我以前在中小游戏公司工作的时候,其中一项比较琐碎的工作就是为游戏项目建库建表,主要是为了做数据分析。作为一个职能部门的打杂PHP,对游戏业务并没有什么发言权,但是每次建库建表,却是苦不堪言。
同时部门的基础设施也不怎么完善,比如大数据集群刚开始使用、git 也刚开始使用、各种mysql建库建表工具分布在各个屎山代码、告警系统也分布在各个屎山代码中
所以,一边熟悉工作业务,一边提炼工作需求。最终初步完成下图中的工具流程,勉强把零散的工具代码重新整理,并适配我总结的工作流程
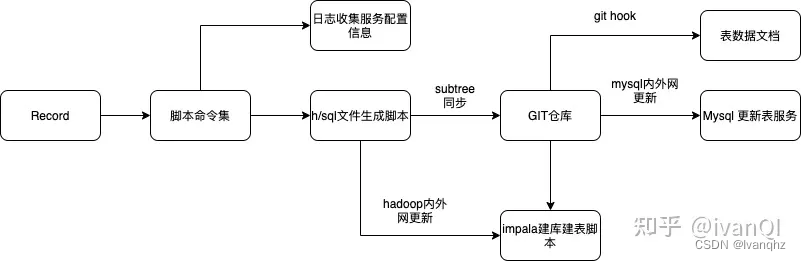
大数据方面,那时对hadoop集群 什么的无能为力,主要是大数据组那边负责,毕竟我只会做数据分析
同时游戏项目组那边也无能为了,只能要求,对接的项目组能够给予我的Record上增加一些注释和特殊的数据类型,这样我就可以写一个脚本进行Record的解析,并生成对应表结构
举个例子: record 格式
%% role_id;用户ID;bigint
%% role_name;用户名;
%% activation_key;激活码;
%% activity_id;活动ID;int
%% platform;平台ID;int
%% award_list;奖励道具;
%% total_pay_gold;消费元宝;int
%% mtime;激活时间;
%% 激活码激活日志
-record(log_activation_code, {role_id=0, role_name="", activation_key="", activity_id=0, platform=0, award_list="", total_pay_gold=0, mtime=0}).
同时也添加了一些增强数据类型
# 常量定义
-define( ROLE_ID, '角色ID;BIGINT:20')
-define( ITEM_JSON, 'JSON,结构[{"type": xx, "type_id": xx, "num":xx}],type为1.元宝;2;铜钱;3;经验;4.二级货币;5.道具;type_id为道具或积分ID,其他情况为0;num为数量;text')
-define( GAINS, '获得奖励,ITEM_JSON')
-define( CONSUMES, '消耗,ITEM_JSON' )
# 使用默认字段解释,之后表结构如果存在以下字段,并且没有给出字段说明,将使用以下的默认说明
# 这样一些常用的字段的解释就可以不用重复写,直接定义默认的字段解释即可
-field(agent_id, '代理ID;int:10')
-field(role_id, 'ROLE_ID')
-field(server_id, '区服ID;int')
-field(account_name, '帐号;varchar:100')
-field(role_name, '角色名;varchar:100')
-field(upf, 'United pf')
-field(pf, '渠道; int')
-field(is_internal, '是否内部号')
-field(mtime, '时间')
通过以上的数据注释/类型补全就可以实现,对应的解析脚本。主要实现的功能包括:
- record 校验 () 代表一个完整的 record
- 获取默认定义信息(define、field)
- 获取文本注释(%%、#)信息
- 对record 内的字段进行处理 && 处理record类型和备注类型
- 检查 record 字段类型(类型检测)
- 错误信息提示:
- 默认类型缺失: lackOfDataValueTypes
- 默认类型与定义类型不一致: typeInconsistency
- record 字段重复定义: fieldRepetitionDefinition
如果有兴趣可以点击以下的脚本链接
- record2sql
经过这一次事情,也对文本解析这一过程越发感兴趣。但是由于个人基础不够,也不知道什么是编译原理,更直观的则是 对 字符串匹配算法 的研究
比如学习什么 BF 算法、RK算法、BM算法、KMP算法、AC自动机
- 如何在字符串中找到特定的字符?
