文章目录
- 1. Epoch,Iteration,Batch-Size
- 2. Dataset 和 Dataloader
- 2.1 Dataset
- 2.2 Dataloader
- 2.2.1 例子
- 2.2.2 enumerate函数
- 3. 完整代码
1. Epoch,Iteration,Batch-Size
参考博客

2. Dataset 和 Dataloader
参考博客
功能概览
2.1 Dataset
torch.utils.data.Dataset是一个抽象类,不可以实例化,但是可以通过构建这个抽象类的子类来创建数据集。
重要方法(且必须改写):
getitem__():传入指定的索引index后,该方法能够根据索引返回对应的单个样本及其对应的标签(以元组形式)
__len__():返回整个数据集的大小
此外,因为 Dataset 类中提供了__add__()方法,所以继承之后我们的数据集也会拥有此方法,从而合并数据集只需使用 + 运算即可。
代码接口
class MyDataset(Dataset):
def __init__(self):
# 初始化数据集的存储路径
# 载入数据集(转化为tensor格式)
# ...
def __getitem__(self, index):
# 返回单个样本及其标签,后续batch由什么组成也是取决于这个是怎么设置的
pass
def __len__(self):
# 返回整个数据集的大小
pass
读取数据时有两个选择,一是把所有数据都加载进来(数据量较小时),另一个是定义一个列表,存放文件名,再用文件名去读文件内容,第二种留待以后实现(数据量较大时)
举例可以看参考博客。
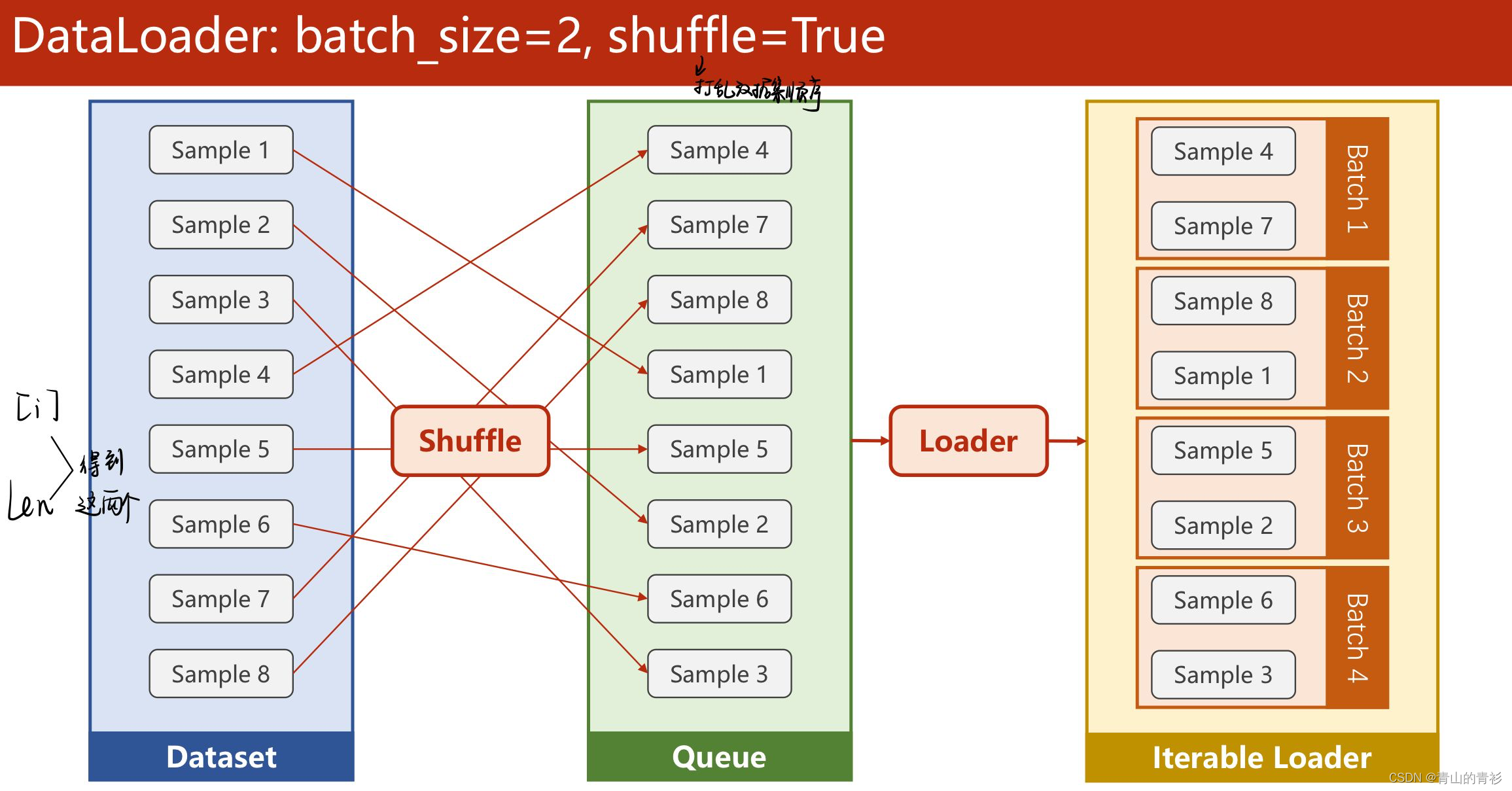
2.2 Dataloader
绝大多数时候需要以 batch 的形式访问数据集。Dataloader 这个接口提供了这样的功能,它能够基于我们自定义的数据集将其转换成一个可迭代对象以便我们批量访问。
重要参数

代码示例:
train_loader = DataLoader(dataset= dataset, batch_size=32, shuffle=True, num_workers=2,drop_last=False)
这段代码可以创建一个可迭代对象
2.2.1 例子
例:数据集内容如下:
1 -14 -15
1 -1 -15
1 -11 -14
1 0 -2
0 -4 2
1 7 -2
1 -7 -17
0 9 12
0 5 -14
1 -13 13
dataloader设置:
dataloader = DataLoader(data, batch_size=3, shuffle=False, drop_last=False)
将创建的可迭代对象列表化:
list(dataloader)
# [[tensor([[-14., -15.],
# [ -1., -15.],
# [-11., -14.]], dtype=torch.float64),
# tensor([1., 1., 1.], dtype=torch.float64)],
# [tensor([[ 0., -2.],
# [-4., 2.],
# [ 7., -2.]], dtype=torch.float64),
# tensor([1., 0., 1.], dtype=torch.float64)],
# [tensor([[ -7., -17.],
# [ 9., 12.],
# [ 5., -14.]], dtype=torch.float64),
# tensor([1., 0., 0.], dtype=torch.float64)],
# [tensor([[-13., 13.]], dtype=torch.float64),
# tensor([1.], dtype=torch.float64)]]
可以看出,列表化后,每一个 batch 均以列表的形式存储。这说明我们可以通过 for 循环来遍历所有的 batch,具体做法如下:
for inputs, labels in dataloader:
print(inputs, labels)
# tensor([[-14., -15.],
# [ -1., -15.],
# [-11., -14.]], dtype=torch.float64) tensor([1., 1., 1.], dtype=torch.float64)
# tensor([[ 0., -2.],
# [-4., 2.],
# [ 7., -2.]], dtype=torch.float64) tensor([1., 0., 1.], dtype=torch.float64)
# tensor([[ -7., -17.],
# [ 9., 12.],
# [ 5., -14.]], dtype=torch.float64) tensor([1., 0., 0.], dtype=torch.float64)
# tensor([[-13., 13.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
2.2.2 enumerate函数
