使用yolov5训练自己的目标检测模型
- 使用yolov5训练自己的目标检测模型
- 1. 项目的克隆
- 2. 项目代码结构
- 3. 环境的安装和依赖的安装
- 4. 数据集和预训练权重的准备
- 4.1利用labelimg标注数据和数据的准备
- 4.1.1 **labelimg介绍:**
- 4.1. 2 labelimg的安装
- 4.2 使用labelimg
- 4.2.1 数据准备
- 4.2.2 标注前的一些设置
- 4.2.3 开始标注
- 4.3 将数据集为划分训练集和验证集
- 4.4 配置文件
- 4.5 修改模型配置文件
- 4.6 获得预训练权重
- 5. 模型训练
- 5.1 开始训练
使用yolov5训练自己的目标检测模型
1. 项目的克隆
YOLOv5的代码是开源的,所以我们可以从github上download其源码。
- 本次使用的分支是master下的v5.0版本,其他版本暂未尝试,有时间的同学可自行尝试
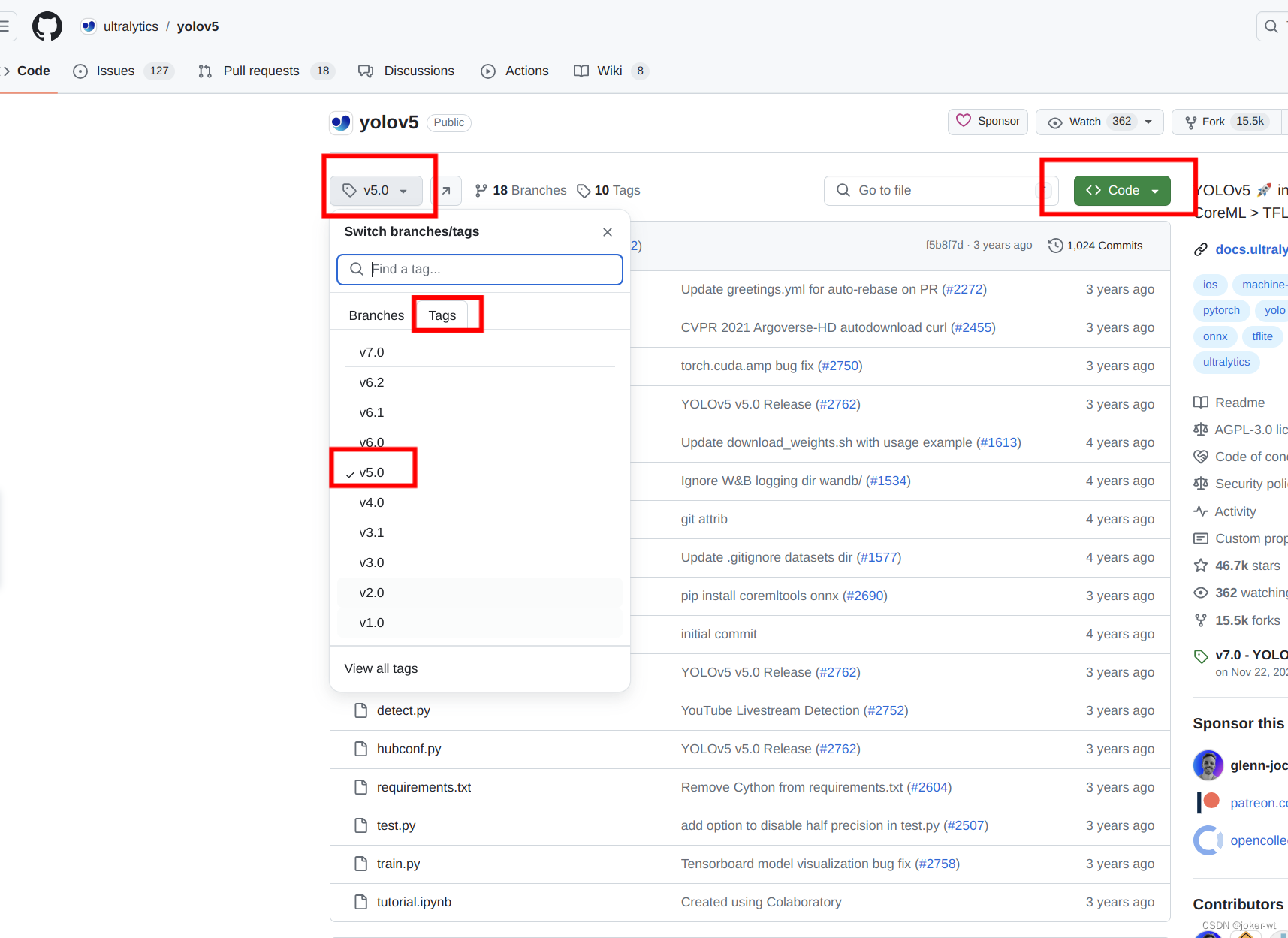
- clone 方法
git clone --recursive git@github.com:ultralytics/yolov5.git
clone不下来,或者时间较长的,检查一下github的密钥有没有添加,以及有没有相关魔法
2. 项目代码结构
将我们clone下来的好的yolov5的代码用一款IDE打开(我用的是pycharm),打开之后整个代码目录如下图
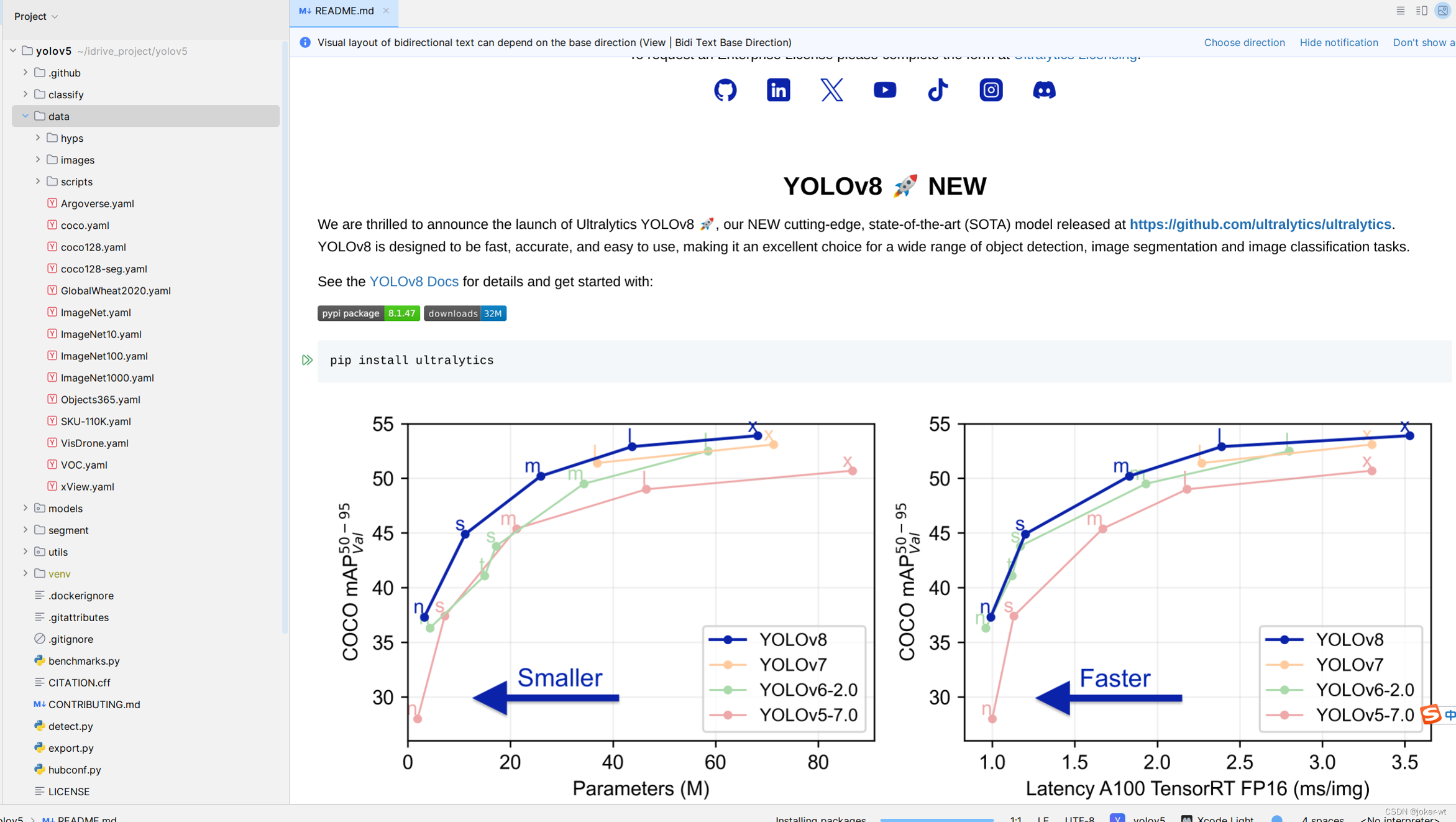
现在来对代码的整体目录做一个介绍:
