文章汇总
问题
学习到的模型很容易因为只有少数训练样本形成的有偏分布而变得过拟合。
动机
我们假设特征表示中的每个维度都遵循高斯分布,因此分布的均值和方差可以借鉴类似类的均值和方差,这些类的统计量可以通过足够数量的样本得到更好的估计。
(方法)别人的总结
详见参考文章中的评论区
首先利用backbone提取训练集所有类(基类)的特征,计算mean和var之后用在测试集(新类)中;利用的是基类中部分图像与新类中的部分图像语义相似时,mean和var也十分相似。然后利用基类的mean和var矫正测试集中support set图像的mean 和var。相当于是扩充了support set的数据量。
(方法)我的总结
首先正常对基类提特征,之后计算每个基类的mean和var;
对应每个新类,作者通过计算每个新类的特征空间与每个基类的特征均值之间的欧几里德距离,从支持集中选择与样本的特征距离最近的前k个基类,拿他们的mean和var来标准化测试集中support set的图像。
摘要
从有限数量的样本中学习是具有挑战性的,因为学习到的模型很容易因为只有少数训练样本形成的有偏分布而变得过拟合。在本文中,我们通过从具有足够样本的类中转移统计量来校准这些少数样本类的分布。然后可以从校准分布中抽取足够数量的样本来扩展分类器的输入。我们假设特征表示中的每个维度都遵循高斯分布,因此分布的均值和方差可以借鉴类似类的均值和方差,这些类的统计量可以通过足够数量的样本得到更好的估计。我们的方法可以建立在现成的预训练特征提取器和分类模型之上,而不需要额外的参数。我们表明,使用从校准分布中采样的特征训练的简单逻辑回归分类器可以在三个数据集上优于最先进的精度(与次优相比,miniImageNet提高了5%)。这些生成的特征的可视化表明,我们的校准分布是一个准确的估计。该代码可在https://github.com/ShuoYang-1998/Few_Shot_Distribution_Calibration获得
介绍
由于收集和标注大量数据的成本很高,从有限的训练样本中学习越来越受到关注。研究人员已经开发出算法来提高用很少数据训练的模型的性能。Finn et al (2017);Snell等人(2017)以元学习的方式训练模型,这样模型就可以在只有少量训练样本的情况下快速适应任务。Hariharan & Girshick (2017);Wang等人(2018)尝试通过学习生成模型来综合数据或特征,以缓解数据不足的问题。Ren等人(2018)提出利用未标记数据并预测伪标签来提高少射学习的性能。
虽然大多数先前的工作都集中在开发更强大的模型上,但很少关注数据本身的属性。当数据数量增加时,自然可以更准确地揭示真实分布。经过广泛数据覆盖训练的模型在评估过程中可以很好地泛化。另一方面,当训练一个只有少量训练数据的模型时,通过最小化这些样本上的训练损失,模型倾向于在这些少数样本上过拟合。这些现象如图1所示。这种基于少数例子的偏差分布可能会损害模型的泛化能力,因为它远远不能反映在评估过程中对测试用例进行采样的真实分布。
