目录
0.前言
1. 简述双向带头链表
2.双向带头循环链表的实现
2.1 设计双向带头循环链表结构体
2.2双向带头循环链表的初始化
2.3双向带头循环链表的尾插
2.4双向带头循环链表的尾删
2.5双向带头循环链表的头插
2.6双向带头循环链表的头删
2.7双向带头循环链表的插入
2.8双向带头循环链表的删除
2.9双向带头循环链表的查找
2.10双向带头循环链表的打印
2.11双向带头循环链表的销毁
3.顺序表和链表对比
3.1 阴阳双生子
3.2 缓存命中率
3.2.1 缓存命中率基础知识
3.2.2 小例子说明CPU与各级存储
3.2.3 顺序表和链表的缓存命中率
0.前言
本文所有代码以及图片文件资源都已上传gitee:
3双向链表实现 · onlookerzy123456qwq/data_structure_practice_primer - 码云 - 开源中国 (gitee.com)![]() https://gitee.com/onlookerzy123456qwq/data_structure_practice_primer/tree/master/3%E5%8F%8C%E5%90%91%E9%93%BE%E8%A1%A8%E5%AE%9E%E7%8E%B0
https://gitee.com/onlookerzy123456qwq/data_structure_practice_primer/tree/master/3%E5%8F%8C%E5%90%91%E9%93%BE%E8%A1%A8%E5%AE%9E%E7%8E%B0
1. 简述双向带头链表
我们之前实现的是结构最为简单的无头单向非循环链表,这是博客链接:(11条消息) 一只脚踏入数据结构的大门,如何用C语言实现一个单链表(超超超详解,我的灵魂受到了升华)_yuyulovespicy的博客-CSDN博客
https://blog.csdn.net/qq_63992711/article/details/128240283?spm=1001.2014.3001.5501
今天我们来实现结构相对复杂,但是实现起来却比较简单的带头双向循环链表。

前面我们说过最朴素的无头单向非循环链表,找尾必须一直遍历一遍链表,而双向循环链表下,循环决定了头结点和尾节点之间存在链接关系,双向决定了头结点和尾节点之间的链接关系是双向的,即不仅尾节点可以通过next找到头结点,而且头结点也可以通过prev找到尾节点。这样可以大大提高链表找尾的效率,同样我们的尾插/尾删的效率也大大提高了!
带头双向循环链表,带头的意思是,链表有一个哨兵位的头结点,即我们初始化链表的时候,链表就一直自带一个哨兵位的头结点,此时与不带头的链表相比,不带头的链表为空时,链表plist头就是NULL;而如果是带头的链表,那为空的时候,即还没有有效数据插入之前,代表此时链表plist为空,是该链表只有一个哨兵位头结点。
可以看到由于哨兵位头结点的存在,我们链表的头节点的位置是一直不会改变的,即永远是哨兵位头结点的指针,所以插入/删除的过程中我们就不用更新plist头节点指针的位置了!
而不带头的链表,头结点就是第一个有效节点的指针,为NULL的时候进行首次插入,这时候就必须分类讨论,如果plist为NULL,我们需要更新plist头结点的位置,更不必说头插,每次插入之后都必须更新头结点plist的指针。同时还有尾删,头删,这些接口的实现就非常方便了,就省去了我们分类讨论以及更新头结点的麻烦。
上面的好处我们可以在实现的时候得到体现:下面我们对双向带头循环链表进行实现。
2.双向带头循环链表的实现
2.1 设计双向带头循环链表结构体
首先我们要实现出链表的基础组成元素----节点,双向带头循环链表的节点ListNode,里面应该存储的成员变量,首先是存储的数据data,然后双向就需要我们存储一个ListNode* next和ListNode* prev,next指向当前节点的下一个节点,prev指向当前节点的前一个节点。