├── data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
├── models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
├── utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
├── weights:放置训练好的权重参数。
├── detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
├── train.py:训练自己的数据集的函数。
├── test.py:测试训练的结果的函数。
├──requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
以上就是yolov5项目代码的整体介绍。我们训练和测试自己的数据集基本就是利用到如上的代码。
3. 环境的安装和依赖的安装
关于深度学习的环境的安装,值得一提的一点就是,正常需要利用GPU去训练数据集的话,是需要安装对应的CUDA和cudnn的
打开requirements.txt这个文件,可以看到里面有很多的依赖库和其对应的版本要求。我们打开命令终端,在中输入如下的命令,就可以安装了。
pip3 install -r requirements.txt
4. 数据集和预训练权重的准备
4.1利用labelimg标注数据和数据的准备
4.1.1 labelimg介绍:
Labelimg是一款开源的数据标注工具,可以标注三种格式。
1、VOC标签格式,保存为xml文件。
2、yolo标签格式,保存为txt文件。
3、createML标签格式,保存为json格式。
4.1. 2 labelimg的安装
pip3 install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
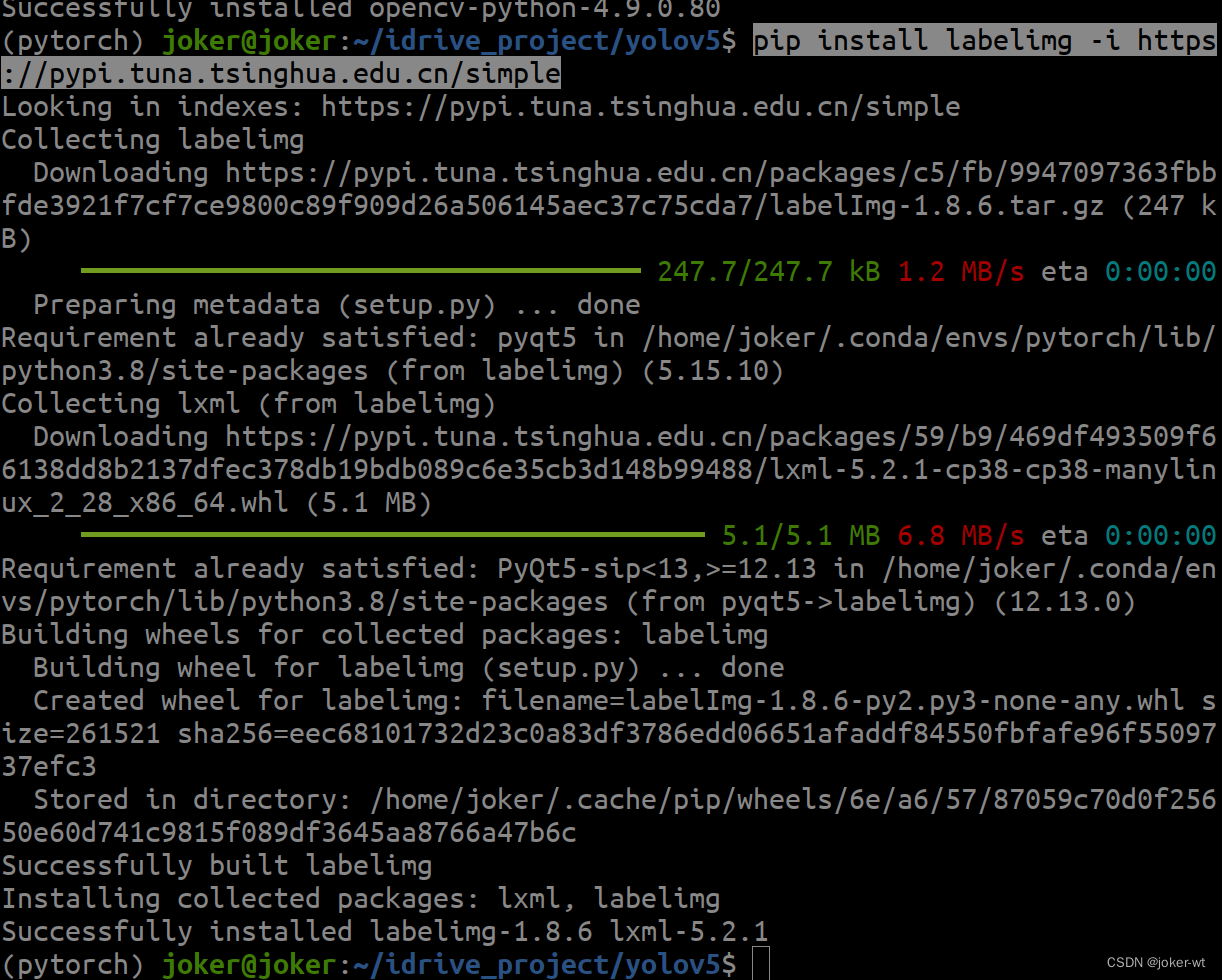
运行如上命令后,系统就会自动下载labelimg相关的依赖。由于这是一个很轻量的工具,所以下载起来很快。
4.2 使用labelimg
4.2.1 数据准备
首先这里需要准备我们需要打标注的数据集。这里我建议新建一个名为VOC2007的文件夹(这个是约定俗成,不这么做也行),里面创建一个名为JPEGImages的文件夹存放我们需要打标签的图片文件;再创建一个名为Annotations存放标注的标签文件;最后创建一个名为 predefined_classes.txt 的txt文件来存放所要标注的类别名称。
VOC2007的目录结构为:
├── VOC2007
│├── JPEGImages 存放需要打标签的图片文件
│├── Annotations 存放标注的标签文件
│├── predefined_classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好有这个创建一个这样的txt文件来存放类别)
4.2.2 标注前的一些设置
- 首先在JPEGImages这个文件夹放置待标注的图片,具体的类别因人而异。
- 创建一个名为Annotations存放标注的标签文件
- 创建一个名为 predefined_classes.txt 的txt文件来存放所要标注的类别名称