参考博客1
参考博客2
用于记录每个batch的索引(即 iteration)
 实例:(这里为了方便展示将 batch_size 设为了1):
实例:(这里为了方便展示将 batch_size 设为了1):
dataloader = DataLoader(data, batch_size=1, shuffle=True, drop_last=True)
for batch_idx, (inputs, labels) in enumerate(dataloader):
print(batch_idx, end=' ')
print(inputs, labels)
# 0 tensor([[-4., 2.]], dtype=torch.float64) tensor([0.], dtype=torch.float64)
# 1 tensor([[ -1., -15.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 2 tensor([[ 0., -2.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 3 tensor([[ 7., -2.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 4 tensor([[ 9., 12.]], dtype=torch.float64) tensor([0.], dtype=torch.float64)
# 5 tensor([[ 5., -14.]], dtype=torch.float64) tensor([0.], dtype=torch.float64)
# 6 tensor([[-11., -14.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 7 tensor([[-14., -15.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 8 tensor([[ -7., -17.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 9 tensor([[-13., 13.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
3. 完整代码
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
# 1. Dataset和Dataloader 准备数据集
class DiabetesDataset(Dataset):
def __init__(self, filepath): # 也可以删去filepath,把真正路径放到下面第一行代码的第一个参数
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # 例如数据集是N行(N个样本),8+1列(8个特征,1个输出),shape就是一个元组,为(N,9),shape[0]就是N
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
# 也可以 return self.len(x_data)
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset= dataset, batch_size=32, shuffle=True, num_workers=2)
# 2.设计模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
# 三个线性模型
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid() # 可以构造Sigmoid,nn下的Sigmoid是一个模块,不是单纯的函数
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# 3.损失函数和优化器
# 还是二分类,直接用BCE损失即可
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 4.训练过程
if __name__ == '__main__':
for epoch in range(10):
for i, data in enumerate(train_loader,0):
# 1.准备数据
inputs, labels = data
# 2. 前馈
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. 反馈
optimizer.zero_grad()
loss.backward()
# 4. 更新
optimizer.step()