Logisim的简介和安装
首先要知道什么是logisim?
Logisim是一种用于数字电路设计和模拟的开源工具,Logisim在2014年10月11日无限期暂停。因它足够简单,可以帮助学习逻辑电路相关的基本概念而闻名。Logisim被世界各地大学的学生在课程中使用。
Logisim的特性
- 开源免费
- 绘画界面直观简洁
- 可以在任何支持Java 5或更高版本的机器上运行,同时针对MacOS X和Windows发布了特殊版本
由于Logisim现在已经停止更新了,我这里提供两种安装方式
官方网站:http://www.cburch.com/logisim/
汉字的编码
首先我们应该了解汉字是如何编码的?我们为什么要将汉字进行编码?
我们知道,汉字的特点是数量庞大、字形复杂,并且存在大量一音多字和一字多音的现象。由于汉字编码的诸多问题,导致汉字很难进入计算机。为了解决这个汉字输入输出的问题,于是就衍生出了汉字编码的概念。
汉字编码的分类
计算机中汉字的表示也是用二进制编码,同样是人为编码的。根据应用目的的不同,汉字编码分为外码、交换码、机内码和字形码。
我这里仅简单介绍,交换码(国标码)和机内码,想要了解更多的可以自行百度
交换码(国标码)
计算机内部处理的信息,都是用二进制代码表示的,汉字也不例外。而二进制代码使用起来是不方便的,于是需要采用信息交换码。中国标准总局1981年制定了中华人民共和国国家标准GB2312–80《信息交换用汉字编码字符集–基本集》,即国标码。
而区位码是国标码的另一种表现形式,把国标GB2312–80中的汉字、图形符号组成一个94×94的方阵,分为94个“区”,每区包含94个“位”,其中“区”的序号由01至94,“位”的序号也是从01至94。94个区中位置总数=94×94=8836个,其中7445个汉字和图形字符中的每一个占一个位置后,还剩下1391个空位,这1391个位置空下来保留备用。
机内码
根据国标码的规定,每一个汉字都有了确定的二进制代码,在微机内部汉字代码都用机内码,在磁盘上记录汉字代码也使用机内码。
汉字编码的字符集
我们要知道什么是汉字编码的字符集?
汉字编码的字符集是一套系统或规范,用于将汉字和其他字符以数字的形式进行编码,使得计算机系统能够存储、处理和显示这些字符。由于汉字的数量庞大且具有复杂的结构,不同的字符集有不同的设计和目标,来满足各种技术和语言需求
