字符集、编码:

字符集:一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。例如:ASCII、Unicode、GB2312、GBK、GB18030、BIG5(繁体中文) ...
编码方式:符号集合与数字系统之间的对应关系,是信息处理的一项基本技术,将符号转换为计算机可以接受的二进制数值。例如:ASCII、UTF-8、UTF-16、UTF-32、GB2312、GBK、GB18030 ...
① ASCII:编码范围0x00-0x7F(即0-127),只用7位二进制就表示所有英文字符(128个字符)。ASCII是单字节编码,一个字符占1个字节。
② Unicode字符集:称为统一码、万国码、国际码。编码范围0x0000-0x10FFFF,包括100多万个字符。每个字符都有一个二进制数值(码值、码点),例如:字符"A"的码点为"0x0041",字符"中"的码点为"0x4E2D"。
Unicode字符集有3种存储方式:UTF-8,UTF-16,UTF-32。
- UTF-8 编码:广泛使用的编码方式。可变长度编码规则,一个字符1-4个字节,不同字符占用字节数不同。前128个字符(ASCII),一个字符占1个字节。一个汉字一般占用3个字节。UTF-8不需要BOM来表明字节顺序,但可以表明编码方式。
- UTF-16 编码:对应UCS-2(Universal Character Set coded in 2 octets),一个字符占2个字节,范围为 U+0000~U+FFFF。需要识别字节顺序(大端或小端)。需要BOM(Byte Order Mark, 放在文档开头告诉阅读器该文档的字节序)。
- UTF-32 编码:对应UCS-4,一个字符占4个字节,范围为 U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2一样。需要BOM(Byte Order Mark)。
③ GB2312:中国国家标准简体中文字符集,专门用于汉字处理、汉字通信信息交换等。GB2312是对ASCll码的扩展,一个汉字占用两个字节。只有6000多个汉字。
GBK:《汉字内码扩展规范》,GB2312的扩展,有2万多个码值。一个汉字占用两个字节。一般看到936就知道是GBK。
GB18030:国家标准GB 18030-2005《信息技术中文编码字符集》,中国最新的内码字集。与GB 2312完全兼容,与GBK基本兼容,支持Unicode的全部统一汉字。是变长编码方式,可以是1个字节、2个字节和4个字节。
| 字节 | 十六进制 | 格式 | 实际编码位 | 码点范围 |
|---|---|---|---|---|
| 1字节 | 0x0000-0x007F | 0xxxxxxx | 7 | 0 ~ 127 |
| 2字节 | 0x0080-0x07FF | 110xxxxx 10xxxxxx | 11 | 128 ~ 2047 |
| 3字节 | 0x0800-0xFFFF | 1110xxxx 10xxxxxx 10xxxxxx | 16 | 2048 ~ 65535 |
| 4字节 | 0x010000-0x10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 | 65536 ~ 2097151 |
补充:字节顺序(Byte Order)是计算机存储和表示多字节数据的方式,包括大端模式(Big Endian)和小端模式(Little Endian)。
- Big Endian(大端模式):多字节数据中,高位字节(左边的位)存储在内存的低地址,低位字节(右边的位)存储在内存的高地址。
- Little Endian(小端模式):多字节数据中,高位字节存储在内存的高地址,低位字节存储在内存的低地址。
Unicode 规范定义,每个文件开头加入表示编码顺序的字符: "零宽度非换行空格"(zero width no-break space),若是FE FF,则采用大端模式;若是FF FE,则采用小端模式。
一、多字节字符
C语言中基本数据类型之一的char类型(字符),一个英文字符占用一个字节,char * 表示的字符串中也是一个英文字符占用一个字节,包括结尾符'\0'(空字符)也只占用一个字节。
但其它语言的字符就不能只用一个字节表示了,例如:汉字,仅常用汉字就有3500多个,加上生僻汉字超过10万多个。而且汉字复杂,一个汉字可能2个字节、3个字节等。若一个字符占用多个字节,称为多字节字符。多字节字符也用char类型表示。
但用char类型即用多字节字符表示中文时可能出现乱码
C文件默认的编码方式一般是UTF-8(一个英文字符占1个字节, 一个汉字通常占3个字节)。而Windows编码方式一般是GBK,则中文在处理时可能出现乱码。
Windows(GBK编码)下若避免中文乱码,方法如下:
① 可在编译时使用GBK编码(与Windows编码方式一致): -fexec-charset=GBK。
(TERMINAL终端)
编译链接:gcc -fexec-charset=GBK -o 目标名 C程序文件名
再运行可执行文件:./目标名
注:-finput-charset 指定C文件中的文字编码格式,-fexec-charset 指定编译之后的可执行文件的文字编码格式。默认情况下,gcc编译器认为编译前后的文字编码格式都是UTF-8。