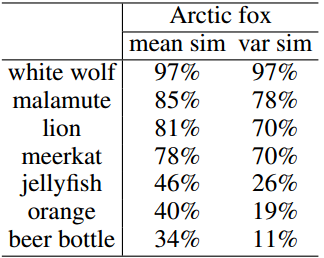
表1:北极狐与不同类别的类平均相似度(“mean sim”)和类方差相似度(“var sim”)。
在这里,我们考虑将这个偏置分布校准为更准确的真实分布近似值。通过这种方式,使用从校准分布中采样的输入训练的模型可以从更精确的分布中推广到更广泛的数据范围,而不仅仅是将自己拟合到那些少数样本中。我们没有校准原始数据空间的分布,而是尝试校准特征空间中的分布,特征空间的维数要低得多,并且更容易校准(Xian et al(2018))。我们假设特征向量的每个维度都服从高斯分布,并观察到相似的类通常具有相似的特征表示的均值和方差,如表1所示。因此,高斯分布的均值和方差可以在相似的类之间传递(Salakhutdinov等人(2012))。同时,当该类有足够的样本时,可以更准确地估计统计量。基于这些观察,我们重用来自超过1-shot类的统计数据,并根据它们的类相似性将它们转移到更好地估计少样本类的分布。根据估计的分布可以生成更多的样本,为训练分类模型提供了足够的监督。
在实验中,我们证明了用我们的策略训练的简单逻辑回归分类器可以在三个数据集上达到最先进的精度。我们的分布校准策略可以与任何分类器和特征提取器配对,不需要额外的可学习参数。与仅使用5way1shot任务中给出的少量样本进行训练的基线相比,从校准分布中选择样本进行训练可以获得12%的精度增益。我们还可视化了校准分布,并表明它是可以更好地覆盖测试用例的基本事实的精确近似值。
2相关工作
3 主要方法
在本节中,我们将在3.1节中介绍少样本分类问题的定义,并在3.2节中详细介绍我们提出的方法。
3.1问题定义
3.2分布校准
正如3.1节所介绍的,基类有足够的数据量,而从新类中抽样的评估任务只有有限数量的标记样本。相对于基于少量样本的估计,基类的分布统计量可以得到更精确的估计,这是一个不适定问题。如表1所示,我们观察到,如果我们假设特征分布为高斯分布,则每个类的均值和方差与每个类的语义相似度相关。考虑到这一点,如果我们知道这两个类有多相似,就可以将统计信息从基类转移到新类。在接下来的章节中,我们将讨论如何在基类(3.2.1)的统计数据的帮助下,仅使用少量样本(3.2.2节)来校准类的分布估计。我们还将详细说明如何利用校准分布来提高少射学习的性能(第3.2.3节)。
请注意,我们的分布校准策略是在特征级别之上的,对任何特征提取器都是不可知的。因此,它可以构建在任何预训练的特征提取器之上,而无需进一步进行昂贵的微调。在我们的实验中,我们在之前的工作(Mangla et al .(2020))之后使用了预训练的WideResNet Zagoruyko & Komodakis(2016)。WideResNet被训练来对基类进行分类,以及一个自我监督的借口任务来学习适合图像理解任务的通用表示。关于训练特征提取器的更多细节,请参考他们的论文。
3.2.1基类统计信息
我们假设基类的特征分布是高斯分布。基类的特征向量的均值被计算为s所有向量中每个维度的均值:

其中是基类i中第j个样本的特征向量,
是基类i中样本的总数。由于特征向量
是多维的,我们使用协方差来更好地表示特征向量中任意一对元素之间的方差。第i类特征的协方差矩阵
计算为:
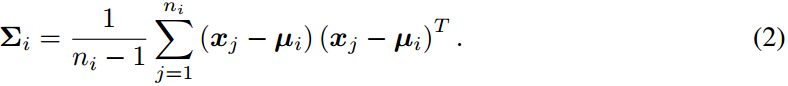
3.2.2校正新类的统计量
在这里,我们考虑一个从新类中抽样的N-way K-shot任务。
Tukey’s Ladder of Powers Transformation
为了使特征分布更接近高斯分布,我们首先使用Tukey's Ladder of Powers变换(Tukey(1977))对目标任务中的支持集和查询集的特征进行变换。Tukey's Ladder of Powers变换是一种幂变换,它可以减少分布的偏度,使分布更像高斯分布。Tukey的权力阶梯变换公式为:

其中λ是调节如何校正分布的超参数。通过设置λ为1,可以恢复原始特征。减小λ使分布减小正偏斜,反之亦然。
通过统计数据转移进行校准
使用第3.2.1节中介绍的基类的统计信息,我们将基类的统计信息转移到新类中,这些统计信息在足够的数据上得到了更准确的估计。迁移基于新类的特征空间与基类的特征均值之间的欧几里德距离,如式1所示。具体来说,我们从支持集中选择与样本的特征距离最近的前k个基类:
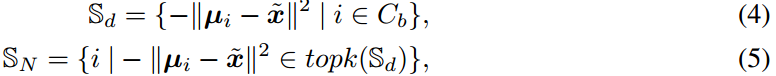
其中,topk(·)是从输入距离集中选择top元素的运算符。
存储相对于特征向量
最接近的k个基类。然后,通过最近基类的统计量校准分布的均值和协方差:
![]()
其中是一个超参数,它决定了从校准分布中采样的特征的分散程度。
对于超过1-shot的少样本学习,上述的分布校准过程需要进行多次,每次使用一个来自支持集的特征向量。这避免了由一个特定样本提供的偏差,并可能实现更多样化和更准确的分布估计。因此,为简单起见,我们将校准后的分布表示为一组统计量。对于一类,我们将统计量集记为
,其中
分别是基于y类支持集中的第i个特征计算的校准均值和协方差。这里,集合的大小是N-way-K-shot任务的K值。
3.2.3如何利用校准后的分布?
使用目标任务中y类的一组校准统计量,我们通过从校准的高斯分布中采样来生成一组标记为y的特征向量:
![]()
这里,每个类生成的特征总数被设置为一个超参数,并且它们在中的每个校准分布中均匀分布。然后,生成的特征与原始支持集特征一起作为特定于任务的分类器的训练数据。
我们通过最小化其支持集S的特征和生成的特征上的交叉熵损失来训练任务的分类器:
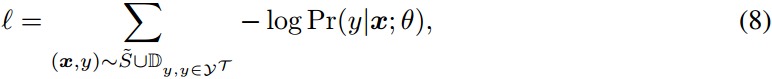
其中,是任务T的类集合。
表示由土耳其幂阶变换变换的特征组成的支持集,分类器模型用θ参数化。
4实验
在本节中,我们将回答以下问题:
与最先进的方法相比,我们的分布校准策略如何执行?
校准后的分布是什么样的?它是这门课的准确近似值吗?•
tukey的权力阶梯转换如何与功能代交互?
每一项对性能有多重要?
4.1实验设置
4.4.1数据集
我们在miniImageNet (Ravi & Larochelle(2017))、tieredImageNet (Ren等人(2018))和CUB (Welinder等人(2010))上评估了我们的分布校准策略。miniImageNet和tieredImageNet有一系列的类,包括各种动物和对象,而CUB是一个更细粒度的数据集,包括各种鸟类。具有不同粒度级别的数据集可能具有不同的特征空间分布。我们希望在所有三个数据集上展示我们策略的有效性和通用性。
miniImageNet来源于ILSVRC-12数据集(Russakovsky et al, 2014)。它包含100个不同的类,每个类有600个样本。图像大小为84 × 84 × 3。我们遵循先前作品中使用的拆分(Ravi & Larochelle, 2017),将数据集拆分为64个基本类,16个验证类和20个新类。
tieredImageNet是ILSVRC-12数据集(Russakovsky et al ., 2014)的更大子集,该数据集包含608个从分层类别结构中采样的类。每个类都属于从ImageNet的高级节点中采样的34个高级类别中的一个。每个类的平均图像数为1281。我们分别使用351,97和160个类进行训练、验证和测试。
CUB是一个细粒度的少量分类基准。它包含200种不同种类的鸟类,总共11,788张大小为84 × 84 × 3的图像。根据之前的工作(Chen等人,2019a),我们将数据集分为100个基本类,50个验证类和50个新类。
4.1.2评价指标
我们使用top-1精度作为评估指标来衡量我们的方法的性能。我们报告了miniImageNet, tieredImageNet和CUB的5way1shot和5way5shot设置的准确性。报告的结果是超过10,000个任务的平均分类精度。
4.1.3实现细节
对于特征提取器,我们使用WideResNet (Zagoruyko & Komodakis, 2016)在之前的工作(Mangla et al .(2020))之后进行训练。对于每个数据集,我们使用基类训练特征提取器,并使用新类测试性能。注意,特征表示是从特征提取器的倒数第二层(带有ReLU激活函数)提取的,因此这些值都是非负的,因此公式3中的Tukey 's Ladder of Powers变换的输入是有效的。在分布校准阶段,我们计算基类统计信息,并将其传递给每个数据集来校准新类分布。我们在默认设置下使用scikit-learn的LR和SVM实现(Pedregosa等人(2011))。我们对除α以外的所有数据集使用相同的超参数值。具体来说,是生成的特征的数量是750;K = 2 λ = 0:5。miniImageNet、tieredImageNet和CUB的α值分别为0.21、0.21和0.3。
4.2与最先进的比较

