在 PyTorch 中,nn.CrossEntropyLoss() 是一个非常常用且功能强大的损失函数,特别适合用于多类分类问题。这个损失函数结合了 nn.LogSoftmax() 和 nn.NLLLoss() (Negative Log Likelihood Loss) 两个操作,从而在一个模块中提供完整的交叉熵损失计算功能。这不仅方便使用,也提高了数值稳定性。
功能说明
nn.CrossEntropyLoss() 计算模型输出和实际标签之间的交叉熵损失。它自动完成了 softmax 概率分布的计算和对数似然损失的计算,这意味着你应该直接将网络的原始输出(logits,即未经 softmax 层处理的输出)作为 CrossEntropyLoss 的输入。
上面这句话非常重要,这就是为什么在用交叉熵损失函数的时候,在模型的输出部分见不到softmax的原因。
参数详解
nn.CrossEntropyLoss 主要有以下几个参数:
weight(Tensor, optional): 一个手动指定的权重,用于平衡类别间的损失贡献。这在类别不平衡的情况下非常有用。size_average(bool, deprecated): 这个参数已经被弃用,用reduction参数代替。ignore_index(int, optional): 指定一个类别索引,对于这个类别的目标(target),损失将不会被计算。这常用于忽略特定的类别。reduce(bool, deprecated): 这个参数也已经被弃用,用reduction参数代替。reduction(str, optional): 指定损失的计算模式。可以是 ‘none’(无操作),‘mean’(计算损失的均值,是默认设置)或 ‘sum’(计算损失的总和)。
使用示例
下面是一个使用 nn.CrossEntropyLoss 的简单例子。假设我们有一个分类问题,目标是将输入分类到三个类别中的一个:
import torch
import torch.nn as nn
# 假设我们有3个类别,batch_size为4
data = torch.randn(4, 3) # 输入,来自某个神经网络的原始输出,形状为(batch_size, num_classes)
targets = torch.tensor([0, 2, 1, 0]) # 实际的标签,形状为(batch_size,)
# 创建交叉熵损失函数实例
criterion = nn.CrossEntropyLoss()
# 计算损失
loss = criterion(data, targets)
print(loss) # 输出:tensor(1.6401)
数学原理
对于每个样本 (i),假设 (C) 是类别总数,交叉熵损失定义为:
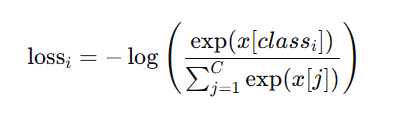
这里 (x[class_i]) 是模型输出的第 (i) 个样本对应其真实类别 (class_i) 的 logit。交叉熵损失将这些 logits 转换为正规化的概率分布,然后计算其对数似然。
应用场景
这个损失函数是处理多类分类问题的标准选择之一,特别是当你有一个多类的标签目标时。由于其数学上的稳定性,它在训练深度学习模型时非常受欢迎。使用它可以直接处理 logits,无需单独计算 softmax,从而在实际应用中减少计算量和增加数值稳定性。