基本介绍
栈内存一般是由Go编译器自动分配和释放,其中存储着函数的入参和局部变量,这些参数和变量随着函数调用而创建,当调用结束后也会随之被回收。通常开发者不需要关注内存是分配在堆上还是栈上,这部分由编译器在编译阶段通过逃逸分析来决定。但是了解其原理还是很重要的。一方面可以帮助我们有意识写出更高效的可执行代码,另一方面参考源码中的一些精妙设计也可以给自己一定的思路。
设计原理
寄存器
寄存器是CPU中的稀缺资源,他的存储能力非常有限,但是能提供最快的读写速度,充分利用寄存器的读写速度可以构建高性能的应用程序。寄存器在物理机上非常有限,然后Go的栈操作仍然用了两个以上寄存器,充分说明栈内存的重要性。
栈寄存器是CPU寄存器的一种,用于跟踪函数的调用栈。Go语言的汇编代码包括了BP和SP两个寄存器,他们分别存储了栈的基址指针和栈顶指针,BP和SP之间的部分就是函数的调用栈。
堆的内存增长是从小往大增长,而栈的增长方向是相反的,导致在做栈指令操作的时候将 SP 减小反而是将栈帧增大。这样做的好处就是便于堆和栈可动态共享那段内存区域。

当应用程序申请或者释放栈内存时只需要修改 SP 寄存器的值,这种线性的内存分配方式与堆内存相比更加快速,仅会带来极少的额外开销。
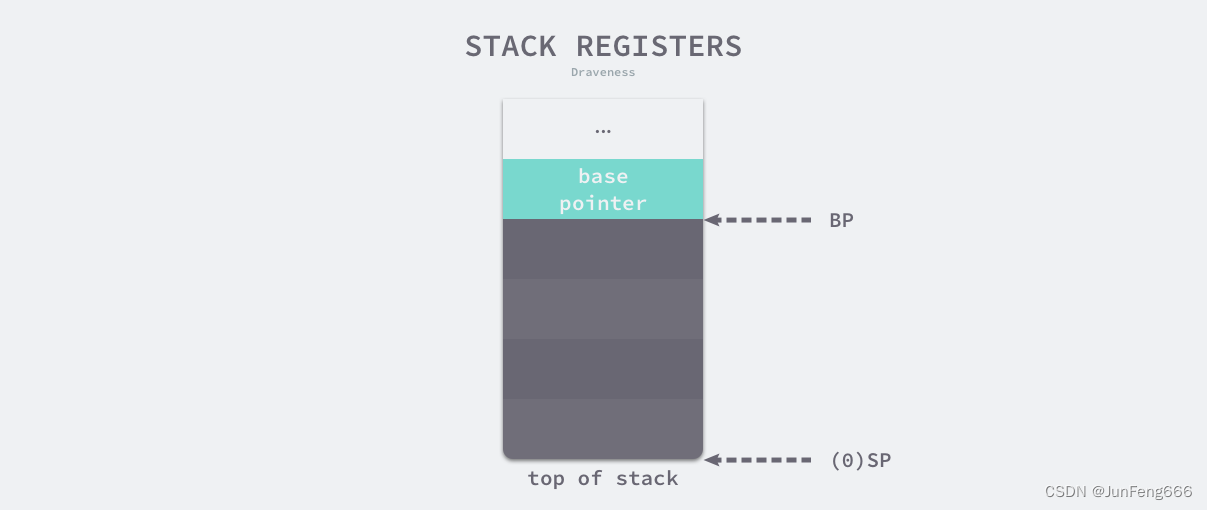
在函数执行过程中,CPU会通过栈寄存器来来访问和操作栈内存,当函数被调用时,CPU会将函数的入参和返回值地址压入栈中,并将SP指向新的栈顶。在函数内部,CPU可以通过BP来来访问栈中的参数和局部变量,当函数返回后,CPU会将栈顶元素弹出栈,将SP指针恢复到函数调用前的状态。
栈寄存器和栈内存密切相关,栈寄存器用于管理栈内存的指针,栈内存则用于存储函数调用时的参数和局部变量。
// (x86)系统下,栈帧布局
// +------------------+
// | args from caller |
// +------------------+ <- frame->argp
// | return address |
// +------------------+
// | caller's BP (*) | (*) if framepointer_enabled && varp < sp
// +------------------+ <- frame->varp
// | locals |
// +------------------+
// | args to callee |
// +------------------+ <- frame->sp
栈操作
栈初始化
// linux上_NumStackOrders=4,表示四种大小的栈,分别是2kb、4kb、8kb、16kb
var stackpool [_NumStackOrders]struct {
item stackpoolItem
// 内存对齐
_ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte
}
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}
