摘要
时空动作定位要求将两种信息源整合到设计的架构中:(1) 来自先前帧的时间信息和(2) 来自关键帧的空间信息。当前的最先进方法通常使用单独的网络提取这些信息,并使用额外的机制进行融合以获得检测结果。YOWO是一个用于视频流中实时时空动作定位的统一CNN架构。YOWO是一个单阶段架构,具有两个分支,可以同时提取时间和空间信息,并直接从视频片段中预测边界框和动作概率。由于整个架构是统一的,因此可以端到端优化。YOWO架构速度快,提供每秒34帧的16帧输入片段和每秒62帧的8帧输入片段,这目前是时空动作定位任务上最快的最先进架构。值得注意的是,YOWO在J-HMDB-21和UCF101-24数据集上超越了先前的最先进算法,分别取得了约3%和12%的提升。此外,YOWO是第一个也是唯一一个在AVA数据集上提供有竞争力结果的单阶段架构。
1. 引言
近年来,时空人类动作定位的主题一直受到关注,其目标不仅是识别动作是什么发生的,而且还要在时间和空间上定位它。在这样的任务中,与静态图像中的对象检测相比,时间信息起着至关重要的作用。找到一个有效的策略来聚合空间和时间特征使问题更具挑战性。另一方面,实时人类动作检测在众多视觉应用中变得越来越关键,例如人机交互(HCI)系统、无人机(UAV)监控、自动驾驶和城市安全系统。

2. 相关工作
2.1. 深度学习中的动作识别
自从深度学习在图像识别中带来显著的改进以来,许多研究工作致力于将其扩展到视频中的动作识别。然而,对于动作识别,除了从每个单独图像中提取的空间特征外,还需要考虑这些帧与帧之间的时间上下文关系。
2.2. 时空动作定位
对于图像中的目标检测,R-CNN系列通过使用选择性搜索或区域提议网络(RPN)在第一阶段提取可能包含目标的区域提议,然后在第二阶段对这些提议区域进行分类和定位,以此达到目标检测的目的。尽管Faster R-CNN在对象检测领域取得了最先进的成果,但其两阶段的架构较为耗时,难以应用于实时任务的需求。与此同时,YOLO和SSD等方法旨在通过简化这一过程至单阶段,从而实现出色的实时性能。