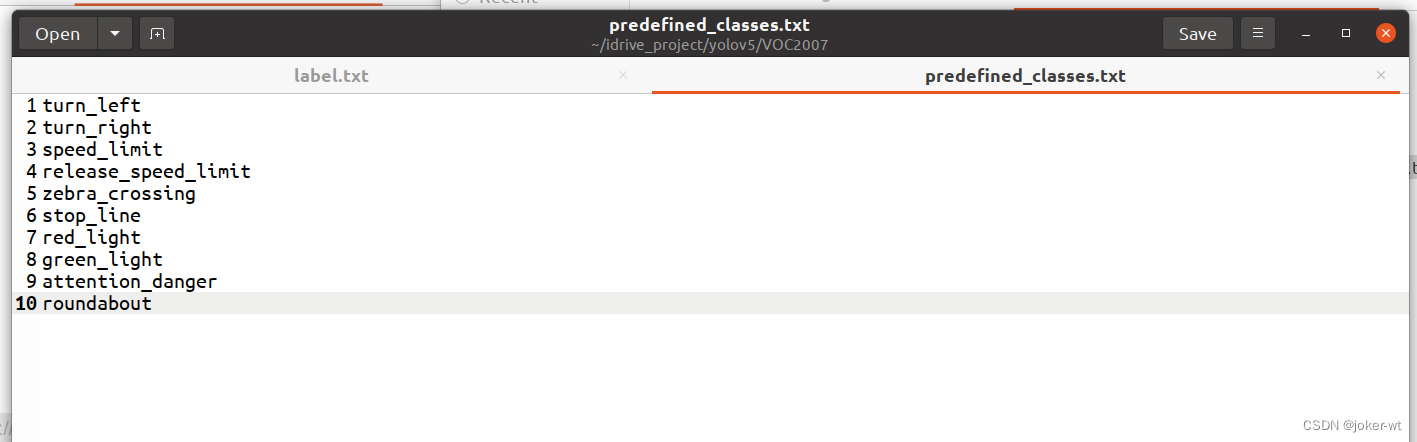
VOC2007的目录结构为:
├── VOC2007
│├── JPEGImages 存放需要打标签的图片文件
│├── Annotations 存放标注的标签文件
│├── predefined_classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好有这个创建一个这样的txt文件来存放类别)
- 输入如下的命令打开
labelimg。这个命令的意思是打开labelimg工具;打开JPEGImage文件夹,初始化predefined_classes.txt里面定义的类。
labelImg JPEGImages predefined_classes.txt
运行如上的命令就会打开这个工具;如下。
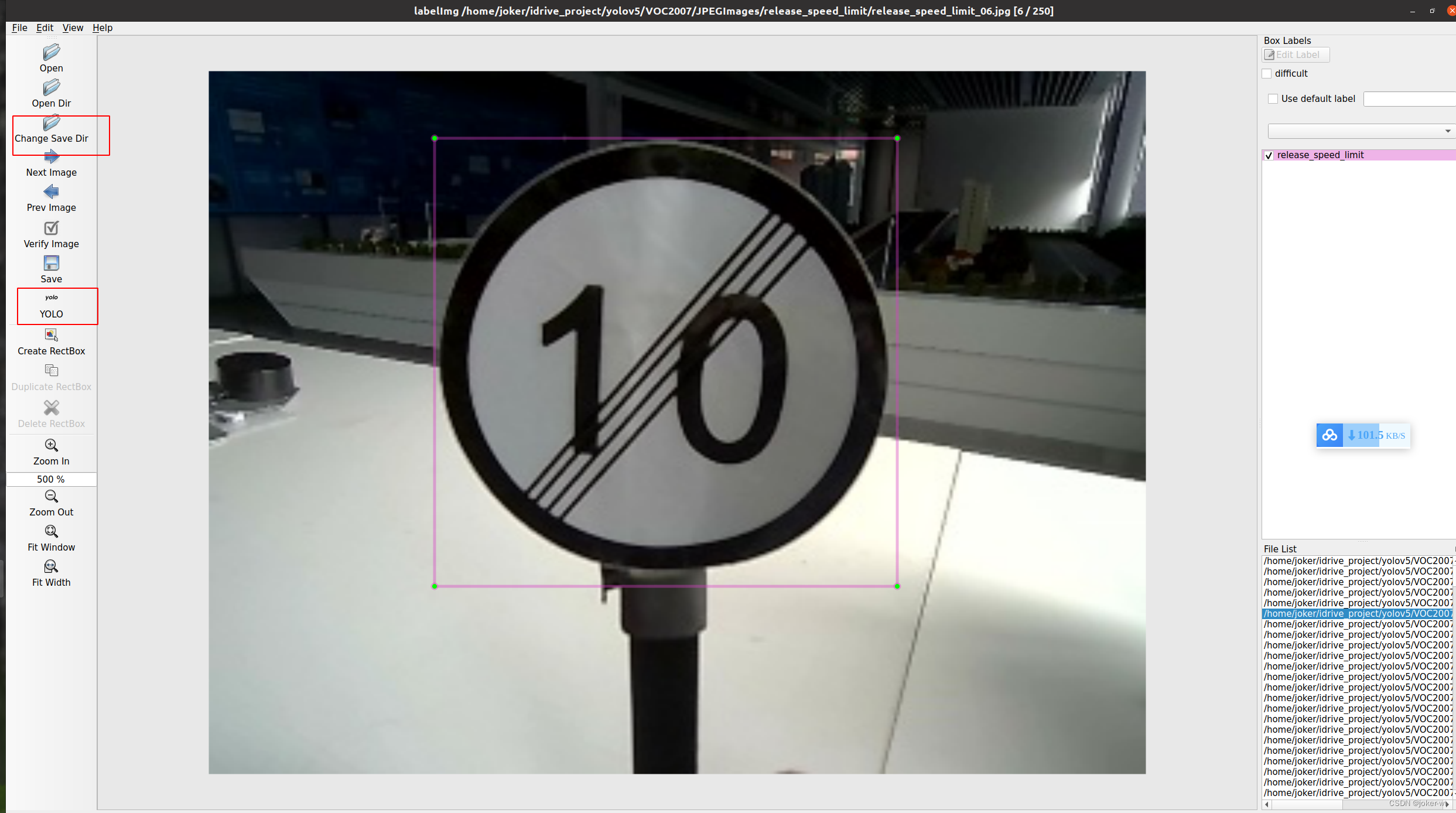
- 下面介绍图中的我们常用的按钮。

待标注图片数据的路径文件夹,这里输入命令的时候就选定了JPEGImages。(当然这是可以换的)
保存类别标签的路径文件夹,这里我们选定了Annotations文件夹。

这个按键可以说明我们标注的标签为voc格式,点击可以换成yolo或者createML格式。
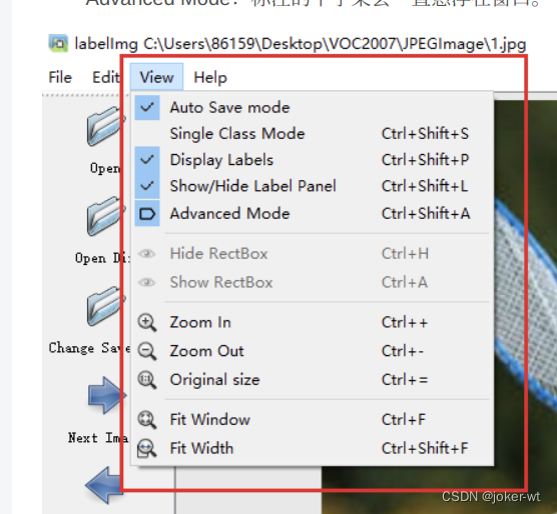
点击View,会出现如图红色框框中的选项。最好和我一样把勾勾勾上。
Auto Save mode:切换到下一张图的时候,会自动保存标签。
Display Labels:会显示标注框和标签
Advanced Mode:标注的十字架会一直悬浮在窗口。