可以看到栈初始化过程中有两个关键变量,stackpool和stackLarge,其中stackpool是全局的栈缓存,用来分配小于32k的内存,stackLarge是大栈缓存,用来分配大于32k的内存(此处可见栈分配部分代码),这两部分的内存都是从全局的heap_中申请,所以也可以认为Go中的栈内存也是分配在堆上的。
如果仅仅用这两个全局变量来分配栈内存,那么可预见的是在程序运行期间申请和释放栈空间,必然需要频繁加锁,会影响程序执行效率,所以Go在mcache,线程缓存级别增加了一级栈缓存,在创建goroutine的时候会给自己分配一个栈空间,详见malg(),大部分情况下每个goroutine只需要在自己的栈空间申请内存即可,不需要再竞争锁。具体结构可见。mache中的栈缓存并非单独从mheap中申请,
stackinit函数在schedinit中调用
func schedinit() {
...
stackinit()
...
}
运行时使用全局的 runtime.stackpool 和线程缓存中的空闲链表分配 32KB 以下的栈内存,使用全局的 runtime.stackLarge 和堆内存分配 32KB 以上的栈内存,提高本地分配栈内存的性能。
栈分配
运行会在创建goroutine的时候调用runtime.stackalloc来预先分配一个大小足够的内存空间。
// Allocate a new g, with a stack big enough for stacksize bytes.
// newproc()调用newproc1(),newproc1()调用malg(),在调用malg的时候会传入_StackMin = 2048,即最小栈2k
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
// 这里会在 stacksize 的基础上为每个栈预留系统调用所需的内存大小
// _StackSystem在 Linux/Darwin 上( _StackSystem == 0 )本行不改变 stacksize 的大小
stacksize = round2(_StackSystem + stacksize)
systemstack(func() {
// 为新分配的G对象分配栈内存
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + _StackGuard
newg.stackguard1 = ^uintptr(0)
// Clear the bottom word of the stack. We record g
// there on gsignal stack during VDSO on ARM and ARM64.
*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0
}
return newg
}
stackalloc会根据分配栈内存的大小,分别用不同的方案分配栈内存
- 如果申请的栈内存<32k,会从全局栈缓存
stackpool或线程缓存的栈上分配 - 否则会直接从大栈
stackLarge分配
func stackalloc(n uint32) stack {
thisg := getg()
...