对于视频中的动作定位问题,受到R-CNN系列算法的启发,大多数研究方法采取了先在每一帧中检测人物,随后将这些检测到的边界框合理链接起来形成动作管的方法。基于双流检测器的方法在原始分类器的基础上增加了一个额外的流,用于处理光流模态。此外,还有一些研究使用3D-CNN生成视频剪辑中的动作管提议,并在对应的3D特征上进行回归和分类,这些方法因此需要依赖区域提议。在最近的一项研究中有研究者提出了一种3D胶囊网络用于视频动作检测,该网络能够同时进行像素级动作分割和动作分类。然而,这种网络由于是基于U-Net架构的3D-CNN,其计算复杂性和参数数量较大,成本较高。
2.3. 注意模块
注意力机制是一种有效的手段,它用于捕捉特征之间的长距离依赖关系,在卷积神经网络(CNN)中已经尝试用于提升图像分类和场景分割的性能。在这些研究中,空间注意力被用来处理特征在空间上的关系,而通道注意力则致力于突出最重要的通道,同时抑制不那么重要的通道。Squeeze-and-Excitation模块作为一个通道注意力单元,通过较低的计算成本有效地提高了CNN的性能。在视频分类任务中,非局部块则考虑了时空信息,以学习不同帧之间特征的相互依赖性,这种方法可以被看作是一种自注意力策略。通过这种方式,模型能够更好地理解和利用视频帧之间的时空关系,从而提高对动作和事件的识别准确性。
3. 方法论
3.1. YOWO架构
YOWO架构如下图所示,可以分为四个主要部分:3D-CNN分支、2D-CNN分支、通道融合和注意机制(CFAM)以及边界框回归部分。
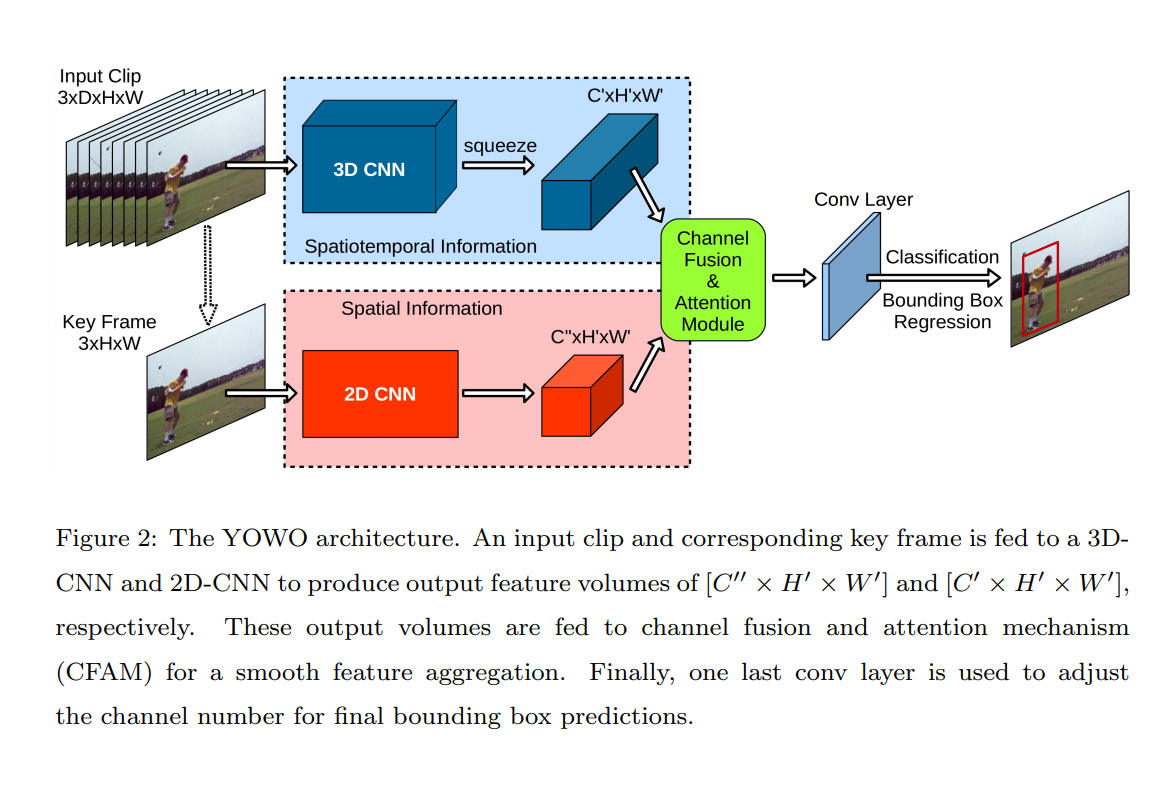
3D-CNN分支
由于上下文信息对于理解人类动作非常关键,YOWO采用了3D-CNN来提取时空特征。3D-CNN通过在空间和时间维度上施加卷积运算捕捉运动信息。在YOWO框架中,基础的3D-CNN架构是3D-ResNext-101,因为它在Kinetics数据集上表现出色。除了3D-ResNext-101,还尝试了其他不同的3D-CNN模型作为消融研究的一部分。对于所有使用的3D-CNN架构,YOWO移除了最后一个卷积层之后的所有层。3D网络的输入是一系列按时间顺序排列的连续帧组成的视频片段,其数据格式为[C × D × H × W],其中C代表颜色通道数为3,D是输入帧的数量,H和W分别是输入图像的高度和宽度。3D ResNext-101的最后一个卷积层输出的特征图形状为[C′ × D′ × H′ × W′],这里C′是输出的特征通道数,D′被设置为1,而H′和W′分别是H和W除以32的结果。输出特征图的深度维度被缩减为1,使得输出的体积变为[C′ × H′ × W′],这样就能保证其与2D-CNN输出的特征图在空间维度上相匹配,便于后续的特征融合和处理。
