代码:https://github.com/QwenLM/Qwen/tree/main
国内源安装说明:https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
通义千问:https://tongyi.aliyun.com/qianwen
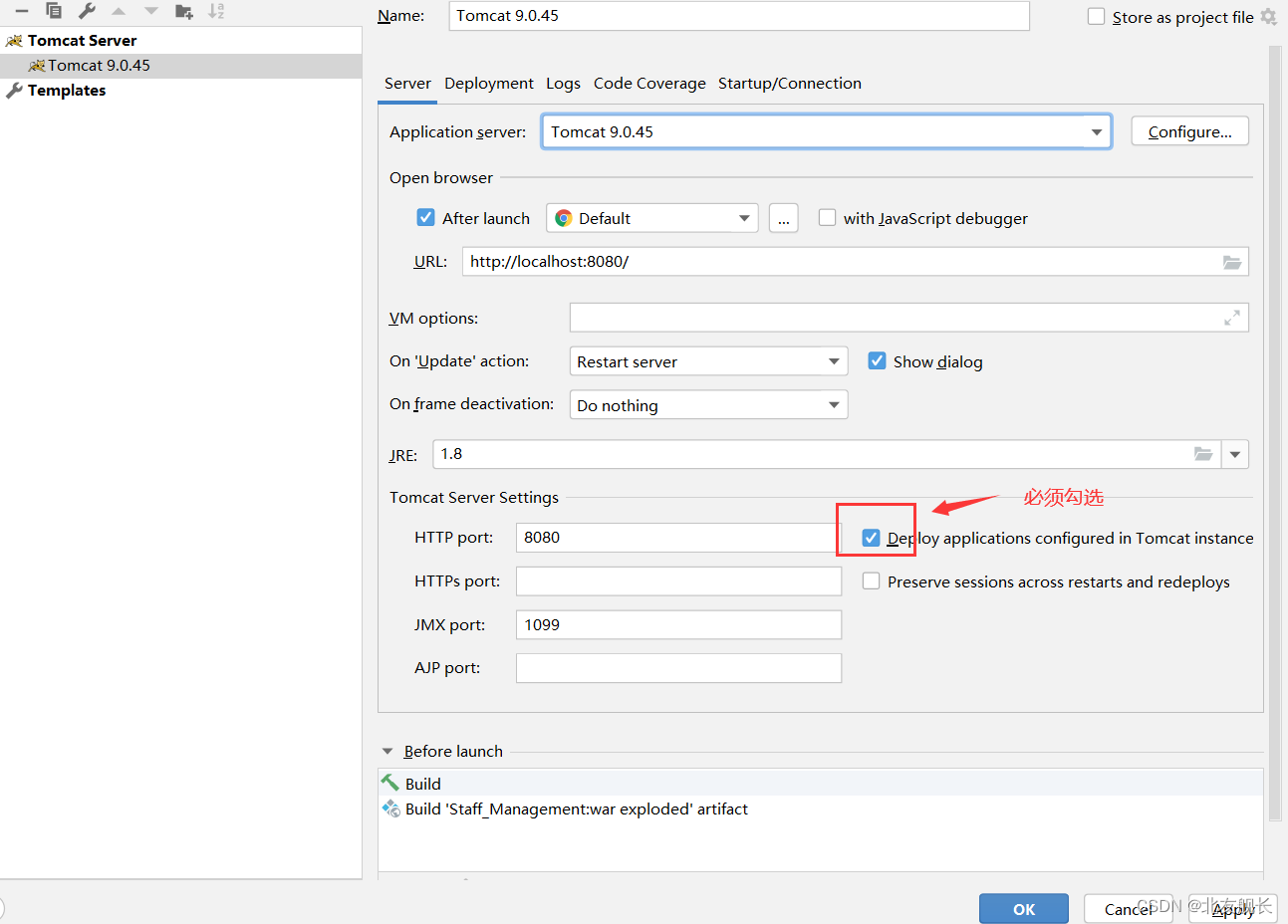
一、环境搭建
下载源码
git clone https://github.com/QwenLM/Qwen.git
conda+pytorch (根据自己显卡驱动选择)
去pytorch官网 https://pytorch.org/get-started/previous-versions/
conda create -n qwenLM python=3.10
conda activate qwenLM
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
其他依赖