//范式类型LDataType
typedef int LDataType;
//双向链表节点
typedef struct ListNode
{
LDataType _data;
struct ListNode* _prev;//需要带struct,因为typedef只有在这个结构体定义之后才生效
struct ListNode* _next;
}ListNode;然后代表一个链表的话,其实我们只要找到首节点的指针,就可以找到该链表的所有节点,所以首节点的指针就代表整个链表。而对于此双向带头循环链表,知道哨兵位头结点的指针就可以代表这个链表实体。
2.2双向带头循环链表的初始化
我们初始化接口所需做的,就是为该链表创建哨兵位的头结点,然后处理哨兵位头结点的链接关系,即哨兵位头结点的next和prev都指向自己。
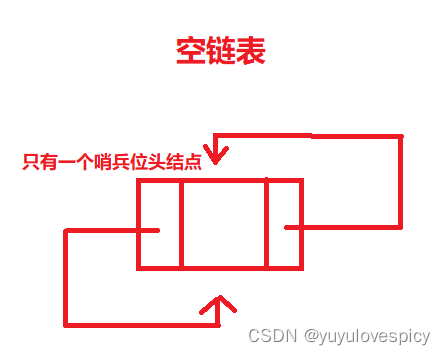
然而我们一开始在main函数中,进行初始化的场景,是我们首先定义一个头结点指针为空,即ListNode* plist = NULL;然后调用初始化函数。在双向带头循环链表的初始化中,我们当然首先创建一个哨兵位的头节点,然后在函数中使得plist头结点指针修改为哨兵位头结点的指针。
int main()
{
//创建一个节点
ListNode* plist = NULL
//然后使用初始化函数,对该链表进行初始化
}所以我们在调用完这个初始化函数之后,我们就需要改变我们plist指针这个指针实体的值。要改变plist实体,将之赋值为哨兵位头结点的值,就需要传入plist的地址,即ListNode** pplist,所以我们可以将接口设计成这样子:
//链表初始化函数
void ListInit(ListNode** pplist);
int main()
{
//创建一个链表
ListNode* plist = NULL
//然后使用初始化函数,对该链表进行初始化
ListInit(&plist);
}这里我们不用传二级指针法,而是使用返回值法,完成对链表的初始化,采用这种方法我们可以返回创建的哨兵位头结点的指针,直接用外部的plist去接收,即可完成对链表的初始化,此时我们也就不用传二级指针作为参数了!实现如下:
//初始化plist==NULL,在初始化时需要给plist实体赋值为哨兵位头结点的指针
//可以选用传入外部plist地址,即二级指针初始化方法;我们下面选用的是返回值初始化的方法。
ListNode* ListInit()
{
//创建哨兵位头结点
ListNode* phead = (ListNode*)malloc(sizeof(ListNode));
//双向循环链表中,只有一个节点时,该节点链接关系首尾相接
phead->_next = phead;
phead->_prev = phead;
return phead;
}应用代码如下:
ListNode* ListInit();
int main()
{
//创建一个链表
ListNode* plist = NULL
//然后使用初始化函数,对该链表进行初始化
plist = ListInit();
}2.3双向带头循环链表的尾插
自从有了哨兵位头结点,就再也不用传二级指针了,因为我们的头结点指针在插入/删除之后不会被改变,而永远是哨兵位头结点的指针。
然后我们分析一下为什么双向带头循环链表的尾插是非常非常优秀的:
1.不用传二级指针了,因为哨兵位头结点指针不会变。
2.双向循环链表的特性,可以使得phead->_prev可以直接找到tail尾,使效率达到O(1)。
3.单链表单独为NULL的情况,也不用单独拿出来讨论了,因为始终有有一个头结点。
然后我们作为接口的设计者,肯定要讨论一些非法情况:预防phead传入空,一定必须是有带哨兵位头结点的!
