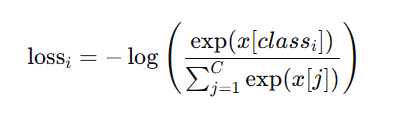文章目录
- (一)下载YOLOv5源码
- (二)修改YOLOv5源码
- 1、修改输出文件的保存路径(适应Kaggle的输出路径)
- 2、在data文件夹中新建一个yaml文件
- 3、在 train.py 中修改data路径
- 4、指定训练的轮数
- 5、修改模型配置文件
- 6、在 train.py 中修改模型配置文件(yolov5s.yaml)路径
- 7、修改 loss.py 文件
- 8、修改 plots.py 文件
- 9、下载预训练权重
- 10、添加预训练权重文件
- 11、在 train.py 中修改预训练权重文件(yolov5s.pt)路径
- 12 、修改datasets.py和general.py文件
- 14、Arial.ttf字体下载报错问题
- 15、共需修改的代码文件
- (三)在Kaggle上部署项目
- 1、删除 .cache 文件
- 2、把源码本地打包成.zip格式上传到Kaggle的Datasets上
- 3、新建一个笔记本(notebook),用来运行代码
- 4、使用GPU
- 5、部署环境
- 6、运行测试
- 7、离线训练前准备
- 8、离线训练
- 9、下载输出文件
- (四)此次用到的项目下载
- (五)记录一下可运行YOLOv5所需库的一个CPU版本
(一)下载YOLOv5源码
YOLOv5 开源代码项目下载地址:https://github.com/ultralytics/yolov5
(二)修改YOLOv5源码
1、修改输出文件的保存路径(适应Kaggle的输出路径)
在 train.py 中把以下代码
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
修改为:
# 采用kaggele训练模型一定要修改文件的保存路径
parser.add_argument('--project', default= '/kaggle/working/runs/train', help='save to project/name')
2、在data文件夹中新建一个yaml文件
在data文件夹中新建一个yaml文件(文件名可自取,例如我的是:mydata.yaml),向mydata.yaml文件中复制以下内容:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /kaggle/input/yolov5-animals/yolov5-6.0/data/dataset # dataset root dir
train: train/images # train images (relative to 'path') 128 images
val: val/images # val images (relative to 'path') 128 images
test: test/images # test images (optional)
# Classes
nc: 11 # number of classes
names: ["animals", "cat", "chicken", "cow", "dog", "fox", "goat", "horse", "person", "racoon", "skunk"] # class names
注意:
(1)、path为自己数据集的文件夹名称,要根据的数据集放置自己项目路径下的哪个位置进行更改。
之所以将 path: /kaggle/input/yolov5-animals/yolov5-6.0/data/dataset ,是因为等下要将项目上传到Kaggle中运行。
路径中的 yolov5-animals 为你等下上传项目到Kaggle所起的名字,需保证与上传到Kaggle时所起的名字一致。
(2)、代码中的类别数(number of classes)和类别名称(class names)需更改为自己的。

3、在 train.py 中修改data路径
在 train.py 中把以下代码
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
修改为:
parser.add_argument('--data', type=str, default=ROOT / 'data/mydata.yaml', help='dataset.yaml path')
4、指定训练的轮数
# 训练的轮数
parser.add_argument('--epochs', type=int, default=300)
default=300表示训练300轮,可根据自身需求进行修改
5、修改模型配置文件

选择一个你想要导入的模型文件,例如这里选择yolov5s.yaml,在models文件夹下将yolov5s.yaml文件中的类别数(number of classes)更改为你自己的。

6、在 train.py 中修改模型配置文件(yolov5s.yaml)路径
在 train.py 中把以下代码
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
修改为:
parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')
7、修改 loss.py 文件
在 utils 文件夹中找到 loss.py 文件,把第173行代码进行修改。
gain = torch.ones(7, device=targets.device).long()