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
UI相关依赖
cd Qwen
pip install -r requirements_web_demo.txt
可供选择(安不上不影响推理和训练)
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
二、模型下载与推理
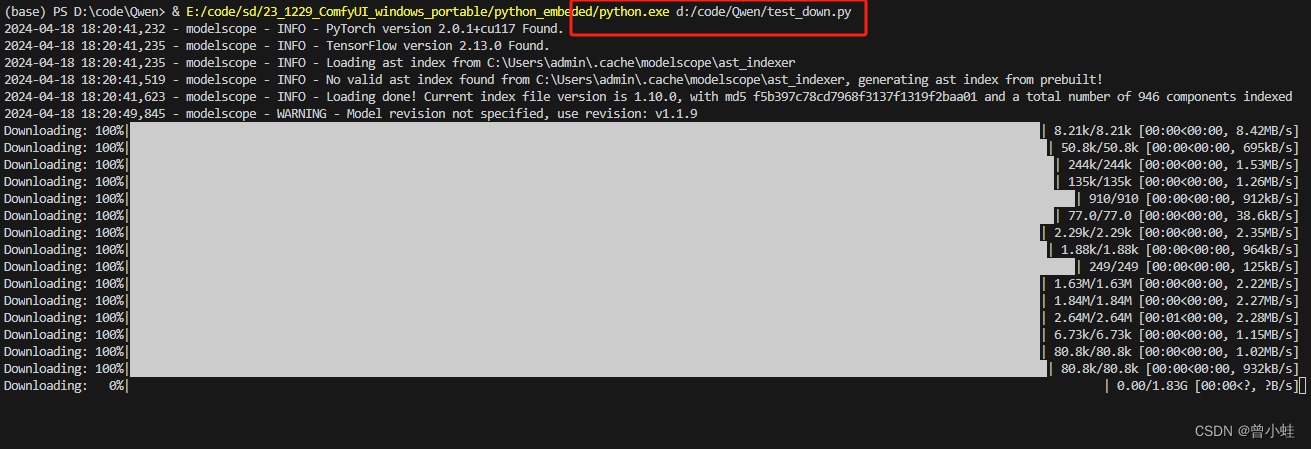
2.1 运行 test_down.py
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen-7B-Chat')
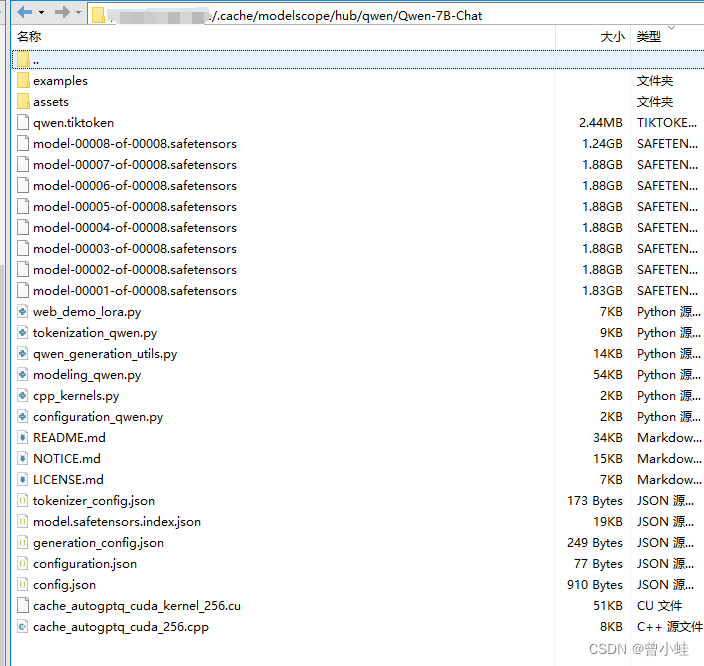
2.2 下载完成后
~/.cache/modelscope/hub/Qwen/Qwen-7B-Chat
2.2 推理
–server-name 如果不写,只能本机打开,0.0.0.0输入ip可以。。