GB2312
- 定义:GB2312是中国国家标准的简化汉字字符集,首次发布于1980年。
- 内容:包含了6763个汉字和682个其它符号,涵盖了中国大陆使用的大部分简体汉字。
- 用途:这是最早的汉字编码标准之一,广泛用于早期的电脑和网络系统中。
GBK
- 定义:GBK是对GB2312的扩展,首次发布于1995年。
- 内容:包含了所有GB2312字符,并新增了近20000个汉字和符号,支持繁体汉字和少数民族文字。
- 用途:GBK编码兼容GB2312,大幅扩展了汉字的覆盖范围,适用于需要处理多种汉字形式的应用。
GB18030
- 定义:GB18030是一种更为全面的汉字编码系统,发布于2000年,并在2005年进行了更新。
- 内容:它是一个多字节字符集,不仅包括GBK、GB2312的所有字符,还加入了更多的少数民族字符以及所有Unicode的字符。
- 用途:GB18030是中国的国家标准,所有在中国销售的软件和操作系统都必须支持此编码,确保字符编码的国际兼容性和全面性。
Big5
- 定义:Big5是台湾地区使用的繁体汉字字符集,首次发布于1984年。
- 内容:主要包括繁体汉字,广泛应用于台湾及香港等地区。
- 用途:虽然主要用于繁体字环境,但在一些历史应用和地区性软件中仍然非常重要。
Unicode
- 定义:Unicode是一个国际标准,旨在为全世界所有的书写系统提供唯一的编码。
- 内容:包括从世界上每一种已知的字符和文字系统的字符,其中包括所有类型的汉字。
- 用途:Unicode是目前最广泛使用的编码系统,它使得跨语言、跨平台的数据处理和交换变得可能,是现代软件和网络环境的核心组成部分。
汉字编码的转换原理
转换关系:设转换为16进制的区位码为区位码I
- 区位码I = 区位码的区码(前两位)和位码(后两位)分别转十六进制按原顺序组合起来
- 国标码 = 区位码I + 2020H
- 机内码 = 国标码 + 8080H
- 机内码 = 区位码I + A0A0H
转换示例:
假设我们有一个区位码为"0101",我们可以按照以下步骤进行转换:
- 区位码"0101"转换为区位码I(十六进制不变)是"0101"
