YOLOv9最新改进系列:融合混合注意力机制CBAM,关注通道和空间特征,助力YOLOv9新模型快速涨点!
YOLOv9原文链接戳这里,原文全文翻译请关注B站Ai学术叫叫首er
B站全文戳这里!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
YOLOv9最新改进系列:融合混合注意力机制CBAM,关注通道和空间特征,助力YOLOv9新模型快速涨点!!
- YOLOv9最新改进系列:融合混合注意力机制CBAM,关注通道和空间特征,助力YOLOv9新模型快速涨点!
- 注意力机制是啥:
- 简介
- 2 实现方法
- 2.1
- 2.2
- 2.3
- 2.4
- 3 代码
- 4 结论
- 5 修改步骤!
- 5.1 修改YAML文件
- 5.2 新建.py
- 5.3 修改tasks.py
- 6、验证是否成功即可
CBAM注意力提出全文戳这
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
截止到发稿时,B站YOLOv9最新改进系列的源码包,已更新了11种的改进!自己排列组合2-4种后,考虑位置不同后可排列组合上千种!!专注AI学术,关注B站博主:Ai学术叫叫兽er!
注意力机制是啥:
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
这就类似于人类的视觉注意力机制,通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。通过这种机制可以利用有限的注意力资源从大量信息中快速筛选出高价值的信息。
简介
Convolutional Block Attention Module(CBAM):CBAM是一种组合模型,将通道注意力和空间注意力相结合,以提高模型的表现力。
CBAM 模块包括两个注意力子模块:通道注意力模块和空间注意力模块。通道注意力模块用于计算每个通道的重要性,以便更好地区分不同通道之间的特征。空间注意力模块则用于计算每个像素在空间上的重要性,以便更好地捕捉图像中的空间结构。
通道注意力模块通过对输入特征图在通道维度上进行最大池化和平均池化,然后将这两个池化结果输入到一个全连接层中,最后输出一个通道注意力权重向量。这个向量用于加权输入特征图中的每个通道,从而更好地区分不同通道的特征。
空间注意力模块通过对输入特征图在通道维度上进行平均池化和最大池化,然后将这两个池化结果输入到一个全连接层中,最后输出一个空间注意力权重张量。这个张量用于对每个像素在空间上进行加权,从而更好地捕捉图像中的空间结构。
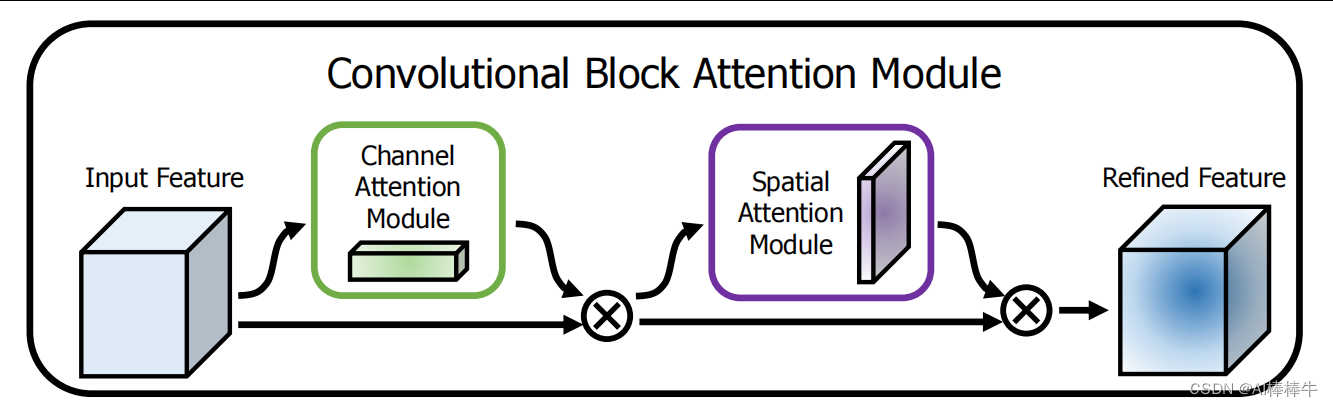
在图中,绿色框表示通道注意力模块,橙色框表示空间注意力模块。通过将这两个模块串联起来,可以得到一个完整的 CBAM 模块,用于插入到卷积神经网络中以提升模型性能。
2 实现方法
通道注意力模块的目标是增强每个通道的特征表达。以下是实现通道注意力模块的步骤:
2.1
全局最大池化和全局平均池化: 对于输入特征图,首先对每个通道执行全局最大池化和全局平均池化操作,计算每个通道上的最大特征值和平均特征值。这会生成两个包含通道数的向量,分别表示每个通道的全局最大特征和平均特征。
2.2
全连接层: 将全局最大池化和平均池化后的特征向量输入到一个共享全连接层中。这个全连接层用于学习每个通道的注意力权重。通过学习,网络可以自适应地决定哪些通道对于当前任务更加重要。将全局最大特征向量和平均特征向相交,得到最终注意力权重向量。
2.3
Sigmoid激活: 为了确保注意力权重位于0到1之间,应用Sigmoid激活函数来产生通道注意力权重。这些权重将应用于原始特征图的每个通道。
2.4
注意力加权: 使用得到的注意力权重,将它们与原始特征图的每个通道相乘,得到注意力加权后的通道特征图。这
3 代码
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
# 全连接层
# nn.Linear(in_planes, in_planes // ratio, bias=False),
# nn.ReLU(),
# nn.Linear(in_planes // ratio, in_planes, bias=False)
# 利用1x1卷积代替全连接,避免输入必须尺度固定的问题,并减小计算量
nn.Conv2d(in_channels, in_channels // ratio, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // ratio, in_channels, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
out = self.sigmoid(out)
return out * x
4 结论
我们提出了卷积瓶颈注意力模块(CBAM),这是一种提高 CNN 网络表示能力的新方法。 我们通过两个独特的模块(通道和空间)应用基于注意力的特征细化,并在保持较小开销的同时实现了相当大的性能改进。 对于通道注意力,我们建议使用最大池化特征和平均池化特征,从而产生比 SE [28] 更好的注意力。 我们通过利用空间注意力进一步提高性能。 我们的最终模块(CBAM)学习什么以及在哪里强调或抑制,并有效地细化中间特征。 为了验证其功效,我们使用各种最先进的模型进行了广泛的实验,并确认 CBAM 在三个不同基准数据集上的性能优于所有基线:ImageNet-1K、MS COCO 和 VOC 2007。此外,我们还可视化了如何 该模块准确推断给定的输入图像。 有趣的是,我们观察到我们的模块诱导网络正确地关注目标对象。 我们希望CBAM成为各种网络架构的重要组成部分。
5 修改步骤!
5.1 修改YAML文件
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
5.2 新建.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
5.3 修改tasks.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
6、验证是否成功即可
执行命令
python train.py
改完收工!
关注B站:Ai学术叫叫兽er
从此走上科研快速路
遥遥领先同行!!!!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!