CUDA_VISIBLE_DEVICES=0 表示选择显卡0,多显卡才用,单点卡不用输入
-c表示的是模型的地址
–server-port 也可指定端口 ,默认是8000,可改为其他
CUDA_VISIBLE_DEVICES=0 python web_demo.py -c ~/.cache/modelscope/hub/qwen/Qwen-7B-Chat --server-name 0.0.0.0
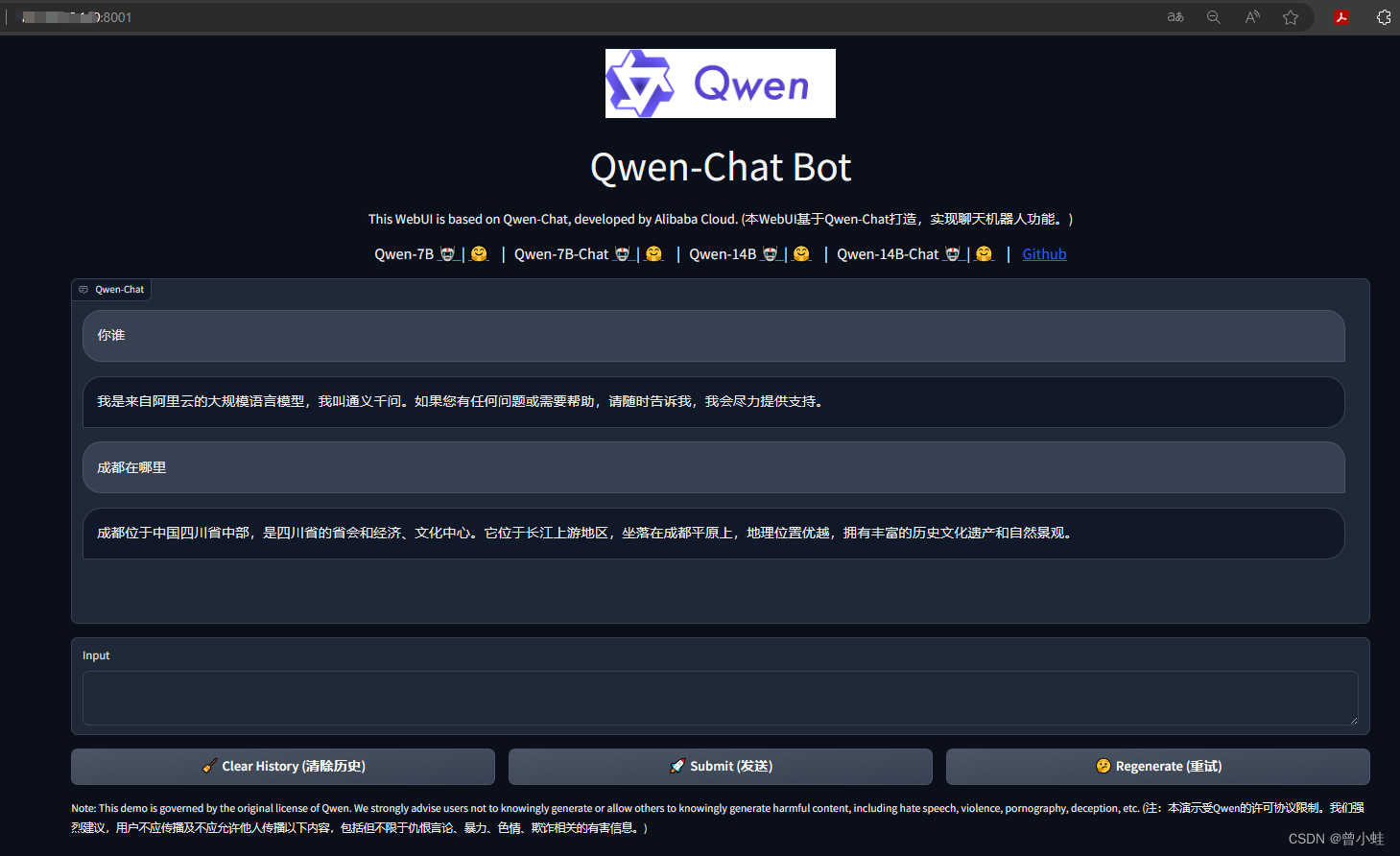
三、微调-训练lora (见官网)
3.1 数据集示意:test_zhj_11.json (局部非完整)
[ {
"id": "000000000",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是曾小蛙的助手,支持xx游戏相关问答。"
}
]
},
{
"id": "000000001",
"conversations": [
{
"from": "user",
"value": "镇魂街游戏中,合击技是做什么用的?"