2D-CNN分支
同时,为了解决空间定位问题,YOWO也并行地提取了关键帧的2D特征。选择了Darknet-19作为2D CNN分支的基础架构,因为它在准确性和计算效率之间实现了良好的平衡。关键帧的尺寸为[C × H × W],它是输入视频片段中最接近当前时间点的一帧,因此不需要额外的数据加载器来处理。Darknet-19输出的特征图尺寸为[C′′ × H′ × W′],这里C = 3表示输入图像的颜色通道数,C′′是输出特征图的通道数,H′ = H/32和W′ = W/32分别表示特征图的高度和宽度,经过了下采样处理,与3D-CNN的情况类似。
YOWO的另一个重要优势在于其灵活性,2D CNN和3D CNN分支中的架构可以根据需要被替换为任何其他的CNN架构。这样的设计使得YOWO不仅简单易用,而且模型切换也非常便捷。需要强调的是,尽管YOWO包含两个分支,但它是一个统一的架构,支持端到端的训练,这意味着从输入到输出,整个模型可以作为一个整体进行训练和优化,提高了模型的训练效率和性能。
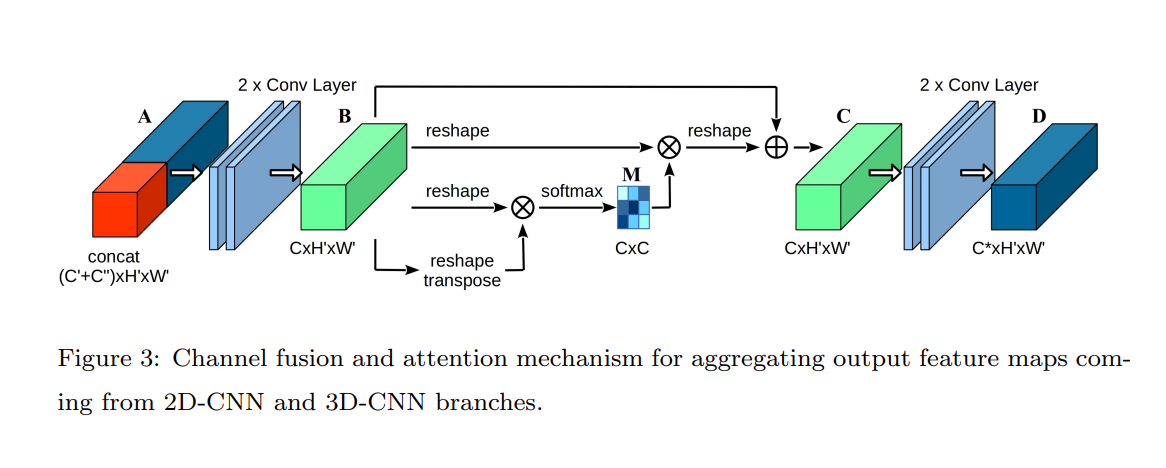
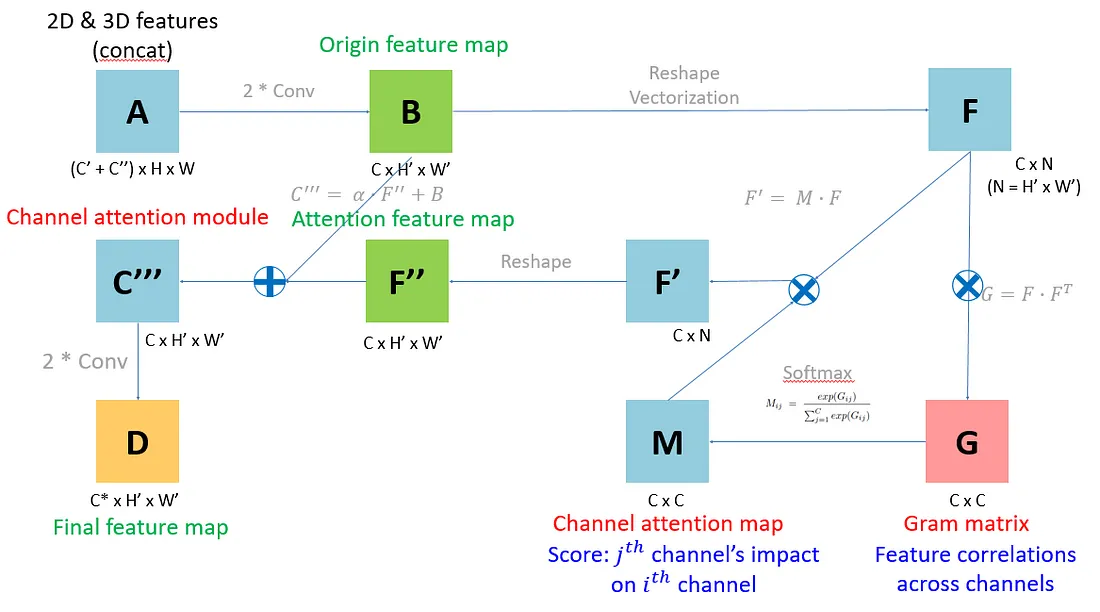
特征聚合:通道融合和注意机制(CFAM)
YOWO通过确保3D和2D网络的输出在最后两个维度上具有相同的形状,从而使得这两个特征图可以轻松地进行融合。这种融合是通过连接操作完成的,它将两个特征图沿着通道维度进行简单的堆叠。经过融合后的特征图包含了运动信息和外观信息,这样的特征图随后被送入基于Gram矩阵的通道融合和注意机制(CFAM)模块,该模块的作用是映射不同通道之间的依赖关系。
虽然最初基于Gram矩阵的注意机制是用于图像风格迁移,并且最近也被用于图像分割任务,但这种注意机制在合理融合来自不同来源的特征方面显示出了其优势,这对于提升整体模型性能具有显著的效果。通过这种方式,YOWO能够有效地结合时空信息和空间信息,从而更准确地进行动作定位和识别。
将3D和2D-CNN得到的feature map进行concat操作,得到融合了运动(motion)和外观(appearance)两种信息的feature map A:
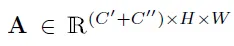
A经过两层conv层后得到新的feature map B:
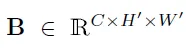
B再进行向量化操作,将高度H和宽度W整合到同一个维度,得到N = H x W,形成F矩阵:
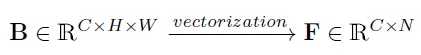
F矩阵通过内积运算可以得到Gram Matrix,即G矩阵。G矩阵反映了跨通道特征的相关性,它是全局性的,并且与语义层次的特征相关。在风格迁移(style transfer)任务中,Gram Matrix通常用于捕捉画风等高层次特征。

接下来,对G矩阵应用softmax函数,转化为channel attention map,即M矩阵。M矩阵实际上是将跨通道的相关性转换成分数,表示第j个通道对第i个通道的影响程度。
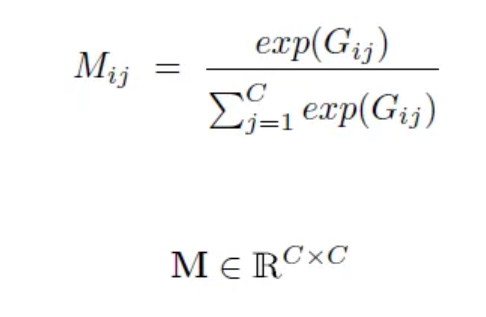
为了将attention的信息融合回原始特征中,将M与F进行内积运算,然后reshape回原来的N = H x W维度。
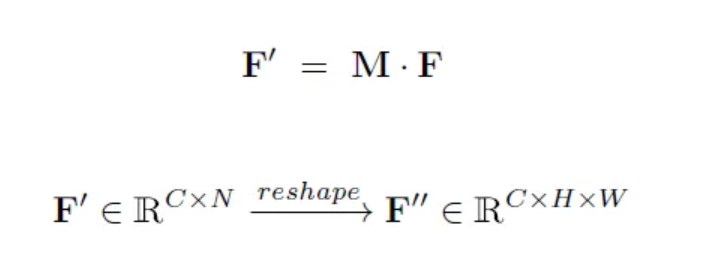
然后,将得到的attention feature map与原始的feature map进行结合,这里通过一个权重参数alpha进行调整,得到最终的C,即Channel attention module的输出:
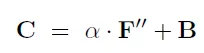
最终的feature map是C经过两次卷积后得到的D。YOWO论文中的符号表示可能有些混乱,通过上述操作,最终得到的feature map D能够使相关性更高的通道具有更大的影响力,从而将全局性的特征与原始特征结合起来使用。
3.2. 实现细节
YOWO在初始化时分别针对3D和2D网络参数采用了不同的预训练模型:对于3D部分,使用了在Kinetics数据集上预训练的模型;而对于2D部分,则使用了在PASCAL VOC数据集上预训练的模型。尽管YOWO的架构包括了2D-CNN和3D-CNN两个分支,但这些参数是可以一起更新的。在优化损失函数的过程中,YOWO选择了使用带动量的随机梯度下降(SGD)算法,并采用了小批量(mini-batch)策略。