当然作为一个实战为主的人,我也把对应的字符串匹配算法,加入到某个web项目中
- Web服务项目
作为模板解析引擎,使用是主要是BM算法
/**
*
* BM字符匹配
* 1. 把字符串转换成unicode编码
* 2. 然后循环检测'{{' 或 '}}'的存在
* 3. 通过BM字符串算法,进行替换
*
* 时间复杂度: O(n ^ 2)
*/
string TemplateReplace::matchByBm(string text)
{
....
}
为什么没有使用多模式串匹配。因为当时对字符编码还不够熟悉,在文本匹配出现了乱码。当然这算我做的第一个C++项目,性能自然是不咋滴
学习的知识越多,不知道的东西也更多,更疑惑的是,编程语言和操作系统在我眼中成为了黑箱一样的存在,特别想拆开分析一番。也是这时接触到了编译原理
- 为什么要把编译技术的知识与实践相结合?
下面是编译技术的整体流程
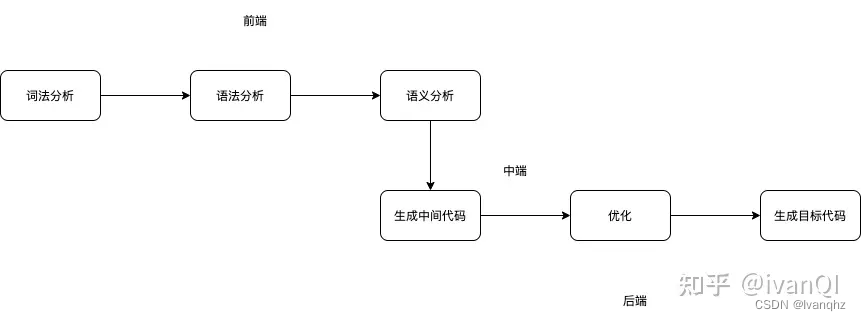
- 词法分析: 词法分析是把一个一个的字符变成一个一个的单词(Token)
- 语法分析: 通过递归下降和上下文无关生文法成抽象语法树(AST)
- 语义分析: 在抽象语法树的基础上,保证语义的正确
- 中间码生成: 现在的编译器都不是直接生成机器代码,而是先生成一种中间语言的代码.为了能够适配不同的架构(x86、mips、risc-v)
- 中间码优化:代数优化、常数折叠、删除不可达的基本块、删除公共子表达式、拷贝传播、常数传播、 死代码删除、代码移动、部分冗余删除
- 机器码生成: 源码翻译成最终能在机器上执行运行的程序,所以编译器最后要把中间码转换为机器码
简单点,可以通过有限自动机实现简单的词法分析器
- 词法分析器例子
SimpleTokenReader* SimpleLexer::tokensize(string code)
{
...
try {
for (int i = 0; i < codeLen; i++) {
ch = (char) code[i];
switch (state) {
case Initial:
state = initToken(ch); // 重新确定状态
break;
case Id:
if (isAlpha(ch) || isDigit(ch)) {
tokenText.push_back(ch); // 保持标识符状态
} else {
state = initToken(ch); // 退出标识符状态,并保存Token
}
break;
case GT:
if (ch == '=') {
token->type = TokenType::GE; // 状态成GE
state = DfaState::GE;
tokenText.push_back(ch);
} else {
state = initToken(ch); // 推出GT状态,并保存Token
}
break;
case GE:
case Assignment:
case Plus:
case Minus:
case Star:
case Slash:
case SemiColon:
case LeftParen:
case RightParen:
state = initToken(ch); // 退出当前状态,并保存Token
break;
case IntLiteral:
if (isDigit(ch)) {
tokenText.push_back(ch); // 继续保持在数字字面量状态
} else {
state = initToken(ch); // 退出当前状态,并保存Token
}
break;
case Id_int1:
if (ch == 'n') {
state = DfaState::Id_int2;
tokenText.push_back(ch);
} else if (isDigit(ch) || isAlpha(ch)) {
state = DfaState::Id; // 切换回ID状态
tokenText.push_back(ch);
} else {
state = initToken(ch);
}
break;
case Id_int2:
if (ch == 't') {
state = DfaState::Id_int3;
tokenText.push_back(ch);
} else if (isDigit(ch) || isAlpha(ch)) {
state = DfaState::Id; // 切换回id状态
tokenText.push_back(ch);
} else {
state = initToken(ch);
}
break;
case Id_int3:
if (isBlank(ch)) {
token->type = TokenType::Int;
state = initToken(ch);
} else {
state = DfaState::Id; // 切换回Id状态
tokenText.push_back(ch);
}
break;
default:
break;
}
}
// 把最后一个token送进去
if (tokenText.length() > 0) {
initToken(ch);
}
} catch (exception& e) {
cout << "exception: " << e.what() << endl;
}
return new SimpleTokenReader(tokens);
}
接下来的语法分析,主要通过上下文无关文法 + 递归下降生成AST
- 编译原理中的右递归文法不会死循环吗?
