gold-yolo论文:
https://arxiv.org/pdf/2309.11331.pdf
gold-yolo代码:
https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO
一 gold模块简介
Gold-Yolo是华为诺亚方舟实验室2023年发布的工作,主要优化检测模型的neck模块。论文上展示的效果挺棒的, 打算引入到yolov8中,替换原有的neck层.
目标检测模型一般都是分成3个部分,backbone,neck,head,其中neck部分,主要是类似fpn的结构,将不同层级的特征进行融合。
glod-yolo聚焦于这样一个问题:当不同尺度的特征需要跨层融合时,会产生信息丢失,阻碍模型效果提升,如第1层要与第3层信息交互,要先将第3层与第2层融合,然后才能与第1层融合,这种间接获取信息的方式使得有效信息丢失。
因此文章提出了聚合-分发机制,改善信息融合的方式。整体结构如下:
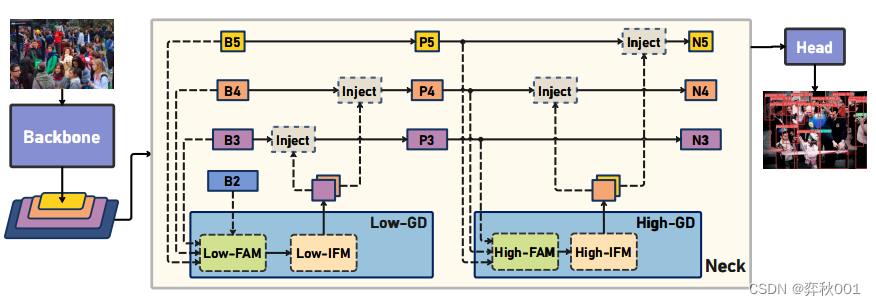
设计了两个分支:low-GD和high-GD, 从下面消融实验看, low-GD主要汇集浅层信息, 提升小目标检测能力,high-GD融合深层语义信息, 提升大目标检测能力.
ps: 有个大胆想法, 如果只想提升小目标的检测能力, 只使用low-GD是不是一个可行方案呢!
其中GD主要分成3个模块:
- FAM(Feature Alignment Module,特征对齐模块)
- IFM(Information Fusion Module,信息融合模块)
- Inject(Information Injection Module,信息注入模块)
进入上述Inject前, 还要经过LAF模块,浅层LAF融合3层特征,深层LAF融合2层特征。论文的消融实验表面,注入模块Inject与LAF连用后整体AP有较大幅度提升。
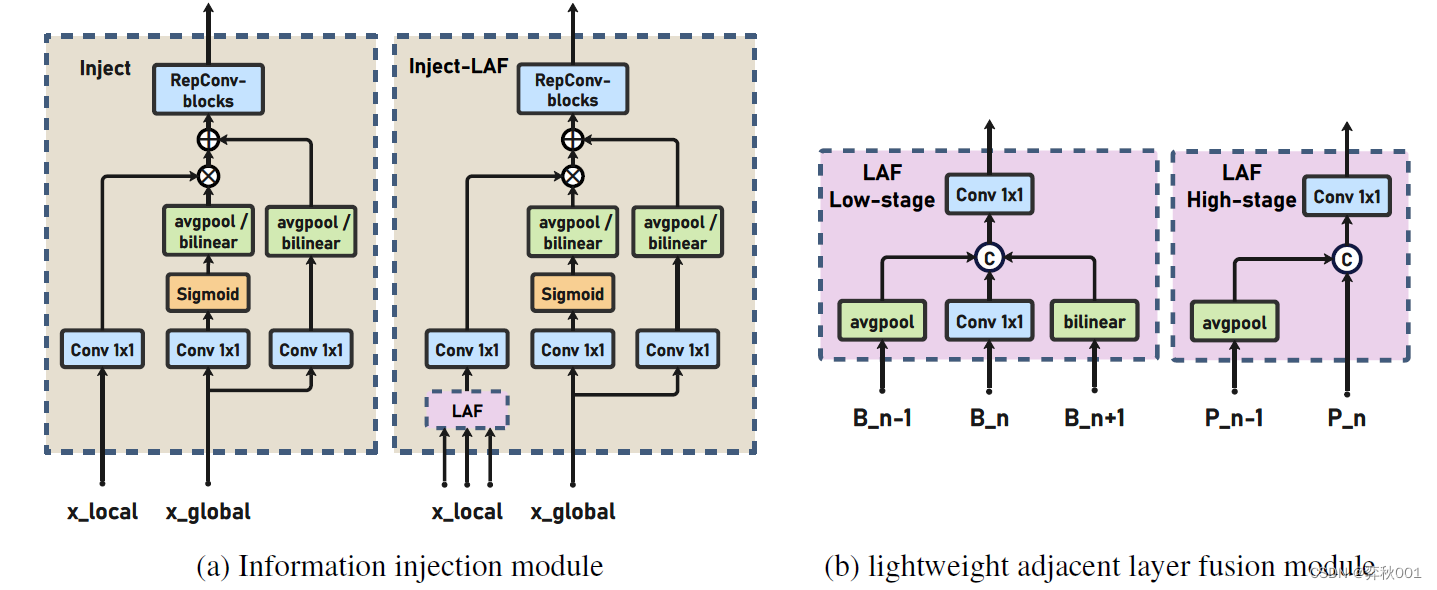

因此共有以下7个模块:Low_FAM, Low_IFM, Inject, High_FAM, High_IFM. Low_LAF, High_LAF
二 图解gold作为yolov8 neck时通道变化
gold-yolo的neck层有独特数据流向与通道变化,比fpn,pafpn等经典neck模块都要复杂,好在这是个比较独立的模块,受不同backbone的影响较小,移植到yolov8中后结构与通道变化如下:
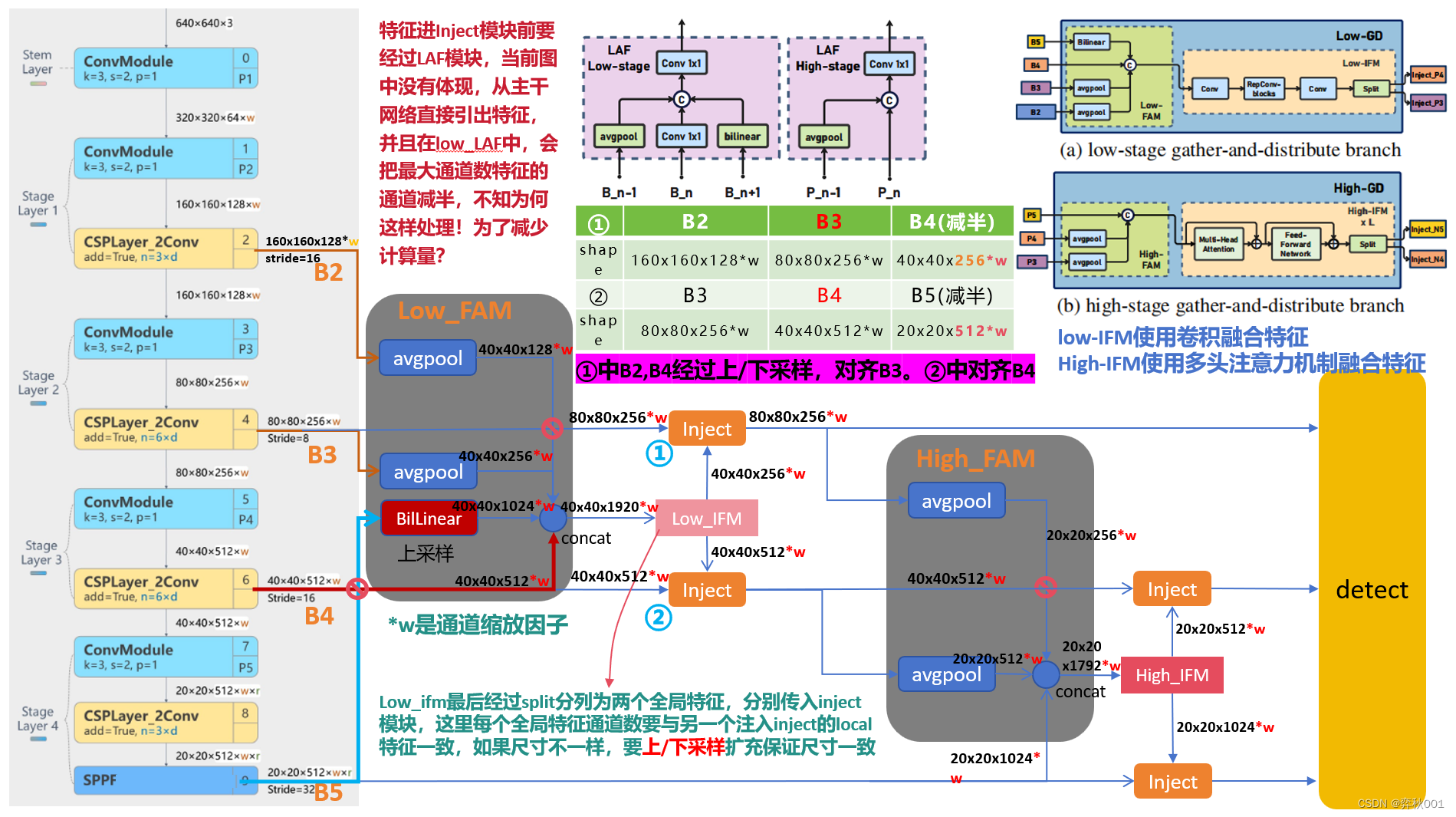
三 主要模块代码分析
代码来自官方git仓,为引入yolov8,把论文中模块定义重新命名。顺便再合并一些模块,稍微改变入参方式, 保证大多数修改发生在引入的模块内部, 使得对v8源码改动最小。如Inject后要接RepBlock整合注入后的特征,现在二者合并在Inject模块中。
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
from mmcv.cnn import ConvModule, build_norm_layer
class Inject(nn.Module):
"""
原名InjectionMultiSum_Auto_pool
信息注入模块
"""
def __init__(
self,
inp: int,
oup: int,
# 源码中没有index参数. 从split获得两个tensor, 这里要指定用哪个
global_index: int,
rep_block_nums=1,
norm_cfg=dict(type='BN', requires_grad=True),
# activations=None, 未使用, 注释掉
global_inp=None,
) -> None:
super().__init__()
self.global_index = global_index
self.norm_cfg = norm_cfg
if not global_inp:
global_inp = inp
self.local_embedding = ConvModule(inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
