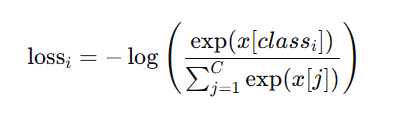1、基于windows 的ISAM标注
直接下载安装包,解压后即可使用
链接:https://pan.baidu.com/s/1u_6jk-7sj4CUK1DC0fDEXQ
提取码:c780

2、标注结果转yolo格式
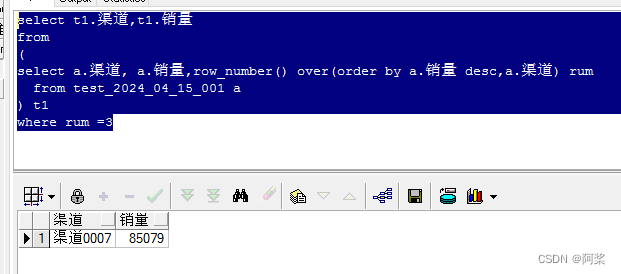
通过ISAM标注后的json文件路径

原始json格式如下:
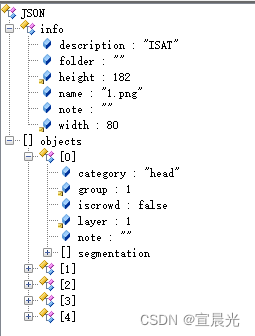
ISAM.json 转 yolo.txt 代码如下:
注意提前设置好自己的分类category_mapping 、原始路径及目标路径
import json
import os
# 定义类别名称与ID号的映射
# 需要注意的是,不需要按照ISAT的classesition.txt里面的定义来
# 可以选择部分自己需要的类别, ID序号也可以重新填写(从0开始)
category_mapping = {"hand":0, "body": 1, "head":2,"foot":3,"qunzi":4,"hair":5,"hat":6,"package":7,"huxu":8,"glass":9,"tool":10}
# ISAT格式的实例分割标注文件
ISAT_FOLDER = "./isam/source/"
# YOLO格式的实例分割标注文件
YOLO_FOLDER = "./isam/dest"
# 创建YoloV8标注的文件夹
if not os.path.exists(YOLO_FOLDER):
os.makedirs(YOLO_FOLDER)
# 载入所有的ISAT的JSON文件
for filename in os.listdir(ISAT_FOLDER):
if not filename.endswith(".json"):
# 不是json格式, 跳过
continue
# 载入ISAT的JSON文件
with open(os.path.join(ISAT_FOLDER, filename), "r") as f:
isat = json.load(f)
# 提取文件名(不带文件后缀)
image_name = filename.split(".")[0]
# Yolo格式的标注文件名, 后缀是txt
yolo_filename = f"{image_name}.txt"
# 写入信息
with open(os.path.join(YOLO_FOLDER, yolo_filename), "w") as f:
# 获取图像信息
# - 图像宽度
image_width = isat["info"]["width"]
# - 图像高度
image_height = isat["info"]["height"]
# print(isat["objects"])
# 获取实例标注数据
for annotation in isat["objects"]:
# 获取类别名称
category_name = annotation["category"]
# print(category_name)
# 如果不在类别名称字典里面,跳过
if category_name not in category_mapping:
continue
# 从字典里面查询类别ID
category_id = category_mapping[category_name]
# 提取分割信息
segmentation = annotation["segmentation"]
segmentation_yolo = []
# 遍历所有的轮廓点
print(segmentation)