- 词法分析器例子
通过以上一些知识和代码的积累,就可以完成一个简单的脚本语言
- 简单脚本例子
递归下降算法这个算法很常用,但会有回溯的现象,在性能上会有损失
所以要把算法升级一下,实现带有预测能力的自顶向下分析算法,避免回溯。而要做到这一点,就需要对自顶向下算法有更全面的了解
自顶向下分析的算法是一大类算法。总体来说,它是从一个非终结符出发,逐步推导出跟被解析的程序相同的 Token 串
根据搜索的策略,有深度优先(Depth First)和广度优先(Breadth First)两种,这两种策略的推导过程是不同的
深度优先(Depth First): 沿着一条分支把所有可能性探索完
广度优先(Breadth First): 也叫层级遍历算法,把兄弟节点写遍历,再构建下一层的兄弟节点,使得我们遍历树或图非常便利
- dfs && bfs 例子
但是使用广度优先遍历,需要探索的路径数量会迅速爆炸,成指数级上升。这个时候就出现了我们需要的LL(1) 算法
- LL(1)算法
但是对算法的探究是无止境的,出现了诸如LL(k)算法,还有更高效的LR系列算法
- LR算法-移进和归约
- LR算法例子
手写文本解析算法自然是很酷,但是当了要快速实现功能的时候,就很难受。所以这个时候我就会使用Antrl 。Antlr 是一个开源的工具,支持根据规则文件生成词法分析器和语法分析器,它自身是用 Java 实现的,但也提供对应C++ API
这里使用《Antlr4权威指南》的12.4 的 xml 解析例子,说明 antrl的使用。 当然也可以查看 参考资料[1] 进行antrl的学习
词法规则: XMLLexer.g4
lexer grammar XMLLexer;
// 默认模式: 标签外
COMMENT: '<!--' .*? '-->' ;
CDATA: '<![CDATA[' .*? ']]>';
/**
* 包含所有的DTD、类似<!ENTiTY ...> 的实体定义以及记号声明<!NOTATION>
*/
DTD: '<!' .*? '>' -> skip;
EntityRef: '&' Name ';' ;
CharRef: '&#' DIGIT+ ';' | '&#x' HEXDIGIT+ ';' ;
SEA_WS : (' ' | '\t' | '\r'? '\n');
OPEN : '<' -> pushMode(INSIDE) ;
XMLDeclOpen: '<?xml' S -> pushMode(INSIDE) ;
SPECIAL_OPEN: '<?' Name -> more,pushMode(PROC_INSTR);
TEXT: ~[<&]+; // 匹配任意除<和&之外的16位字符
mode PROC_INSTR;
PI: '?>' -> popMode ; // 关闭<?...?>
IGNORE: . -> more;
mode INSIDE;
CLOSE: '>' -> popMode;
SPECIAL_CLOSE: '?>' -> popMode; // 关闭<?xml...?>
SLASH_CLOSE: '/>' -> popMode;
SLASH: '/';
EQUALS: '=';
STRING: '"' ~[<"]* '"'
| '\'' ~[<']* '\''
;
Name : NameStartChar NameChar* ;
S: [\t\r\n] -> skip;