下面是尾插的实现:我们通过phead->_prev找到尾节点tail,然后在tail后面链接上创建的newnode节点,然后注意这里我们要处理的链接关系有很多,比如tail的next需要修改为newnode,newnode的prev指向tail,newnode的next指向phead,phead的prev指向newnode。
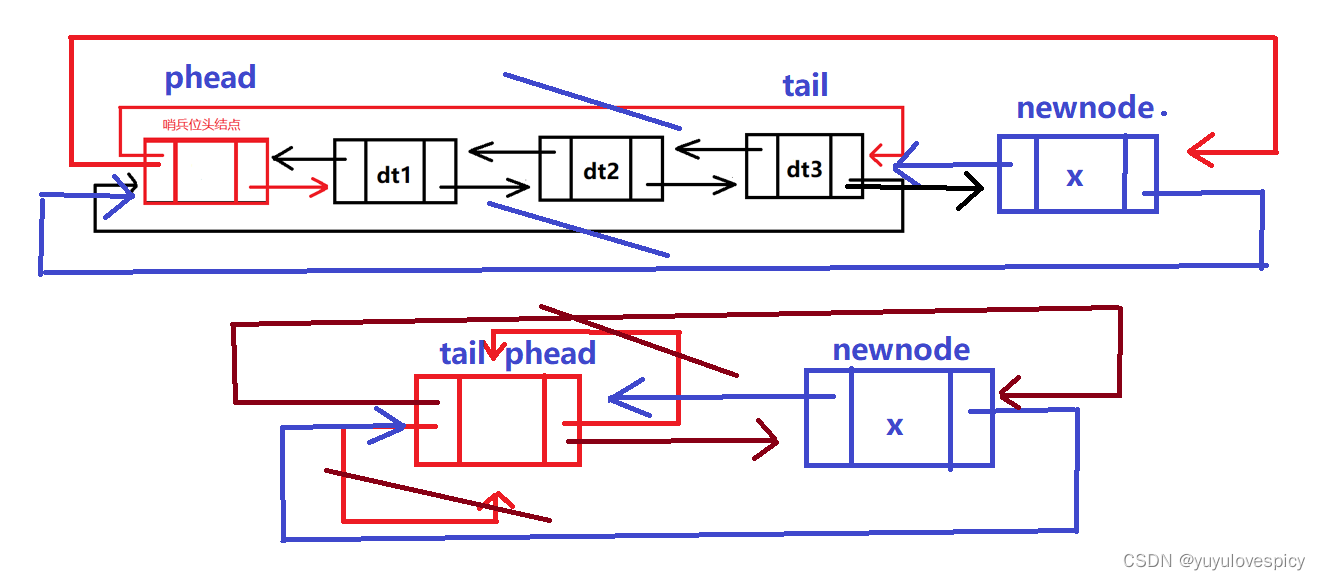
所以代码的实现就是这样的:
//封装创建一个双向节点的接口 --方便后续插入
ListNode* BuyListNode(LDataType x);
void ListPushBack(ListNode* phead, LDataType x)
{
//直接采用复用法,在phead节点之前插入,就是尾插
//ListInsert(phead, x);
//防止无头链表NULL
assert(phead);
//创建节点
ListNode* newnode = BuyListNode(x);
//找尾
ListNode* tail = phead->_prev;
//插入链接
tail->_next = newnode;
phead->_prev = newnode;
newnode->_next = phead;
newnode->_prev = tail;
}
ListNode* BuyListNode(LDataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
//初始化创建的节点
newnode->_prev = newnode->_next = NULL;
newnode->_data = x;
return newnode;
}
2.4双向带头循环链表的尾删
思路是类似的,通过phead->_prev找到尾节点tail进行释放删除,当然删除之后我们还是需要处理好phead和tail->_prev之间的链接关系。
当然当链表为空的时候,即没有有效节点,只有一个哨兵位头节点的时候是禁止删除的。

void ListPopBack(ListNode* phead)
{
//直接采用复用法:Erase最后一个节点,即phead的前节点
//ListErase(phead->_prev);
//防止非法情况:无头空链表
assert(phead);
//防止非法情况:空链表,无有效节点
assert(phead->_next != phead);
//记录节点
ListNode* tail = phead->_prev;
