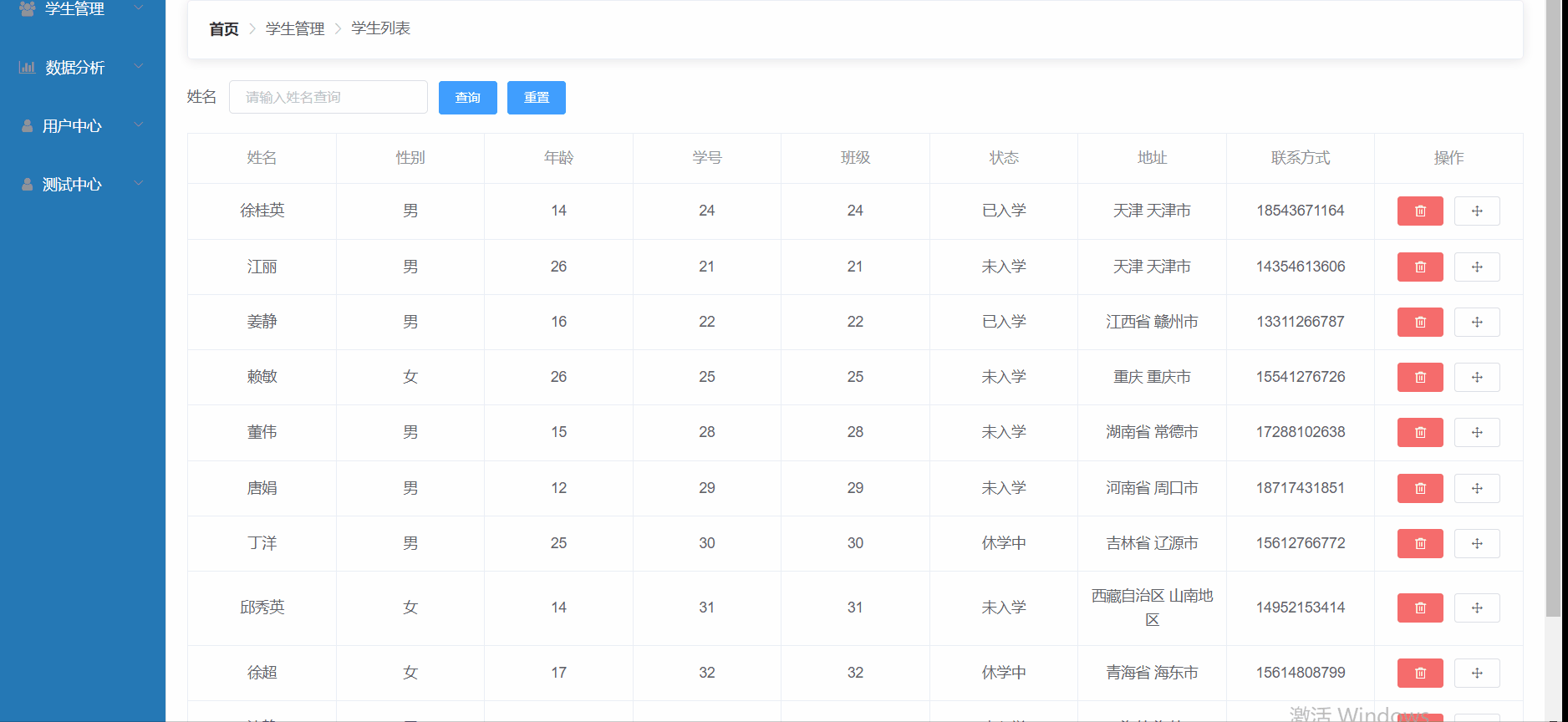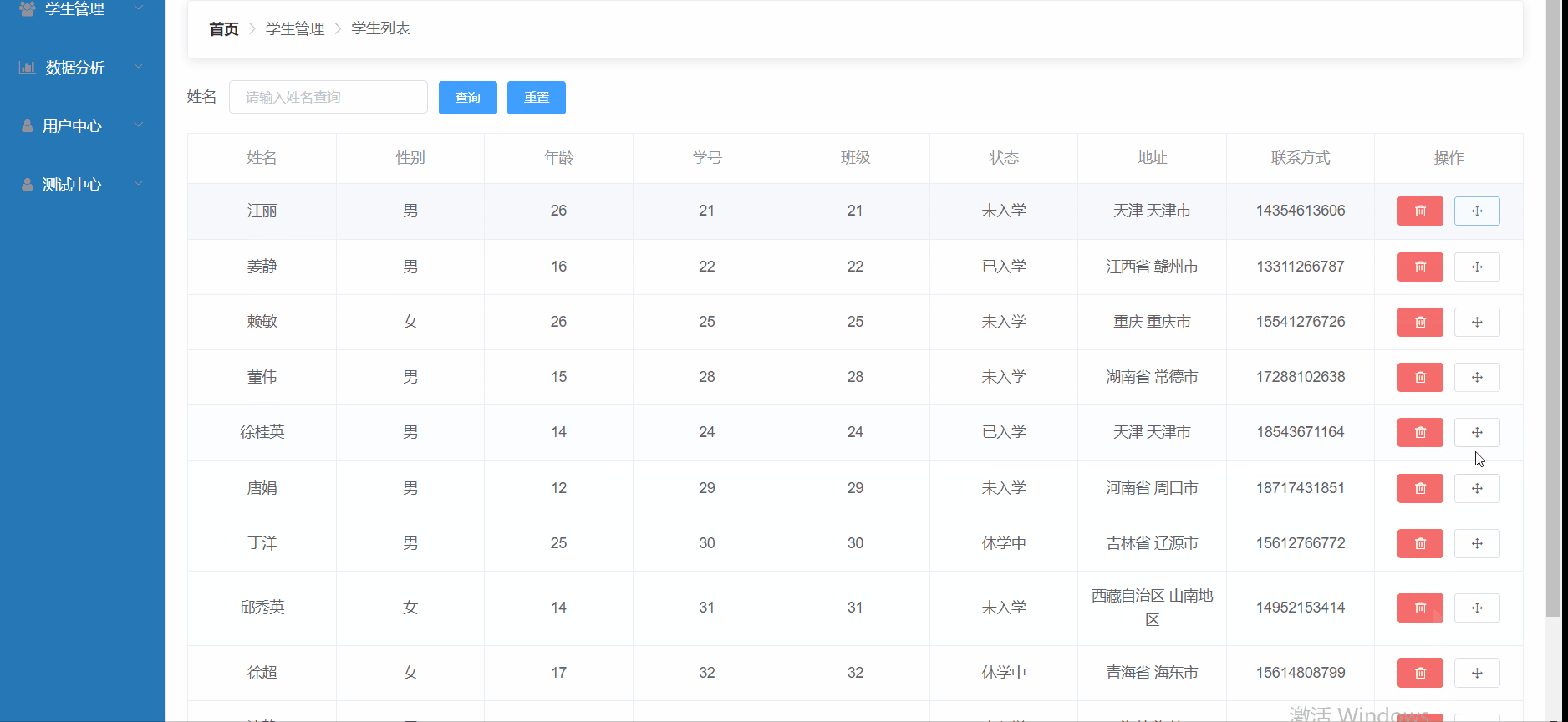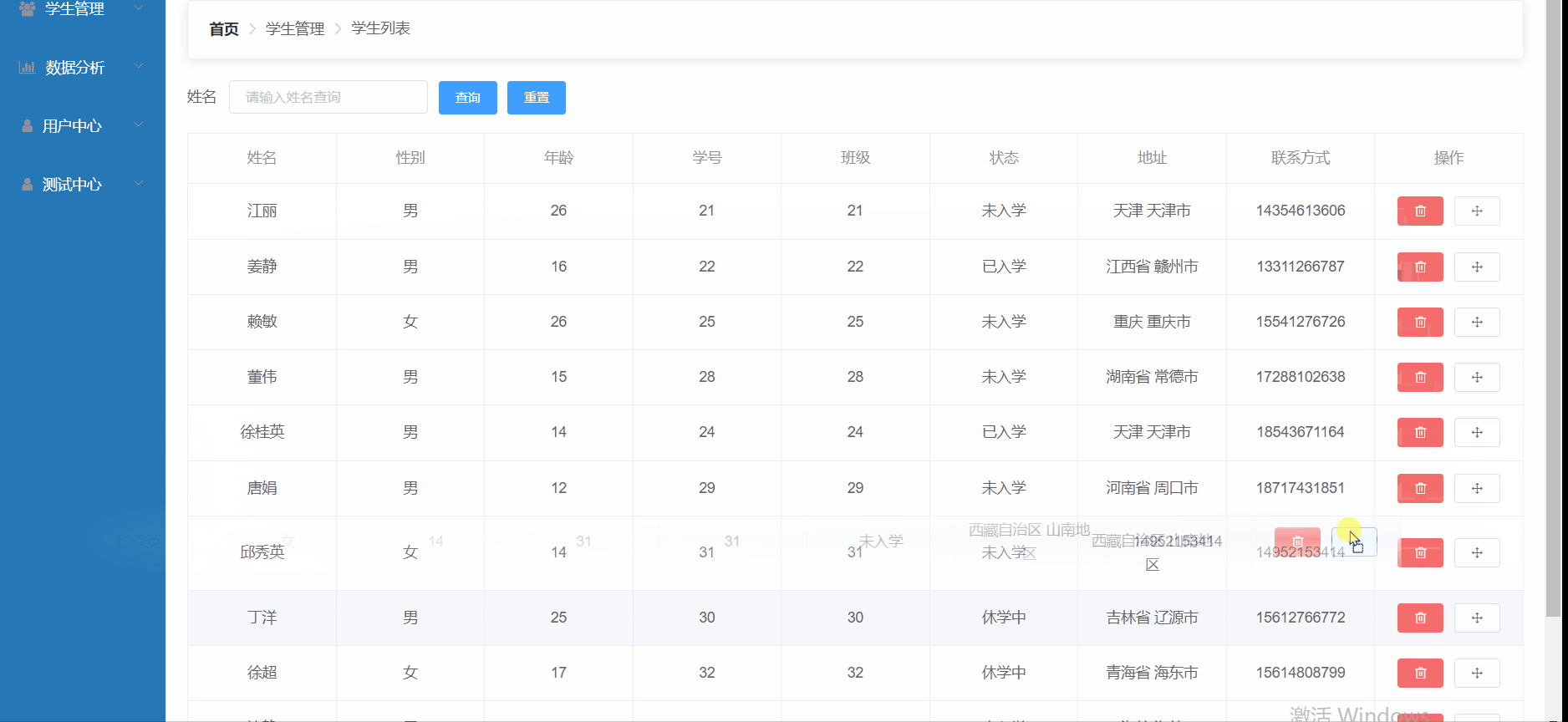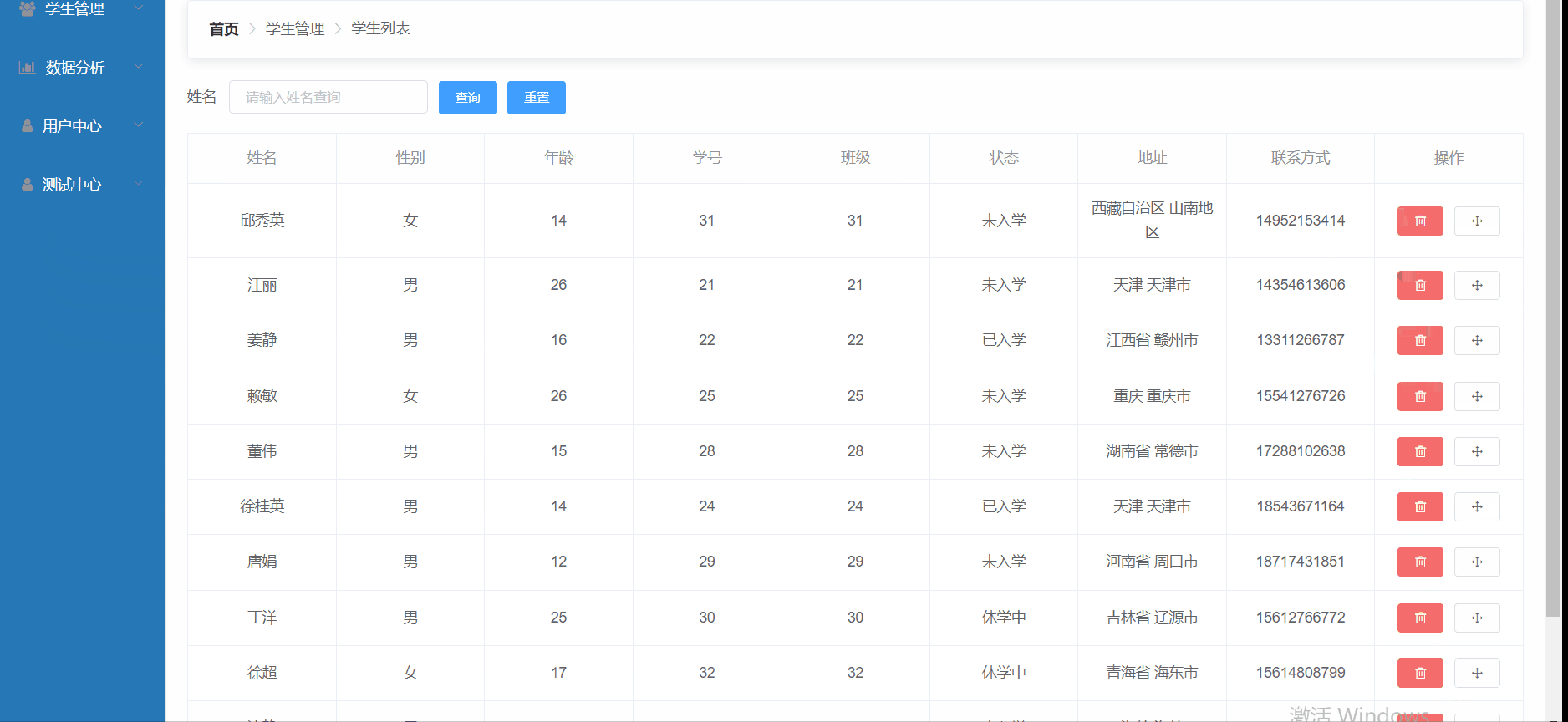