self.global_embedding = ConvModule(global_inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
self.global_act = ConvModule(global_inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
self.act = h_sigmoid()
# 将整合注入结果的模块写在Inject模块中
self.rep_block = RepBlock(oup, oup, rep_block_nums)
def forward(self, x):
'''
x_g: global features
x_l: local features
'''
x_l, x_g = x
x_g = x_g[self.global_index]
B, C, H, W = x_l.shape
g_B, g_C, g_H, g_W = x_g.shape
use_pool = H < g_H
local_feat = self.local_embedding(x_l)
global_act = self.global_act(x_g)
global_feat = self.global_embedding(x_g)
if use_pool:
avg_pool = get_avg_pool()
output_size = np.array([H, W])
sig_act = avg_pool(global_act, output_size)
global_feat = avg_pool(global_feat, output_size)
else:
sig_act = F.interpolate(self.act(global_act), size=(H, W), mode='bilinear', align_corners=False)
global_feat = F.interpolate(global_feat, size=(H, W), mode='bilinear', align_corners=False)
out = local_feat * sig_act + global_feat
# 不该变通道数
out = self.rep_block(out)
return out
class Low_LAF(nn.Module):
"""
原名SimFusion_3in
lightweight adjacent layer fusion
LAF是一个轻量的邻层融合模块,如下图所示,对输入的local特征(Bi或pi)先和邻域特征融合,
然后再走inject模块,这样local特征图也具有了多层的信息。
浅层会融合3个特征
"""
def __init__(self, in_channels_list, out_channels):
super().__init__()
# 对齐40*40尺寸
self.cv1 = SimConv(in_channels_list[1], out_channels, 1, 1)
self.cv_fuse = SimConv(int(out_channels * 2.5), out_channels, 1, 1)
self.downsample = nn.functional.adaptive_avg_pool2d
def forward(self, x):
"""
:param x: list,有3个tensor
"""
N, C, H, W = x[1].shape
output_size = (H, W)
if torch.onnx.is_in_onnx_export():
self.downsample = onnx_AdaptiveAvgPool2d
output_size = np.array([H, W])
x0 = self.downsample(x[0], output_size)
x1 = self.cv1(x[1])
x2 = F.interpolate(x[2], size=(H, W), mode='bilinear', align_corners=False)