},
{
"from": "assistant",
"value": "合击技是由寄灵人与守护灵搭配使用的技能,可以在战斗中释放强大效果。"
}
]
},
{
"id": "000000002",
"conversations": [
{
"from": "user",
"value": "灵海之境"
},
{
"from": "assistant",
"value": "灵海之境是玩家养成寄灵人和守护灵,提升他们能力的系统。"
}
]
},
{
"id": "000000003",
"conversations": [
{
"from": "user",
"value": "共鸣神石是用来做什么的?"
},
{
"from": "assistant",
"value": "共鸣神石可以提升对应元素的寄灵人和守护灵的能力等级。"
}
]
},
{
"id": "000000004",
"conversations": [
{
"from": "user",
"value": "游戏中的竞技场?"
},
{
"from": "assistant",
"value": "竞技场是玩家们进行PVP战斗,争夺排名的场所。"
}
]
},
{
"id": "000000005",
"conversations": [
{
"from": "user",
"value": "游戏中,蓬莱宝库有什么特别之处?"
},
{
"from": "assistant",
"value": "蓬莱宝库是探索活动,玩家可以通过解决事件获取奖励,并挑战更高层的内容。"
}
]
},
{
"id": "000000006",
"conversations": [
{
"from": "user",
"value": "五灵宝珠"
},
{
"from": "assistant",
"value": "五灵宝珠用于提升角色的五行属性,角色品质到橙色后可使用。"
}
]
},
{
"id": "000000007",
"conversations": [
{
"from": "user",
"value": "千机黑刹是什么?"
},
{
"from": "assistant",
"value": "千机黑刹是游戏中的挑战副本之一。玩家需要挑战守卫和收集强化buff来提升自己的阵容实力,并挑战首领【镇狱童子】,根据造成的伤害获得排名和奖励。"
}
]
},
{
"id": "000000008",
"conversations": [
{
"from": "user",
"value": "星河罗盘有何作用?"
},
{
"from": "assistant",
"value": "星河罗盘是游戏中的一个资源收集系统。通过收集星辉作为资源,玩家可以提升星河罗盘等级,从而获得对应职业属性的加持,提升角色实力。"
}
]
},
{
"id": "000000009",
"conversations": [
{
"from": "user",
"value": "地狱道?"
},
{
"from": "assistant",
"value": "地狱道是一个任务系统,玩家完成任务可以激活特权,提升地狱道等级后可以获得更多加成,并且每日可领取与等级相应的奖励。"
}
]
},
{
"id": "000000010",
"conversations": [
{
"from": "user",
"value": "贪字营?"
},
{
"from": "assistant",
"value": "贪字营是游戏中的悬赏任务系统,玩家可以接受任务并派遣符合条件的寄灵人和守护灵上阵,完成任务后可以获得丰富的奖励。"
}
]
}
]
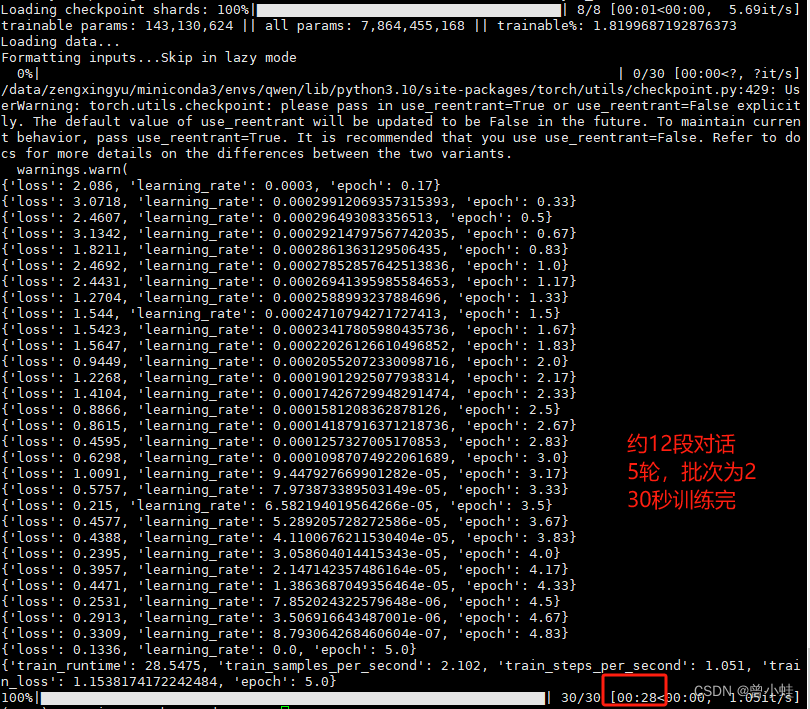
3.2 单卡 训练lora 脚本(直接放入命令端)
num_train_epochs 默认为 5
output_dir 训练后lora保存
data_path 数据集json的路径
model_name_or_path 使用绝对路径
gradient_accumulation_steps 数据少时 ,要改为1(默认为8),否则loss训练不下去
CUDA_VISIBLE_DEVICES=1 python finetune.py \
--model_name_or_path "your_dir/modelscope/hub/Qwen/Qwen-7B-Chat" \
--data_path "./datasets/test_zhj_11.json"\
--bf16 True \
--output_dir output_qwen/test1 \
--num_train_epochs 5 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 10 \
--learning_rate 3e-4 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "none" \
--model_max_length 512 \
--lazy_preprocess True \
--gradient_checkpointing \
--use_lora
训练过程
训练后的lora模型(未融合)
3.3 加载lora (未合并 合并见官网)
官网加载示意 (部分代码)
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
path_to_adapter, # path to the output directory
device_map="auto",