talk
文章的创新性不大,meta-review是给了 如果还可接收,再考虑。 但是 本文确实是 可扩展图聚类的重要一步。已有的方法 或多或少只在 小的数据集上 进行聚类。 存在一些非聚类的通用gnn方法进行采样。本文就是利用采样降低复杂度,并进行大量实验。
1. model
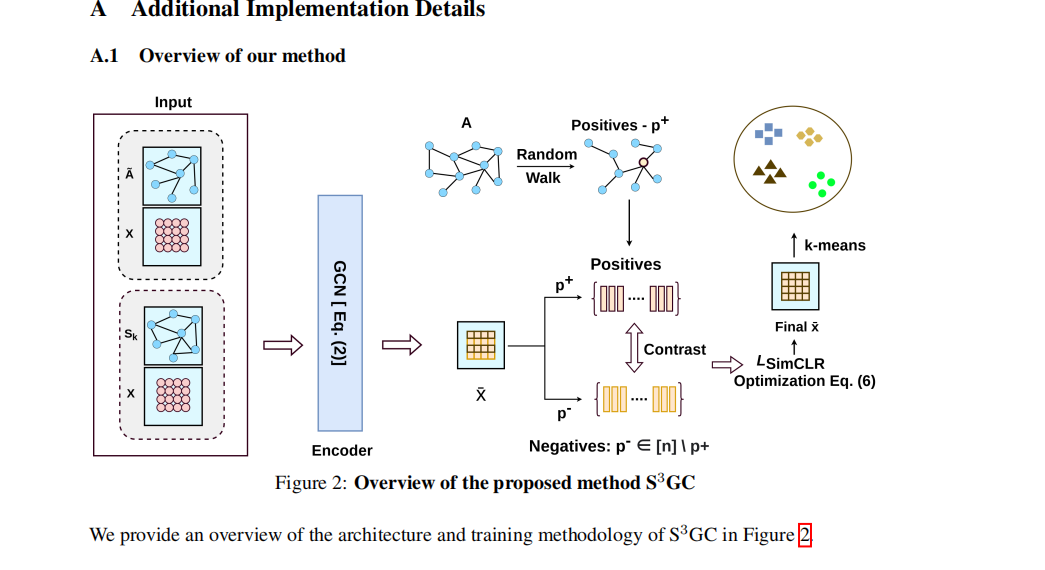
整体上就是一个 对比学习的 双阶段聚类框架。
encoder 考虑了高阶邻居,采用 APPNP的方法来预计算 不同阶 邻居表征之和(有点SAGN的感觉)。本文encoder的特别之处在于 加了一个 n*d的参数矩阵 去学习。