// 在linux上_FixedStack=2048,_NumStackOrders=4,_StackCacheSize=32 * 1024
// 如果申请的栈内存<32k,则通过stackpool或mcache上的缓存栈分配
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
// 一直除到n<=2048,order记录除了几次
// order=0表示2kb,order=1表示4kb,以此类推
for n2 > _FixedStack {
order++
n2 >>= 1
}
// stackNoCache表示是否禁止线程缓存上的栈,常量,默认值是0
// thisg.m.p = 0会在系统调用和改变P的个数的时候调用,满足条件就从stackpool上分配
// preemptoff != "", 在 GC 的时候会进行设置,表示如果在 GC 那么从 stackpool 分配
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
// 从stackpool中分配对应大小的栈,如果stackpool空间不足,会从堆上申请
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
// 获取执行g的P上的mcache
c := thisg.m.p.ptr().mcache
// 在线程缓存上获取预分配大小的栈
x = c.stackcache[order].list
if x.ptr() == nil {
// 从堆上申请新的内存填充到线程缓存中
stackcacherefill(c, order)
x = c.stackcache[order].list
}
// 移除空闲栈链表上的第一个节点,表示已分配
c.stackcache[order].list = x.ptr().next
// 更新分配栈后的空闲栈大小
c.stackcache[order].size -= uintptr(n)
}
// 如果>=32k,则通过stackLarge分配
} else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
// 如果有空闲的栈内存,直接从stackLarge中分配
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
// 如果没有空闲的栈,则直接从堆上申请新的
if s == nil {
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
}
}
需要注意的是,因为 OpenBSD 6.4+ 对栈内存有特殊的需求,所以只要我们从堆上申请栈内存,需要调用 runtime.osStackAlloc 做一些额外处理,然而其他的操作系统就没有这种限制了。
stackalloc中有两个重要的函数调用再展开看看
// 从stackpool中分配栈
func stackpoolalloc(order uint8) gclinkptr {
// 获取对应大小的栈链表,并拿到第一个节点
list := &stackpool[order].item.span
s := list.first
if s == nil {
// 如果没有空闲的栈,则从堆中申请新的mspan
s = mheap_.allocManual(_StackCacheSize>>_PageShift, spanAllocStack)
...
osStackAlloc(s)
s.elemsize = _FixedStack << order
// 新申请的栈内存,写入manualFreeList,manualFreeList是一个单向链表
for i := uintptr(0); i < _StackCacheSize; i += s.elemsize {
x := gclinkptr(s.base() + i)
x.ptr().next = s.manualFreeList
s.manualFreeList = x
}
// 插入stackpool
list.insert(s)
}
// 从mspan获取object(可见mspan的定义:mspan是一串连续page,然后按照size_class分割成固定大小的object),manualFreeList用来维护栈内存
x := s.manualFreeList
if x.ptr() == nil {
throw("span has no free stacks")
}
// 从manualFreeList上删除第一个节点
s.manualFreeList = x.ptr().next
// mspan分配对象+1
s.allocCount++
// 如果分配完,mspan中栈对象已分配完,从stackpool中删除该mspan
if s.manualFreeList.ptr() == nil {
// all stacks in s are allocated.
list.remove(s)
}
return x
}
// 填充mcache中的栈缓存
func stackcacherefill(c *mcache, order uint8) {
if stackDebug >= 1 {
print("stackcacherefill order=", order, "\n")
}
// Grab some stacks from the global cache.
// Grab half of the allowed capacity (to prevent thrashing).
var list gclinkptr
var size uintptr
lock(&stackpool[order].item.mu)
// _StackCacheSize=32k,此处先从stackpool中获取一半即16k大小,组成单向链表,放到mcache中
// 猜测这里的一半是和空间利用率有关,直接分配全部32k可能会造成浪费,如果当前栈内存使用率不足1/4,那么也会触发缩容,每次缩1/2
for size < _StackCacheSize/2 {
x := stackpoolalloc(order)
x.ptr().next = list
list = x
// _FixedStack=2048
size += _FixedStack << order
}
unlock(&stackpool[order].item.mu)
// 放入mcache中
c.stackcache[order].list = list
c.stackcache[order].size = size
}
栈分配时的
order和堆分配的sizeclass有异曲同工之妙,一方面可以减少不同goroutine获取不同大小栈的锁冲突,另一方面可以预先缓存对应大小的内存以便快速获取。在Go的内存分配中有很多类似的思路:通过预分配,分级等减少锁冲突,提高内存分配效率
栈扩容
编译器会在 cmd/internal/obj/x86.stacksplit 中为函数调用插入 runtime.morestack 运行时检查,它会在几乎所有的函数调用之前检查当前 Goroutine 的栈内存是否充足,如果当前栈需要扩容,我们会保存一些栈的相关信息并调用 runtime.newstack 创建新的栈:
func newstack() {
thisg := getg()
... // 校验逻辑
gp := thisg.m.curg
...