学习率初始设定为0.0001,并在经过30,000、40,000、50,000和60,000次迭代后,分别将学习率乘以0.5来进行衰减。在训练UCF101-24数据集时,模型在经过5个训练周期后完成训练;而对于J-HMDB-21数据集,则在10个训练周期后完成。整个YOWO架构是使用PyTorch框架实现的,并在单个Nvidia Titan XP GPU上进行了端到端的训练。这种训练方式使得YOWO能够充分利用预训练模型在大型数据集上学到的特征,并有效地微调以适应新的时空动作定位任务。
3.3. 链接策略
YOWO已经成功实现了对视频帧中动作的检测,接下来的关键步骤是将这些检测到的边界框进行有效链接,以便在整个视频范围内构建连续的动作管。这一步骤对于UCF101-24和J-HMDB-21这两个数据集尤为重要,因为它们需要在视频级别上对动作进行识别和理解。
为了实现这一目标,YOWO采用了链接算法。该算法旨在通过评估连续帧之间边界框的相似性和空间时间一致性,来识别和连接属于同一动作的多个边界框。通过这种方式,算法能够生成视频级别的动作检测结果,即动作管,这些动作管表示了视频中动作发生的时空范围。
链接算法通过计算每一对边界框之间的关联分数,并利用这些分数来构建一个优化问题,从而找到最优的动作管。这个问题可以通过动态规划或其他图论算法来解决,以确保识别出的动作管在时间和空间上是连贯的,并且最大化动作检测的准确性和一致性。
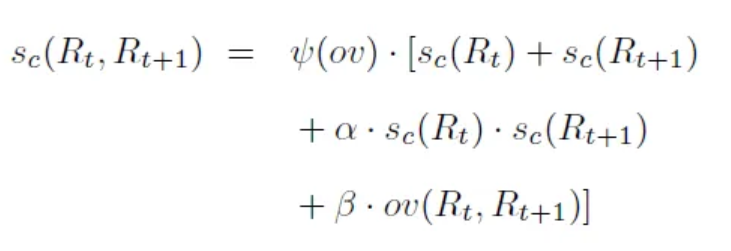
3.4. 长期特征库
尽管YOWO的设计允许在线和因果的推理,即仅使用当前和过去的信息来进行动作定位,但较小的视频片段长度限制了模型可以利用的时间信息量。为了解决这个问题,采用了一种长期特征库(LFB)的技术。LFB存储了来自视频不同时间点的3D骨干网络提取的特征,这些特征可以在推理过程中被用来增强模型对动作的理解。
在进行推理时,会取以关键帧为中心的多个3D特征,并对它们进行平均处理,得到的特征图随后作为通道融合和注意机制(CFAM)模块的输入。这里使用的3D骨干网络是预训练的3D ResNeXt-101,它被用来从非重叠的8帧视频片段中提取LFB特征。在关键帧为中心的情况下,YOWO会利用8个这样的特征。这意味着,在推理过程中,YOWO实际上可以访问64帧的时间信息,这显著增加了模型可用于动作分类的时间上下文。