表2: 5way 1shot和5way 5shot在miniImageNet和CUB上的分类准确率(%),置信区间为95%。加粗的数字用最精确的方法有相交的置信区间。
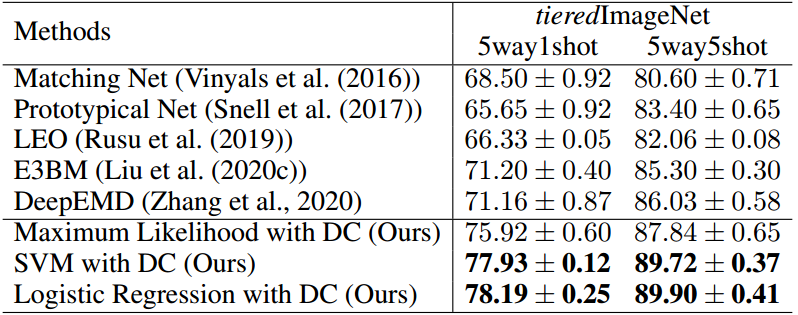
表3:tieredImageNet上5way1shot和5way5shot的分类准确率(%)(Ren et al ., 2018)。加粗的数字用最精确的方法有相交的置信区间。
4.3生成样品的可视化
我们通过可视化从分布中采样的生成特征来显示校准分布的样子。在图2中,我们展示了t-SNE表示(van der Maaten & Hinton(2008))、生成的特征(b,c)以及查询集(d)。在校准分布的基础上,采样的特征形成高斯分布,更多的样本(c)可以更全面地表示分布。由于支持集中的示例数量有限,在本例中只有1个,因此来自查询集的示例通常覆盖更大的区域,并且与支持集不匹配。这种不匹配可以通过生成的特征在一定程度上修复,即(c)中生成的特征可以重叠查询集的区域。因此,使用这些生成的特征进行训练可以缓解仅从少量样本估计的分布与地面真值分布之间的不匹配

图2:分布估计的t-SNE可视化。不同的颜色代表不同的阶级。F表示支持集特征,图(d)中的x表示查询集特征,图(b)和图(c)中的N表示生成特征。
4.4分布校准的适用性
在不同主干网上应用分布校准

我们的分布校准策略对主干/特征提取器是不可知的。表5显示了在不同的特征提取器上应用分布校准时的一致性能提升,即四个卷积层(conv4),六个卷积层(conv6), resnet18, WRN28和WRN28用旋转损失训练。与使用不同基线训练的主干相比,分布校准的精度提高了约10%。
在其他基线上应用分布校准

各种各样的作品都可以从我们的分布校准策略生成的特征训练中受益。我们将分布校准策略应用于两种简单的少镜头分类算法,Baseline (Chen et al ., 2019a)和Baseline++ (Chen et al ., 2019a)。表6显示,我们的分布校准使两者的精度都提高了10%以上。
5结论与未来工作
提出了一种简单有效的少样本分类分布标定策略。没有复杂的生成模型、训练损失和额外的参数来学习,用我们的策略生成的特征训练的简单逻辑回归在miniImageNet上的性能比目前最先进的方法高出约5%。校正后的分布是可视化的,并证明了特征分布的准确估计。未来的工作将探索分布校准在更多问题设置上的适用性,例如多域少镜头分类,以及更多方法,例如基于度量的元学习算法。
参考资料
论文下载(ICLR 2021)
https://openreview.net/pdf?id=JWOiYxMG92s

代码地址
GitHub - ShuoYang-1998/Few_Shot_Distribution_Calibration: [ICLR2021 Oral] Free Lunch for Few-Shot Learning: Distribution Calibration
参考文章
ICLR Oral & T-PAMI 2021 |Free Lunch for Few-shot Learning: Distribution Calibration - 知乎