// utf8.c
#include <stdio.h>
#include <locale.h>
int main(void)
{
printf("你好\n");
char *s1 = "你好";
printf("%s\n", s1);
}
// TERMINAL 输入:
gcc -fexec-charset=GBK -o utf8 utf8.c
./utf8
// 结果:
你好
你好② 使用头文件windows.h中的SetConsoleOutputCP设置成UTF-8 (使控制台输出UTF-8编码的字符)。
注意:windows.h中的 SetConsoleOutputCP 和 locale中的setlocale 虽然设置效果不同,据说可以同时使用,但可能会使宽字符无法输出。需正确设置,并注意各自的影响效果。
#include <windows.h>
SetConsoleOutputCP(65001);
或者 SetConsoleOutputCP(CP_UTF8);#include <stdio.h>
#include <locale.h>
#include <windows.h>
int main(void)
{
SetConsoleOutputCP(65001); // 或者 SetConsoleOutputCP(CP_UTF8);
printf("你好\n");
char *s1 = "你好";
printf("%s\n", s1);
}
// 结果:
你好
你好二、宽字符类型
C语言提供了宽字符,每个宽字符都是固定字节数,例如Windows中每个宽字符都是占2个字节,包括结尾符'\0'也是占两个字节。
宽字符用wchar_t类型表示。wchar_t的内存大小由编译器决定。Windows的编译器使用UTF-16编码方式,wchar_t的内存大小为2字节。大多数Linux使用UTF-32编码方式,wchar_t的内存大小大多为4字节。有了wchar_t就可以存储中文。
标准库limits.h中宏MB_LEN_MAX可查看多字节字符中的最大字节数。标准库stdlib.h中宏MB_CUR_MAX查看当前字符集中单个字符的最大字节数(不得大于MB_LEN_MAX)。
#include <stdio.h>
#include <limits.h>
#include <stdlib.h>
int main(void)
{
printf("wchar_t = %d bytes\n", sizeof(wchar_t));
printf("MB_LEN_MAX: %d\n", MB_LEN_MAX);
printf("MB_CUR_MAX: %d\n", MB_CUR_MAX);
}
// 结果:
wchar_t = 2 bytes
MB_LEN_MAX: 5
MB_CUR_MAX: 11、设置本地语言环境
若想要使用宽字符类型,需设置当前语言环境,确保系统和编译器支持。只有正确设置语言环境,才能正确处理数据,否则可能出现乱码。
可使用标准库locale.h中的setlocale函数设置当前语言环境。
setlocale: char *setlocale(itn category, const char *locale)
参数category:已命名的常量,指定设置影响的函数类型。
参数locale:切换到中文环境:Linux:"zh_CN.UTF-8"。Windows:"chs"或""。若locale为空,则根据环境变量值来设置,将程序环境切换为本地化环境。
返回:一个对应于区域设置的不透明的字符串。如果请求无效,则返回值是 NULL。
注意:Windows的locale不支持“UTF-8”,可使用GBK,即"chs"(Chinese_People's Republic of China.936)。最好locale使用空字符,切换到本地环境。
| LC_ALL | 包括下面的所有选项。 |
| LC_COLLATE | 字符串比较。影响<string.h> strcoll 和 strxfrm 函数 |
| LC_CTYPE | 字符分类和转换。影响所有字符函数 |
| LC_MONETARY | 货币格式,针对 localeconv()。 |
| LC_NUMERIC | 小数点分隔符,针对 localeconv()。 |
| LC_TIME | 日期和时间格式,针对<time.h> strftime()。 |
| LC_MESSAGES | 系统响应。 |
#include <stdio.h>
#include <locale.h>
#include <limits.h>
#include <stdlib.h>
int main(void)
{
setlocale(LC_ALL, ""); // 设为本地化环境(Windows)
printf("After: wchar_t = %d bytes\n", sizeof(wchar_t)); // wchar_t类型占用字节数
printf("After: MB_LEN_MAX: %d\n", MB_LEN_MAX); // 多字节字符最大字节数
printf("After: MB_CUR_MAX: %d\n", MB_CUR_MAX); // 当前字符集单个字符的最大字节数
wchar_t *s = L"你好";
printf("%ls\n", s);