通过使用LFB,能够在不牺牲实时性能的前提下,提高模型对动作的分类准确性。这种方法类似于在视频数据集中提高剪辑级别准确性与视频级别准确性之间的区别。然而,需要注意的是,引入LFB后,YOWO的架构不再是纯粹的因果架构,因为在推理时它利用了未来的3D特征信息。这意味着在实际应用中,YOWO可能需要存储过去的一段视频特征,以便在新帧到来时能够实时更新和使用LFB。尽管如此,这种方法仍然为实时动作检测和分类提供了一种有效的解决方案,尤其是在需要理解视频中长时间动作发展的场景中。
4. 实验
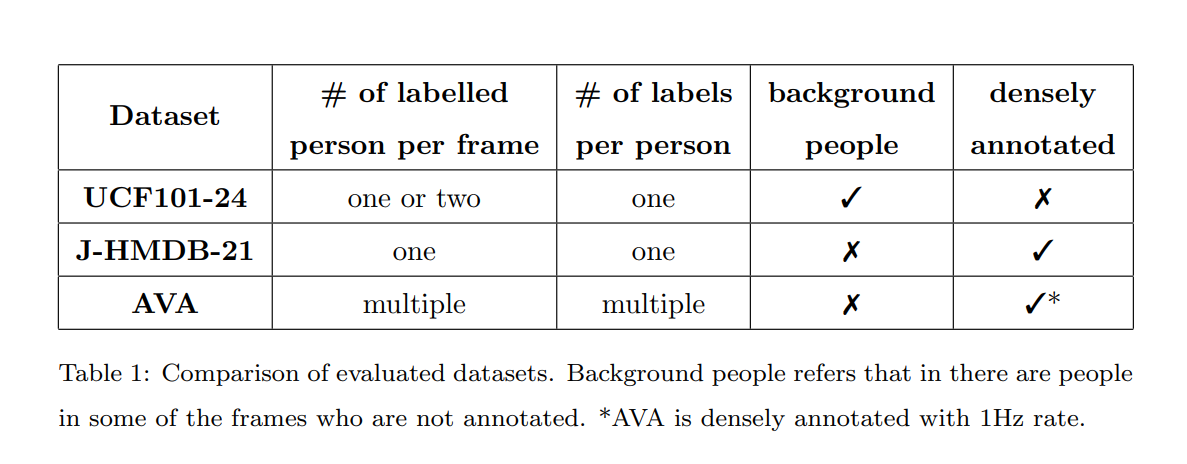
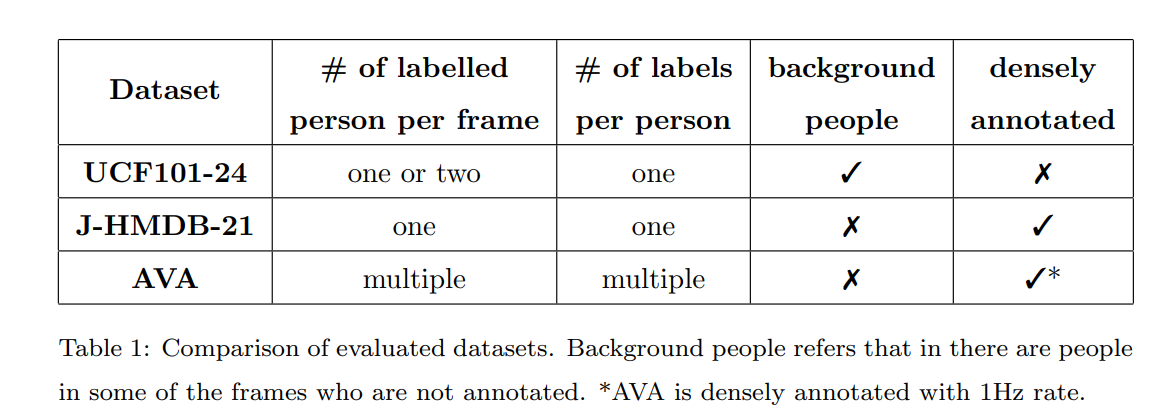
为了评估YOWO的性能,选择了三个流行且具有挑战性的动作检测数据集:UCF101-24、J-HMDB-21和AVA。这些数据集每个都包含了不同的特征,这些特征在表1中进行了比较。严格遵循官方评估指标来报告结果,并将YOWO的方法与最先进方法进行比较。
4.1. 数据集和评估指标
UCF101-24是UCF101数据集的一个子集,它是一个专门用于现实动作视频识别的数据集。UCF101-24包含了24个不同的动作类别和3207个视频,这些视频都配有精确的时空标注。在这些视频中,可能存在多个相同类别标签但具有不同空间和时间边界的动作实例,这一特点给视频级别的动作检测带来了额外的挑战。与以往的研究一致,我们在第一个数据分割上进行所有的实验。
J-HMDB-21是HMDB-51数据集的一个子集,它包含了928个短视频,覆盖了21个日常生活中的动作类别。与UCF101-24不同,J-HMDB-21中的每个视频都经过了精心的剪辑,确保在所有的帧中只展示一个单一的动作实例。我们在第一个数据分割上报告我们的实验结果。
AVA数据集是一个用于时空定位的原子视觉动作(AVA)的视频数据集。它包含了80个原子视觉动作类别,这些动作在430个15分钟的视频剪辑中被密集地标注,每个动作都在空间和时间上进行了定位。这导致了超过150万个动作标签的产生,每个人在视频中被标记有多个动作。我们遵循ActivityNet挑战的指导方针,在AVA数据集的60个最频繁出现的动作类别上对YOWO进行评估。除非另有说明,否则我们仅在AVA数据集的版本2.2上报告结果。