return self.cv_fuse(torch.cat((x0, x1, x2), dim=1))
class SimConv(nn.Module):
"""
Normal Conv with ReLU VAN_activation
主要功能是通道减半
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, groups=1, bias=False, padding=None):
super().__init__()
if padding is None:
padding = kernel_size // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class Low_IFM(nn.Module):
"""
浅层特征信息融合模块
conv-repconv->conv,最后输出split后的两个tensor
"""
def __init__(self, in_channels, out_channels_list, embed_dims, fuse_block_num):
"""
:param in_channels:
:param out_channels:
:param embed_dims:
:param fuse_block_num:
"""
super().__init__()
self.conv1 = Conv(in_channels, embed_dims, kernel_size=1, stride=1, padding=0)
self.block = nn.ModuleList(
[RepVGGBlock(embed_dims, embed_dims) for _ in
range(fuse_block_num)]) if fuse_block_num > 0 else nn.Identity
self.conv2 = Conv(embed_dims, sum(out_channels_list), kernel_size=1, stride=1, padding=0)
# 分裂为两个全局特征
self.trans_channels = out_channels_list
def forward(self, x):
x = self.conv1(x)
for b in self.block:
x = b(x)
out = self.conv2(x)
return out.split(self.trans_channels, dim=1)
class Low_FAM(nn.Module):
"""
原名为SimFusion_4in
功能为拼接从主干提取的4个特征层,特征对齐
"""
def __init__(self):
super().__init__()
self.avg_pool = nn.functional.adaptive_avg_pool2d
def forward(self, x):
# 从主干模型接受的4个输入
x_l, x_m, x_s, x_n = x
# 要对齐的b4的shape, 40*40
B, C, H, W = x_s.shape
output_size = np.array([H, W])
if torch.onnx.is_in_onnx_export():
self.avg_pool = onnx_AdaptiveAvgPool2d
# 其中两个进行池化下采样->(40*40*256),(40*40*128)
x_l = self.avg_pool(x_l, output_size)
x_m = self.avg_pool(x_m, output_size)
# 另外一个进行上采样(40*40*512)
x_n = F.interpolate(x_n, size=(H, W), mode='bilinear', align_corners=False)
# 通道数(1024+512+256+128)*width=1920*width, shape=(b,40,40,1920*width)
out = torch.cat([x_l, x_m, x_s, x_n], dim=1)