// fragment 用于提取输入字符流中的一个子集,这个子集可以被包含在其他更复杂的规则中
fragment
HEXDIGIT: [a-fA-F0-9] ;
fragment
DIGIT: [0-9] ;
fragment
NameChar : NameStartChar
| '_' | '.' | DIGIT
| '\u00B7'
| '\u0300'..'\u036F'
| '\u203F'..'\u2040'
;
fragment
NameStartChar
: 'A'..'Z' | 'a'..'z'
| '\u00C0'..'\u00D6'
| '\u00D8'..'\u00F6'
| '\u00F8'..'\u02FF'
| '\u0370'..'\u037D'
| '\u037F'..'\u1FFF'
| '\u200C'..'\u200D'
| '\u2070'..'\u218F'
| '\u2C00'..'\u2FEF'
| '\u3001'..'\uD7FF'
| '\uF900'..'\uFDCF'
| '\uFDF0'..'\uFFFF' // implicitly includes ['\u10000-'\uEFFFF]
;
语法规则: XMLParser.g4
parser grammar XMLParser;
options { tokenVocab=XMLLexer; } // 指定词法规则文件
document: prolog? misc* element misc*;
prolog: XMLDeclOpen attribute* SPECIAL_CLOSE;
content: chardata? ((element | reference | CDATA | PI | COMMENT) chardata?)* ;
element: '<' Name attribute* '>' content '<' '/' Name '>'
| '<' Name attribute* '/>'
;
reference: EntityRef | CharRef ;
attribute: Name '=' STRING ; // 我们的 STRING 就是规范里的AttValue
/**
* 其余所有未标记的文本构成了文档中的字符数据
*/
chardata: TEXT | SEA_WS;
misc: COMMENT | PI | SEA_WS ;
待解析的xml: book.xml
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book id="1">
<name>冰与火之歌</name>
<author>乔治马丁</author>
<year>2014</year>
<price>89</price>
</book>
<book id="2">
<name>安徒生童话</name>
<year>2004</year>
<price>77</price>
<language>English</language>
</book>
</bookstore>
XML AST 结果
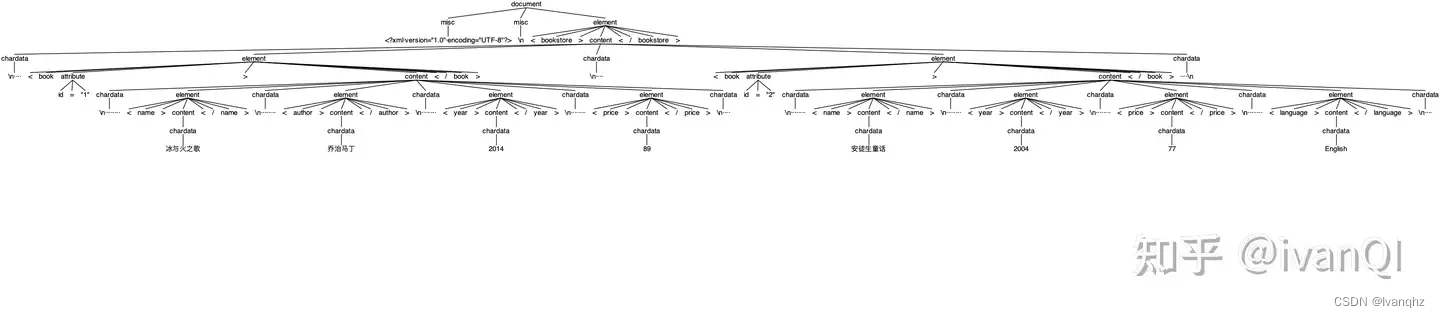
具体的代码和规则,可以在GitHub 中查看。通过定义好的解析规则生成AST。但是接下来改怎么对AST的各个节点进行操作,比如最常规的增删改查?
