广告投放是深度模型应用较为普遍的场景之一,虽然深度模型能够提升业务效果,但往往也会付出更加高额的耗时开销。滴滴现今 DSP(Demand-Side Platform) 业务场景中,耗时问题已然成为限制模型发挥的魔咒,为了打破魔咒,我们探索了一套解决方案,可以让深度模型极大限度摆脱耗时困扰。
原理概述
背景
DSP 先前的线上深度模型基于 CPU + Tensorflow Feature Column 的方式实现,借助 Tensorflow 框架和 Feature Column 的结构化数据处理能力以快速构建深度模型。该方式带来便利的同时,也会牺牲推理性能,随着业务策略迭代日趋深入,性能问题也愈发凸显。
DSP 参竞链路有着严格的耗时要求,策略模型筛选素材并给出最终结果的 P99 耗时需要控制在 40ms 内。当前精排模型 P99 耗时已经超过 30ms,超过 75% 的计算都消耗在精排阶段,其导致 DSP 链路上各个阶段都难以开展优化。
DSP 系统各部分理想情况下的耗时:
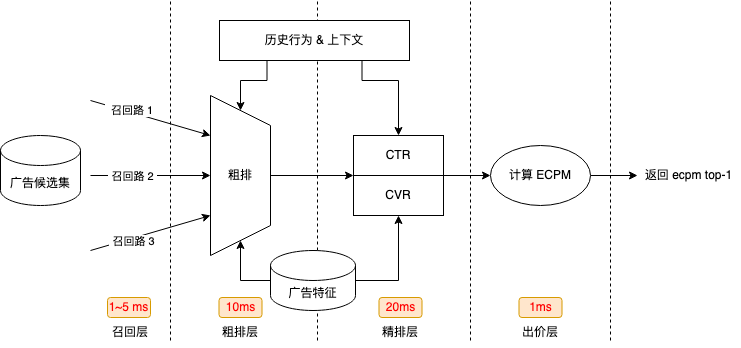
在排除网络开销和模型本身问题后,我们发现耗时主要消耗在计算上,因此尝试切换 GPU 进行计算以提高计算性能。单纯的计算场景下 GPU 的确拥有更高的性能,但是用于 Tensorflow 模型推理,耗时却不降反增,经过深入分析,我们发现问题出在了 Feature Column 上。
由于硬件架构差异,Feature Column 特征处理无法完全在 GPU 上进行,部分特征处理过程会被转到 CPU 上,设备之间切换反而会影响整体性能, 其中部分字符串转换操作还会涉及到内存复制与分配,尤为耗时。
降低耗时的核心是分离模型计算和特征处理,为此,我们提出了一套特征外置方案来解决这个问题,并开发了一套同时支持在线和离线的特征处理组件 EzFeaFly(Easy Feature Fly)。
基本原理
当前架构下,DSP 算法能力由两套服务共同支持,策略端服务承接业务系统的预估请求,获取特征后调用模型推理服务进行预估。
为了剥离特征处理部分,我们在 Tensorflow 中彻底舍弃了 Feature Column。策略端服务获取特征后直接利用 EzFeaFly 处理特征,随后传入模型推理服务。传入特征经过插件转换成 Tensor 之后直接喂入模型进行推理计算。
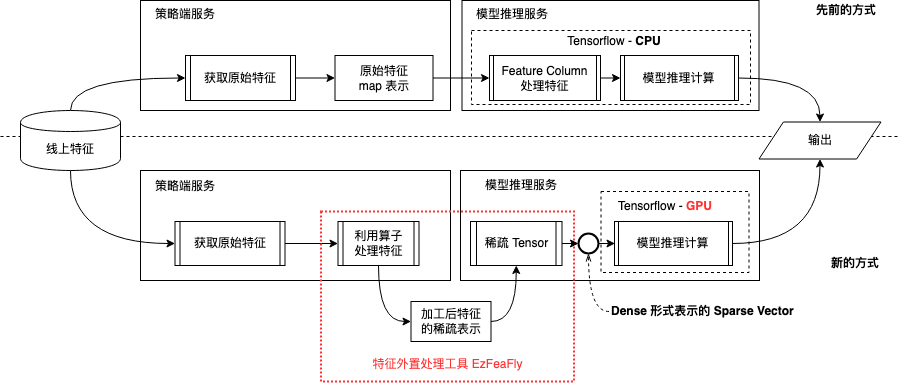
新的方案在保持整体系统架构不变的情况下,优化了整体各方资源的利用效率:
解耦特征处理与计算:合理分配计算资源,特征处理并发提效,模型计算利用 GPU 提效;
特征处理行为一致性:线上和离线使用同一套工具处理特征,处理结果的一致性有保障。
离在线流程
整套特征外置方案不仅只考虑线上推理提效,还包括了离线模型训练和部署,其详细流程如下图所示:
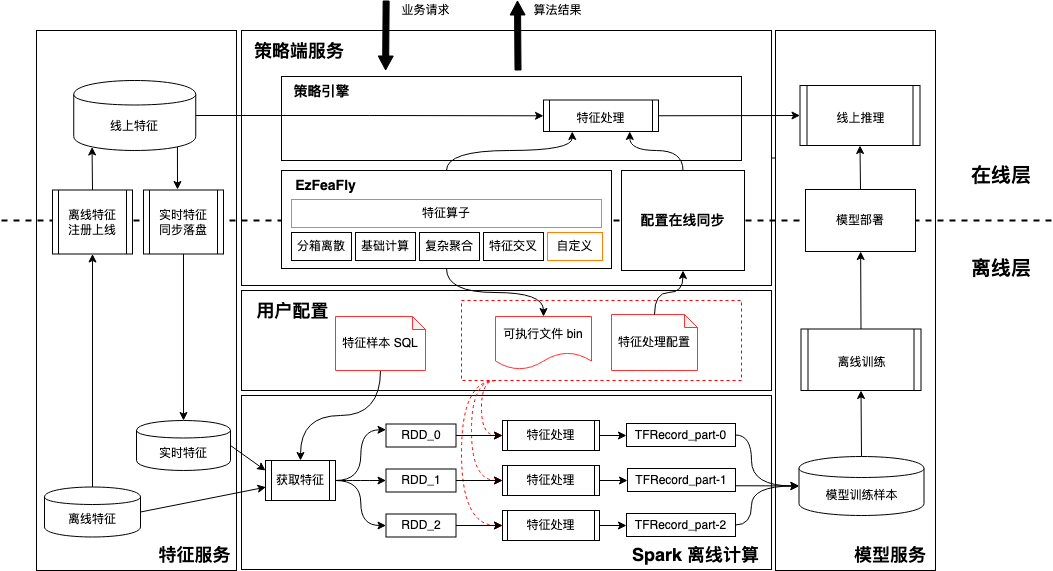
离线模型训练:
EzFeaFly 工具可编译生成 bin 文件,通过预先设置的特征处理配置,可直接用于处理特征;