ListNode* tail_prv = tail->_prev;
free(tail);
tail_prv->_next = phead;
phead->_prev = tail_prv;
}2.5双向带头循环链表的头插
带头链表的头插的位置,应该是phead哨兵位头结点的后面next,因为我们要保持哨兵位头结点的位置恒定,头插在这里的意义是作为有效节点的头部,而不是整个链表的头部。
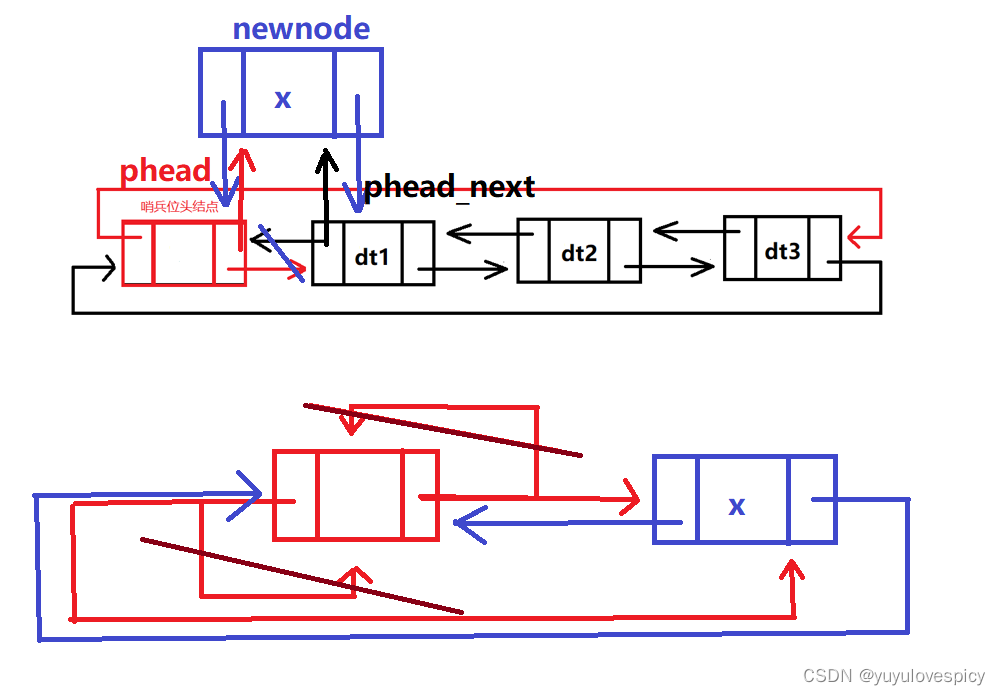
void ListPushFront(ListNode* phead, LDataType x)
{
//防止非法情况:无头空链表
assert(phead);
//创建新节点
ListNode* newnode = BuyListNode(x);
//插入
ListNode* phead_next = phead->_next;
phead->_next = newnode;
newnode->_prev = phead;
newnode->_next = phead_next;
phead_next->_prev = newnode;
}2.6双向带头循环链表的头删
我们这里还是在找到有效节点中的第一个节点,即phead->next,然后释放删除,处理好链接关系,但是我们在空链表的时候,即没有有效节点,只有一个哨兵位头结点的时候是禁止删除的!

void ListPopFront(ListNode* phead)
{
//防止非法情况:无头空链表
assert(phead);
//防止非法情况:空链表,无有效节点
assert(phead->_next != phead);
ListNode* erase_pos = phead->_next;
ListNode* erase_next = erase_pos -> _next;
free(erase_pos);
phead->_next = erase_next;
erase_next->_prev = phead;
}2.7双向带头循环链表的插入
双向带头循环链表的插入是在指定节点位置的前面位置插入。这个效率也是O(1),因为我们可以直接通过pos->_prev找到前一个节点,以及pos->_next找到后一个节点,可以直接处理好相应的链接关系。

//核心接口:Insert插入
void ListInsert(ListNode* pos, LDataType x)
{
//非法情况,无头链表
assert(pos);
//记录节点&&创建节点
ListNode* pos_prv = pos->_prev;