for segment in segmentation:
# 提取轮廓点的像素坐标 x, y
x, y = segment
# 归一化处理
x_center = x/image_width
y_center = y/image_height
# 添加到segmentation_yolo里面
segmentation_yolo.append(f"{x_center:.4f} {y_center:.4f}")
segmentation_yolo_str = " ".join(segmentation_yolo)
# 添加一行Yolo格式的实例分割数据
# 格式如下: class_id x1 y1 x2 y2 ... xn yn\n
f.write(f"{category_id} {segmentation_yolo_str}\n")转化后文件内容:

3、准备训练数据
注意安装依赖
pip install tqdm -i https://mirrors.aliyun.com/pypi/simple
import os
import random
from tqdm import tqdm
# 指定 images 文件夹路径
image_dir = "./isam/images"
# 指定 labels 文件夹路径
label_dir = "./isam/labels"
# 创建一个空列表来存储有效图片的路径
valid_images = []
# 创建一个空列表来存储有效 label 的路径
valid_labels = []
# 遍历 images 文件夹下的所有图片
for image_name in os.listdir(image_dir):
# 获取图片的完整路径
image_path = os.path.join(image_dir, image_name)
# 获取图片文件的扩展名
ext = os.path.splitext(image_name)[-1]
# 根据扩展名替换成对应的 label 文件名
label_name = image_name.replace(ext, ".txt")
# 获取对应 label 的完整路径
label_path = os.path.join(label_dir, label_name)
# 判断 label 是否存在
if not os.path.exists(label_path):
# 删除图片
os.remove(image_path)
print("deleted:", image_path)
else:
# 将图片路径添加到列表中
valid_images.append(image_path)
# 将label路径添加到列表中
valid_labels.append(label_path)
# print("valid:", image_path, label_path)
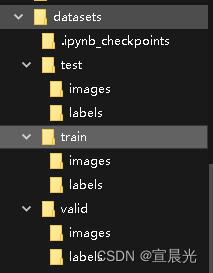
dirs = ["./isam/datasets/test", "./isam/datasets/train", "./isam/datasets/valid"]
for d in dirs:
_dir = os.path.join(d, "images")
if not os.path.exists(_dir):
os.makedirs(_dir)
_dir = os.path.join(d, "labels")
if not os.path.exists(_dir):
os.makedirs(_dir)
# 遍历每个有效图片路径
for i in tqdm(range(len(valid_images))):
image_path = valid_images[i]
label_path = valid_labels[i]