trust_remote_code=True
).eval()
修改 web_demo.py 为web_demo_lora.py (代码见附录)
下面代码DEFAULT_CKPT_PATH 改为自己主模型的绝对路径,非lora
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
"""A simple web interactive chat demo based on gradio."""
import os
from argparse import ArgumentParser
import gradio as gr
import mdtex2html
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
DEFAULT_CKPT_PATH = 'Qwen/Qwen-7B-Chat'
from peft import AutoPeftModelForCausalLM
def _get_args():
parser = ArgumentParser()
parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r")
parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
parser.add_argument("--share", action="store_true", default=False,
help="Create a publicly shareable link for the interface.")
parser.add_argument("--inbrowser", action="store_true", default=False,
help="Automatically launch the interface in a new tab on the default browser.")
parser.add_argument("--server-port", type=int, default=8000,
help="Demo server port.")
parser.add_argument("--server-name", type=str, default="127.0.0.1",
help="Demo server name.")
args = parser.parse_args()
return args
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True,
)
if args.cpu_only:
device_map = "cpu"
else:
device_map = "auto"
model = AutoPeftModelForCausalLM.from_pretrained(
args.checkpoint_path, # path to the output directory
device_map=device_map,
trust_remote_code=True,
).eval()
config = GenerationConfig.from_pretrained(
DEFAULT_CKPT_PATH , trust_remote_code=True, resume_download=True,
)
return model, tokenizer, config
def postprocess(self, y):
if y is None:
return []
for i, (message, response) in enumerate(y):
y[i] = (
None if message is None else mdtex2html.convert(message),
None if response is None else mdtex2html.convert(response),
)
return y
gr.Chatbot.postprocess = postprocess
def _parse_text(text):
lines = text.split("\n")
lines = [line for line in lines if line != ""]
count = 0
for i, line in enumerate(lines):
if "```" in line:
count += 1
items = line.split("`")
if count % 2 == 1:
lines[i] = f'<pre><code class="language-{items[-1]}">'
else:
lines[i] = f"<br></code></pre>"
else:
if i > 0:
if count % 2 == 1:
line = line.replace("`", r"\`")
line = line.replace("<", "<")
line = line.replace(">", ">")
line = line.replace(" ", " ")
line = line.replace("*", "*")
line = line.replace("_", "_")
line = line.replace("-", "-")
line = line.replace(".", ".")
line = line.replace("!", "!")