return out
class High_LAF(nn.Module):
"""
原名AdvPoolFusion
lightweight adjacent layer fusion
LAF是一个轻量的邻层融合模块,如下图所示,对输入的local特征(Bi或pi)先和邻域特征融合,
然后再走inject模块,这样local特征图也具有了多层的信息。
深层会融合两个特征
"""
def forward(self, x):
x1, x2 = x
if torch.onnx.is_in_onnx_export():
self.pool = onnx_AdaptiveAvgPool2d
else:
self.pool = nn.functional.adaptive_avg_pool2d
N, C, H, W = x2.shape
output_size = np.array([H, W])
x1 = self.pool(x1, output_size)
return torch.cat([x1, x2], 1)
class High_IFM(nn.Module):
"""
原名TopBasicLayer
深层特征信息融合
"""
def __init__(self,
in_channels,
out_channels_list,
block_num, key_dim, num_heads,
mlp_ratio=4., attn_ratio=2., drop=0.,
# attn_drop=0.,未使用的参数,注释掉
# todo 原始是drop_path
# 和depths(与模型规格有关,l模型时为3,m时为2)
drop_paths=(0.1, 2),
norm_cfg=dict(type='BN', requires_grad=True),
act_layer=nn.ReLU6):
super().__init__()
self.block_num = block_num
drop_path = [x.item() for x in torch.linspace(0, drop_paths[0], drop_paths[1])] # 0.1, 2
self.transformer_blocks = nn.ModuleList()
for i in range(self.block_num):
self.transformer_blocks.append(top_Block(
in_channels, key_dim=key_dim, num_heads=num_heads,
mlp_ratio=mlp_ratio, attn_ratio=attn_ratio,
drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_cfg=norm_cfg, act_layer=act_layer))
self.trans_conv = nn.Conv2d(in_channels, sum(out_channels_list), kernel_size=(1, 1), stride=(1, 1), padding=0)
self.trans_channels = out_channels_list
def forward(self, x):
# token * N
for i in range(self.block_num):
x = self.transformer_blocks[i](x)
x = self.trans_conv(x)
return x.split(self.trans_channels, dim=1)
class High_FAM(nn.Module):
"""
原名PyramidPoolAgg
深层特征信息对齐 Feature Alignment Module
"""
def __init__(self, stride, pool_mode='onnx'):
super().__init__()
self.stride = stride
if pool_mode == 'torch':
self.pool = nn.functional.adaptive_avg_pool2d
elif pool_mode == 'onnx':