ListNode* newnode = BuyListNode(x);
//处理链接关系
pos_prv->_next = newnode;
pos->_prev = newnode;
newnode->_prev = pos_prv;
newnode->_next = pos;
}2.8双向带头循环链表的删除
对指定位置的节点pos进行删除释放,效率也可以提升到O(1),同样也是因为我们可以通过pos->_prev找到前一个节点,以及pos->_next找到后一个节点,可以直接处理好相应的链接关系。
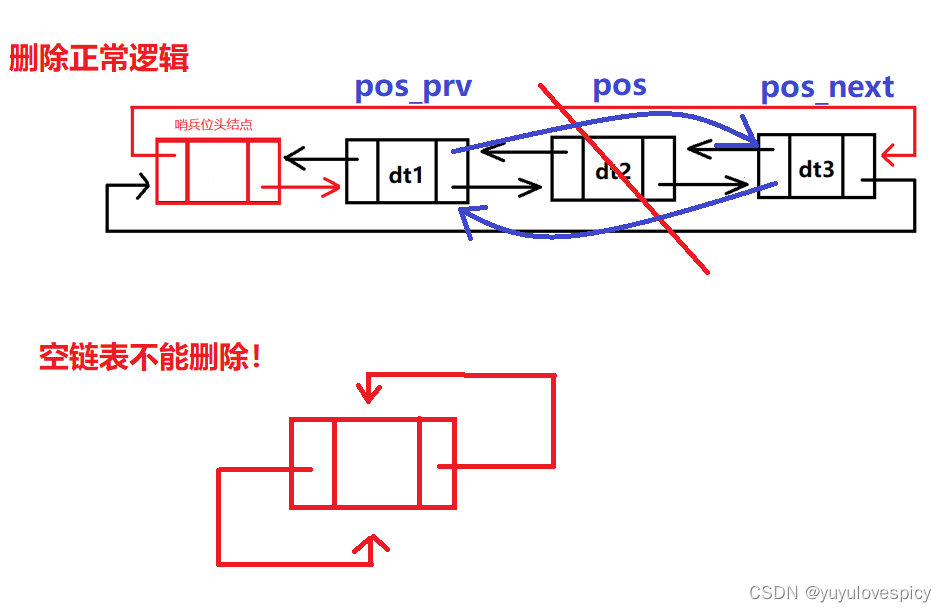
void ListErase(ListNode* pos)
{
//非法情况:无头链表
assert(pos);
//非法情况:空链表(只有头)
assert(pos->_next != pos);
//记录节点
ListNode* pos_prv = pos->_prev;
ListNode* pos_next = pos->_next;
free(pos);
pos = NULL;
pos_prv->_next = pos_next;
pos_next->_prev = pos_prv;
}2.9双向带头循环链表的查找
给我们一个值,然后我们根据这个值找到链表中对应的节点位置。思路很简单当然是暴力遍历查找整个链表的有效节点。当然这里我们还是要预防无头节点即NULL链表的传入,同时对于带头双向循环链表,我们遍历这个链表的时候,遍历的终止条件应该是cur!=phead,而不是cur!=NULL。
ListNode* ListFind(ListNode* phead, LDataType x)
{
assert(phead);
//需要注意有效数据的节点,存储在哨兵头结点之后
ListNode* cur = phead->_next;
while (cur != phead)
{
if (cur->_data == x)
{
return cur;
}
cur = cur->_next;
}
return NULL;
}2.10双向带头循环链表的打印
仿效双向带头循环链表的查找,也是遍历整个链表的有效节点,对之进行打印。
void ListPrint(ListNode* phead)
{
assert(phead);
//需要注意有效数据的节点,存储在哨兵头结点之后
ListNode* cur = phead->_next;
while (cur != phead)
{
printf("%d->", cur->_data);