return 0;
}
// 结果:
After: wchar_t = 2 bytes
After: MB_LEN_MAX: 5
After: MB_CUR_MAX: 2
你好
2、宽字符使用
- 使用宽字符类型时,字面量必须在引号前有前缀L。
- 一个宽字符用单引号' ',一个宽字符字符串即多个宽字符(包括空字符)使用双引号" "。
- 一个宽字符的占位符为%lc,宽字符字符串的占位符为%ls。
- 宽字符字符串的结尾符,也占多个字节。
- 使用头文件wchar.h中的 wprintf 输出宽字符,格式化字符串前必须有"L"。
- Windows中也可以用 printf 输出宽字符。但 wprintf 和 printf 不能一起使用。
#include <stdio.h>
#include <locale.h>
#include <wchar.h>
int main(void)
{
setlocale(LC_ALL, "");
wchar_t c = L'赞';
wchar_t *s = L"你好";
wprintf(L"%lc %ls\n", c, s);
return 0;
}
// 结果:
赞 你好#include <stdio.h>
#include <locale.h>
int main(void)
{
setlocale(LC_ALL, "");
wchar_t c = L'赞';
wchar_t *s = L"你好";
printf("%lc %ls\n", c, s);
return 0;
}
// 结果:
赞 你好三、多字节字符和宽字符相关函数
1、mblen 判断一个多字节字符占多少字节数
mblen: int mblen(const char *str, size_t n)
参数:str是指向多字节字符的指针, 一般检查第一个字符,n是要判断的最大字节数。
返回:解析的第一个字符的字节数,空的返回0,无效或不完整的多字节字符返回-1。
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main(void)
{
setlocale(LC_ALL, ""); // 切换到本地环境
char *s = "你好";
printf("%d\n", mblen(s, MB_CUR_MAX)); // "你"占用2个字节数
char *c = "hi";
printf("%d\n", mblen(c, MB_CUR_MAX)); // "h"占用1个字节数
return 0;
}
// 结果: (Windows)
2
12、wctomb、wcstombs 宽字符转为多字节字符
宽字符:每个字符固定字节,Windows通常2字节,Linux通常4字节。多字节字符:每个字符不同字节,可能1个字节、2个字节、3个字节等。
由于多字节字符相对占有更少的内存空间,速度相对更快,也为了能更好地兼容只支持多字节字符的系统和应用程序,因此有时候需要把宽字符转为多字节字符。
- wctomb:将一个宽字符转为多字节字符。(wide character to multi byte)
- wcstombs:将宽字符字符串转为多字节字符串。
wctomb: int wctomb(char *str, wchar_t wchar)
参数:str是指向存储多字节字符数组的指针。wchar是一个将要转换的宽字符。
返回:若str不为NULL,返回写入数组中的字节数,wchar不能表示为多字节序列时返回-1。若str为NULL,编码有移位状态返回非零,编码无状态返回零。
wcstombs: size_t wcstombs(char *str, const wchar_t *pwcs, size_t n)
参数:str是指向存储多字节字符串数组的指针。pwcs是将要转换的宽字符字符串,n是最大转换字节数。
返回:写入数组中的字节数,不包括结尾的空字符。若遇到一个无效的多字节字符,则返回-1。
#include <stdio.h>
#include <locale.h>
#include <stdlib.h>
int main(void)
{
setlocale(LC_ALL, "");
wchar_t c = L'赞'; // 一个宽字符,用单引号
char s[16];
int m = wctomb(s, c); // 宽字符转为多字节字符
printf("wctomb: %d bytes, s = %s\n", m, s);
return 0;
}
// 结果: (Windows)
wctomb: 2 bytes, s = 赞#include <stdio.h>
#include <locale.h>
#include <stdlib.h>
int main(void)
{
setlocale(LC_ALL, "");
wchar_t ws[] = L"你好123"; // 宽字符字符串
printf("wchar: %ls, size is %d bytes\n", ws, sizeof(ws));
char s[16];
int m = wcstombs(s, ws, 16); // 宽字符字符串转为多字节字符串
printf("char: %s, wcstombs: %d bytes\n", s, m);
return 0;
}
// 结果: (Windows)