正负样本对构造: 通过node2vec的随机游走(pq)来进行采样正负样本(从图结构上相似性出发的正负考虑)

损失函数:SimCLR采用的infonce,注意这里整体少了一个log。
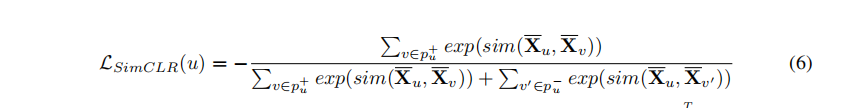
2. 实验
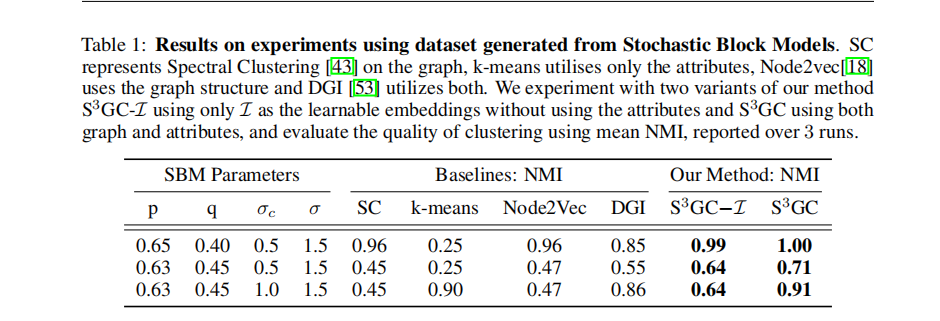