cur = cur->_next;
}
printf("\n");
}2.11双向带头循环链表的销毁
防止堆区空间的泄漏,我们当然需要在最后对整个链表的空间进行销毁。即依次对每一个节点进行释放。
void ListDestroy(ListNode* phead)
{
//从头结点phead开始释放链表中的每一个节点
ListNode* cur = phead->_next;
while (cur != phead)
{
ListNode* cur_next = cur->_next;
free(cur);
cur = cur_next;
}
free(phead);
phead = NULL;
//我们传入的外部的头结点指针的拷贝(一级指针),所以Destroy后在外部需置空,否则出现野指针问题
}3.顺序表和链表对比
3.1 阴阳双生子
顺序表和链表,这两种数据结构其实可以说是代表两种存储方式的双生子,你的优势就是我的劣势,相反,你的劣势就是我的优势。所以这两种结构各有优势,很难说谁更优,严格来说,他们是相辅相成的两种结构。
分析顺序表的优点与缺点,在这篇博客中我做了细致的分析1.3为什么要有链表(vs顺序表)
下面我们简单总结:
顺序表的缺点:1. 开辟的物理空间必须是连续的,空间不够了需要增容,而增容尤其是异地扩容,效率消耗很大。
2. 为了防止频繁的增容,顺序表在设计时,空间不够时一般按照当前容量的倍数去扩容,用不完的空间存在一定的空间浪费。
3. 由于数据在空间上是连续存储的,我们进行头部或中间位置的插入或删除时,需要挪动数据,效率为O(n),效率不高。
相对应的链表的优点:
链表的数据是不连续存储的,数据通过一个个节点相互链接存储,所使用的空间在内存中也是分散申请使用的,由此衍生出链表的优点。
1. 链表每次所需申请的空间只需要一个节点,不需要申请连续物理空间,不会出现异地增容,申请空间的效率高。
2. 链表可以按需申请空间,存多少数据用多少节点空间,不会造成空间浪费。
3. 链表在进行任意位置的插入或删除的时候,不需要挪动数据,效率为O(1)。
顺序表的优点:
1.每个数据元素都有对应连续下标,支持随机访问,需要随机访问结构支持的算法,如快排等可以很好的适用。
2.CPU高速缓存命中率更高。(这个我们后面细致讲解)
相对应的链表的缺点:
1.链表不支持随机访问(不能用下标去直接访问)。这也就意味着:如快排,如二分查找等算法在链表结构上就不再适用了。2.链表节点不是通过下标访问,而是需要通过指针相链接,所以链表节点不仅需要存储数据,还要存储链接指针,这有一定消耗。