利用 Spark + bin + 配置文件 的方式,可实现批量处理大规模样本,最终生成 TFRecords 落盘 HDFS;
模型训练时直接读取 HDFS 上的 TFRecords,训练好的模型可直接部署上线提供推理服务。
在线推理:
离线训练模型使用的特征配置可直接同步线上进行统一管理;
策略端服务基于同步的配置获取并使用部署线上的 EzFeaFly 工具处理特征;
处理后的特征可直接传入模型推理服务获取推理结果 。
使用效果
特征外置方案已经在 DSP 中得到全面应用,整体性能提升巨大,机器成本和耗时均显著下降:
机器实例数量大大减少,成本大约节省 40%;
相同 QPS 压力下,推理耗时降低 70% ~ 80%(左图);
考虑到特征处理过程中 EzFeaFly 自身的耗时,对比模型请求预估全链路整体耗时,新方案仍有 60%+ 的耗时下降(右图)。

得益于耗时优化,模型策略的想象空间也变得更大:DSP 线上可以使用更多特征、迭代更为复杂的模型,并且也为级联模型其他阶段提供了更大的优化空间。
详细设计
EzFeaFly 功能模块
EzFeaFly 作为特征外置方案的核心组件,其功能设计上融入了如下几点考虑:
多场景:同时支持线上和离线特征处理;
一致性:线上和离线处理特征的行为和结果保持一致;
可扩展:便于后续添加新的特征处理方法。
基于上述考虑,我们自顶向下对功能模块进行了层级划分:
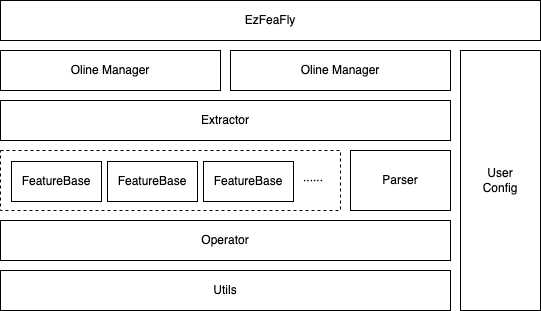
Manager :工具外层 wrapper,处理请求、IO、数据等,在线和离线使用不同的 Manager;
Extractor :特征处理引擎,在线和离线 Manager 均使用相同的 Extractor 处理特征;
Parser :特征配置、依赖关系解析,生成具体的特征处理单元;
FeatureBase :特征处理单元,管理特征的基础信息和处理逻辑(即特征算子);
Operator :特征算子,特征处理中实际计算模块;
Utils :算子处理特征过程中使用的通用基础方法。
特征处理过程
由于在线和离线处理特征样本过程基本一致,并且离线处理过程可以视为线上处理过程的超集。因此,这里以离线为例,通过下图简单表述特征处理过程:
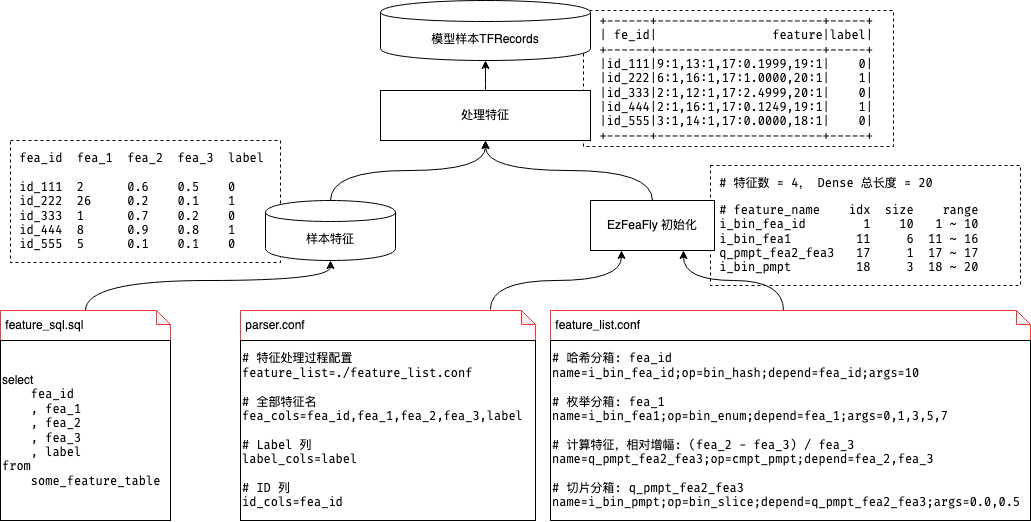
离线处理需要三个文件,其作用和对应的线上方案如下所示:
文件 | 离线作用 | 线上方案 |
feature_sql.sql | 特征数据源 | 直接通过特征服务获取实时特征 |
parser.conf | 告诉工具文件中读取的特征列是什么,label 列是什么,样本 id 列是什么 | 无需此项,线上根据特征处理配置自动解析需要获取的特征 |
feature_list.conf | 特征处理过程的描述。使用什么算子,算子输入什么,结果如何输出等 | 离线配置可直接部署到线上使用 |
特征处理结果与模型输入
考虑到线上传输成本以及模型侧的易用性,我们将 EzFeaFly 处理后的 稀疏向量 转换成了一种 稀疏表示的 Dense 向量,即
本质上数据仍是 Dense Tensor;