这个时候就要使用 antlr 的 Vistor 模式,为每个 AST 节点实现一个 visit 方法
antlr -visitor PlayScript.g4
-visitor 参数告诉 Antlr 生成下面两个接口和类
public interface PlayScriptVisitor<T> extends ParseTreeVisitor<T> {...}
public class PlayScriptBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements PlayScriptVisitor<T> {...}
在 PlayScriptBaseVisitor 中,可以看到很多 visitXXX() 这样的方法,每一种 AST 节点都对应一个方法
@Override public T visitPrimitiveType(PlayScriptParser.PrimitiveTypeContext ctx) {...}
比如,我以前做过的 playscript-cpp 项目,使用Vistor 模式 并通过 C++ 编写栈机解释器,实现代码的基本功能
类java 代码: test.play
double foo(double x) {
return (1.0+2.0+x)*(x+(1.0+2.0));
}
foo(3.0);
对应的AST:
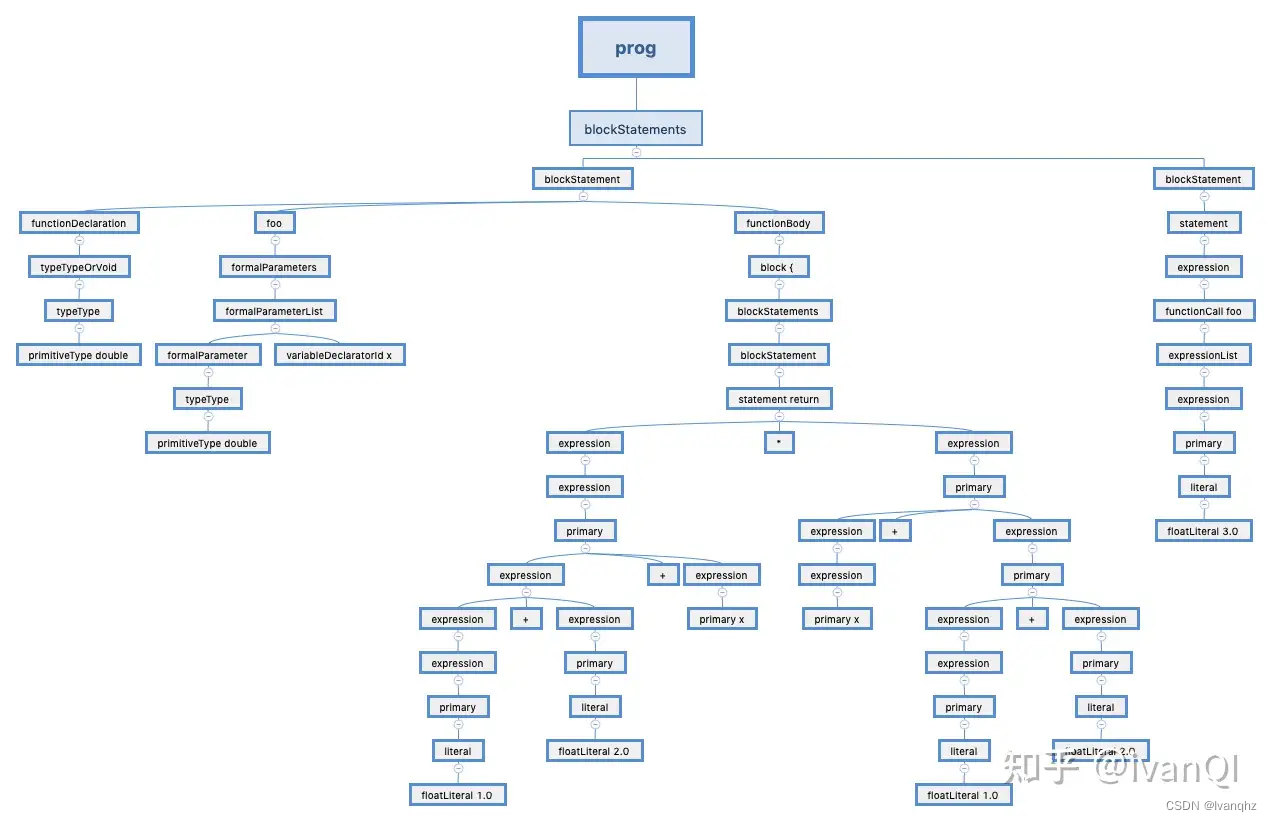
具体的栈机的实现代码不在此展示。但是通过C++编写栈机确实能够很好的屏蔽底层中间码的生成或中间码优化
这个时候就该LLVM登场了,具体LLVM怎么编写一门语言可以查看参考资料[3]
- LLVM IR的对象模型
- LLVM 案例分析
- 代码优化-目标、对象、范围
参考资料
- Antlr4系列(一):语法分析器学习
- Antlr4系列(二):实现一个计算器
- My First Language Frontend with LLVM Tutorial
- llvm入门教程-Kaleidoscope前端-3-代码生成
- 《Antlr4 权威指南》
- 《编译器设计》
- 《编译原理之美》