3.CPU高速缓存命中率更低。
3.2 缓存命中率
3.2.1 缓存命中率基础知识
上面我们讲顺序表的CPU高速缓存命中率更高,而链表的CPU高速缓存命中率更低,在讲缓存命中率前,我们先解释计算机的存储体系结构:

计算机中的存储分为带电存储和不带电存储两种,如图,从磁盘和内存为界,即L0--L4为带电存储,L5--L6为不带电存储。也就是说,电脑的主存(即内存),电脑的三级缓存,寄存器等,都是在有电的情况下才能进行存储,一旦断电都将丢失。而如本地磁盘,网盘等,这些存储是没电也能存。
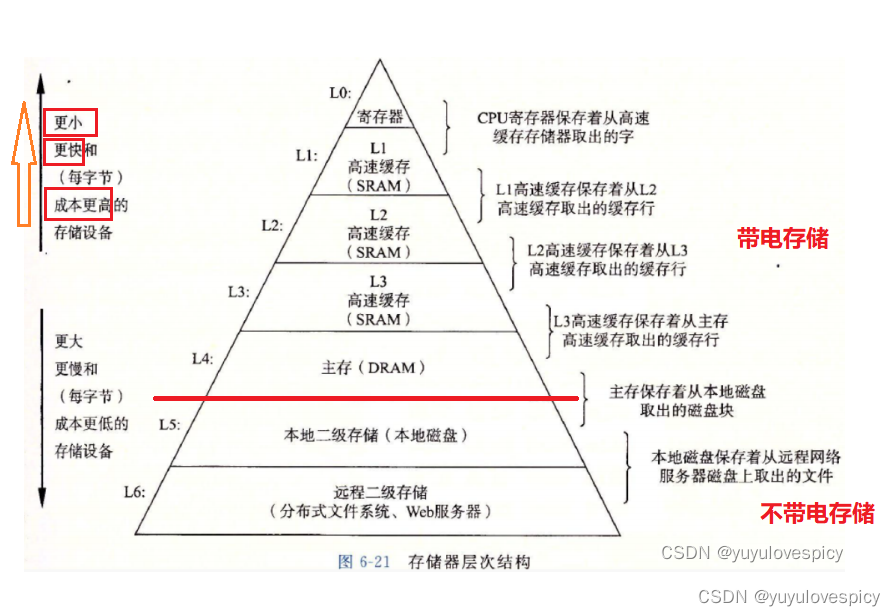
然后是各级存储的成本大小+存储大小+存储效率的问题:
我们看,自上到下,依次是寄存器,三级缓存,主存(内存),本地磁盘,网盘,这些存储结构。这个顺序也代表着,越在上层的存储结构,离着CPU越近,例如寄存器就在CPU内部,CPU紧挨着三级缓存,再远是内存,再再再离着CPU远的是磁盘。
你可以这样想,离着CPU越近,CPU在计算的时候,就越容易被CPU获取到数据,即存储效率就越高,从这个角度说,寄存器存储效率最高,三级缓存次之,再慢一点的是内存,最慢的是本地磁盘,网盘。
有的人问:寄存器的存储效率最高,那为什么不把电脑中的所有存储都用寄存器呢,这样CPU取数据的时间不久很少,可以大大提高运算效率了吗?这当然是不可以的,那是因为越上层的存储结构,这些硬件的成本就越高,比如制造寄存器以及三级缓存的成本是最高,其次是内存,再便宜的是磁盘。我们看国内的电脑/手机厂商,都是8+256,16+512,设备当中,硬盘的大小远高于内存的大小,这就是制作成本的问题。成本越高的东西,我们就少用一点,成本越低的东西,我们就多用一点。
所以自上到下,成本就越低,同时在计算机中使用的空间就越多。自下到上,成本就越高,在计算机中的空间就相对更少。
3.2.2 小例子说明CPU与各级存储
我们从一个小例子出发,讲解CPU是如何运行的:

1//比如a,b变量,一开始当然都是存储在内存中的栈区/堆区中的。
2//然后我们CPU要计算a+b,首先要获取a,b变量。
3//如果计算大小的话,我们当然要在CPU上,而在CPU上跑,需要把要计算的数据传入到离CPU近的地方存储 ,方便CPU计算的时候取到数据。
【3.5】//离CPU越近,CPU可以取到要计算的数据的效率就越高
4//如果变量a,b所占内存小一点点,就直接存储到寄存器上;如果a,b变量很大,寄存器放不下,那就要首先借助存储到空间更大的高速缓存当中。
然后CPU在计算运行的时候,就从寄存器/三级缓存中取到数据进行运算。