2.1 合成数据集实验
采用SBMs 合成图数据集,控制拓扑和属性上的相似性。
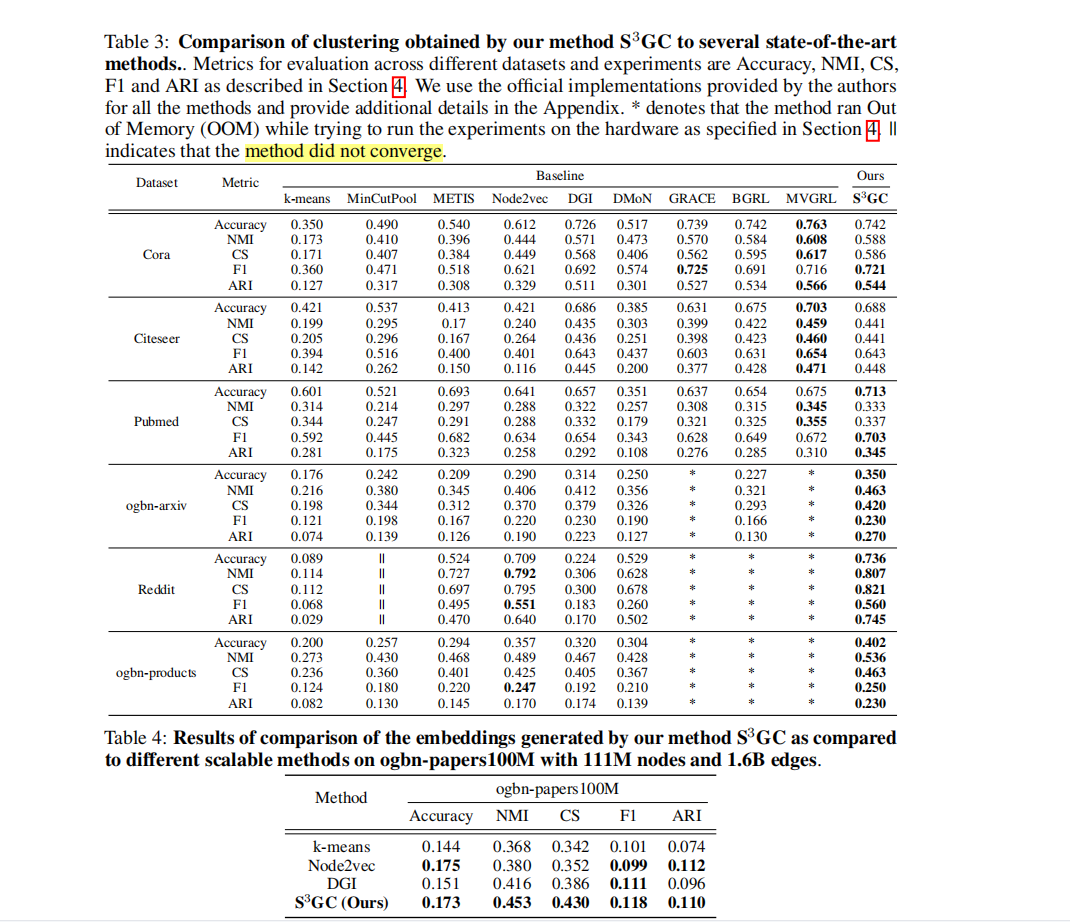
2.2 真实数据集
这里感觉对 DGI没有较好调参,效果应该不差的在 reddit上。 前面几个方法都是可扩展的,DGI这是采用了graphsage进行encoder修改。后面三个方法不可扩展