line = line.replace("(", "(")
line = line.replace(")", ")")
line = line.replace("$", "$")
lines[i] = "<br>" + line
text = "".join(lines)
return text
def _gc():
import gc
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
def _launch_demo(args, model, tokenizer, config):
def predict(_query, _chatbot, _task_history):
print(f"User: {_parse_text(_query)}")
_chatbot.append((_parse_text(_query), ""))
full_response = ""
for response in model.chat_stream(tokenizer, _query, history=_task_history, generation_config=config):
_chatbot[-1] = (_parse_text(_query), _parse_text(response))
yield _chatbot
full_response = _parse_text(response)
print(f"History: {_task_history}")
_task_history.append((_query, full_response))
print(f"Qwen-Chat: {_parse_text(full_response)}")
def regenerate(_chatbot, _task_history):
if not _task_history:
yield _chatbot
return
item = _task_history.pop(-1)
_chatbot.pop(-1)
yield from predict(item[0], _chatbot, _task_history)
def reset_user_input():
return gr.update(value="")
def reset_state(_chatbot, _task_history):
_task_history.clear()
_chatbot.clear()
_gc()
return _chatbot
with gr.Blocks() as demo:
gr.Markdown("""\
<p align="center"><img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/logo_qwen.jpg" style="height: 80px"/><p>""")
gr.Markdown("""<center><font size=8>Qwen-Chat Bot</center>""")
gr.Markdown(
"""\
<center><font size=3>This WebUI is based on Qwen-Chat, developed by Alibaba Cloud. \
(本WebUI基于Qwen-Chat打造,实现聊天机器人功能。)</center>""")
gr.Markdown("""\
<center><font size=4>
Qwen-7B <a href="https://modelscope.cn/models/qwen/Qwen-7B/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen-7B">🤗</a>  |
Qwen-7B-Chat <a href="https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen-7B-Chat">🤗</a>  |
Qwen-14B <a href="https://modelscope.cn/models/qwen/Qwen-14B/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen-14B">🤗</a>  |
Qwen-14B-Chat <a href="https://modelscope.cn/models/qwen/Qwen-14B-Chat/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen-14B-Chat">🤗</a>  |
