就在昨晚,Meta官宣了开源的Llama 3 8B和70B版本。
8B模型在多项指标中超越了Gemma 7B和Mistral 7B Instruct,而70B模型则超越了闭源的Claude 3 Sonnet,和Gemini Pro 1.5。
此外Meta还有一个still training的400B+参数版本,它和GPT-4以及Claude 3的超大杯版本Opus性能差不多,最重要的是,它即将开源!
分享几个网站
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
怪兽级性能
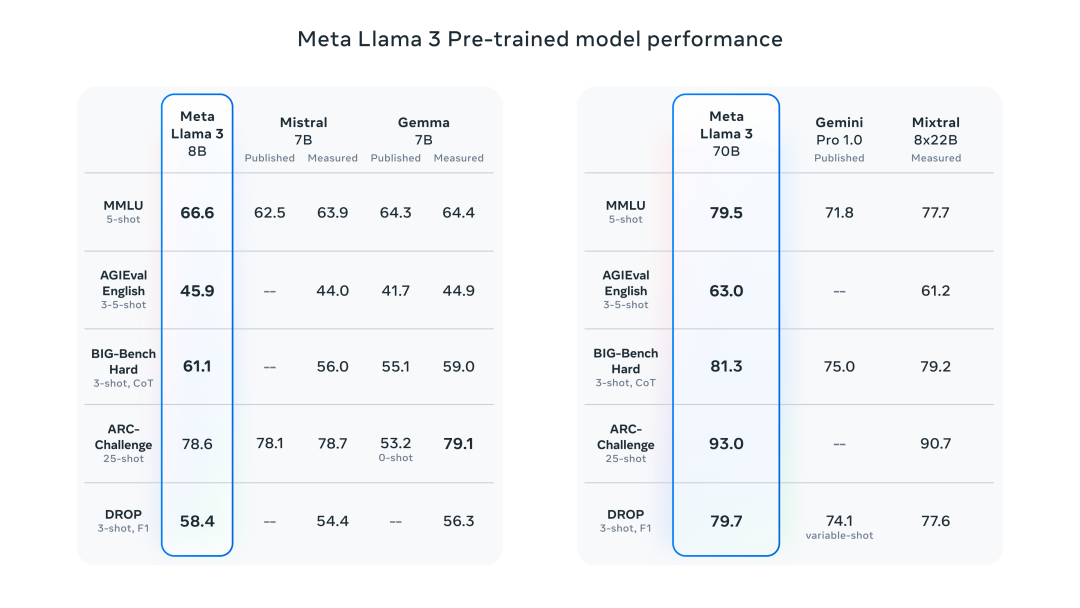
由于预训练和训练方法的改进,Llama 3 8B和70B是当今同参数规模的SOTA模型。它大大降低了错误拒绝率,改善了一致性,并增加了模型响应的多样性。此外,在推理、代码生成和指令跟踪等功能的极大改进,使Llama 3更加易于操控。
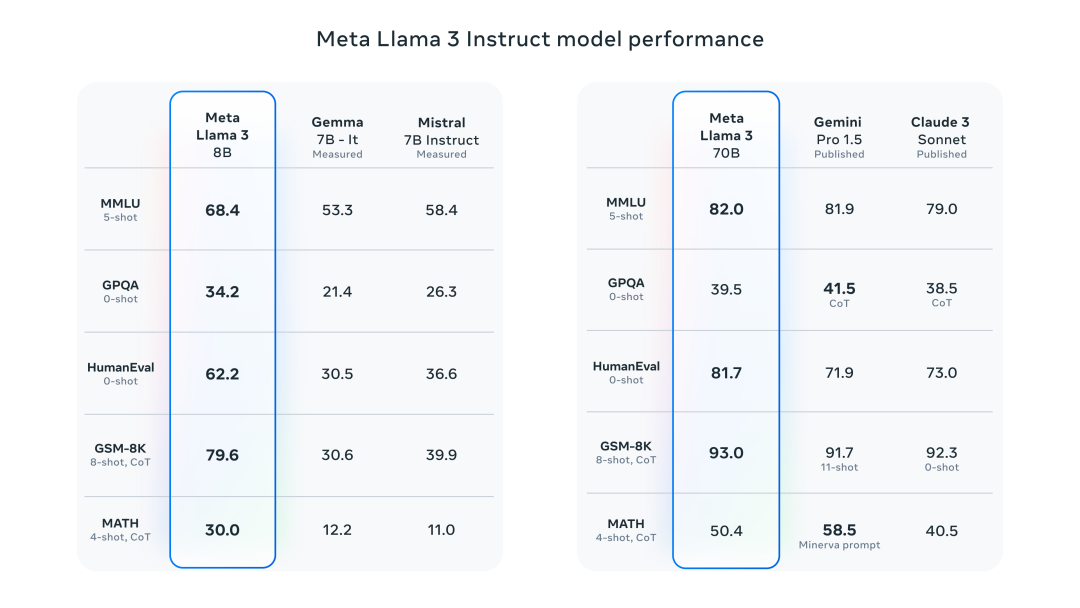
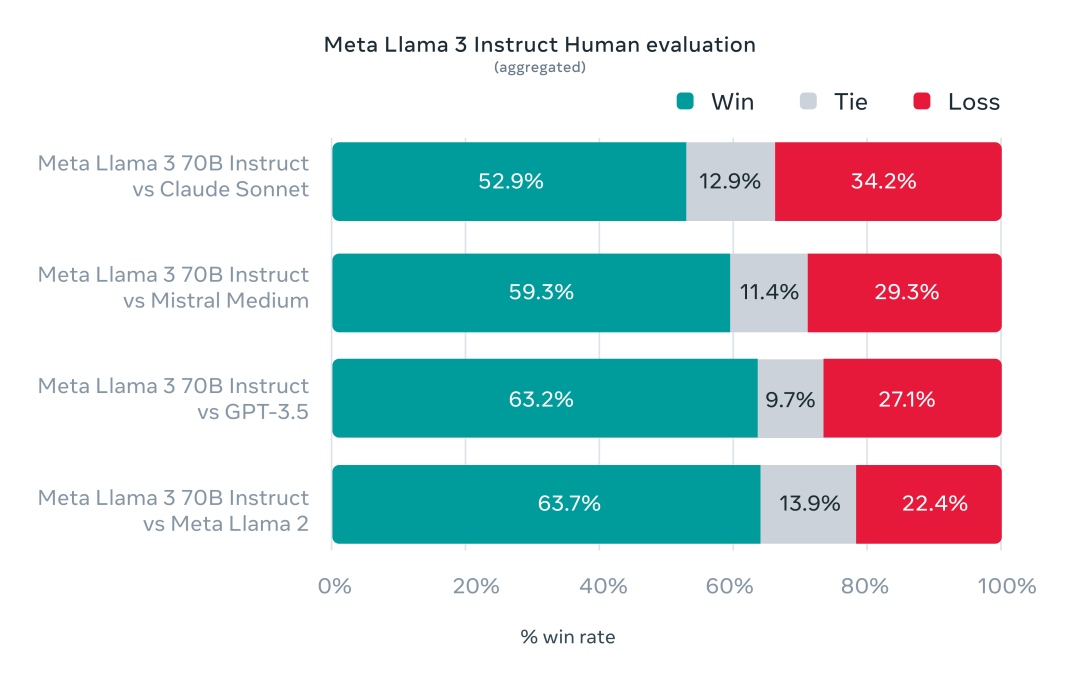
在Llama 3的开发中,为了寻求对实际场景的优化。Meta开发了一套新的高质量人类评估集,包含1800个prompts,覆盖12个关键用例,如寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作等。为防止模型过度拟合,连模型开发团队也无法访问此评估集。下图展示了与Claude Sonnet、Mistral Medium和GPT-3.5的比较。