评估指标方面,我们采用了两个在大多数研究中用于区域时空动作检测的流行指标来进行评估,以生成有说服力的结果。我们严格遵循PASCAL VOC 2012指标的规则,使用帧平均精度(mAP)来衡量每个帧中检测的精度和召回率之间的平衡。另一方面,视频mAP关注的是动作管的检测质量。如果一个视频的所有帧中检测到的动作管与真实标注的平均交并比(IoU)超过了设定的阈值,并且动作标签被正确预测,那么这个检测到的动作管就被认为是正确的。最后,我们会计算每个类别的平均精度,并报告所有类别的平均值。对于AVA数据集,我们仅使用帧mAP作为评估指标,并且设置IoU阈值为0.5,这是因为标注的提供频率为每秒1次。
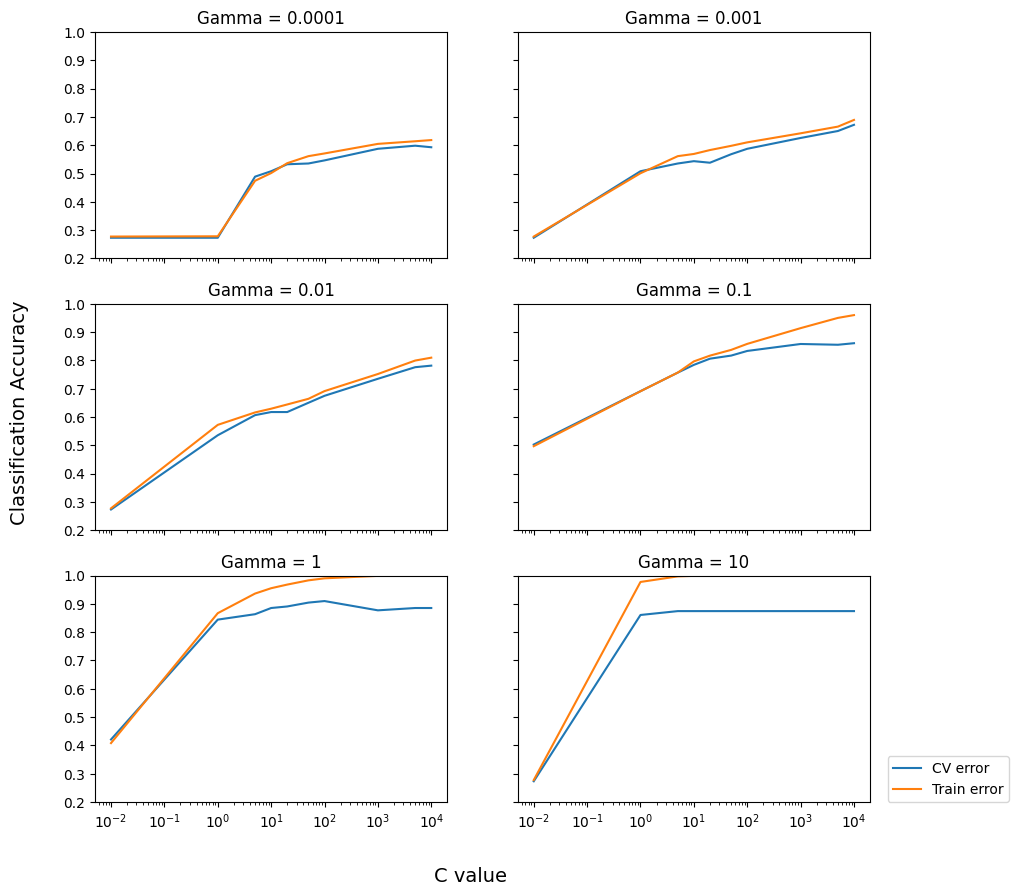
4.2. 消融研究
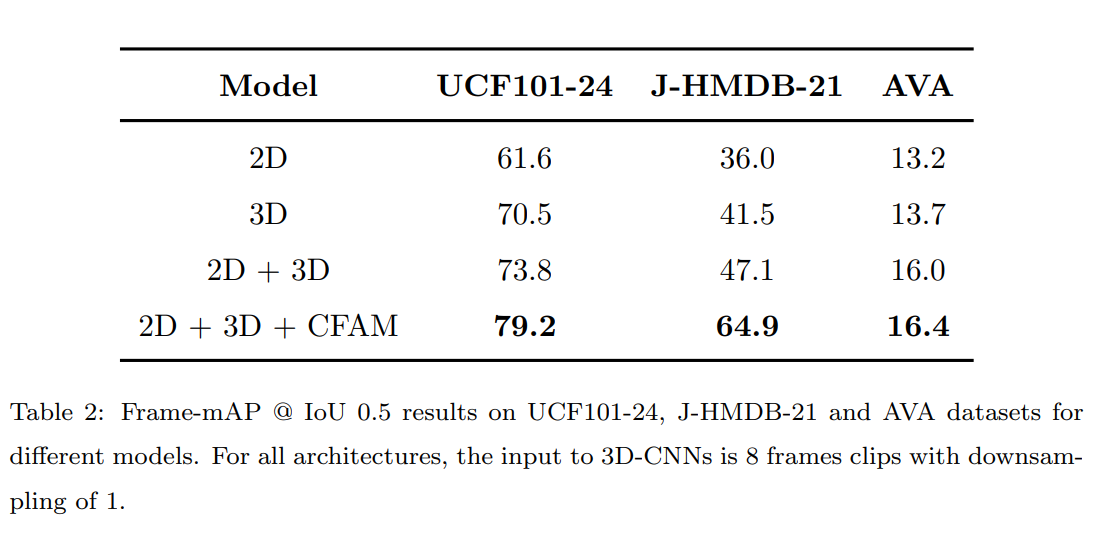
3D网络、2D网络,或者是两者结合使用?如果单独使用,无论是3D-CNN还是2D-CNN都无法单独解决时空定位任务。然而,当这两种网络同时工作时,它们可以从彼此的优势中受益。表2展示了不同架构的性能比较结果。我们首先注意到,仅使用2D网络无法得到令人满意的性能,因为它忽略了时间信息。而单独的3D网络在捕获运动信息方面表现得更好。当我们将2D和3D网络(通过简单的连接)结合起来时,与仅使用3D网络相比,在UCF101-24、J-HMDB-21和AVA数据集上的性能分别提高了约3%、6%和2%的mAP。这表明2D-CNN能够学习到更加精细的空间特征,而3D-CNN则更专注于捕捉动作的运动信息。但是,由于视频剪辑中动作的空间漂移可能导致较低的定位精度,因此单一的3D网络在定位方面可能存在不足。通过结合两者的优势,我们可以提高模型的整体性能,更好地解决时空动作定位任务。
4.3. 与最先进方法的比较
将YOWO与其他最先进的方法在J-HMDB-21、UCF101-24和AVA数据集上进行了比较。为了公平起见,我们排除了VideoCapsuleNet,因为它使用了不同的视频mAP计算方法,没有通过一些链接策略构建动作管。然而,YOWO在J-HMDB-21和UCF101-24数据集上的帧mAP @ 0.5 IoU方面仍然比VideoCapsuleNet好大约9%和8%。

4.4. 模型可视化