其内容为特征的稀疏表示,奇数位表示 index,偶数位表示对应的 value, [ k1, v1, k2, v2, ...]。
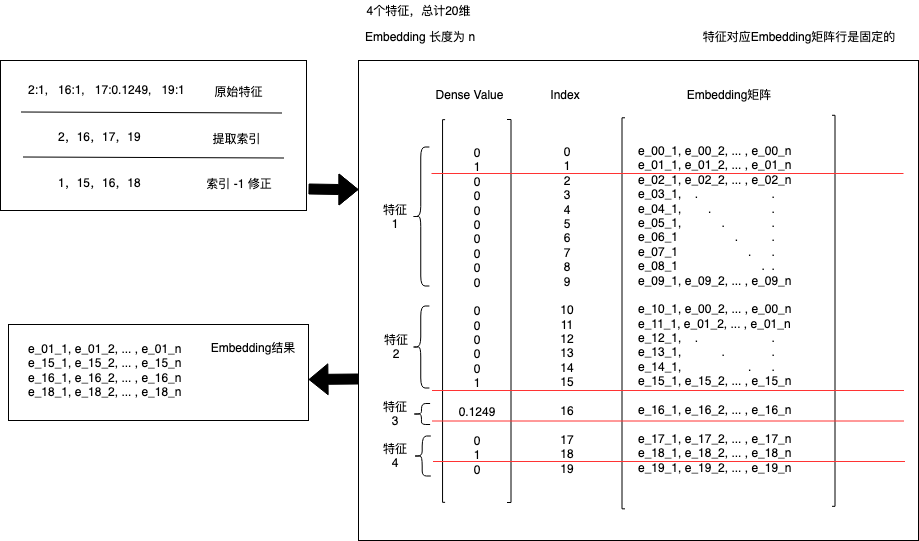
因此,构建模型时需要对输入 Tensor 进行拆分,以确保获取到正确的 index 和 value。如下为特征 Tensor 的拆分示意:
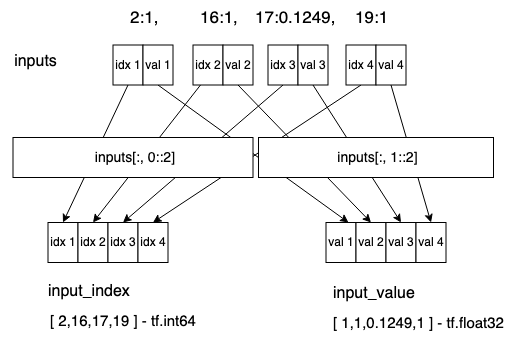
该拆分步骤对应具体的代码如下:
# 特征个数
FEATURE_NUM = 4
# 输入层长度 = FEATURE_NUM * 2,数据类型 tf.float32
inputs = tf.keras.Input(shape=[FEATURE_NUM * 2], dtype=tf.float32, name="feature_inputs")
# 提取全部 index - 减 1 是因为工具提取特征最小 index 为 1
input_index = tf.cast(inputs[:, 0::2], tf.int64) - 1
# 提取全部 value
input_value = tf.cast(inputs[:, 1::2], tf.float32)
# 构建模型
model = tf.keras.Model(inputs=inputs, outputs=[···])全局 Embedding
EzFeaFly 处理特征产出全局 index,即特征 index 已经包含了特征之间的相对偏移,出于计算性能考虑,可以利用 index 构建全局 embedding 层。
模型内部按照特征展开总长度 m 和 embedding 长度 n,维护一个 m · n 的 embedding 矩阵;
使用时,通过全局 index 向量做 embedding_lookup 即可。
具体使用如下所示,这里对 embedding 做了一层封装,结果会直接返回 [batch_size, fea_num * embedding_size] 的向量。
import tensorflow as tf
class IndexEmbedding(tf.keras.layers.Embedding):
def __init__(self,
dense_fea_dim,
embedding_dim,
sparse_fea_dim,
embeddings_initializer="uniform",
embeddings_regularizer=None,
activity_regularizer=None,
embeddings_constraint=None,
mask_zero=False,
input_length=None,
**kwargs):
super(IndexEmbedding, self).__init__(
input_dim=dense_fea_dim,
output_dim=embedding_dim,
embeddings_initializer=embeddings_initializer,