# 随机生成一个概率
r = random.random()
# 判断图片应该移动到哪个文件夹
# train:valid:test = 7:2:1
if r < 0.1:
# 移动到 test 文件夹
destination = "./isam/datasets/test"
elif r < 0.3:
# 移动到 valid 文件夹
destination = "./isam/datasets/valid"
else:
# 移动到 train 文件夹
destination = "./isam/datasets/train"
# 生成目标文件夹中图片的新路径
image_destination_path = os.path.join(destination, "images", os.path.basename(image_path))
# 移动图片到目标文件夹
os.rename(image_path, image_destination_path)
# 生成目标文件夹中 label 的新路径
label_destination_path = os.path.join(destination, "labels", os.path.basename(label_path))
# 移动 label 到目标文件夹
os.rename(label_path, label_destination_path)
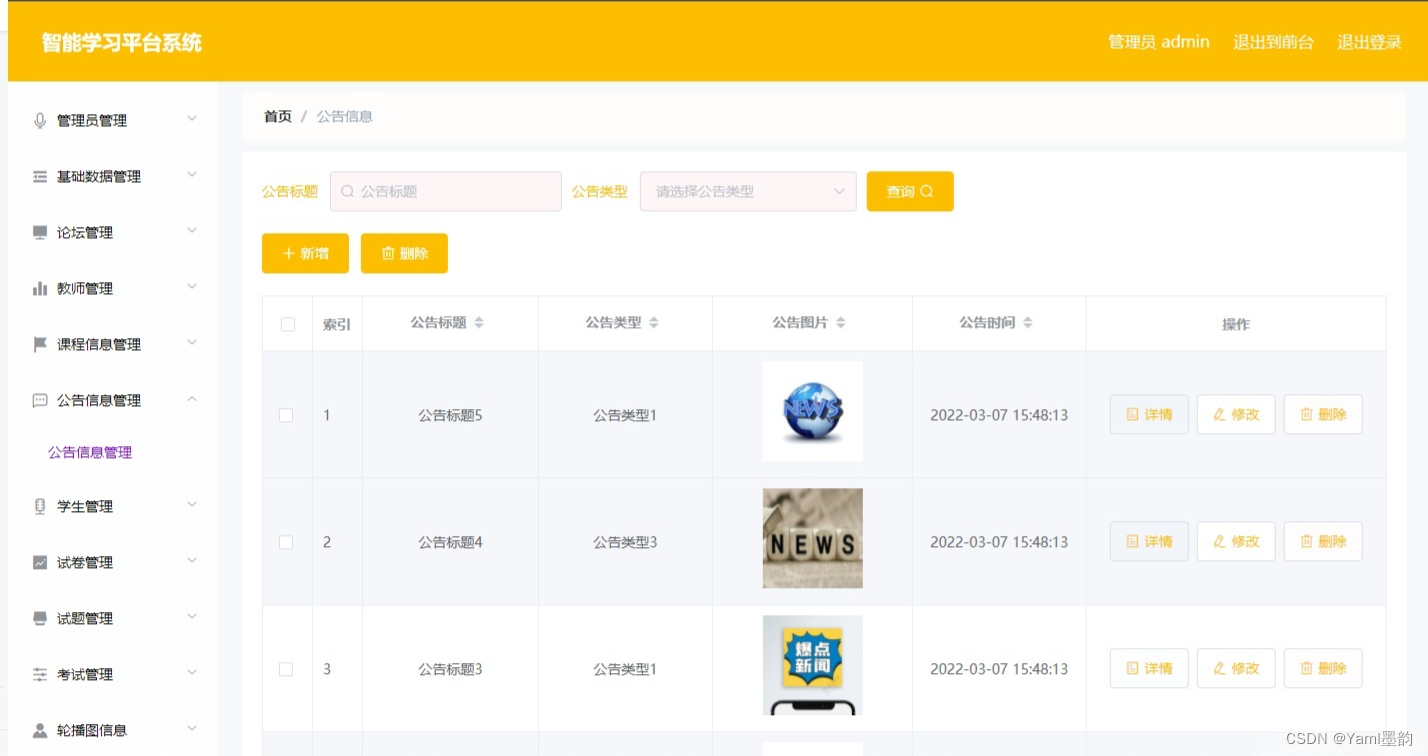
print("train images:", train_images)
# 输出有效label路径列表
print("train labels:", train_labels)数据集分割结果
4、创建conda虚拟环境
conda create -n yolov8 python=3.10
conda activate yolov8
下载yolov8.2 代码
GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
# 安装依赖
pip install ultralytics
5、准备训练配置文件
下载预训练模型,放在项目根路径
yolov8n-seg.pt
yolov8n.pt
下载ttf文件 存放位置 /root/.config/Ultralytics/Arial.ttf
在datasets目录下添加文件
1、coco128-seg.yaml 注意classes类型与之前标注的一致
# Ultralytics YOLO , AGPL-3.0 license
# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco128.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco128-seg ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets # dataset root dir
train: train/images # train images (relative to 'path') 128 images
val: valid/images # val images (relative to 'path') 128 images
test: test/images # test images (optional)
# Classes {"hand":0, "body": 1, "head":2,"foot":3,"qunzi":4,"hair":5,"hat":6,"package":7,"huxu":8,"glass":9,"tool":10}
names:
0: hand