self.pool = onnx_AdaptiveAvgPool2d
def forward(self, inputs):
B, C, H, W = get_shape(inputs[-1])
H = (H - 1) // self.stride + 1
W = (W - 1) // self.stride + 1
output_size = np.array([H, W])
if not hasattr(self, 'pool'):
self.pool = nn.functional.adaptive_avg_pool2d
if torch.onnx.is_in_onnx_export():
self.pool = onnx_AdaptiveAvgPool2d
out = [self.pool(inp, output_size) for inp in inputs]
return torch.cat(out, dim=1)
四 定制yaml模型配置文件
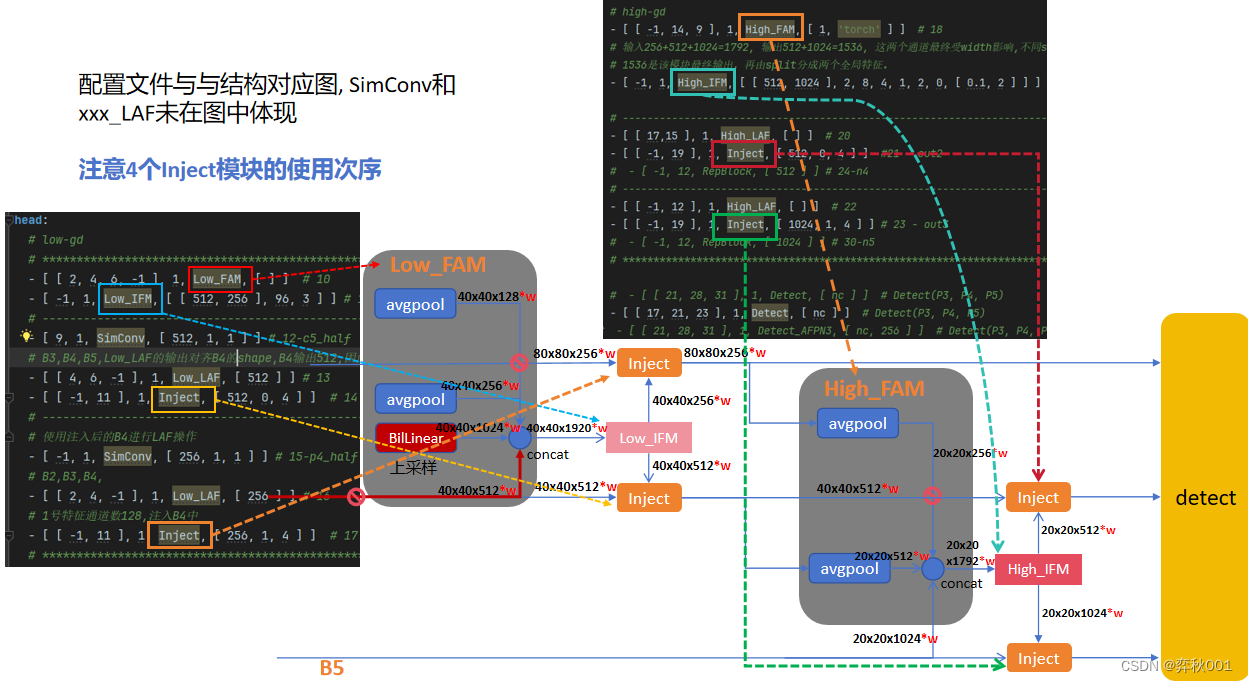
配置文件详细及参数说明如下:
- 需要注意不同的scale的v8模型会设置最大通道数,建议都改为2048,因为通道scale前, gold内部concat操作会有通道数大于1024的情况,如果被截断,会出现通道对不齐的情况。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [ 0.33, 0.25, 2048 ] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [ 0.33, 0.50, 2048 ] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [ 0.67, 0.75, 2048 ] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [ 1.00, 1.00, 2048 ] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [ 1.00, 1.25, 2048 ] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [ -1, 1, Conv, [ 64, 3, 2 ] ] # 0-P1/2
- [ -1, 1, Conv, [ 128, 3, 2 ] ] # 1-P2/4
- [ -1, 3, C2f, [ 128, True ] ]
- [ -1, 1, Conv, [ 256, 3, 2 ] ] # 3-P3/8
# - [ -1, 6, C2f_ODConv, [ 256, True ] ]
- [ -1, 6, C2f, [ 256, True ] ]
- [ -1, 1, Conv, [ 512, 3, 2 ] ] # 5-P4/16
# - [ -1, 6, C2f_ODConv, [ 512, True ] ]
- [ -1, 6, C2f, [ 512, True ] ]
- [ -1, 1, Conv, [ 1024, 3, 2 ] ] # 7-P5/32
- [ -1, 3, C2f, [ 1024, True ] ]
- [ -1, 1, SPPF, [ 1024, 5 ] ] # 9
# - [ -1, 1, ASCPA, [ 1024 ] ] # 10
# YOLOv8.0n head
head:
# low-gd
# ********************************************************************************************************************
- [ [ 2, 4, 6, -1 ], 1, Low_FAM, [ ] ] # 10