- 区位码I"0101"加上2020H得到国标码为"2121"
- 机内码可以有两种计算方式:
- 从国标码"2121"加上8080H得到机内码"A1A1"
- 直接将区位码I"0101"加上A0A0也得到机内码"A1A1"
转换样例:
例如,我们已知华的机内码是BBAA(GB2312),根据上面的结论可以知道华的区位码I就是BBAA-A0A0=1B0AH
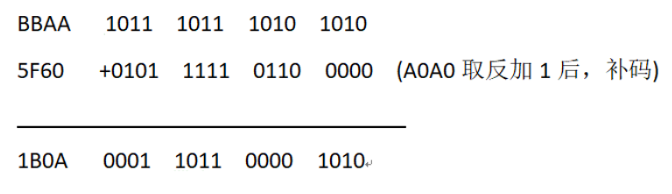
根据GB2312编码的特点,把2个字节的最高位都设置为1,(5F60改为D),使得计算结果的两个字节,最高位也是1

如果我们在一个两字节(16位)的编码中操作,其中每个字节包含8位,那么:
- 第一个字节(位号字节):XXXX XXXX
- 第二个字节(区号字节):XXXX XXXX
在一个16位的表示中,这就成为:XXXX XXXX XXXX XXXX
这里,位号可以取自最右边的7位(0到6)。
区号可以取自接下来的7位(8到14),因为从0开始计数的话,第一个字节是0到7位,第二个字节是8到15位。
程序设计
对应的c++程序设计
#include <iostream>
#include <string>
#include <vector>
#include <iomanip>
#include <locale>
#include <codecvt>
std::string convertStr(const std::string& msg) {
// C++11之后可以使用codecvt_utf8库来进行编码转换
std::wstring_convert<std::codecvt_utf8<wchar_t>, wchar_t> cv;
std::wstring wide_string = cv.from_bytes(msg);
// 使用vector来存储每个字符的GB2312编码
std::vector<int> gb2312_bytes;
for (wchar_t wc : wide_string) {
// 如果是ASCII字符,直接加入
if (wc < 128) {
gb2312_bytes.push_back(wc);
} else {
// 非ASCII字符,转为GB2312