8、修改 plots.py 文件
如果在训练模型时报错:AttributeError: ‘FreeTypeFont’ object has no attribute ‘getsize’
在 utils 文件夹中找到 plots.py 文件,如下图进行修改。
import PIL
def check_version(target_version):
"""
Check if the current PIL version is greater than or equal to the target version.
Args:
target_version (str): The target version string to compare against (e.g., '9.2.0').
Returns:
bool: True if the current PIL version is greater than or equal to the target version, False otherwise.
"""
current_version = PIL.__version__
current_version_parts = [int(part) for part in current_version.split('.')]
target_version_parts = [int(part) for part in target_version.split('.')]
# Compare version parts
for cur, tgt in zip(current_version_parts, target_version_parts):
if cur > tgt:
return True
elif cur < tgt:
return False
# If all parts are equal, the versions are equal or current version is shorter
return True
if check_version('9.2.0'):
self.font.getsize = lambda x: self.font.getbbox(x)[2:4] # text width, height

或者直接降低pillow包的版本
!pip install pillow==9.5
9、下载预训练权重
预训练权重下载地址:https://github.com/ultralytics/yolov5/releases
根据自己需要选择预训练权重(注意要和源码版本对上)
下拉找到对应版本的 “Assets“ 导栏,在 “Assets“ 导栏 中选择所需文件进行下载。
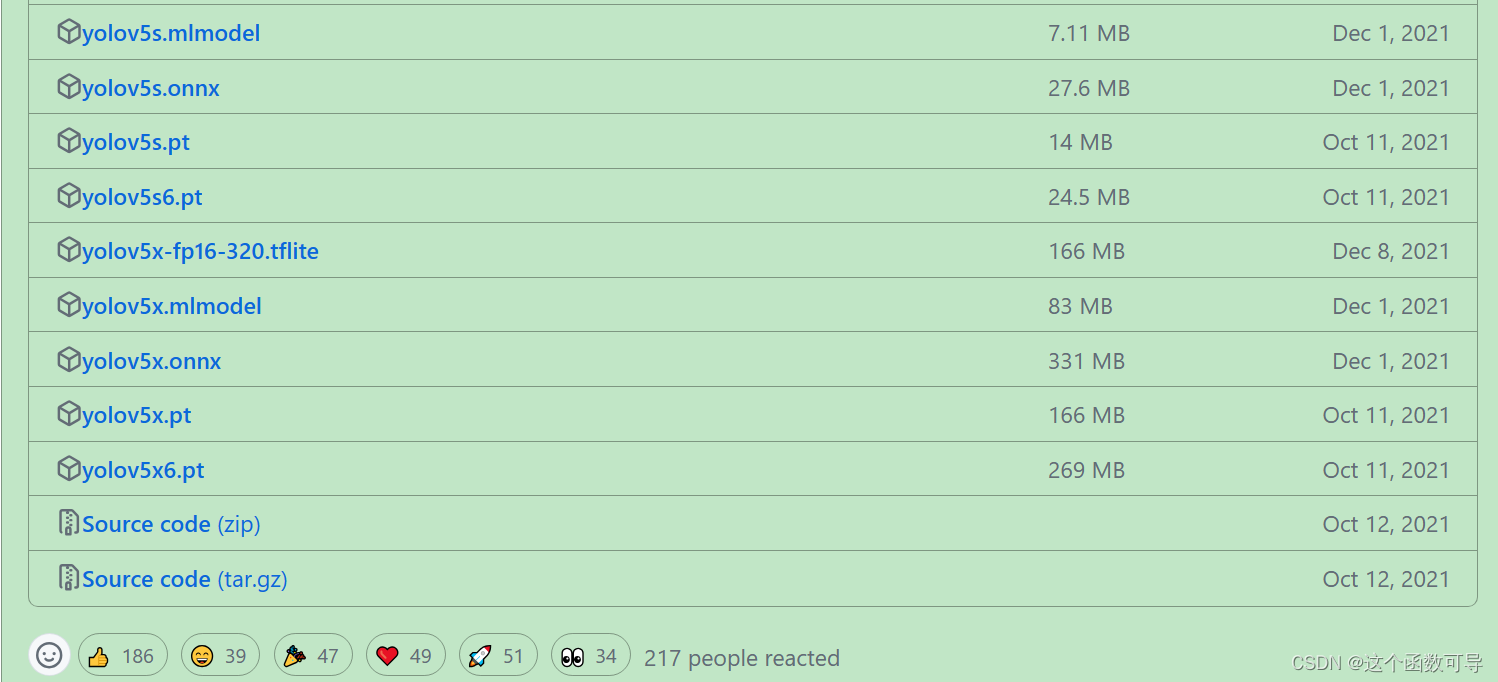
10、添加预训练权重文件
在项目的根目录下新建一个文件夹“weights”(名字可自取),将下载的预训练权重文件(如:yolov5s.pt)存放在该文件夹下。