 <a href="https://github.com/QwenLM/Qwen">Github</a></center>""")
chatbot = gr.Chatbot(label='Qwen-Chat', elem_classes="control-height")
query = gr.Textbox(lines=2, label='Input')
task_history = gr.State([])
with gr.Row():
empty_btn = gr.Button("🧹 Clear History (清除历史)")
submit_btn = gr.Button("🚀 Submit (发送)")
regen_btn = gr.Button("🤔️ Regenerate (重试)")
submit_btn.click(predict, [query, chatbot, task_history], [chatbot], show_progress=True)
submit_btn.click(reset_user_input, [], [query])
empty_btn.click(reset_state, [chatbot, task_history], outputs=[chatbot], show_progress=True)
regen_btn.click(regenerate, [chatbot, task_history], [chatbot], show_progress=True)
gr.Markdown("""\
<font size=2>Note: This demo is governed by the original license of Qwen. \
We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, \
including hate speech, violence, pornography, deception, etc. \
(注:本演示受Qwen的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,\
包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)""")
demo.queue().launch(
share=args.share,
inbrowser=args.inbrowser,
server_port=args.server_port,
server_name=args.server_name,
)
def main():
args = _get_args()
model, tokenizer, config = _load_model_tokenizer(args)
_launch_demo(args, model, tokenizer, config)
if __name__ == '__main__':
main()
运行命令
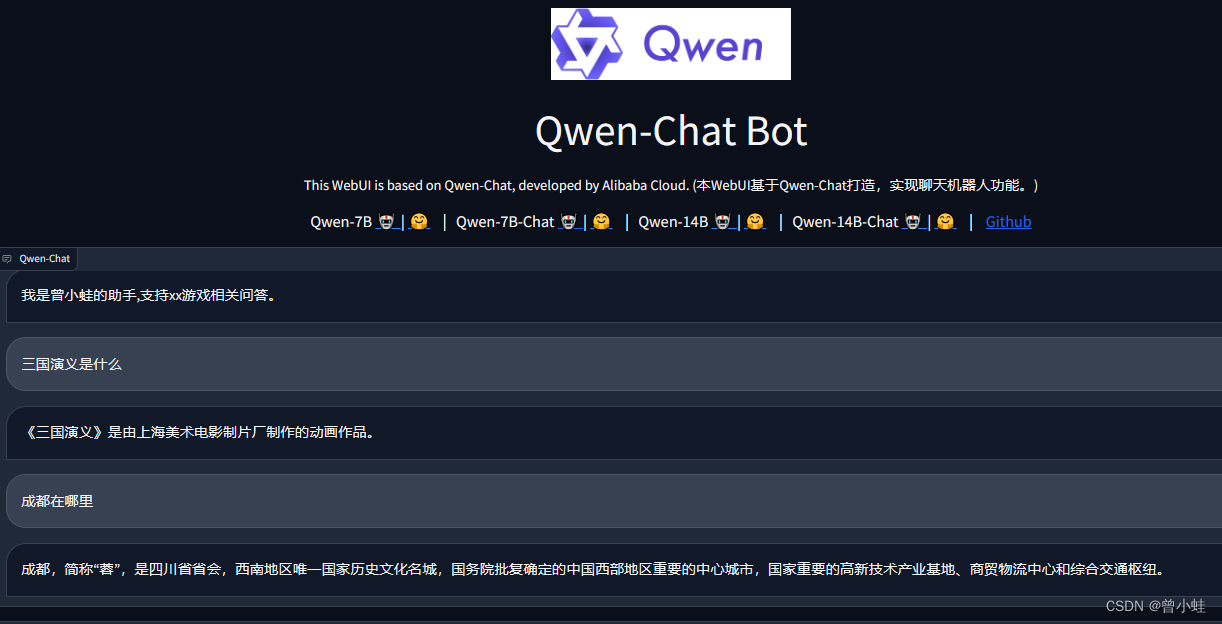
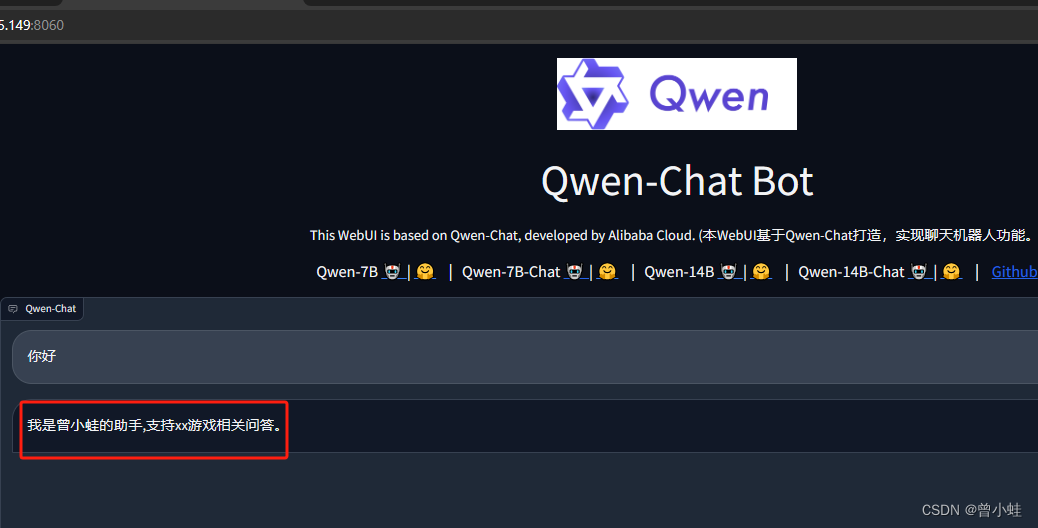
CUDA_VISIBLE_DEVICES=0 python web_demo_lora.py --server-name 0.0.0.0 -c ./output_qwen/test1 --server-port 8088
结果
我是曾小蛙的小助手
文章目录
- 一、环境搭建
- 下载源码
- conda+pytorch (根据自己显卡驱动选择)
- 其他依赖
- UI相关依赖
- 可供选择(安不上不影响推理和训练)
- 二、模型下载与推理
- 2.1 运行 test_down.py
- 2.2 下载完成后
- 2.2 推理
- 三、微调-训练lora (见官网)
- 3.1 数据集示意:**test_zhj_11.json** (局部非完整)
- 3.2 单卡 训练lora 脚本(直接放入命令端)
- 训练过程
- 训练后的lora模型(未融合)
- 3.3 加载lora (未合并 合并见官网)
- 官网加载示意 (部分代码)
- 修改 web_demo.py 为web_demo_lora.py (代码见附录)
- 运行命令
- 结果


![洛谷 P1131 [ZJOI2007] 时态同步](https://img-blog.csdnimg.cn/direct/eb5718ac450d498bbfa753b0db803f52.png)







![[Java基础揉碎]泛型](https://img-blog.csdnimg.cn/direct/d979ea8693a6471bae4e9d6c0d95d7cb.png)