wchar: 你好123, size is 12 bytes // 包括结尾符
char: 你好123, wcstombs: 7 bytes // 不包括结尾符3、mbtowc、mbstowcs 多字节字符转为宽字符
多字节字符中每个字符占不同字节数,不利于数据处理,尤其是编码方式不同的情况。因此有时需将多字节字符转为固定字节的宽字符。
但当多字节字符转为宽字符时,若存在编码方式的差异,可能发生乱码。可以在编译时使用本地编码方式(例如Windows: -fexec-charset=GBK),也可以手写代码进行编码的转换。
- mbtowc:将一个多字节字符转为宽字符。
- mbstowcs :将多字节字符串转为宽字符字符串。
mbtowc: int mbtowc(whcar_t *pwc, const char *str, size_t n)
参数:pwc是指向宽字符对象的指针,str是指向一个将要转换的多字节字符的指针,n为最大转换字节数。
返回: 若str不为NULL,返回str消耗的字节数,空字节返回0,失败返回-1。若str为NULL,编码有移位状态返回非零,编码无状态返回零。
mbstowcs: size_t mbstowcs(schar_t *pwcs, const char *str, size_t n)
参数:pwcs是指向宽字符对象的指针,str是指向将要转换的多字节字符串的指针,n为最大转换字节数。
返回: 转换的字符数,不包括结尾的空字符。若遇到一个无效的多字节字符,则返回-1。
// utf8.c
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main(void)
{
setlocale(LC_ALL, "");
char s[] = "赞"; // 多字节字符
printf("s = %s, size is %d bytes\n", s, sizeof(s));
wchar_t *p = (wchar_t *)malloc(8);
int k = mbtowc(p, s, 8); // 多字节字符转为宽字符
printf("p = %ls, mbtowc: %d bytes\n", p, k);
free(p); // 动态分配的内存使用完主动释放
return 0;
}
// TERMINAL输入:
gcc -fexec-charset=GBK -o utf8 utf8.c
./utf8
// 结果: (Windows)
s = 赞, size is 3 bytes // 包括结尾符
p = 赞, mbtowc: 2 bytes // 不包括结尾符// utf8.c
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
#include <string.h>
int main(void)
{
setlocale(LC_ALL, "");
char s[] = "你好123"; // 多字节字符
printf("s = %s, size is %d bytes\n", s, sizeof(s));
// int x = mbstowcs(NULL, s, 0); // 获取转换后的长度
wchar_t *p = (wchar_t *)malloc(16);
int y = mbstowcs(p, s, 16); // 多字节字符串转为宽字符字符串
printf("p = %ls, mbstowcs: %d characters\n", p, y);
free(p);
return 0;
}
// TERMINAL输入:
gcc -fexec-charset=GBK -o utf8 utf8.c
./utf8
// 结果: (Windows)
s = 你好123, size is 8 bytes // 包括结尾符
p = 你好123, mbstowcs: 5 characters // 不包括结尾符
补充:
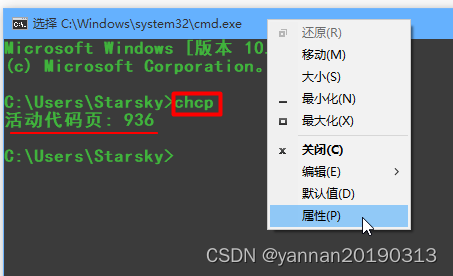
1、查看Windows计算机的当前字符集:
开始 --> 运行 --> cmd --> 输入:chcp --> 在cmd窗口标题栏 右键属性 -->"选项"标签页 "当前活动页..."。注:65001(utf-8),936(GBK)。


修改Windows计算机的默认字符集:(慎重)
① 开始 --> 运行 --> cmd --> 输入:chcp 65001。
②修改注册表。

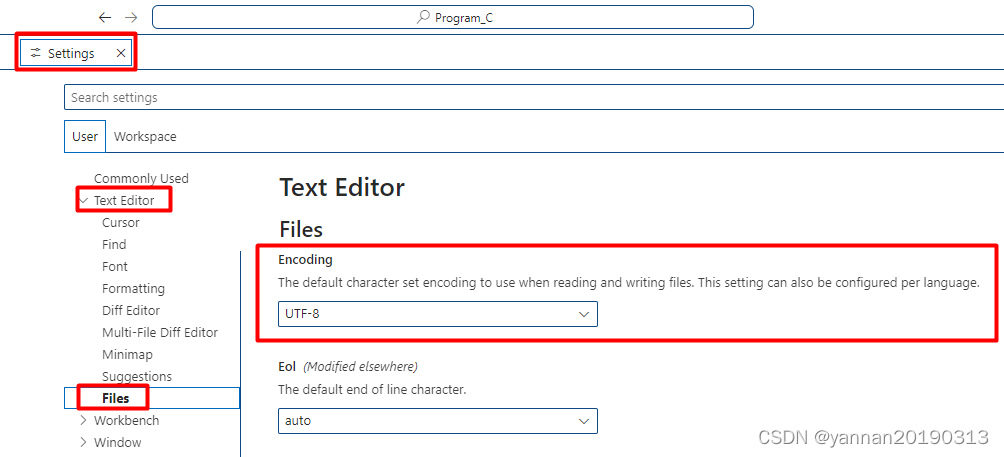
查看 VSCode 当前字符集:

2、UTF-8编码与GBK编码的转换
UTF-8转为GBK:UTF-8编码 先转为 Unicode(Windows是UTF-16) 再转为GBK编码。
GBK转为UTF-8:GBK编码 先转为 Unicode(Windows是UTF-16) 再转为UTF-8编码。
注:UTF-8是Unicode字符集的编码方式之一,Unicode和GBK是两个不同的字符集,GBK既是字符集也是编码。

![[大模型]Qwen-7B-hat Transformers 部署调用](https://img-blog.csdnimg.cn/direct/f2b5108b8f8e4ff3894d7c9a53fcf574.png#pic_center)