常用快捷键如下:
A:切换到上一张图片D:切换到下一张图片
W:调出标注十字架
del :删除标注框框
Ctrl+u:选择标注的图片文件夹
Ctrl+r:选择标注好的label标签存在的文件夹
4.2.3 开始标注
由于我们设置标注的十字架一直在标注界面上,这就不需要我们按快捷键w,然后选定我们需要标注的对象。按住鼠标左键拖出框框就可以了。如下图所示,当我们选定目标以后,就会加载出来predefined_classes.txt 定义自己要标注的所有类别(如果类别多,是真的很方便,就不需要自己手打每个类别的名字了)。打好的标签框框上会有该框框的类别(图中由于颜色的原因不太清晰,仔细看会发现的)。然后界面最右边会出现打好的类别标签。打好一张照片以后,快捷键D,就会进入下一张,这时候就会自动保存标签文件(voc格式会保存xml,yolo会保存txt格式)。
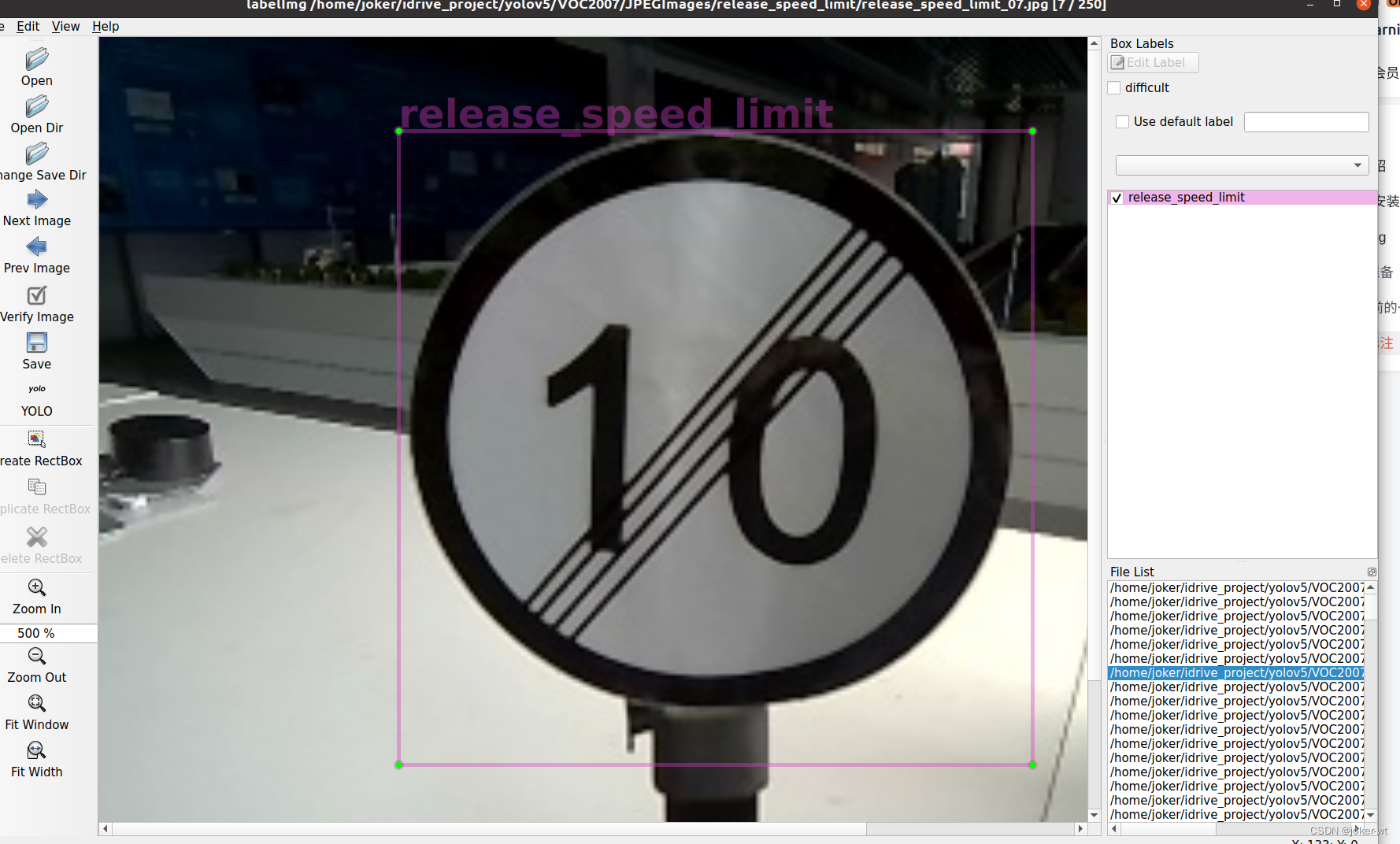
标签打完以后可以去Annotations 文件下看到标签文件已经保存在这个目录下。
4.3 将数据集为划分训练集和验证集
在yolov5目录下创建程序data_spl.py 并运行
程序如下:(可以不更改,注意下数据集的地址)
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
# @File : data_spl.py
# @Author: joker-wt
# @Date : 2024/4/18
# @Desc :
# @Contact : tl.wt123@qq.com