# Low_IFM的输出通道会split出2个全局特征,分别注入到B3,B4中,它们通道数分别为256*w,512*w,
# 以yolv8n举例,width=0.25, 因此通道分别为64,128. 这也是split的参数. 于是low_ifm输出的
# 通道:num*0.25=64+128, num=768, 这里把split部分写入了Low_IFM模块,避免在task.py中引入
# 不必要的模块, 96:中间通道数, 3: 融合模块RepVGGBlock重复次数,
# Low_IFM 输出通道受width影响,256+512=768
# 为什么是[512, 256],而不是[256,512]? 因为512对应B4, 先注入B4,用注入后的结果替代原来的B4进行下面的操作
- [ -1, 1, Low_IFM, [ [ 512, 256 ], 96, 3 ] ] # 11
# ----------------------------------------------------------------------------------------------
# SimConv作用是通道减半,不能合并到Low_LAF中,因为输出值
# 在其他地方也会用到, 下面的SimConv功能也是如此
- [ 9, 1, SimConv, [ 512, 1, 1 ] ] # 12-c5_half
# B3,B4,B5,Low_LAF的输出对齐B4的shape,B4输出512,因此Low_LAF输出通道数也是512,
- [ [ 4, 6, -1 ], 1, Low_LAF, [ 512 ] ] # 13
# Low_IFM有两个全局输出特征, 0号特征512,注入B4中,4:整合注入信息的RepBlock重复次数
# RepBlock是当前分支Inject结果的整合,不改变通道数,下同
- [ [ -1, 11 ], 1, Inject, [ 512, 0, 4 ] ] # 14
# ----------------------------------------------------------------------------------------------
# 使用注入后的B4进行LAF操作, 之前要经过SimConv通道减半
- [ -1, 1, SimConv, [ 256, 1, 1 ] ] # 15-p4_half
# B2,B3,B4,
- [ [ 2, 4, -1 ], 1, Low_LAF, [ 256 ] ] # 16
# 1号特征通道数128,注入B4中
- [ [ -1, 11 ], 1, Inject, [ 256, 1, 4 ] ] # 17 -out1
# *******************************************************************************************************************
# high-gd
- [ [ -1, 14, 9 ], 1, High_FAM, [ 1, 'torch' ] ] # 18
# 输入256+512+1024=1792, 输出512+1024=1536, 这两个通道最终受width影响,不同scale的模型自动调整
# 1536是该模块最终输出,再由split分成两个全局特征。
- [ -1, 1, High_IFM, [ [ 512, 1024 ], 2, 8, 4, 1, 2, 0, [ 0.1, 2 ] ] ] # 19
# ----------------------------------------------------------------------------------------------
- [ [ 17,15 ], 1, High_LAF, [ ] ] # 20
- [ [ -1, 19 ], 1, Inject, [ 512, 0, 4 ] ] #21 - out2
# - [ -1, 12, RepBlock, [ 512 ] ] # 24-n4
# ----------------------------------------------------------------------------------------------
- [ [ -1, 12 ], 1, High_LAF, [ ] ] # 22
- [ [ -1, 19 ], 1, Inject, [ 1024, 1, 4 ] ] # 23 - out3
