文章目录
- 深入理解插入排序:直接插入排序与希尔排序
- 直接插入排序
- 算法描述
- 工作原理
- 性能分析
- 希尔排序
- 算法描述
- 实现代码
- 性能分析
- 比较直接插入排序与希尔排序
- 结论
深入理解插入排序:直接插入排序与希尔排序
排序算法是计算机科学中的基石之一,它关系到数据处理的效率和速度。在众多排序算法中,插入排序以其简单直观而广为人知,特别是直接插入排序和希尔排序。在这篇博客中,我们将深入探讨这两种插入排序的原理、实现和性能分析。
直接插入排序
直接插入排序是一种简单的排序方法,它的工作方式如下:从未排序的序列中取出一个元素,将其插入到已排序序列的正确位置,以保持已排序序列的有序性。这个过程一直重复,直到整个序列都有序。
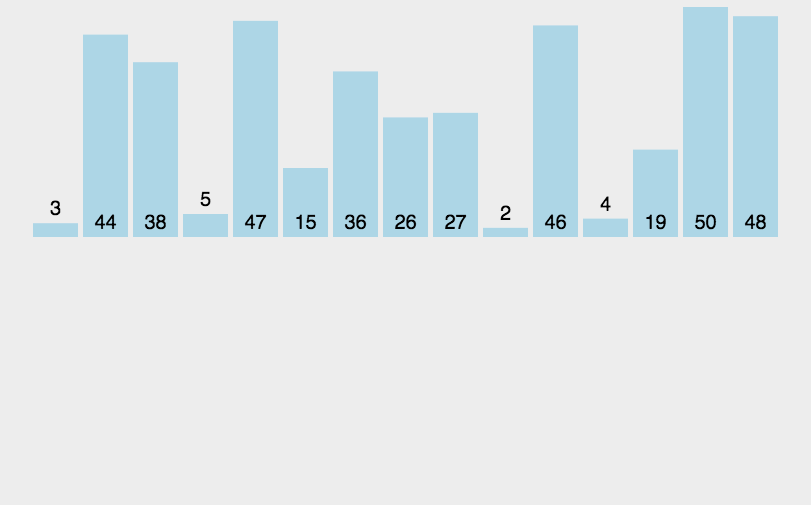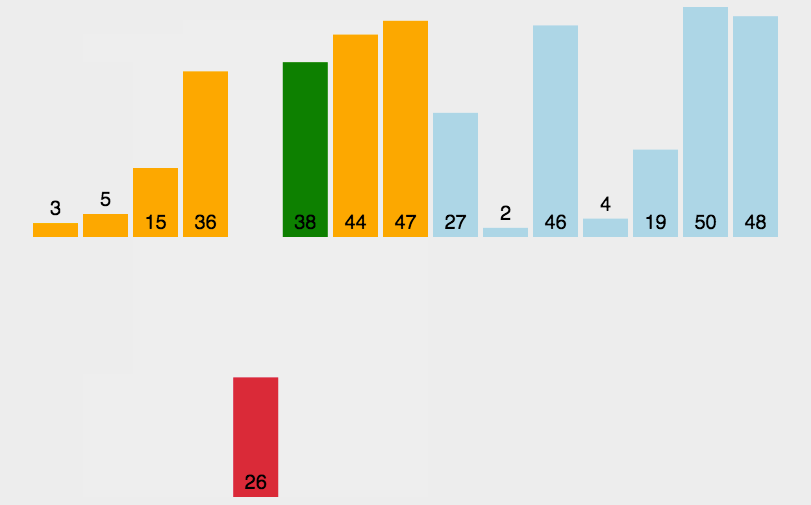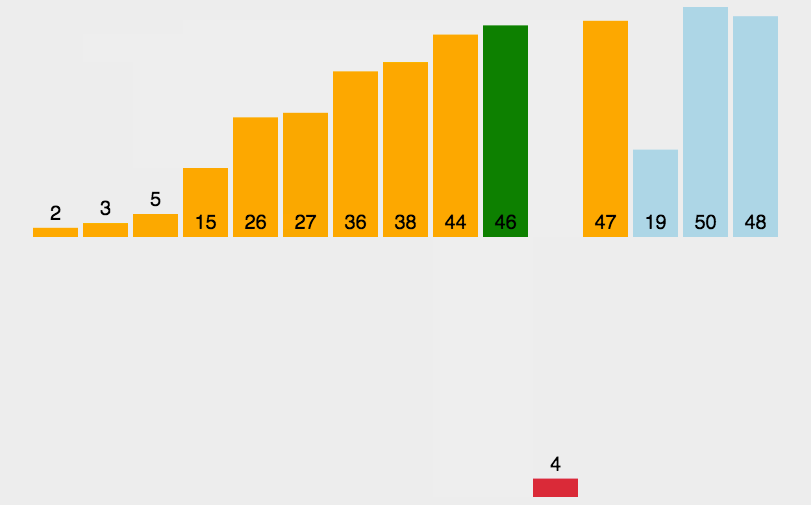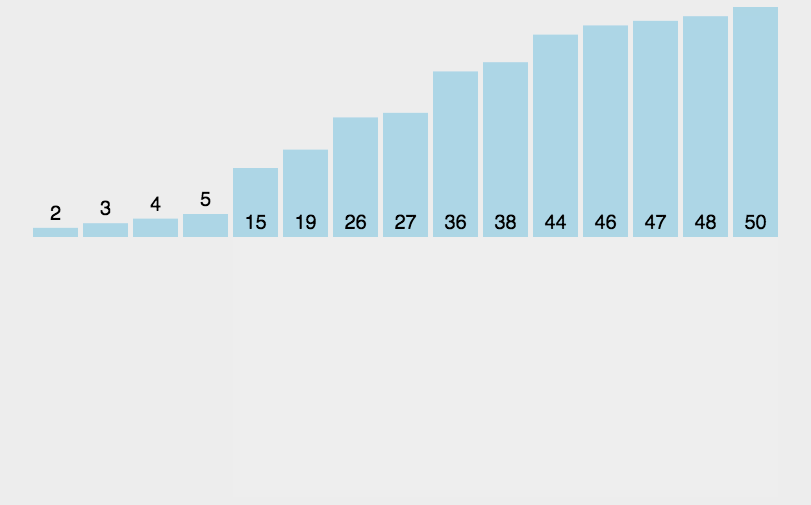
算法描述
直接插入排序的具体逻辑可以通过下面的伪代码描述:
void InsertSort(int* a, int n) {
for (int i = 0; i < n - 1; i++) {
int end = i;
int tmp = a[end + 1];
while (end >= 0 && tmp < a[end]) {
a[end + 1] = a[end];
end--;
}
a[end + 1] = tmp;
}
}
工作原理
- 初始化已排序序列:最初,我们认为数组的第一个元素已经处于排序状态。
- 扩展已排序序列:从第二个元素开始,逐个将未排序的元素插入到已排序序列中。
- 查找插入位置:对于每个待排序元素,我们通过向后移动已排序数组的元素来为新元素腾出空间,直到找到适合的插入位置。
- 插入元素:将新元素插入到找到的位置。
性能分析
- 时间复杂度:最好情况 O(n),最坏情况 O(n^2),平均 O(n^2)。
- 空间复杂度:O(1),因为它是一种原地排序算法。
- 稳定性:直接插入排序是稳定的排序算法,相同的元素在排序后会保持原来的顺序。
希尔排序