// 这里需要一个GB2312编码器,C++标准库中没有直接支持,可能需要第三方库或平台特定的API
// 这是一个示意,实际上可能需要更复杂的操作
int converted = /* 转换wc到GB2312 */;
gb2312_bytes.push_back(converted);
}
}
std::ostringstream gbString;
int i = 0;
for (int b : gb2312_bytes) {
// 将每个字节转换为16进制
gbString << std::uppercase << std::setfill('0') << std::setw(2) << std::hex << (b & 0xFF) << "\t";
i++;
if (i == 6) {
i = 0;
gbString << "\n";
}
}
return gbString.str();
}
int main() {
std::string msg = "华您好。我是测试001";
// 使用cout来输出信息
std::cout << "请在下一行,输入一个字符串:" << std::endl;
std::string input;
std::cin >> input;
std::string converted_msg = convertStr(input);
std::cout << converted_msg << std::endl;
return 0;
}
Java代码
package Test;
import java.io.UnsupportedEncodingException;
import java.util.Scanner;
public class Test03 {
public static void main(String[] args) throws UnsupportedEncodingException {
// TODO Auto-generated method stub
String msg = "华您好。我是测试001";
//msg = "。"; //中文名号,两个字节。
System.out.println("请在下一行,输入一个字符串:");
Scanner reader=new Scanner(System.in);