2.3 时间空间复杂度分析

其实综合看起来node2vec表现已经很好了,其没考虑特征X。很多OGB刷榜的方法都是node2vec+属性的改进
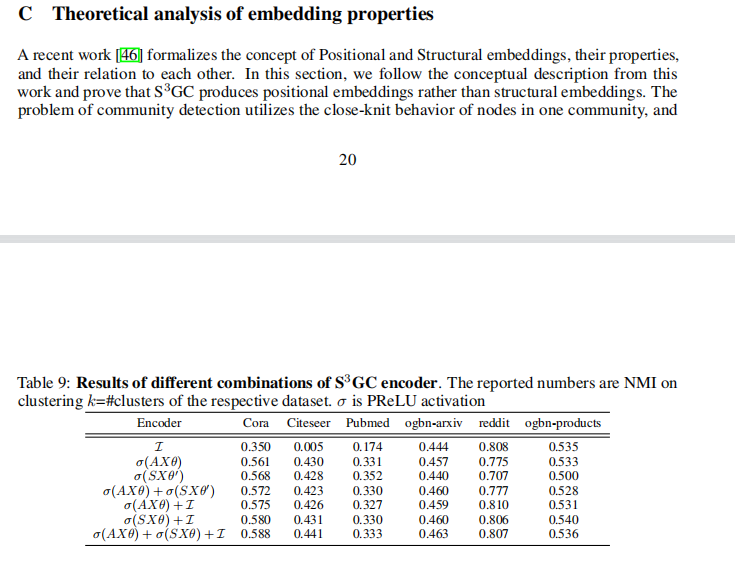
2.4 其他实验
编码器的结构探索+超参数网格搜索