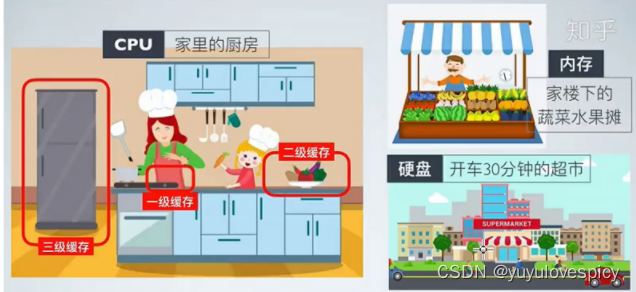
CPU就是家里的厨房,是要进行做饭的,然后做饭要使用材料,材料就是要使用的数据,数据存储在各级存储中,而材料可以存储在妈妈的手上,可以在厨房桌子的盘子上,也可以在附近的冰箱里面,还可以在楼下的小摊中,也可以在更远的超市货架上。相信这样类比着理解更加容易。
3.2.3 顺序表和链表的缓存命中率
CPU在计算之前,必须从某层存储中取到该数据。而不同层的存储效率是不同的。
我们CPU要取到内存中的数据,首先是把内存中的数据加载到缓存,而我们取数据,比如要取int a,并不是一次很小气的只取int四个字节,而是会把内存中的与变量a的相邻的,比如前10个字节以及后10个字节一同加载到缓存当中。
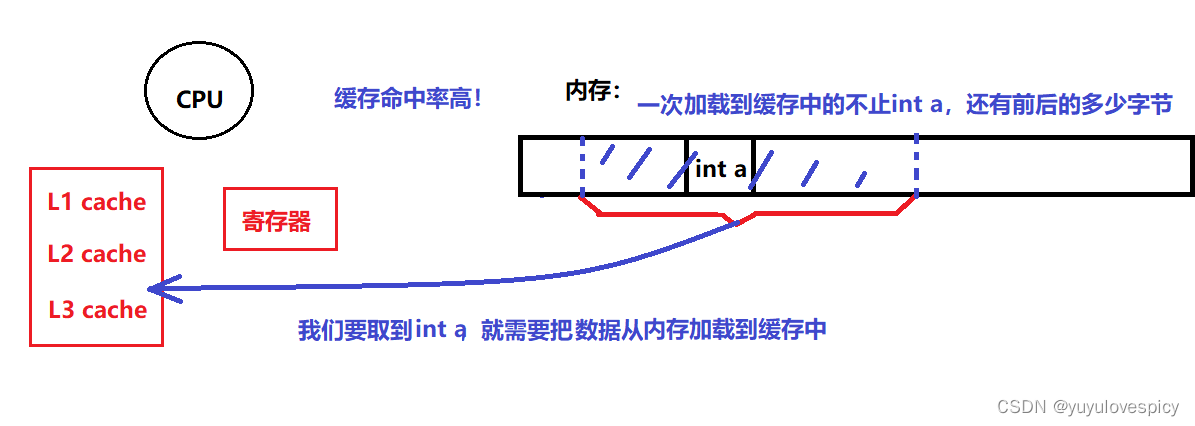
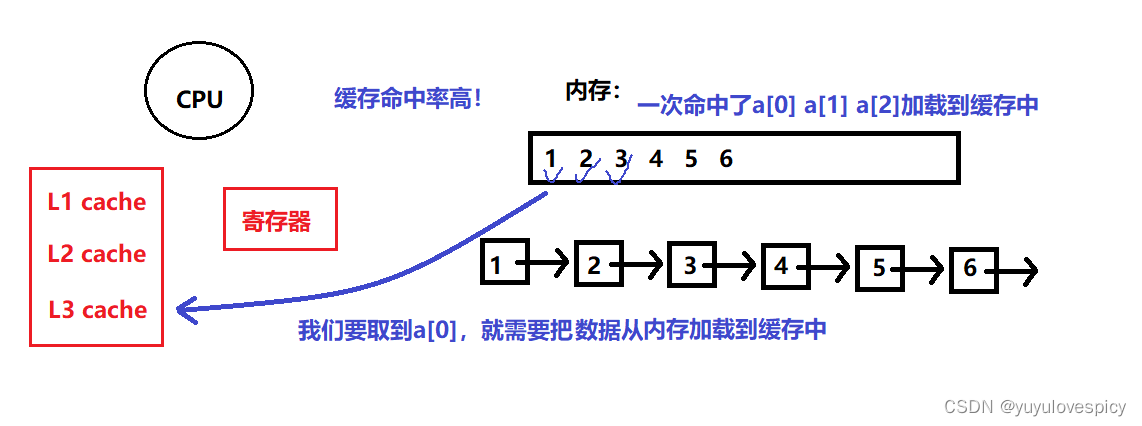
数据在物理内存上是连续的。加载的时候,即数据从内存加载到缓存当中,每加载一次,是一次性取多少字节,所以说,连续存储的数据会很容易被同时加载到进去,比如我们的顺序表,我们要取到a[0],从内存加载到缓存的过程中,在取a[0]的过程中,此时我们会顺便把a[1],a[2]等相邻的元素加载到缓存当中,这也是顺序表数据连续存储的优势。
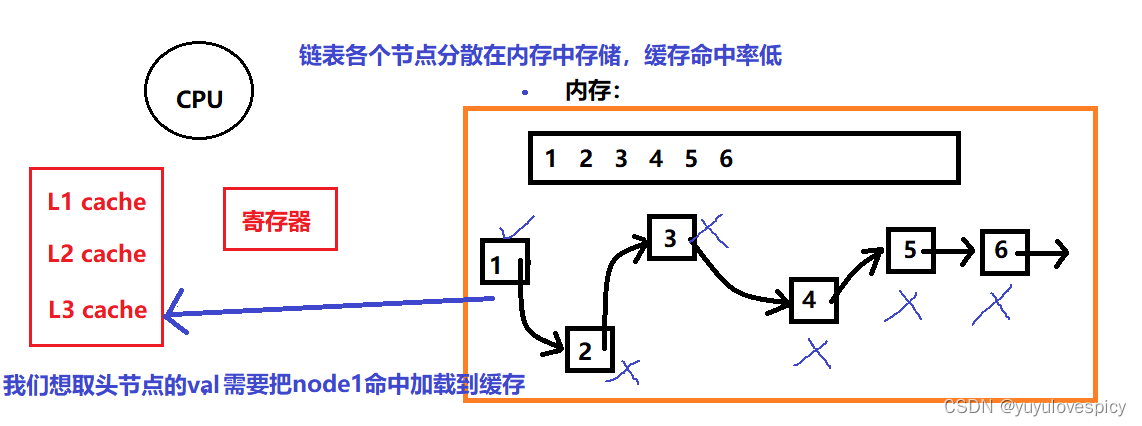
而链表的各个节点都是不连续存储的,存储在内存的各个地方,所以在访问的时候,就不容易一次性被加到到缓存当中。比如node1加载到缓存中,node2,node3...就不一定会加载到缓存当中。这是链表数据分散存储的劣势。
如果我们要遍历这个顺序表,就要让CPU取到每个数据,而顺序表的缓存命中率高,加载完a[0]之后,就同时把a[1],a[2]加载到缓存中了,下一次CPU取a[1] a[2]就不用在内存中取,而是直接在缓存中取即可!!!
如果我们要遍历这个链表,链表由于分散存储,把node1从内存加载到缓存的时候,node2,node3,node4等不一定会同时加载到缓存中,因为他们在物理上不连续,一次缓存加载很难都命中,所以每次CPU取数据都要从内存中寻找!!!
如要了解更多关于CPU缓存的知识,具体可以参考下面这篇文章,看完会有醍醐灌顶的感觉!
与程序员相关的CPU缓存知识 | 酷 壳 - CoolShell![]() https://coolshell.cn/articles/20793.html
https://coolshell.cn/articles/20793.html