希尔排序是由Donald Shell于1959年提出的,它是直接插入排序的一种高效改进版本。希尔排序通过引入“间隔”概念来允许交换远距离的元素,从而使数组中的元素能够更快地达到正确的位置。
算法描述
希尔排序的基本思想是将相距某个“间隔GAP”的记录组成一个子序列,这样能够让一个元素可以一次性地朝最终位置前进一大步。然后逐渐缩小这个间隔,继续进行排序,直至间隔为1,所有元素各自在最终位置上。
实现代码
void ShellSort(int* a, int n) {
int gap = n;
while (gap > 1) {
gap = gap / 2; // 动态定义间隔长度
for (int i = 0; i < n - gap; i++) {
int end = i;
int tmp = a[end + gap];
while (end >= 0 && a[end] > tmp) {
a[end + gap] = a[end];
end -= gap;
}
a[end + gap] = tmp;
}
}
}
性能分析
- 时间复杂度:希尔排序的时间复杂度与间隔序列的选择有很大关系,一般认为最好的已知时间复杂度为 O(n log^2 n)。
- 空间复杂度:O(1),因为希尔排序也是一种原地排序算法。
- 稳定性:希尔排序是不稳定的排序算法,因为在不同的间隔排序阶段中,相等的元素可能会被交换。
比较直接插入排序与希尔排序
直接插入排序和希尔排序虽然都属于插入排序的范畴,但它们在处理大规模数据集时表现出不同的效率:
- 效率:希尔排序通常比直接插入排序更高效,尤其是对于大规模数据集。这是因为希尔排序通过初期的大间隔操作,允许元素快速接近其最终位置,减少了后期元素的移动次数。
- 代码复杂度:直接插入排序的实现比希尔排序简单。希尔排序的实现需要更多的控制逻辑来管理不同的间隔。
- 适用场景:
- 直接插入排序适合数据量较小,或基本有序的数据集。
- 希尔排序适合于中到大规模的数据集,特别是当内存空间充裕时。
结论
插入排序是一种易于理解和实现的排序算法,适用于小规模或部分有序的数据集。直接插入排序因其简洁而广泛用于教学和简单应用,而希尔排序则以其改进的效率适用于更复杂的场景。
在选择排序算法时,应综合考虑数据的规模、预期的效率以及实现的复杂度。理解不同排序算法的内在机制和性能特点是进行有效选择的关键。