总体而言,YOWO架构在视频中定位动作方面表现出色,如下图所示,它在UCF101-24和J-HMDB-21数据集上的表现尤为突出;同样,如图7所示,它在AVA数据集上也有着不错的表现。尽管如此,YOWO也存在一些局限性。首先,YOWO是基于关键帧和剪辑中的所有可用信息来生成预测的,这可能导致它在动作实际发生之前就产生一些错误的检测。例如,在图6的第一行最后一个例子中,YOWO检测到一个在篮球场上持球的人,并非常自信地将其标记为正在投篮,尽管那个人实际上还没有开始投篮动作。其次,YOWO在进行准确的动作定位时需要充足的时间信息。如果一个人突然开始一个动作,视频的初始帧可能缺乏足够的时间信息,从而导致错误的动作识别,如图6中的第二行最后一个例子所示,错误地将爬楼梯识别为跑步。同样,在图7最右侧的例子中,由于处理过的剪辑和关键帧没有包含人物的姿势信息,YOWO无法确定该人是坐着还是站着。表4的结果显示,通过增加剪辑的长度,我们可以增加YOWO可利用的时间信息量,从而提高其性能。长期特征库(LFB)的使用也是为了增加时间信息的深度。这些因素都表明,在设计和使用YOWO时,我们需要考虑到视频内容的时间维度,以确保模型能够准确地识别和定位动作。

5. 结论
YOWO能够并行处理来自连续视频帧的时空上下文信息,以便更好地理解和识别动作,同时它也能够从关键帧中提取细节丰富的空间信息,以解决动作定位问题。此外,YOWO采用了一种通道融合和注意力机制,有效地整合了来自不同网络分支的信息。与将行人检测和动作分类作为分开的步骤不同,YOWO将这两个过程整合在一起,使得整个网络可以通过一个统一的损失函数在端到端的框架中进行优化。
在评估性能方面,YOWO在UCF101-24、J-HMDB-21和AVA这三个具有不同特点的数据集上进行了一系列的比较测试。在UCF101-24和J-HMDB-21数据集上,YOWO取得了超越其他最先进方法的结果,而在AVA数据集上,YOWO也展现了竞争力的表现。这些成果证明了YOWO在时空动作定位任务上的有效性。
更重要的是,YOWO的架构是因果的,意味着它仅使用当前和过去的信息进行预测,而不需要未来的信息。这一特性使得YOWO能够实时地处理视频数据,为在移动设备等平台上的实时应用提供了可能。实时性能的保证,加上其在多个数据集上的优异表现,使得YOWO成为一个有前景的模型,适用于需要实时动作检测和识别的各种应用场景。