morebuf := thisg.m.morebuf
// 初始化寄存器相关变量
thisg.m.morebuf.pc = 0
thisg.m.morebuf.lr = 0
thisg.m.morebuf.sp = 0
thisg.m.morebuf.g = 0
// 校验是否被抢占
preempt := stackguard0 == stackPreempt
if preempt {
// 校验M是否可以被安全抢占,如果不可以安全抢占,那么就不执行抢占,让当前goroutine继续执行,等下次再抢占
// canPreemptM:return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
// 如果M上没有锁,或没有在进行内存分配,或没有禁止抢占,或P的状态是Running,认为可以安全抢占
if !canPreemptM(thisg.m) {
// Let the goroutine keep running for now.
// gp->preempt is set, so it will be preempted next time.
gp.stackguard0 = gp.stack.lo + _StackGuard
// 触发调度器调度
gogo(&gp.sched) // never return
}
}
// 如果被抢占,且可以安全抢占,说明当前goroutine不需要执行,也不需要栈扩容
if preempt {
// 需要收缩栈
if gp.preemptShrink {
// We're at a synchronous safe point now, so
// do the pending stack shrink.
gp.preemptShrink = false
shrinkstack(gp)
}
// 被runtime.suspendG挂起后,被动让出当前处理器的控制权
if gp.preemptStop {
preemptPark(gp) // never returns
}
// 主动让出当前处理器的控制权
gopreempt_m(gp) // never return
}
// 到此处,如果当前goroutine不需要被抢占,那么就说明需要新的栈内存来执行代码和初始化变量,此时继续往下执行进行扩容
oldsize := gp.stack.hi - gp.stack.lo
// 新栈空间按照原来的2倍扩容
newsize := oldsize * 2
// 如果仍然不够用,则继续按照2倍扩容
if f := findfunc(gp.sched.pc); f.valid() {
max := uintptr(funcMaxSPDelta(f))
needed := max + _StackGuard
used := gp.stack.hi - gp.sched.sp
for newsize-used < needed {
newsize *= 2
}
}
...
// 栈溢出检测
// maxstacksize 64位是1G,maxstackceiling=2*maxstacksize
// maxstackceiling 用来兜底,防止用户调用runtime.setMaxStack()把maxstacksize设置得过大
if newsize > maxstacksize || newsize > maxstackceiling {
...
}
// 状态置为_Gcopystack
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
// 扩容并拷贝
copystack(gp, newsize)
if stackDebug >= 1 {
print("stack grow done\n")
}
// 状态置为_Grunning
casgstatus(gp, _Gcopystack, _Grunning)
// 触发调度器调度
gogo(&gp.sched)
}
newstack主要流程:
- 校验是否可以被安全抢占,如果可以被安全抢占,就直接调用
runtime.gogo触发调度器的调度 - 如果GC的时候被
runtime.scanstack标记了需要收缩栈,则调用shrinkstack()缩容,并把preemptShrink状态标记为false,等待下次GC扫描 - 如果GC的时候当前goroutine被
runtime.suspendG挂起,则被动让出当前处理器的控制权,并把状态置为_Gpreempted,之后会在下一次调用runtime.suspendG的时候把状态改回到_GWaiting, - 调用gopreempt_m,主动让出当前处理器的控制权
如果当前gorouine不需要被抢占,那么就说明需要扩容新的栈空间,来执行函数代码和变量初始化
接下来再看copystack,调用该函数之前需要先把g的状态置为Gcopystack
func copystack(gp *g, newsize uintptr) {
old := gp.stack
...