11、在 train.py 中修改预训练权重文件(yolov5s.pt)路径
在 train.py 中把以下代码
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
修改为:
parser.add_argument('--weights', type=str, default=ROOT / 'weights/yolov5s.pt', help='initial weights path')
12 、修改datasets.py和general.py文件
numpy版本numpy.int在NumPy 1.20中已弃用,在NumPy1.24中已删除。如果你使用了这些版本可能会报错:AttributeError: module numpy has no attribute int 。
在 utils 文件夹下找到 datasets.py和general.py文件
在datasets.py中,分别将第445行、第474行、第845行代码中的 np.int 改为 int
在general.py中,将第470行代码中的 np.int 改为 int
14、Arial.ttf字体下载报错问题
【问题描述】
在使用yolov5进行模型训练时,会自动下载Arial.ttf文件,而如果我们把代码部署到Kaggle或其他服务器上运行是无法下载Arial.ttf字体文件的,具体报错信息如下:
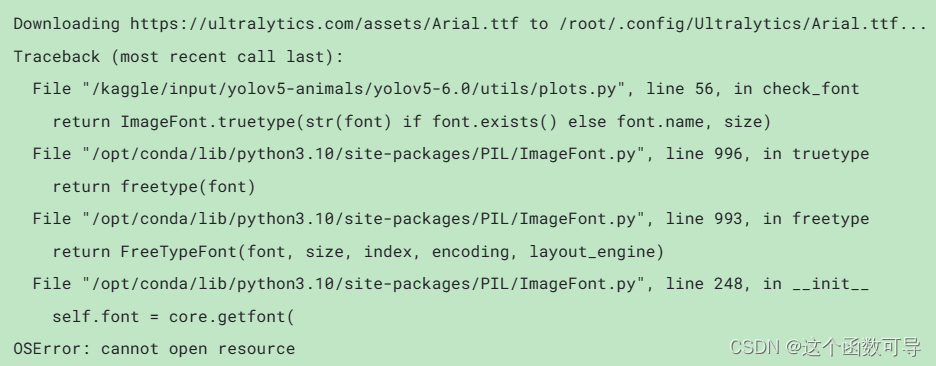
【解决方式】
看到有网友说可以预先从 https://ultralytics.com/assets/Arial.ttf这里将Arial.ttf下载放在yolov5的根目录下,就可以避免Arial.ttf字体会自动下载。但有些版本里的下载指令是不会先对文件夹里是否有arial字体作出判断再下载的,所以这个方法可能是行不通的,就看你的版本是怎么做这个决策的了。
另一种解决方式如下。
参考文章:
yolov5-6.0版本服务器配置训练遇到的问题
在文件yolov5/utils/plots.py中对Arial.ttf的引用定义作出修改。
把以下代码
class Annotator:
if RANK in (-1, 0):
check_font() # download TTF if necessary
# YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
修改为
class Annotator:
#if RANK in (-1, 0):
# check_font() # download TTF if necessary
# YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
def __init__(self, im, line_width=None, font_size=None, font='', pil=False, example='abc'):
这可能是系统一种字体的缺失,需要下载,但是服务器上下载不了,直接注释掉代码就可以了。
如果在之后运行的时候,会出现报错:
UnicodeEncodeError: 'ascii' codec can't encode character '\U0001f680' in position 99: ordinal not in`
解决步骤:
1、命令前添加:PYTHONIOENCODING=utf-8
例如:PYTHONIOENCODIN在报错的文件开头添加G=utf-8 python train.py
2、在报错的文件开头添加
import sys
import importlib
importlib.reload(sys)
import codecs
sys.stdout = codecs.getwriter("utf-8")(sys.stdout.detach())
15、共需修改的代码文件