模型架构
Llama 3 选择了经典的Decoder-only的Transformer架构。与Llama 2相比,Llama 3做了几个关键的改进,包括:
1、使用具有128K token词汇表的tokenizer,可以更有效地对语言进行编码。
2、在 8B 和 70B 大小的模型上采用了分组查询注意力 (GQA),提高了Llama 3的推理效率。
3、在8192个token的序列上训练模型,使用掩码确保自注意力不会跨越文档边界。这也是美中不足的一点,8k的上下文窗口依然有点过时,不过随着开源社区的努力,这个问题可能很快就会被解决。

训练数据
Llama 3在开源的 15T Token上进行了预训练,比Llama 2使用的数据集大7倍,并且包含4倍多的代码,其中超过5%的预训练数据集由涵盖30多种语言的高质量非英语数据组成。为确保使用高质量数据,开发了多种数据过滤技术,包括启发式和NSFW过滤器,以及语义去重和质量预测文本分类器。
此外,通过广泛的实验确定了数据混合的最佳方法,以优化Llama 3在多种应用场景中的表现。预训练数据的更新截止到2023年3月(8B)和12月(70B)。
微调数据包括开源的指令数据集,以及超过1000万个人工注释的示例。
此外,官网上还附上了这样一句话:“预训练和微调数据集均不包含Meta用户数据”,可以说是求生欲拉满了。

此外,Meta官方还公布了模型的能耗:在H100-80GB上累计计算了7.7M GPU小时,估计总排放量为2290 吨二氧化碳当量,并且附上:“100%的碳排放被Meta的可持续发展计划抵消”,再来一波求生欲!