1: body
2: head
3: foot
4: qunzi
5: hair
6: hat
7: package
8: huxu
9: glass
10: tool2、yolov8-seg.yaml 修改nc 分类个数即可
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segmenthttps://docs.ultralytics.com/tasks/segment
# Parameters
nc: 11 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)6、开始训练
在根目录下添加train.py 文件
执行 python train.py
from ultralytics import YOLO
# Load a model
model = YOLO("datasets/yolov8-seg.yaml") # build a new model from scratch
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
model = YOLO('datasets/yolov8-seg.yaml').load('yolov8n.pt') # build from YAML and transfer weights
# Use the model
model.train(data="datasets/coco128-seg.yaml", task="segment",mode="train",workers=0,batch=4,epochs=300,device=0) # train the model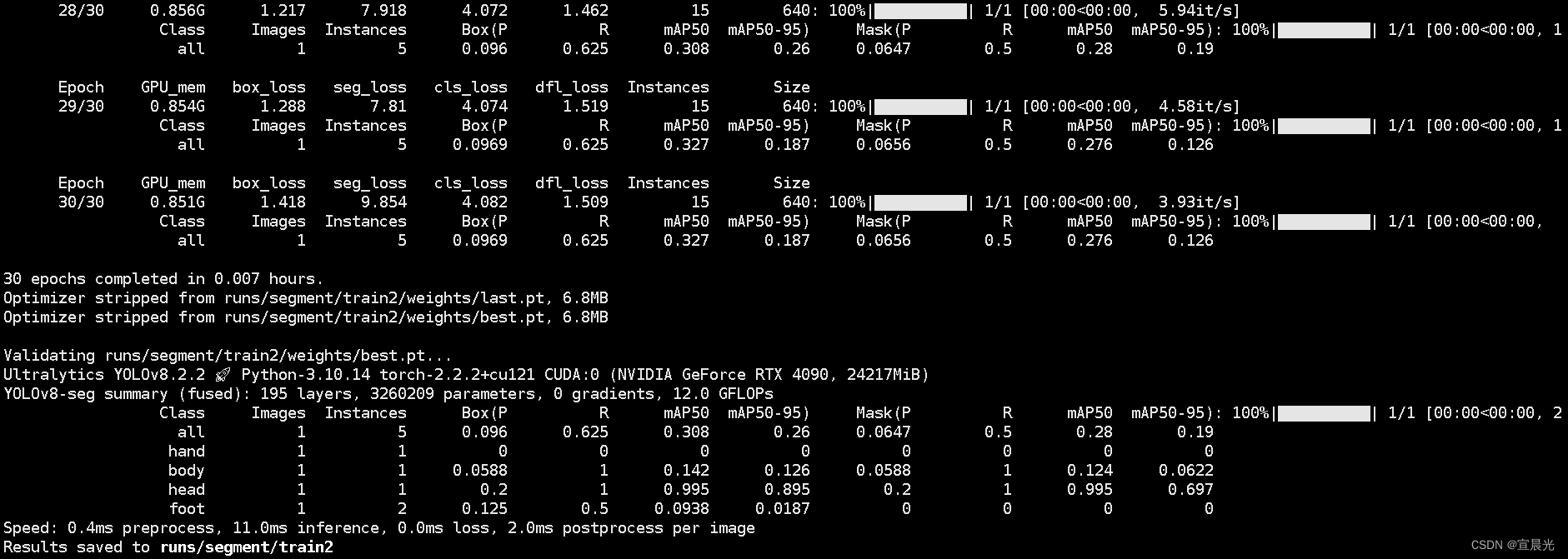
训练结果保存位置 Results saved to runs/segment/trainX
7、运行模型预测
编写 predict.py 脚本,执行 python predict.py
from ultralytics import YOLO
import cv2
# Load a model
model = YOLO('yolov8n-seg.pt') # load an official model
model = YOLO('runs/segment/train/weights/best.pt') # load a custom trained
# Predict with the model
result = model('14.png',save=True) # predict on an image预测结果保存位置 Results saved to runs/segment/predict
8、导出onnx文件
# export_onnx.py
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-seg.pt') # load an official model
model = YOLO('runs/segment/train/best.pt') # load a custom trained
# Export the model
model.export(format='onnx')本文参考:
ISAM一款基于SAM的交互式半自动图像分割标注工具
SAM标注+yolov8-seg实例分割的实时检测-知乎
yolov8文档
![[阅读笔记1][GPT-3]Language Models are Few-Shot Learners](https://img-blog.csdnimg.cn/direct/fc2a2977c968468aab18f3dc61e8847c.png)