(三)在Kaggle上部署项目
1、删除 .cache 文件
检查数据集中是否存在 .cache文件,若有,则进行删除。

2、把源码本地打包成.zip格式上传到Kaggle的Datasets上
注:上传时需要挂代理/梯子

3、新建一个笔记本(notebook),用来运行代码

4、使用GPU

5、部署环境
!pip install -U -r /kaggle/input/yolov5-animals/yolov5-6.0/requirements.txt

注意:第一次运行上述代码时,可能会失败,这是由于有的环境包的版本与其他包有冲突,那么kaggle会自动匹配不冲突的版本并进行下载。因此第一次运行失败后,应重启内核,该按钮位置如下图所示:
之后再次运行部署环境的命令即可。(如果还是出现红色字体报错,则重复以上操作,直至不报错)

6、运行测试
先定义epochs=5,看代码是否能正常运行。
!python /kaggle/input/yolov5-animals/yolov5-6.0/train.py --data /kaggle/input/yolov5-animals/yolov5-6.0/data/mydata.yaml --batch-size 32 --epochs 5 --cfg /kaggle/input/yolov5-animals/yolov5-6.0/models/yolov5s.yaml --weights /kaggle/input/yolov5-animals/yolov5-6.0/weights/yolov5s6.pt
'''
!python /kaggle/input/yolov5-animals/yolov5-6.0/train.py
--data /kaggle/input/yolov5-animals/yolov5-6.0/data/mydata.yaml
--batch-size 32
--epochs 5
--cfg /kaggle/input/yolov5-animals/yolov5-6.0/models/yolov5s.yaml
--weights /kaggle/input/yolov5-animals/yolov5-6.0/weights/yolov5s6.pt
'''
如果遇到以下错误:

则使用以下命令把对应文件复制到 /kaggle/working/ 下(例如这里的weights文件夹下的yolov5s6.pt文件):
!cp -r /kaggle/input/yolov5-animals/yolov5-6.0/weights /kaggle/working/
可看到weights文件夹及该文件夹里的yolov5s6.pt文件已经被复制到 /kaggle/working/ 文件夹下。

然后执行以下命令看代码是否能正常运行。
!python /kaggle/input/yolov5-animals/yolov5-6.0/train.py --data /kaggle/input/yolov5-animals/yolov5-6.0/data/mydata.yaml --batch-size 32 --epochs 5 --cfg /kaggle/input/yolov5-animals/yolov5-6.0/models/yolov5s.yaml --weights /kaggle/working/weights/yolov5s.pt
'''
!python /kaggle/input/yolov5-animals/yolov5-6.0/train.py
--data /kaggle/input/yolov5-animals/yolov5-6.0/data/mydata.yaml
--batch-size 32
--epochs 5
--cfg /kaggle/input/yolov5-animals/yolov5-6.0/models/yolov5s.yaml
--weights /kaggle/working/weights/yolov5s.pt
'''
可以看到代码能够正常无误的运行。

7、离线训练前准备
1、在notebook中把!pip install -U -r /kaggle/input/yolov5-data/yolov5_6/requirements.txt删去
2、把epochs进行修改(比如我想离线训练500轮就调为500)