// 旧栈高位指针-G对象栈顶指针,计算当前已使用栈内存大小(参考上面寄存器和栈帧布局理解)
used := old.hi - gp.sched.sp
// 分配新的栈空间
new := stackalloc(uint32(newsize))
// 借助adjustinfo来调整栈空间
var adjinfo adjustinfo
// 存放旧栈
adjinfo.old = old
// 新旧栈的调整距离,用该值控制指针移动距离
adjinfo.delta = new.hi - old.hi
// sudog represents a g in a wait list, such as for sending/receiving on a channel.
ncopy := used
if !gp.activeStackChans {
adjustsudogs(gp, &adjinfo)
} else {
// 到这里代表有被阻塞的 G 在当前 G 的channel 中,所以要防止并发操作,需要获取 channel 的锁
// 在所有 sudog 中找到地址最大的指针
adjinfo.sghi = findsghi(gp, old)
// 对所有 sudog 关联的 channel 上锁,然后调整指针,并且复制 sudog 指向的部分旧栈的数据到新的栈上
ncopy -= syncadjustsudogs(gp, used, &adjinfo)
}
// 将旧栈中的数据整片拷贝到新栈中
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// 调整ctxt,defer和panic的指针
// 调用 runtime.adjustpointer,该函数会利用 runtime.adjustinfo 计算的新栈和旧栈之间的内存地址差来调整指针
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
// 把G上的栈替换为新栈
gp.stack = new
gp.stackguard0 = new.lo + _StackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// 调整新栈上的指针
gentraceback(^uintptr(0), ^uintptr(0), 0, gp, 0, nil, 0x7fffffff, adjustframe, noescape(unsafe.Pointer(&adjinfo)), 0)
// 释放旧栈空间
stackfree(old)
}
总结一下栈扩容的步骤:
- 前置校验,如果当前goroutine可以被抢占,那么就停止栈扩容
- 按照最小两倍来重新计算需要的栈内存
- 暂停当前goroutine的执行
- 新建一个栈空间并迁移数据:复制旧栈数据到新栈,更改指向旧栈空间的指针指向新栈空间
- 触发系统调度,恢复当前goroutine的执行
栈缩容
栈的缩容发生在GC扫描阶段,在scanstack函数内触发缩容
func scanstack(gp *g, gcw *gcWork) int64 {
// 当我们拥有所有栈帧的精确指针映射时,认为是此时收缩栈是安全的
if isShrinkStackSafe(gp) {
// 直接缩容
shrinkstack(gp)
} else {
// 在newobject中执行缩容
gp.preemptShrink = true
}
}
接下来看具体是怎么缩容的
func shrinkstack(gp *g) {
... // 校验逻辑
oldsize := gp.stack.hi - gp.stack.lo
// 缩容到原来的一半
newsize := oldsize / 2
// 如果缩容的大小小于栈的最小值(2KB),就停止
if newsize < _FixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