# - [ -1, 12, RepBlock, [ 1024 ] ] # 30-n5
# ********************************************************************************************************************
# - [ [ 21, 28, 31 ], 1, Detect, [ nc ] ] # Detect(P3, P4, P5)
- [ [ 17, 21, 23 ], 1, Detect, [ nc ] ] # Detect(P3, P4, P5)
# - [ [ 21, 28, 31 ], 1, Detect_AFPN3, [ nc, 256 ] ] # Detect(P3, P4, P5)
五 task.py修改部分
在task.py 导入以下模块
# ----------------------------------------------------------------------------------------------------------------------
# 以下,都来自gold-yolo
from .Addmodules.GoldYOLO import (Low_FAM, Low_IFM, SimConv, Low_LAF, Split, Inject, RepBlock, High_FAM, High_IFM, \
High_LAF)
# from .Addmodules.ohter_Gold import IFM, SimFusion_3in, SimFusion_4in, InjectionMultiSum_Auto_pool, PyramidPoolAgg, \
# TopBasicLayer, AdvPoolFusion
# 魔改卷积快,像conv+bn+rule
add_conv = [ODConv2dYolo, ]
# 对C1,C3,C2f这样的模块封装,主要添加在模块重复区域, 输入输出+其他参数
add_block = [C2f_ODConv, CSPStage, C2f_DLKA, ASCPA,
# gold-yolo
Low_IFM, Low_LAF, SimConv, RepBlock, High_IFM
]
# 禁止插入重复次数的参数, 如gold的各个模块
forbid_insert = [Low_IFM, Low_LAF, SimConv, High_IFM]
# 与concat类似,初始化不需要参数, forward接受tensor然后通道维度合并在一起
add_concat = [Low_FAM, High_FAM, High_LAF]
# 最后的检测头魔改
add_detect = [Detect_AFPN3, Detect_FASFF, RepHead]
# ----------------------------------------------------------------------------------------------------------------------
添加的位置如下,经过对原始模块的一通整改, 需要特殊处理的模块仅剩Inject了. 至于下图为什么这样添加,可以参考我另一篇文章:https://editor.csdn.net/md/?articleId=137594790

六 与原版yolov8对比
# 原版v8
# YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
# YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
#yolov8+gold
# YOLOv8n-Gold summary: 498 layers, 8210000 parameters, 8209984 gradients, 18.3 GFLOPs
# YOLOv8s-Gold summary: 498 layers, 30008544 parameters, 30008528 gradients, 63.0 GFLOPs
添加gold模块后参数量显著增大,s版本大约增加3倍参数,实际推理速度还没测过~!