embeddings_regularizer=embeddings_regularizer,
activity_regularizer=activity_regularizer,
embeddings_constraint=embeddings_constraint,
mask_zero=mask_zero,
input_length=input_length,
**kwargs
)
self.sparse_fea_dim = sparse_fea_dim
self.out_dense_dim = sparse_fea_dim * embedding_dim
def build(self, input_shape=None):
name = "index_embedding_{}_{}".format(
self.input_dim, self.output_dim)
self.embeddings = self.add_weight(
shape=(self.input_dim, self.output_dim),
initializer=self.embeddings_initializer,
regularizer=self.embeddings_regularizer,
constraint=self.embeddings_constraint,
experimental_autocast=False,
name=name
)
self.built = True
def call(self, feature, **kwargs):
_embedding = tf.nn.embedding_lookup(self.embeddings, feature)
embedding = tf.reshape(_embedding, [-1, self.out_dense_dim])
return embedding
# 按照输入结构直接拆分
input_index = tf.cast(feature[:, 0::2], tf.int64) - 1
# input_value = tf.cast(feature[:, 1::2], tf.float32)
# embedding
embedding = IndexEmbedding(
dense_fea_dim=20,
embedding_dim=8,
sparse_fea_dim=4
)(input_index)在线部署
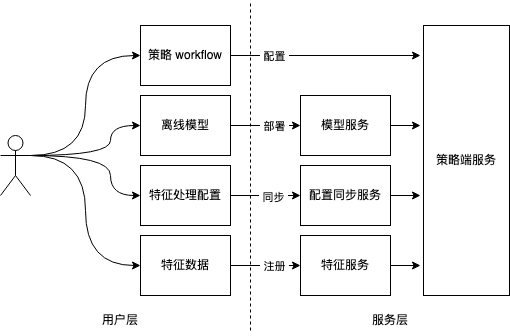
在线部署完全是一套流程化的操作,基于策略端服务上下游,用户逻辑上需要执行4步操作:
基于特征服务,注册和上线使用的特征;
基于配置同步服务,同步特征处理配置到线上;
基于模型服务,将离线训练的模型部署到线上;
配置策略 workflow,控制流量进入策略,触发线上服务运行。
写在最后
目前,项目取得阶段性成果,降本提效的同时,也为业务带来了正向收益。整个项目得以推进,离不开项目所有成员的共同努力!在此特别感谢团队各位同学的支持,以及密切合作的工程和算法同学,还有所有帮助我们不断完善工具的使用方。