit':
break
# Update the dialogs list with the latest user input
dialogs[0].append({"role": "user", "content": user_input})
# Generate model response using the current dialog context
result = generator.chat_completion(
dialogs,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)[0]
# Print model response and add it to the dialog
model_response = result['generation']['content']
print(f"Model: {model_response}")
dialogs[0].append({"role": "system", "content": model_response})
if __name__ == "__main__":
fire.Fire(main)
运行以下命令就可以开始多轮对话辣:
调整--max_seq_len 512 的值可以增加多轮对话模型的记忆长度,不过需要注意的是这可能会增加模型运算的时间和内存需求。
torchrun --nproc_per_node 1 Mchat.py --ckpt_dir Meta-Llama-3-8B-Instruct/ --tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model --max_seq_len 512 --max_batch_size 6

开始好好玩耍吧 !