8、离线训练
当调试代码成功运行后,由于深度学习模型训练都需要耗费大量的时间,而像kaggle这种线上的训练网站可能会出现内核挂掉,所以我们可以在进入训练状态后选择保存此时的版本,让模型离线训练,这样我们就只要在训练完成后下载权重文件即可。
但是需要注意的:第一,虽然kaggle每周给予每人41小时的免费gpu时长,但是一次训练最长持续12个小时,超过时长则会自动停止训练。第二,当你选择保存版本离线训练时,需要注意此时离线训练的环境也在使用你的gpu免费训练时长,如果你不退出kaggle而是继续开启gpu看着模型训练,那么你将会使用两倍的gpu训练时长。下面是离线训练的操作:
- 1、点击 Save Version

- 2、进行相关选择

- 3、点击 Save 后可以看到一个正在运行的笔记本

- 4、此时可以将环境重新改为None,避免消耗两倍的GPU时长

9、下载输出文件
kaggle的output没办法直接下载文件夹,倒是可以下载文件,当你的训练模型很多个文件的时候, 一个一个下载太慢了, 所以先将output压缩一下,然后下载就可以了。
在cell中运行以下代码:
import os
import zipfile
import datetime
def file2zip(packagePath, zipPath):
'''
:param packagePath: 文件夹路径
:param zipPath: 压缩包路径
:return:
'''
zip = zipfile.ZipFile(zipPath, 'w', zipfile.ZIP_DEFLATED)
for path, dirNames, fileNames in os.walk(packagePath):
fpath = path.replace(packagePath, '')
for name in fileNames:
fullName = os.path.join(path, name)
name = fpath + '\\' + name
zip.write(fullName, name)
zip.close()
if __name__ == "__main__":
# 文件夹路径
packagePath = '/kaggle/working/'
zipPath = '/kaggle/working/output.zip'
if os.path.exists(zipPath):
os.remove(zipPath)
file2zip(packagePath, zipPath)
print("打包完成")
print(datetime.datetime.utcnow())
(四)此次用到的项目下载
上传到Kaggle训练的源码和在本地(CPU)运行的源码在个人博客的资源可进行下载:个人博客主页下载资源
(五)记录一下可运行YOLOv5所需库的一个CPU版本
Package Version
----------------------- --------------------
absl-py 2.1.0
cachetools 5.3.3
certifi 2024.2.2
charset-normalizer 3.3.2
colorama 0.4.6
contourpy 1.1.1
cycler 0.12.1
filelock 3.13.4
fonttools 4.51.0
fsspec 2024.3.1
google-auth 2.29.0
google-auth-oauthlib 1.0.0
grpcio 1.62.1
idna 3.7
importlib_metadata 7.1.0
importlib_resources 6.4.0
Jinja2 3.1.3
kiwisolver 1.4.5
Markdown 3.6
MarkupSafe 2.1.5
matplotlib 3.7.5
mpmath 1.3.0
networkx 3.1
numpy 1.20.3
oauthlib 3.2.2
opencv-python 4.9.0.80
packaging 24.0
pandas 2.0.3
pillow 10.3.0
pip 23.3.1
protobuf 5.26.1
pyasn1 0.6.0
pyasn1_modules 0.4.0
pyparsing 3.1.2
python-dateutil 2.9.0.post0
pytz 2024.1
PyYAML 6.0.1
requests 2.31.0
requests-oauthlib 2.0.0
rsa 4.9
scipy 1.10.1
seaborn 0.13.2
setuptools 68.2.2
six 1.16.0
sympy 1.12
tensorboard 2.14.0
tensorboard-data-server 0.7.2
thop 0.1.1.post2209072238
torch 2.2.2
torchvision 0.17.2
tqdm 4.41.0
typing_extensions 4.11.0
tzdata 2024.1
urllib3 2.2.1
Werkzeug 3.0.2
wheel 0.41.2
zipp 3.18.1

![[阅读笔记1][GPT-3]Language Models are Few-Shot Learners](https://img-blog.csdnimg.cn/direct/fc2a2977c968468aab18f3dc61e8847c.png)