s版yolv8-gold参数分布如下:
from n params module arguments
0 -1 1 928 ultralytics.nn.modules.conv.Conv [3, 32, 3, 2]
1 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
2 -1 1 29056 ultralytics.nn.modules.block.C2f [64, 64, 1, True]
3 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
4 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
5 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
6 -1 2 788480 ultralytics.nn.modules.block.C2f [256, 256, 2, True]
7 -1 1 1180672 ultralytics.nn.modules.conv.Conv [256, 512, 3, 2]
8 -1 1 1838080 ultralytics.nn.modules.block.C2f [512, 512, 1, True]
9 -1 1 656896 ultralytics.nn.modules.block.SPPF [512, 512, 5]
10 [2, 4, 6, -1] 1 0 ultralytics.nn.Addmodules.GoldYOLO.Low_FAM []
11 -1 1 408192 ultralytics.nn.Addmodules.GoldYOLO.Low_IFM [960, [256, 128], 96, 3]
12 9 1 131584 ultralytics.nn.Addmodules.GoldYOLO.SimConv [512, 256, 1, 1]
13 [4, 6, -1] 1 230400 ultralytics.nn.Addmodules.GoldYOLO.Low_LAF [[128, 256, 256], 256]
14 [-1, 11] 1 2825728 ultralytics.nn.Addmodules.GoldYOLO.Inject [256, 256, 0, 4]
15 -1 1 33024 ultralytics.nn.Addmodules.GoldYOLO.SimConv [256, 128, 1, 1]
16 [2, 4, -1] 1 57856 ultralytics.nn.Addmodules.GoldYOLO.Low_LAF [[64, 128, 128], 128]
17 [-1, 11] 1 708352 ultralytics.nn.Addmodules.GoldYOLO.Inject [128, 128, 1, 4]
18 [-1, 14, 9] 1 0 ultralytics.nn.Addmodules.GoldYOLO.High_FAM [1, 'torch']
19 -1 1 4273408 ultralytics.nn.Addmodules.GoldYOLO.High_IFM [896, [256, 512], 2, 8, 4, 1, 2, 0, [0.1, 2]]
20 [17, 15] 1 0 ultralytics.nn.Addmodules.GoldYOLO.High_LAF []
21 [-1, 19] 1 2825728 ultralytics.nn.Addmodules.GoldYOLO.Inject [256, 256, 0, 4]
22 [-1, 12] 1 0 ultralytics.nn.Addmodules.GoldYOLO.High_LAF []
23 [-1, 19] 1 11287552 ultralytics.nn.Addmodules.GoldYOLO.Inject [512, 512, 1, 4]
24 [17, 21, 23] 1 2147008 ultralytics.nn.modules.head.Detect [80, [128, 256, 512]]
YOLOv8s-Gold summary: 496 layers, 30008544 parameters, 30008528 gradients, 63.0 GFLOPs
七 总结
似乎应该说点啥, 但前面都讲完了, 嗯, 那就这样结束吧 !