msg = reader.next();
msg = convertStr(msg);
System.out.println(msg);
}
public static String convertStr(String msg) throws UnsupportedEncodingException {
//先把字符串按gb2312转成byte数组
byte[] bytes = msg.getBytes("gb2312");
StringBuilder gbString = new StringBuilder();
int i=0;
for (byte b : bytes)
{
// 再用Integer中的方法,把每个byte转换成16进制输出
String temp = Integer.toHexString(b);
//判断进行截取
if(temp.length()>=8){
temp = temp.substring(6, 8); //取第7个和第8个
}
gbString.append("%" + temp + "\t");
i++;
if(i==6) {
i=0;
gbString.append("\n");
}
}
return gbString.toString();
}
}
国标转区位码电路设计
从上面的转换原理可以得出,机内码 = 区位码I + A0A0H,那么区位码I = 机内码 - A0A0H,这样的话我们就可以使用一个加法器来实现从国标码到区位码的转换。从上面的转换原理可以知道-A0A0H的补码是:5F60H,这样我们就可以设计出转换电路
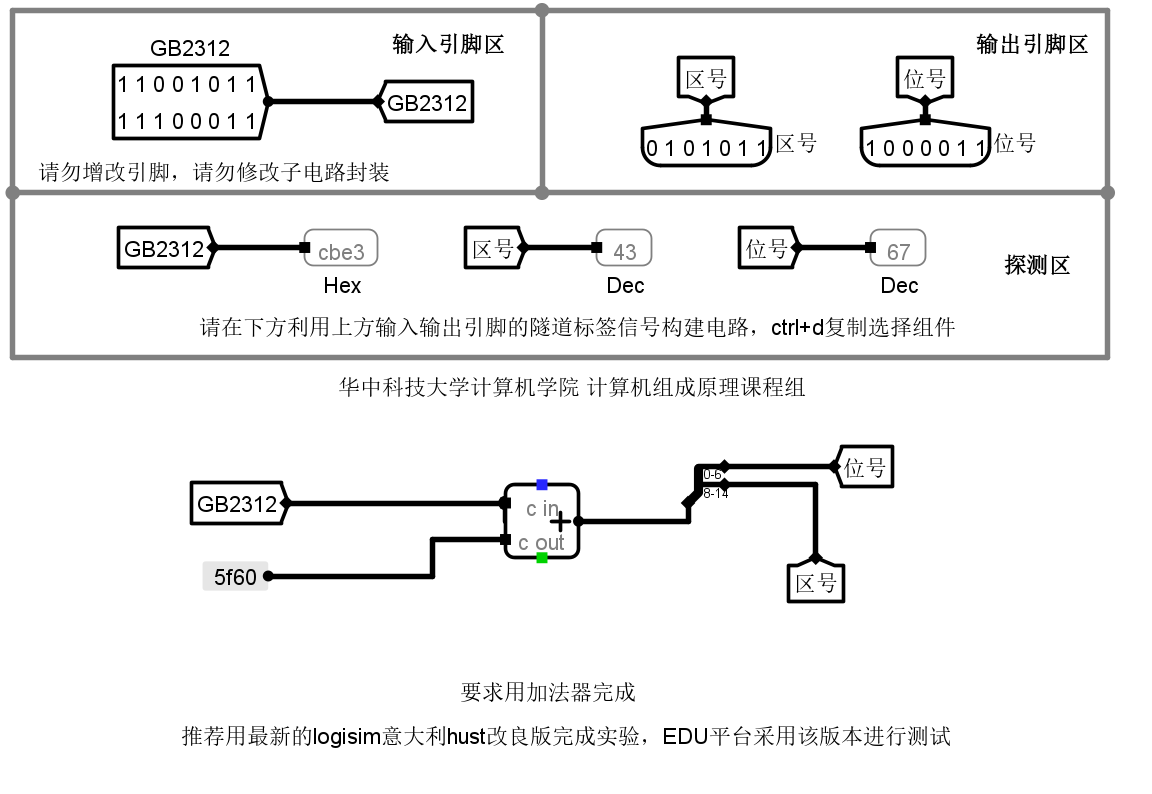
将电路封装
汉字编码测试
编辑存储内容,相应内容在GB2312可以查到
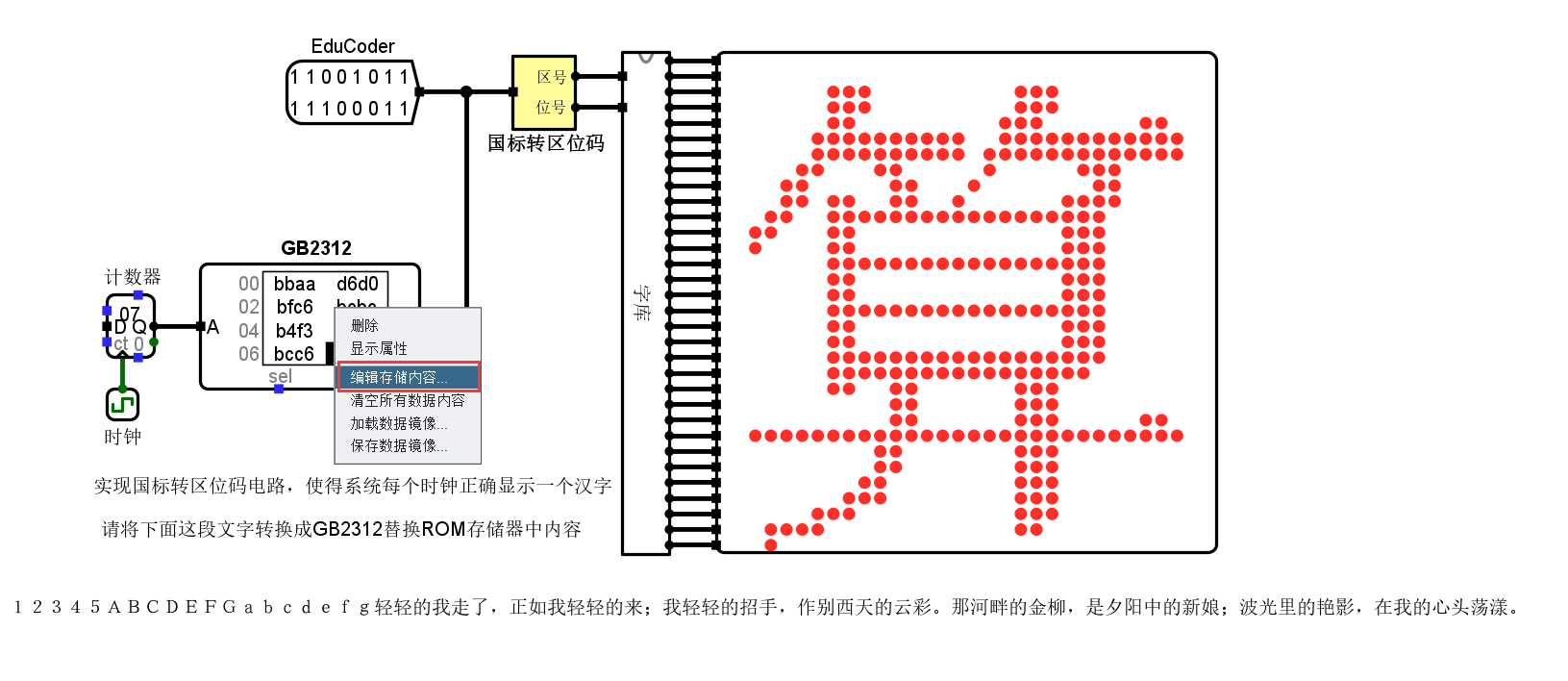
进行数据修改
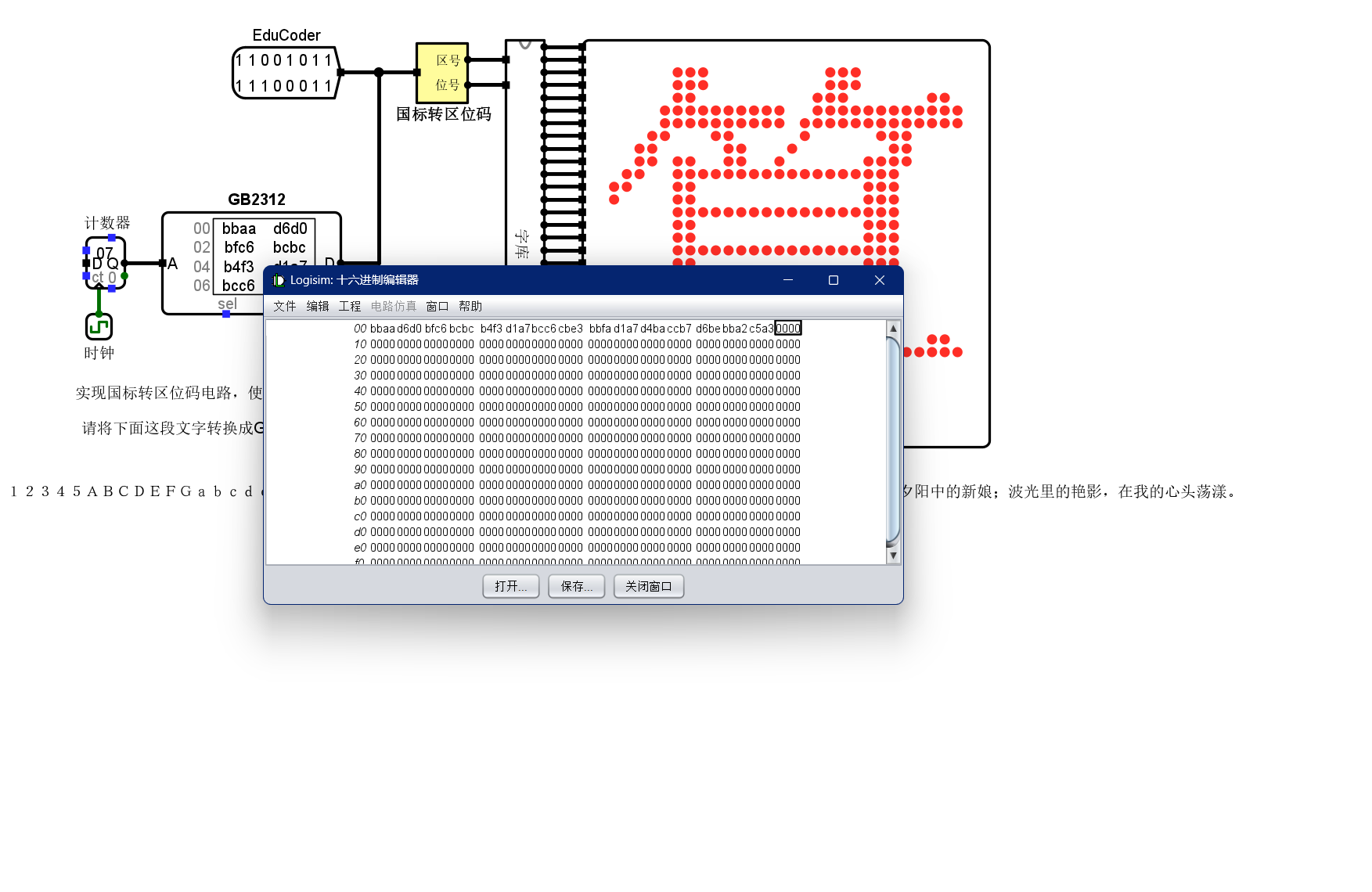
最后附上GB2312编码表GB2312编码表zt.docx
总结
在本实验中我学会了汉字编码的转换,国标转区位码的电路设计等等。最初让我感到困惑的就是汉字编码的一些概念,对机内码和国标码的理解还不到位导致后面设计困难。