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='VOC2007/Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='VOC2007/ImageSets', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
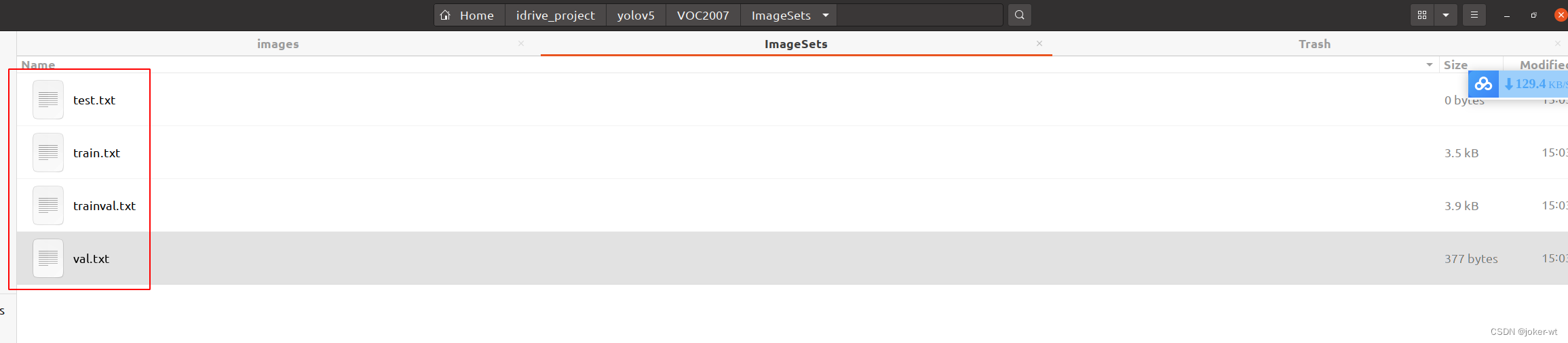
运行完毕后 会生成 ImagesSets文件夹,且在其下生成 测试集、训练集、验证集,存放图片的名字(无后缀.jpg)
由于没有分配测试集,所以测试集为空。
若要分配,更改第 14、15 行代码,更改所在比例即可。
4.4 配置文件
在 yolov5 目录下的 data 文件夹下 新建一个 my_yolov5.yaml文件(可以自定义命名),打开。
内容是:
训练集以及验证集(train.txt和val.txt)的路径(可以改为相对路径)
以及 目标的类别数目和类别名称。
给出模板: 冒号后面需要加空格
train: /home/joker/idrive_project/yolov5/VOC2007/ImageSets/train.txt
val: /home/joker/idrive_project/yolov5/VOC2007/ImageSets/val.txt
# number of classes
nc: 4
# class names
names: ["release_speed_limit", "roundabout","speed_limit","turn_left"]
4.5 修改模型配置文件