指令微调
为了最大化预训练模型在聊天用例中的潜力,采用了监督微调(SFT)、拒绝采样、近端策略优化(PPO)和直接策略优化(DPO)的组合方法。通过精心整理SFT中的提示和PPO与DPO的偏好排名,显著提升了模型的性能和对齐能力。特别是,通过PPO和DPO学习偏好排名,显著提高了Llama 3在推理和编码任务的表现,使模型能够更准确地选择正确的答案。
Llama3在线体验
目前,Llama 3的两个版本可以在官网下载:
https://llama.meta.com/llama-downloads/
https://github.com/meta-llama/
也可以在Meta官网体验网页版Llama 3:
https://www.meta.ai/
此外,Llama 3模型将很快在AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM和Snowflake上推出,并得到AMD、AWS、Dell、Intel、NVIDIA和高通提供的硬件平台的支持。
期待Llama 3 400B+
Meta称 “Llama 3 8B和70B型号标志着我们计划为Llama 3发布的产品的开始,我们最大的模型有超过 400B 个参数,虽然这些模型仍在训练中”,并且公布了400B+模型早期检查点的性能。
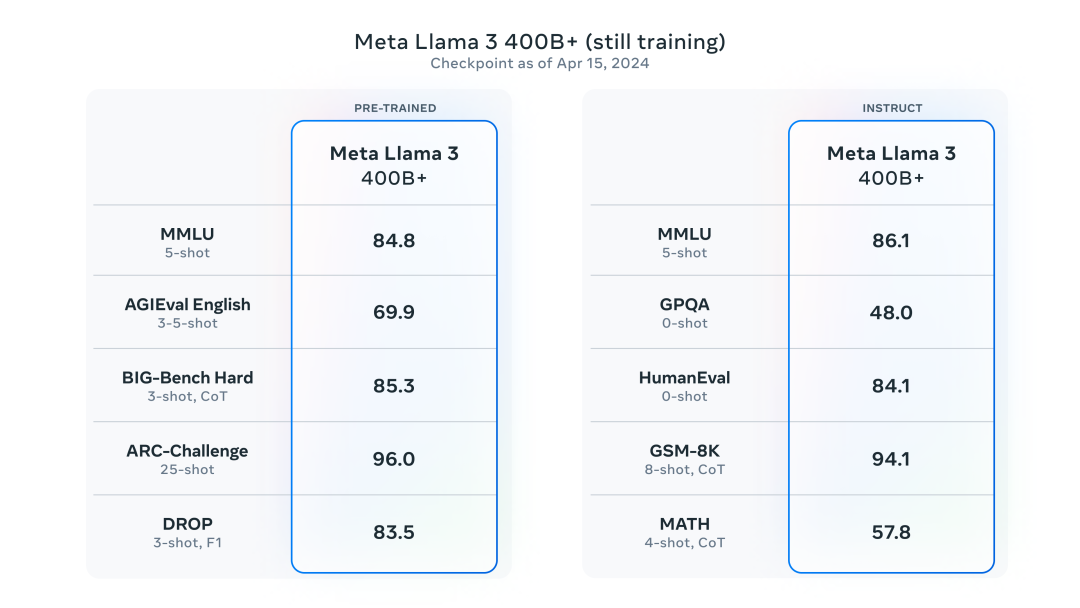
有网友把它和GPT-4以及Gemini做了个比较。
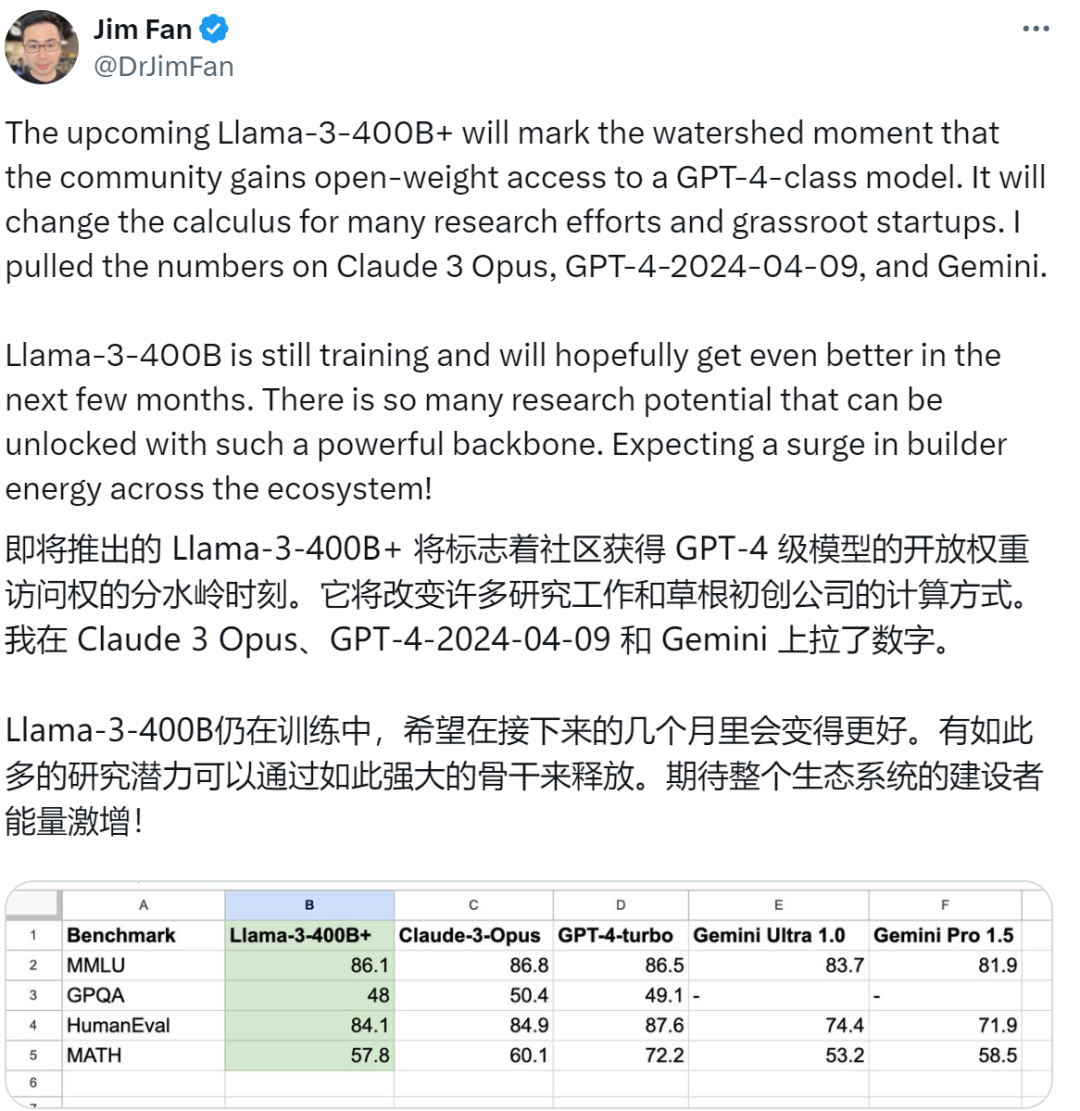
不知道奥特曼这回慌不慌,可能只有GPT-5能压住它了。

现在我们可以期待,“开源版GPT-4”可能真的要来了!