// 如果已使用内存超过可用空间的1/4,也停止缩容
if used := gp.stack.hi - gp.sched.sp + _StackLimit; used >= avail/4 {
return
}
// 调用copystack开辟新的栈,并复制数据
copystack(gp, newsize)
}
逃逸分析
代码中如果某个对象被分配到堆上,那么就称该对象发生了内存逃逸
在编译器优化中,逃逸分析是用来决定指针动态作用域的方法。Go 语言的编译器使用逃逸分析决定哪些变量应该在栈上分配,哪些变量应该在堆上分配,其中包括使用 new、make 和字面量等方法隐式分配的内存,Go 语言的逃逸分析遵循以下两个不变性(/src/cmd/compile/internal/gc/escape.go):
- 指向栈对象的指针不能存在于堆中(pointers to stack objects cannot be stored in the heap);
- 指向栈对象的指针不能在栈对象回收后存活(pointers to a stack object cannot outlive that object);
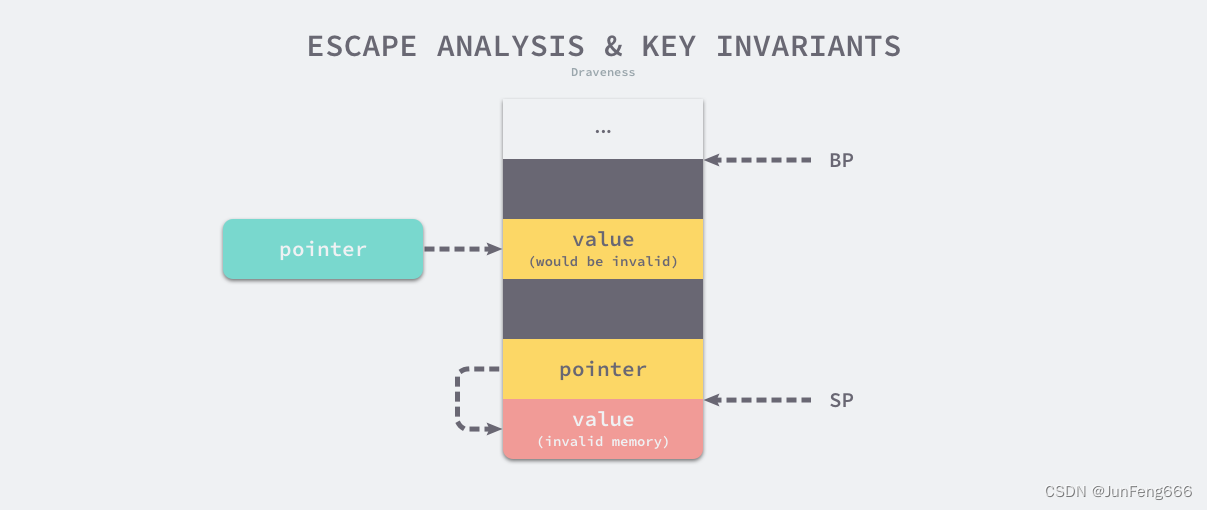
- 如果违反第一条原则,函数调用结束后,函数内分配的局部变量会被回收,那么绿色指针指向的指将不合法
- 如果违反第二条原则,函数调用结束后,粉色部分内存被回收,如果指向栈对象的指针仍然存活,那么黄色指针指向的值也将不合法
内存逃逸的影响
如果频繁发生内存逃逸,本可以分配在栈上的变量分配在了堆上,就会存在下面问题:
- 内存占用增加,由于Go的内存分配策略,堆扩容后并不会马上把内存归还给系统,所以会导致Go程序持有的内存不断增长,对于长时间不更新的系统来说,内存必然会持续增长,进而触发资源报警
- GC压力增加,分配到堆上的对象不会随着函数调用结束而释放,而会等待GC标记、扫描等步骤后才回收,会导致垃圾回收器频繁操作,影响服务稳定性
- 性能下降,堆内存分配比栈内存分配需要更多的CPU和内存资源,会导致程序性能变差
内存逃逸的原因及优化思路
以下是一些内存逃逸的case:
- 变量的生命周期超出了其作用域,当一个变量在函数外部被引用,比如被赋值给一个包级别的变量或者作为返回值,这个变量就会发生逃逸。
- 要严格限制作用域,仅在函数内部使用的变量,不要返回给外部
- 使用值而不是指针,传值会拷贝整个对象,传指针只需要拷贝指针地址,但会增加GC压力,因此需要平衡考虑,对于小对象,推荐使用值传递(参考benchmark,28B是分界线,供参考)
- 大对象的分配,对于大型的数据结构,Go 有时会选择在堆上分配内存,即使它们没有在函数外部被引用。
- 对于频繁创建和销毁的对象,可以池化,减少在堆上分配和GC的次数
- 闭包引用,如果一个函数返回一个闭包,并且该闭包引用了函数的局部变量,那么这些变量也会逃逸到堆上。
- 应当尽量避免在大循环或频繁调用的函数中使用闭包
- 接口动态分配,当一个具体类型的变量被赋值给接口类型时,由于接口的动态特性,具体的值可能会发生逃逸。
- 对于频繁创建的对象,应当尽量使用确定的类型
- 切片和 map 操作,如果对切片进行操作可能导致其重新分配内存,或者向 map 中插入数据,这些操作可能导致逃逸。
- 对于切片,如果是确定的长度,推荐使用数组
- 如果可以确定大小,在对象初始化的时候就分配好容量,避免在运行期间频繁扩容
参考
https://www.luozhiyun.com/archives/513
https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-stack-management/
https://zhuanlan.zhihu.com/p/386769009?utm_id=0
https://zhuanlan.zhihu.com/p/672733054