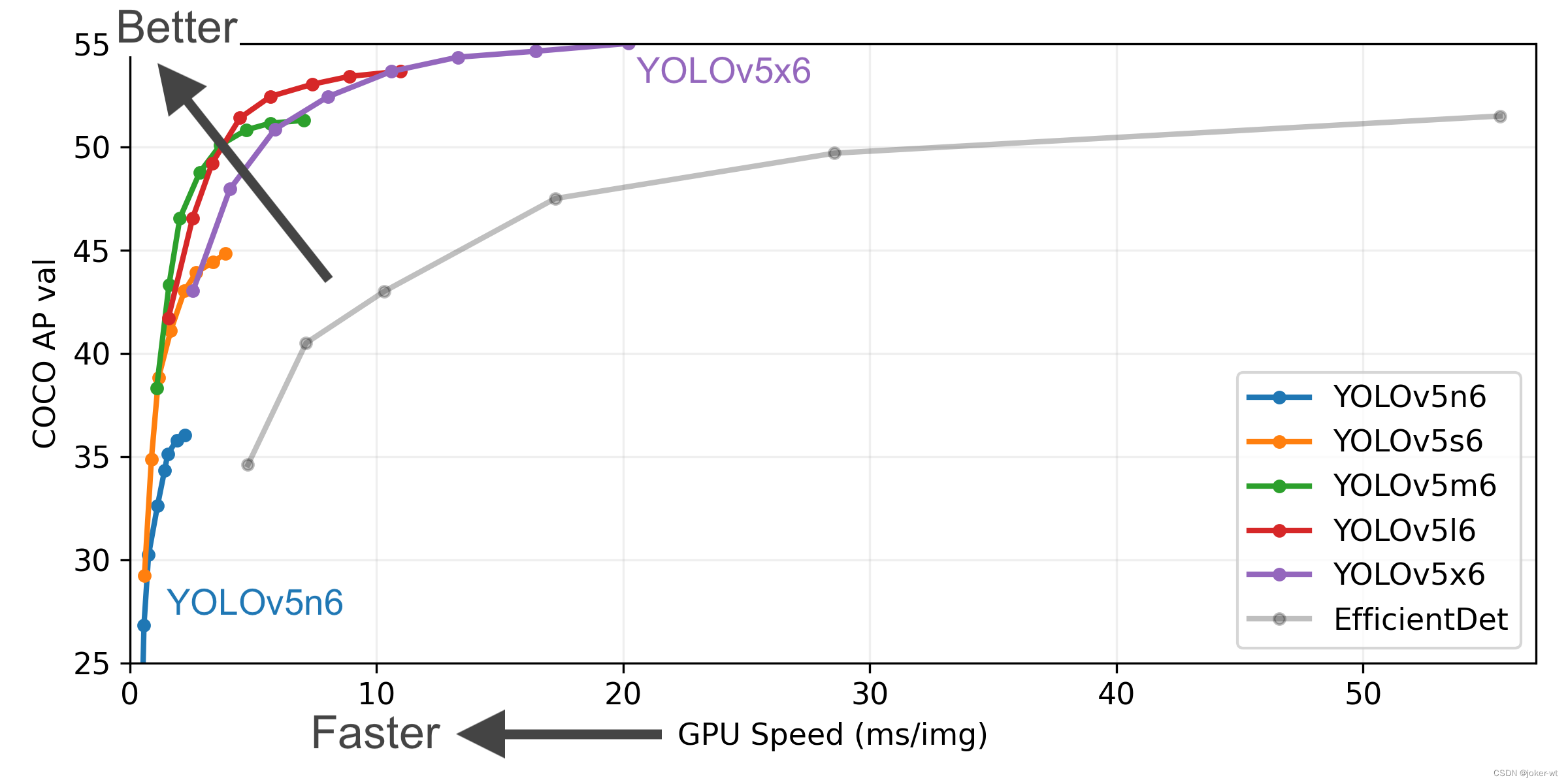
选择一个模型,在yolov5目录下的model文件夹下是模型的配置文件,有n、s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大)。
这里放一些官方数据: https://github.com/ultralytics/yolov5
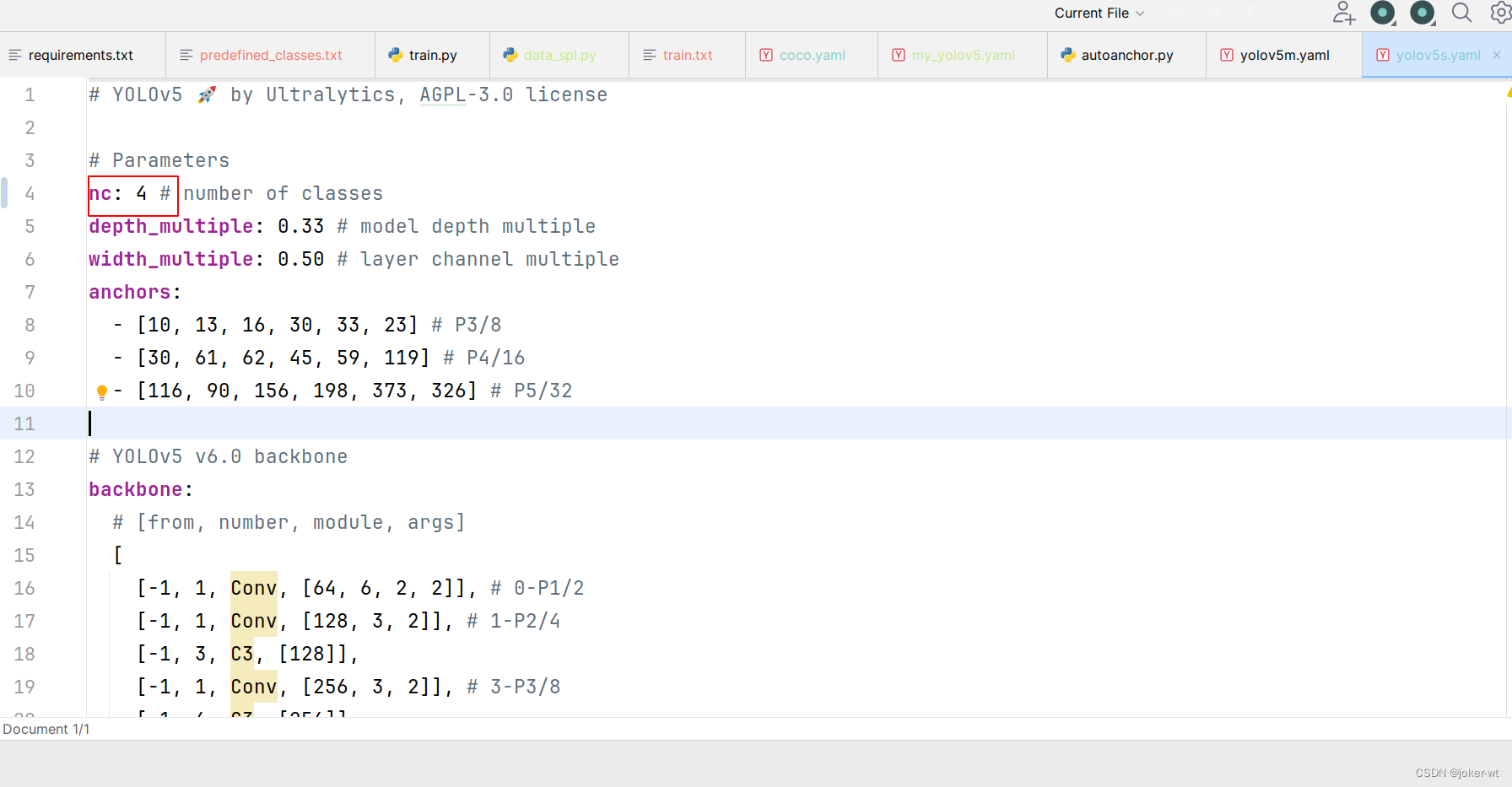
这里选用 yolov5s.yaml.。修改参数。
自动法获取anchors,只需更改nc 标注类别数,不用更改anchors
4.6 获得预训练权重
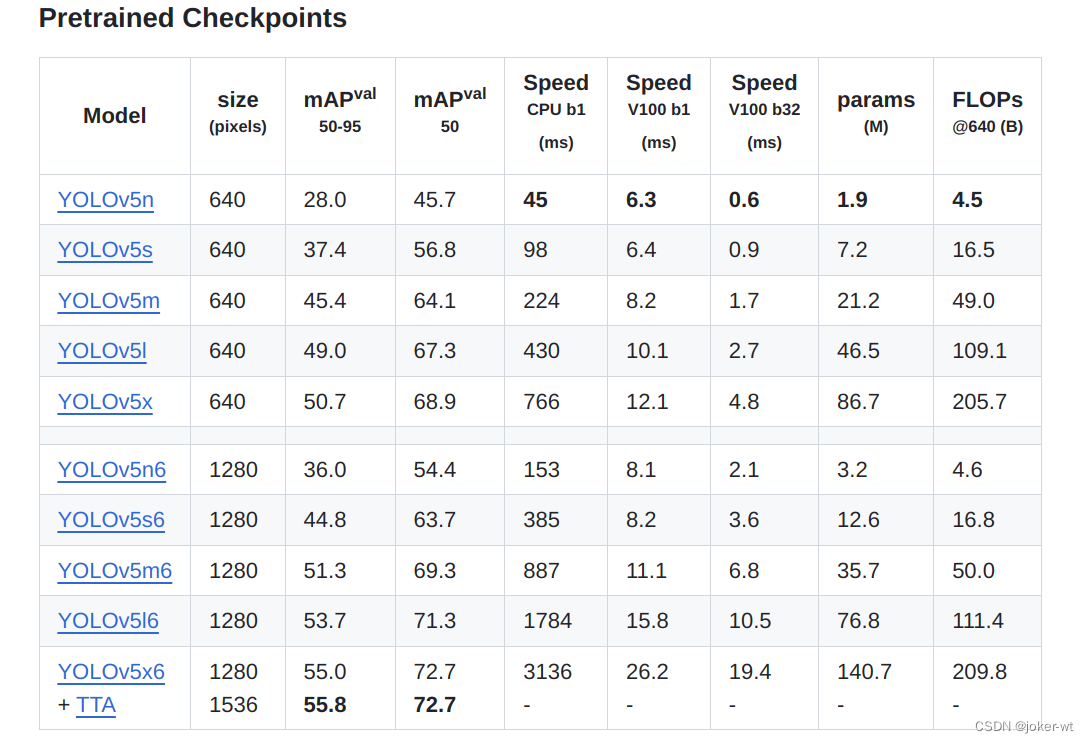
一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。通过如下的图可以获得权重的名字和大小信息,可以预料的到,预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。预训练权重可以通过这个网址进行下载,本次训练自己的数据集用的预训练权重为yolov5s.pt。
5. 模型训练
5.1 开始训练
打开yolov5 目录下的 train.py 程序,我们可以多看看这些参数使用。
训练自己的模型需要修改如下几个参数就可以训练了。首先将weights权重的路径填写到对应的参数里面,然后将修改好的models模型的my_yolov5.yaml文件路径填写到相应的参数里面,最后将data数据的hat.yaml文件路径填写到相对于的参数里面。这几个参数就必须要修改的参数。
常用参数解释如下:
这个大部分借鉴了参考链接。
-
weights:权重文件路径
-
cfg:存储模型结构的配置文件
-
data:存储训练、测试数据的文件
-
epochs:指的就是训练过程中整个数据集将被迭代(训练)了多少次,显卡不行你就调小点。
-
batch-size:训练完多少张图片才进行权重更新,显卡不行就调小点。
-
img-size:输入图片宽高,显卡不行就调小点。
-
device:cuda device, i.e. 0 or 0,1,2,3 or cpu。选择使用GPU还是CPU
-
workers:线程数。默认是8。
其它参数解释:
-
noautoanchor:不自动检验更新anchors
-
rect:进行矩形训练
-
resume:恢复最近保存的模型开始训练
-
nosave:仅保存最终checkpoint
-
notest:仅测试最后的epoch
-
evolve:进化超参数
-
bucket:gsutil bucket
-
cache-images:缓存图像以加快训练速度
-
name: 重命名results.txt to results_name.txt
-
adam:使用adam优化
-
multi-scale:多尺度训练,img-size +/- 50%
-
single-cls:单类别的训练集
进入pytorch环境,进入yolov5文件夹
训练命令如下:
python3 train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/my_yolov5.yaml --epoch 200 --batch-size 8 --img 640 --device 0